【python基础知识】16.文件读写基础及操作
文章目录
- 前言
- 读取文件
-
- 【第1步-开】
- 【第2步-读】
- 【第3步-关】
- 写入文件
-
- 【第1步-开】
- 【第2步-写】
- 【第3步-关】
- 【练习时间来咯】
- 小技巧
- 小练习
前言
文件读写,是Python代码调用电脑文件的主要功能,能被用于读取和写入文本记录、音频片段、Excel文档、保存邮件以及任何保存在电脑上的东西。
你可能会疑惑:为什么要在Python打开文件?我直接打开那个文件,在那个文件上操作不就好了吗?
一般来说直接打开操作当然是没问题的。但假如你有一项工作,需要把100个Word文档里的资料合并到1个文件上,一个个地复制粘贴多麻烦啊,这时你就能用上Python了。或者,当你要从网上下载几千条数据时,直接用Python帮你把数据一次性存入文件也是相当方便。
要不然怎么说,Python把我们从重复性工作中解放出来呢~
【文件读写】,是分为【读】和【写】两部分的,我们就先来瞧瞧【读文件】是怎么实现的?
读取文件

其实,真的就三步:

是不是像很久之前的那个冷笑话?“请问把大象放进冰箱需要几步?”三步:打开冰箱,放入大象,关闭冰箱。同样地,读文件也是三步:开——读——关。
我举个例子好了,你可以跟着我在自己的电脑上操作,如果你的电脑上还没有安装Python环境,可以先安装一下。
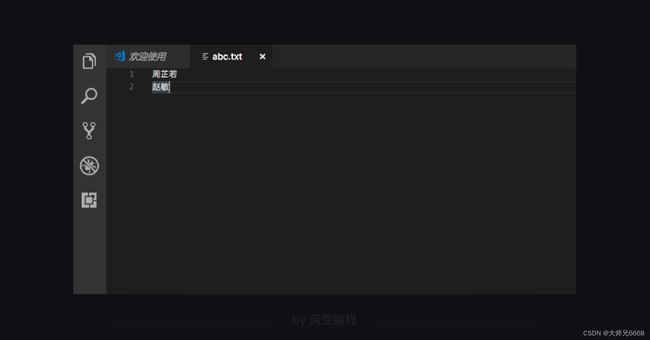
首先,我们先在桌面新建一个test文件夹,然后在文件夹里新建一个名为abc的txt文件,在里面随便写点儿什么,我写的是周芷若、赵敏。
我用编辑器Visual Studio Code打开这个文件,是这样的:
然后,你可以用VS Code新建一个open.py的Python文件,也放在test文件夹里,我们就在这里写代码。
代码怎么写呢?
【第1步-开】
使用open()函数打开文件。语法是这样的:
file1 = open('/Users/Ted/Desktop/test/abc.txt','r',encoding='utf-8')
file1这个变量是存放读取的文件数据的,以便对文件进行下一步的操作。
open()函数里面有三个参数,对吧:
'/Users/Ted/Desktop/test/abc.txt'
'r'
encoding='utf-8'
我们一个个来看。第一个参数是文件的保存地址,一定要写清楚,否则计算机找不到。注意:我和你的文件地址是不一样的哦。
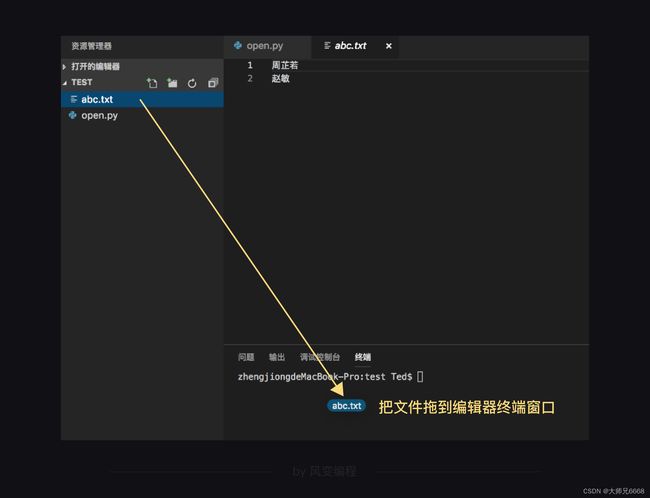
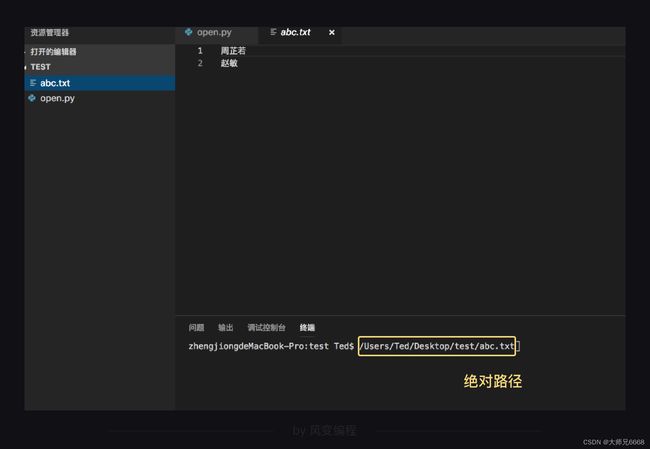
要找到你的文件地址,只需要把你要打开的文件直接拖到编辑器终端的窗口里,就会显示出文件地址,然后复制一下就好。
不过文件的地址有两种:相对路径和绝对路径,拖到终端获取的地址是绝对路径。这两种地址,Mac和Windows电脑还有点傲娇地不太一样,下面我就帮大家捋一捋。
绝对路径就是最完整的路径,相对路径指的就是【相对于当前文件夹】的路径,也就是你编写的这个py文件所放的文件夹路径!
如果你要打开的文件和open.py在同一个文件夹里,这时只要使用相对路径就行了,而要使用其他文件夹的文件则需使用绝对路径。
我们先来看Mac电脑,现在我的txt文件和py文件都放在桌面的test文件夹里。
我将txt文件拖入终端窗口,获得文件的绝对路径:
那么当我用open()函数打开的时候,就可以写成:
open('/Users/Ted/Desktop/test/abc.txt') #绝对路径
