JavaWeb之一直摆,一直赶
注解:


注解如果设置了参数的话最后设置默认值,不然容易报错,而且在设置默认值的时候:

自定义注解:
元注解:
对其他注解做出注解
常用元注解:
@Target:用于描述注解的使用范围:
//比如这样一个注解就只能用于方法了,如果不是用于方法前的话就会报错
public @interface MyAnnotation01 {
@Target(value= ElementType.METHOD)
public @interface XMZAnnotation
{
}
}@Retention用于描述注释的生命周期:一般用的最多的就是RetentionPolicy.RUNTIME
反射:
概念:
是指可以在运行期间加载,探知,使用完全未知的类,对于任意一个已加载的类,都能知道和调用它的任意属性和方法;(反射机制会造成性能问题,使性能比较慢,低,如果想要提升性能,可以根据自身程序来将setAccessible方法设为true,跳过安全检查)
核心代码:(同样一个Class类只会被加载一次,也就是说,如果用两个不同的Class对象来加载同一个类,得到的其实就是同一个类)
Class clazz=Class.forName("annotation.XMZstudent");常见作用:

获取Class类的途径:
1.通过加载获取
Class clazz=Class.forName(path);
2.通过类的class属性直接获取
Class clazz=String.class;
3.通过类的对象获取
String path="reflection.User";
Class clazz= path.getClass();
注意:对于一个类来说,其实它对应的Class对象里面包含了多个class类,其中所有基本类型在一个,同类型的,同一维度数组在一个,注解在接口类,等等;
获取类的属性信息:
public static void main(String[]args)
{
String path="reflection.User";
try {
Class clazz=Class.forName(path);
System.out.println(clazz.getName());//获得包名加类名
System.out.println(clazz.getSimpleName());//获得类名
//获取属性信息:
//如果用的是getField方法返回的是属性数组,但是都必须是public,获取不到其他修饰词的属性
//如果用的是getDeclaredFields返回的是所有属性
//单个的可以用getDeclaredField("属性名")
Field []fields=clazz.getDeclaredFields();
for (Field f:fields)
{
System.out.println("属性"+f);
}
//获取方法信息
Method []methods=clazz.getDeclaredMethods();
Method m01=clazz.getDeclaredMethod("getUname",null);
//如果方法有参,必须传递方法对应的class对象
Method m02= clazz.getDeclaredMethod("setUname", String.class);
for (Method m:methods)
{
System.out.println("方法"+m);
}
//获取构造器信息
//获取构造器和获取方法差不多
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
}动态操作:
1)属性,方法,构造器:
public static void main(String[]args)
{
String path="reflection.User";
try {
Class clazz=Class.forName(path);
//通过反射API调用构造方法,构造对象
User u=(User) clazz.newInstance();//其实是调用了User的无参构造方法,所以说javabean必须要有无参构造方法
System.out.println(u);
//指定相关构造器
Constructorc=clazz.getDeclaredConstructor(int.class,int.class,String.class);
User u2=c.newInstance(1001,12,"小麻子");
System.out.println(u2.getUname());
//通过反射API调用普通方法
User u3=(User) clazz.newInstance();
Method method=clazz.getDeclaredMethod("setUname", String.class);
method.invoke(u3,"小饺子");
System.out.println(u3.getUname());
//通过反射API操作属性
Field field=clazz.getDeclaredField("uname");
//操作私有属性需要先设置权限
field.setAccessible(true);//让这个属性不需要做安全检查直接可以访问
field.set(u3,"小卷卷");//通过反射直接写属性
System.out.println(u3.getUname());
System.out.println(field.get(u3));
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
} 2)注解和泛型:
了解小知识:java通过擦除泛型来的机制来引入泛型,仅给编译器使用,一旦编译完成就会擦除有关类型,所以无法通过反射直接获取泛型;
了解一下:
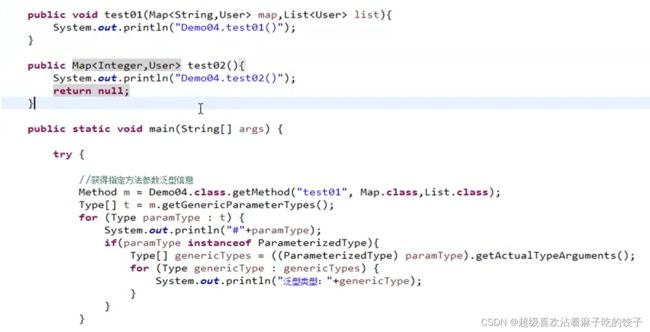

对于注解要分为三部分:
//主要程序:
package annotation;
import java.lang.annotation.Annotation;
import java.lang.reflect.Field;
public class Demo001 {
public static void main(String []args)
{
try {
Class clazz=Class.forName("annotation.XMZstudent");
//获得类上方的所有注解
Annotation[] annotations=clazz.getAnnotations();
for (Annotation a:annotations)
{
System.out.println(a);
}
//获得类指定的注解
XMZtable st=(XMZtable)clazz.getAnnotation(XMZtable.class);
System.out.println(st.value());
//获得类的属性的注解
Field f= clazz.getDeclaredField("studentName");
XMZfield xmzfield=f.getAnnotation(XMZfield.class);
System.out.println(xmzfield.columnName()+"-->"+xmzfield.type()+"-->"+xmzfield.length());
} catch (Exception e) {
e.printStackTrace();
}
}
}
两个注解定义:
package annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(value=ElementType.TYPE )
@Retention(RetentionPolicy.RUNTIME)
public @interface XMZtable {
String value();
}
package annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(value= ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface XMZfield {
String columnName();
String type();
int length();
}
一个对象类
package annotation;
@XMZtable("tb_student")
public class XMZstudent {
@XMZfield(columnName ="id",type="int",length=10)
private int id;
@XMZfield(columnName ="sname",type="varchar",length=10)
private String studentName;
@XMZfield(columnName ="age",type="int",length=3 )
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getStudentName() {
return studentName;
}
public void setStudentName(String studentName) {
this.studentName = studentName;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
动态编译:
public class Demo01 {
public static void main(String[]args)
{
//通过文件路径来编译文件
JavaCompiler compiler= ToolProvider.getSystemJavaCompiler();
int result=compiler.run(null,null,null,"D:/clientsend/helloWorld.java");
System.out.println(result==0?"编译成功":"编译失败");
//也可通过字符串编译代码
//通过IO流将字符串存储成一个临时文件,然后调用动态编译方法
//动态运行编译好的类,通过命令行,启动新的线程运行
// Runtime runtime=Runtime.getRuntime();
// try {
// Process process=runtime.exec("java -cp D:/clientsend helloWorld");
// InputStream in=process.getInputStream();
// BufferedReader reader=new BufferedReader(new InputStreamReader(in));
// String info="";
// while((info=reader.readLine())!=null)
// {
// System.out.println(info);
// }
//
// } catch (IOException e) {
// e.printStackTrace();
// }
//通过反射加载类的main方法
URL[]urls= new URL[0];
try {
urls = new URL[]{new URL("file:/"+"D:/clientsend/")};
URLClassLoader loader=new URLClassLoader(urls);
Class c=loader.loadClass("helloWorld");
//通过加载类的main方法
//由于main方法是静态方法,不需要对象来调,所以第一个参数是null
c.getMethod("main",String[].class).invoke(null,(Object) new String[]{});
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
}
}
Java脚本引擎:
简介:
使得java应用程序可以通过一套固定的接口与各种脚本引擎交互,从而达到在java平台上调用各种脚本语言的目的,可以把一些复杂异变的业务逻辑交给脚本语言处理,这又大大提高了开发效率;
public static void main(String[]args)
{
//获取脚本引擎对象
ScriptEngineManager sem=new ScriptEngineManager();
ScriptEngine engine= sem.getEngineByName("javascript");
//定义变量,存储到引擎上下文中
engine.put("msg","gaoqi is a good man");
String str="var user={name:'gaoqi',age:18,schools:['清华大学','北京大学']};";
str+="print(user.name);";
//执行脚本
try {
engine.eval(str);
engine.eval("msg='sxt is a good school';");
System.out.println(engine.get("msg"));
} catch (ScriptException e) {
e.printStackTrace();
}
//定义函数
try {
engine.eval("function add(a,b){var sum=a+b;return sum;}");
} catch (ScriptException e) {
e.printStackTrace();
}
//取得调用接口
Invocable jsInvoke=(Invocable) engine;
Object result1= null;
try {
//执行脚本中定义的方法
result1 = jsInvoke.invokeFunction("add",new Object[]{11,23});
} catch (ScriptException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
System.out.println(result1);
//导入其他的java包,使用其他的java类,其他可详细了解Rhino的语法
String jsCode="var list=java.util.Arrays.asList([\"北京大学\",\"清华大学\"]);";
try {
engine.eval(jsCode);
} catch (ScriptException e) {
e.printStackTrace();
}
Listlist2=(List) engine.get("list");
for(String temp:list2)
{
System.out.println(temp);
}
//执行一个js文件,将js文件置于项目的src下即可,还不能放包下了
URL url=Demo01.class.getClassLoader().getResource("test.js");
try {
FileReader fr=new FileReader(url.getPath());
engine.eval(fr);
fr.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (ScriptException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} maven:
概念:
是一个项目管理和构建工具
作用:
方便依赖管理
统一的项目结构
标准的项目构建流程
坐标:
Maven中的坐标是资源的唯一标识,通过该坐标可以唯一定位资源位置,通过坐标引入项目所需要的依赖