open('abc.txt') #相对路径
#相对路径也可以写成open('./abc.txt')
在这种情况下,你写绝对和相对路径都是可以的。
假如现在这个txt文件,是放在test文件夹下面一个叫做word的文件夹里,绝对路径和相对路径就变成:
open('/Users/Ted/Desktop/test/word/abc.txt'')
open('word/abc.txt')
我们再来看看Windows。Windows系统里,常用\来表示绝对路径,/来表示相对路径,所以当你把文件拖入终端的时候,绝对路径就变成:
C:\Users\Ted\Desktop\test\abc.txt
但是呢,别忘了\在Python中是转义字符,所以时常会有冲突。为了避坑,Windows的绝对路径通常要稍作处理,写成以下两种格式;
open('C:\\Users\\Ted\\Desktop\\test\\abc.txt')
#将'\'替换成'\\'
open(r'C:\Users\Ted\Desktop\test\abc.txt')
#在路径前加上字母r
获取文件的相对路径还有个小窍门,用VS Code打开文件夹,在文件点击右键,选择:
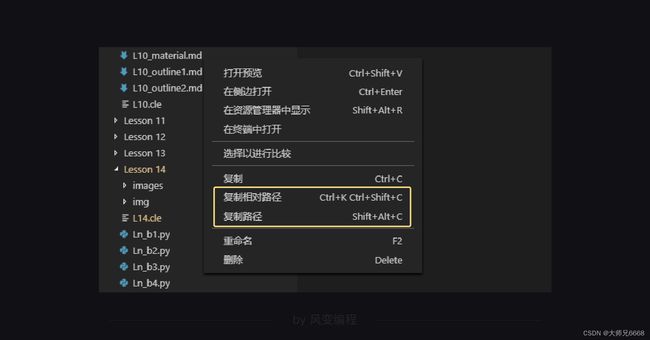
现在,把这行代码复制到你的open.py文件中,然后把文件地址替换成你自己的地址。
file1 = open('/Users/Ted/Desktop/test/abc.txt','r',encoding='utf-8')
好了。终于讲完了第一个参数文件地址,我们来回头看看open()的其他参数:
file1 = open('/Users/Ted/Desktop/test/abc.txt','r',encoding='utf-8')
第二个参数表示打开文件时的模式。这里是字符串 ‘r’,表示 read,表示我们以读的模式打开了这个文件。
你可能会疑惑,为什么打开的时候就要决定是读还是写,之后决定不行吗?这是因为,计算机非常注意数据的保密性,在打开时就要决定以什么模式打开文件。
除了’r’,其他还有’w’(写入),‘a’(追加)等模式,我们稍后会涉及到。
第三个参数encoding=‘utf-8’,表示的是返回的数据采用何种编码,一般采用utf-8或者gbk。注意这里是写encoding而不是encode噢。
读文件的三步:开——读——关,【第1步-开】我们就讲完了,现在看【第2步-读】。
【第2步-读】
打开文件file1之后,就可以用read()函数进行读取的操作了。请看代码:
file1 = open('/Users/Ted/Desktop/test/abc.txt', 'r',encoding='utf-8')
filecontent = file1.read()
第1行代码是我们之前写的。是以读取的方式打开了文件“abc.txt”。
第2行代码就是在读取file1的内容,写法是变量file1后面加个.句点,再加个read(),并且把读到的内容放在变量filecontent里面,这样我们才能拿到文件的内容。
那么,现在我们想要看看读到了什么数据,可以用print()函数看看。请你在自己的电脑里,把剩下的代码补全,可参考下面的代码
file1 = open('/Users/Ted/Desktop/test/abc.txt','r',encoding='utf-8')
filecontent = file1.read()
print(filecontent)
然后,在编辑器窗口【右键】,选择【在终端中运行Python文件】,这时终端显示的是:

你会发现,打印出了abc.txt文件里面的内容,它会读成字符串的数据形式。
【第3步-关】
关闭文件,使用的是close()函数。
file1 = open('/Users/Ted/Desktop/test/abc.txt','r',encoding='utf-8')
filecontent = file1.read()
print(filecontent)
file1.close()
前3行代码你都学了,第4行:变量file1后面加个点,然后再加个close(),就代表着关闭文件。千万要记得后面的括号可不能丢。
为啥要关闭文件呢?原因有两个:1.计算机能够打开的文件数量是有限制的,open()过多而不close()的话,就不能再打开文件了。2.能保证写入的内容已经在文件里被保存好了。
文件关闭之后就不能再对这个文件进行读写了。如果还需要读写这个文件的话,就要再次 open() 打开这个文件。
我们总结一下读文件的三步:开——读——关,并奉上一张总结图。

尤其需要留意的是第二、三步,即读和关的写法。
学完了【读文件】,然后是【写文件】。
写入文件

嘻嘻,写文件也是三步:打开文件——写入文件——关闭文件。

【第1步-开】
以写入的模式打开文件。
file1 = open('/Users/Ted/Desktop/test/abc.txt','w',encoding='utf-8')
第1行代码:以写入的模式打开了文件"abc.txt"。
open() 中还是三个参数,其他都一样,除了要把第二个参数改成’w’,表示write,即以写入的模式打开文件。
【第2步-写】
往文件中写入内容,使用write()函数。
file1 = open('/Users/Ted/Desktop/test/abc.txt', 'w',encoding='utf-8')
file1.write('张无忌\n')
file1.write('宋青书\n')
第2-3行代码:往“abc.txt”文件中写入了“张无忌”和“宋青书”这两个字符串。\n表示另起一行。
请你原样照做,然后记得运行程序。然后当你打开txt文件查看数据:
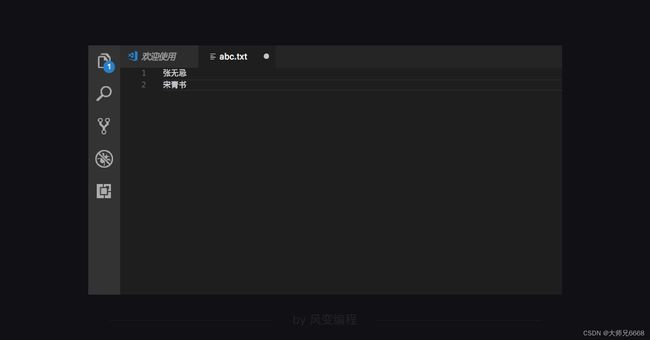
诶?原来文件里的周芷若和赵敏去哪里了?
是这样子的,'w’写入模式会给你暴力清空掉文件,然后再给你写入。如果你只想增加东西,而不想完全覆盖掉原文件的话,就要使用’a’模式,表示append,你学过,它是追加的意思。
如果重新再来一遍的话,就要这样写:
file1 = open('/Users/Ted/Desktop/test/abc.txt', 'a',encoding='utf-8')
#以追加的方式打开文件abc.txt
file1.write('张无忌\n')
#把字符串'张无忌'写入文件file1
file1.write('宋青书\n')
#把字符串'宋青书'写入文件file1
这样的话,就会追加成功,而不会覆盖了。你可以随便试试加点什么,运行看看。

【第3步-关】
还是要记得关闭文件,使用close()函数,看代码:
file1 = open('/Users/Ted/Desktop/test/abc.txt','a',encoding='utf-8')
file1.write('张无忌\n')
file1.write('宋青书\n')
file1.close()
第4行代码,还是熟悉的配方,还是熟悉的味道。这样就搞定【写文件】了。
不过呢,有两个小提示:1.write()函数写入文本文件的也是字符串类型。2.在’w’和’a’模式下,如果你打开的文件不存在,那么open()函数会自动帮你创建一个。
【练习时间来咯】
1.请你在一个叫1.txt文件里写入字符串’难念的经’ 2.然后请你读取这个1.txt文件的内容,并打印出来。
提示:先写再读。写文件分为3步,读文件也同样分为3步。
参考代码:
f1 = open('./1.txt','a',encoding='utf-8')
#以追加的方式打开一个文件,尽管并不存在这个文件,但这行代码已经创建了一个txt文件了
f1.write('难念的经')
#写入'难念的经'的字符串
f1.close()
#关闭文件
f2 = open('./1.txt','r',encoding='utf-8')
#以读的方式打开这个文件
content = f2.read()
#把读取到的内容放在变量content里面
print(content)
#打印变量content
f2.close()
#关闭文件
注:路径根据自己的实际路径来替换即可。
运行结果:
难念的经
我们再来总结下写文件的三步法。

现在问题来了,如果我们想写入的数据不是文本内容,而是音频和图片的话,该怎么做呢?

我们可以看到里面有’wb’的模式,它的意思是以二进制的方式打开一个文件用于写入。因为图片和音频是以二进制的形式保存的,所以使用wb模式就好了,这在今天的课后作业我们会用到。
小技巧
这里再顺便补充一个用法,为了避免打开文件后忘记关闭,占用资源或当不能确定关闭文件的恰当时机的时候,我们可以用到关键字with,之前的例子可以写成这样:
# 普通写法
file1 = open('abc.txt','a')
file1.write('张无忌')
file1.close()
# 使用with关键字的写法
with open('abc.txt','a') as file1:
#with open('文件地址','读写模式') as 变量名:
#格式:冒号不能丢
file1.write('张无忌')
#格式:对文件的操作要缩进
#格式:无需用close()关闭
所以之后当你看到with open…as这种打开文件的语法格式也要淡定,这种还挺常见的。
正所谓“光看不写,学这Python有何用”,接下来,我们还是一起写写代码噢 (p≧w≦q)!
小练习
我们一路到这里,你应该也看出来了,本人非常喜欢《哈利波特》哈哈。
现在假设你来到了魔法世界,最近期末快到了,霍格沃兹魔法学校准备统计一下大家的成绩。
评选的依据是什么呢?就是同学们平时的作业成绩。
现在有这样一个叫scores.txt的文件,里面有赫敏、哈利、罗恩、马尔福四个人的几次魔法作业的成绩。

但是呢,因为有些魔法作业有一定难度,教授不强制同学们必须上交,所以大家上交作业的次数并不一致。
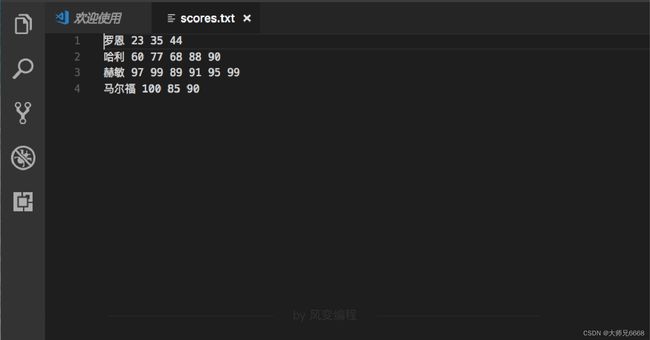
这里是文件内容,你可以在自己的电脑里新建一个scores.txt来操作。
罗恩 23 35 44
哈利 60 77 68 88 90
赫敏 97 99 89 91 95 90
马尔福 100 85 90
希望你来统计这四个学生的魔法作业的总得分,然后再写入一个txt文件。注意,这个练习的全程只能用Python。
面对这个功能,请你思考30s,粗略地想想该怎么实现?然后点击enter继续。
好,一个非常粗糙的思路应该是:拿到txt文件里的数据,然后对数据进行统计,然后再写入txt文件。好,马上开始。
首先,毫无疑问,肯定是打开文件,还记得用什么函数吗?
file1 = open('/Users/Ted/Desktop/scores.txt','r',encoding='utf-8')
接着呢,就是读取文件了。一般来说,我们是用read()函数,但是在这里,我们是需要把四个人的数据分开处理的,我们想要按行处理,而不是一整个处理,所以读的时候也希望逐行读取。
因此,我们需要使用一个新函数readlines(),也就是“按行读取”。
file1 = open('/Users/Ted/Desktop/scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
print(file_lines)
用print()函数打印一下,看看这种方法读出来的内容是咋显示的:
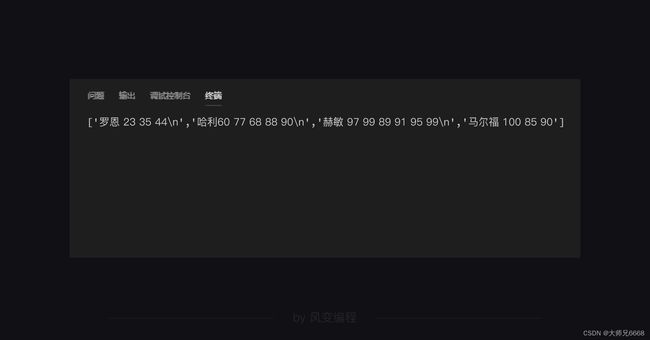
你看到了,readlines() 会从txt文件取得一个列表,列表中的每个字符串就是scores.txt中的每一行。而且每个字符串后面还有换行的\n符号。
这样一来,我们就可以使用for循环来遍历这个列表,然后处理列表中的数据,请看第五行代码:
file1 = open('/Users/Ted/Desktop/scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
for i in file_lines: #用for...in...把每一行的数据遍历
print(i) #打印变量i
我们一样来打印看看。
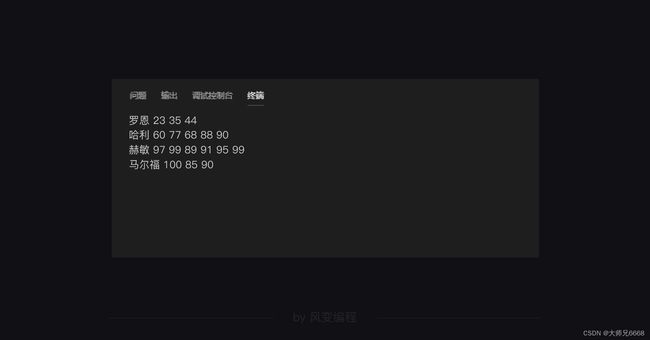
好,现在我们要把这里每一行的名字、分数也分开,这时需要我们使用split()来把字符串分开,它会按空格把字符串里面的内容分开。
看上图第一行的罗恩 23 35 44,它将被分为[‘罗恩’, ‘23’, ‘35’, ‘44’]。
file1 = open('/Users/Ted/Desktop/scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
for i in file_lines: #用for...in...把每一行的数据遍历
data =i.split() #把字符串切分成更细的一个个的字符串
print(data) #打印出来看看
终端是这样的:

显然,对比上面两个终端的图,split()又把每一行的内容分成了一个个的字符串,于是变成了一个个列表。
split()是我们没有学过的对字符串的处理方法,在这里,老师想插一句,对数据类型的处理是有很多种方法的,但我们不可能一次学完,而应该学习最基础必要的知识,然后在需要用到新知识时,再继续学。
split()是把字符串分割的,而还有一个join()函数,是把字符串合并的。
a=['c','a','t']
b=''
print(b.join(a))
c='-'
print(c.join(a))
运行结果:
cat
c-a-t
join()的用法是str.join(sequence),str代表在这些字符串之中,你要用什么字符串连接,在这里两个例子,一个是空字符串,一个是横杠,sequence代表数据序列,在这里是列表a。
在这里只是为了让大家理解join(),不需要记忆,之后再用再看就好。
回到哈利波特的那一步:
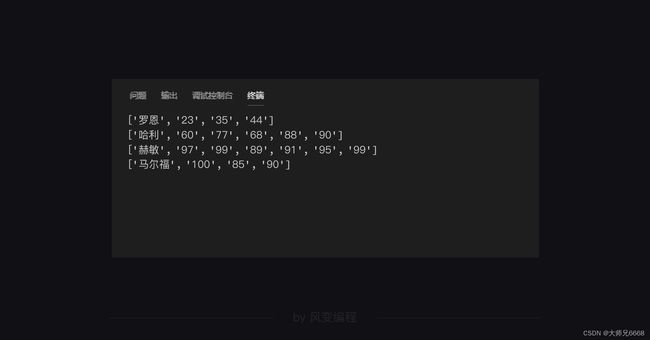
这4个列表的第0个数据是姓名,之后的就是成绩。我们需要先统计各人的总成绩,然后把姓名和成绩放在一起。
还是可以用for…in…循环进行加法的操作,请看第8行的代码:
file1 = open('/Users/Ted/Desktop/scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
for i in file_lines:
data =i.split()
sum = 0 #先把总成绩设为0
for score in data[1:]: #遍历列表中第1个数据和之后的数据
sum = sum + int(score) #然后依次加起来,但分数是字符串,所以要转换
result = data[0]+str(sum) #结果就是学生姓名和总分
print(result)
来看看终端:
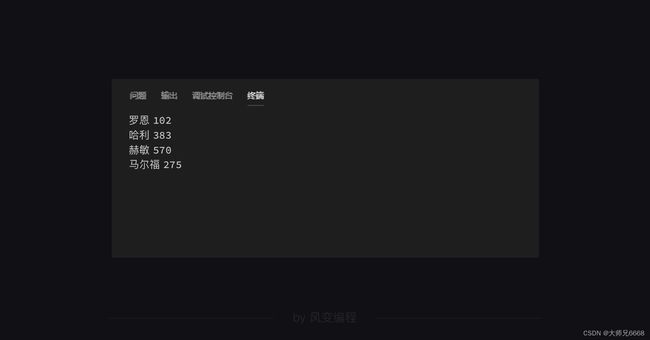
好,接下来就是把成绩写入一个空的列表,因为这样才有助于我们之后写入一个txt文件。
file1 = open('/Users/Ted/Desktop/scores.txt','r',encoding='utf-8')
file_lines = file1.readlines()
file1.close()
final_scores = [] #新建一个空列表
for i in file_lines:
data =i.split()
sum = 0
for score in data[1:]:
sum = sum + int(score)
result = data[0]+str(sum)+'\n' #后面加上换行符,写入的时候更清晰。
final_scores.append(result)#每统计一个学生的总分,就把姓名和总分写入空列表
好啦,那我们就已经处理好了,就差写入文件啦。大家可以从第15行开始看:
file = open('/Users/Ted/Desktop/scores.txt','r',encoding='utf-8')
file_lines = file.readlines()
file.close()
final_scores = []
for i in file_lines:
data =i.split()
sum = 0
for score in data[1:]:
sum = sum + int(score)
result = data[0]+str(sum)+'\n'
final_scores.append(result)
winner = open('/Users/Ted/Desktop/winner.txt','w',encoding='utf-8') # 从这行开始看
winner.writelines(final_scores)
winner.close()
15行的代码是打开一个叫winner.txt的文件。(如果电脑中不存在winner.txt的话,这行代码会帮你自动新建一个空白的winner.txt)
16行的代码是以writelines()的方式写进去,为什么不能用write()?因为final_scores是一个列表,而write()的参数必须是一个字符串,而writelines()可以是序列,所以我们使用writelines()。
17行代码是关闭文件。这个,你记得不要把括号丢掉就好。
这个小练习里,我们增加了一些新的函数用法,并不是很难,只是对你来说暂时还有些陌生,但它们与我们学过的函数其实都有联系,或是用法大有相似之处,你只需要熟悉它,等要用的时候翻出来就好啦。
而且,相比于我们已经翻越过的几座大山,也就是前几个项目实操关卡,这个小练习应该只能算一个轻轻松松就能越过的小山坡,对吧?
好,以上就是本关的内容啦~课程就讲到这里,不要小看这两大块知识,要多多复习噢!去做练习吧!