导入Maven项目:
点击ideal右上角Maven的加号:

选择要导入的maven的pom.xml文件,当然如果选择的是本身肯定不Ok啦,在导入这个之前,现将对应的项目移到该项目文件夹下,就导入成功了;
移除Maven项目:
右键maven项目点击remove module
然后再打开对应项目的磁盘文件,删除项目文件夹就可以了;
依赖管理:
ch.qos.logback
logback-classic
1.2.10
如果要引入的依赖是没有在本地仓库的,不了解的话可以去官网查看:Maven Repository: Search/Browse/Explore (mvnrepository.com)
同时maven会连接远程仓库或是中央仓库然乎下载依赖:
依赖传递:
直接依赖:在当前项目中通过依赖配置建立的依赖关系;
间接依赖:被依赖的资源如果依赖其他资源,当前项目简介以来其他资源;
(切记不要循环依赖;)
查看依赖关系的方法:点击到pom.xml文件右键点击diagrams:
如果某个项目不想要某个间接依赖,这时候就有了排除依赖:排除依赖的时候是不需要指定版本的;
ch.qos.logback
logback-classic
1.2.10
ch.qos.logback
logback-classic
依赖范围:
依赖的jar包默认情况下是可以在任何地方使用的:可以通过
主程序范围有效;(main文件夹范围有效)
测试程序范围有效:(test文件夹范围内)
是否参与打包运行(package指令范围内)

生命周期:
Maven中有三套独立的生命周期:
clean:清理工作
default:核心工作:编译,测试,打包,安装,部署
site:生成报告,发布站点等

主要关注三套里面的这几个阶段:在同一套生命周期中,运行后面的阶段,前面的阶段都会运行

------------------------------------这里是补一补Java知识---------------------------------------------
Junit:
才发现之前没有学单元测试,现在补上:java里面单元测试就是针对单个Java方法的测试:
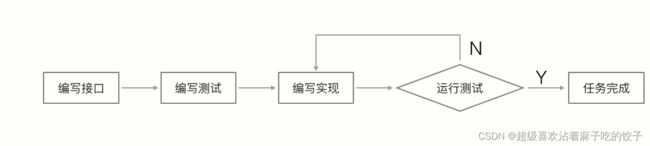
单元测试的好处:
确保单个方法运行正常;
如果修改了方法代码,只需确保其对应的单元测试通过;
测试代码本身就可以作为示例代码;
可以自动化运行所有测试并获得报告;
用junit测试框架的特点:

导入相关jar包并配置好之后,就可以测试相关的类里面的方法了,这里分为两种,一种是普通项目,另一种是maven项目:
普通项目:
在要测试的类里面右键并点击generate

然后点击test :

然后配置有关版本和勾选要测试的方法就好了; 然后编写要测试的代码就行,只需要从要被测试的类里面引入该方法就可以,并不需要重新敲代码;(具体方法在maven'项目里面介绍,这里是差不多的)
maven项目:
先在pom.xml里面引入Junit依赖,我写的是这个:
junit
junit
4.12
test
然后再绿色的里面创建测试的类:

可以是引入,也可以是自己编写; 在maven里面测试有两种方法测试:
方法1:方法边上的小箭头,即可测试;测试结果会显示在控制台:包括所用时间和结果(两个箭头叠加在一起表示测试的是这个类里面的所有方法都测试)
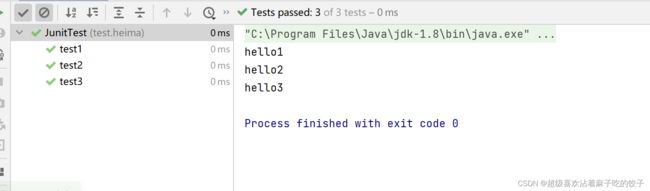

还有就是一种maven的特殊测试方式,点击右边的maven:
 点击里面的lifecycle也就是生命周期,会有一个test,点击之后,测试结果就会显示在控制台上,但是和上面不同的是:这里是测试所有的测试类,兵器他左侧控制台测试的时间包括了经过test之前还必须经过的生命周期所用的时间:
点击里面的lifecycle也就是生命周期,会有一个test,点击之后,测试结果就会显示在控制台上,但是和上面不同的是:这里是测试所有的测试类,兵器他左侧控制台测试的时间包括了经过test之前还必须经过的生命周期所用的时间:

SpringBoot入门级开发:
步骤:具体参考:Day04-10. Web入门-SpringBootWeb-快速入门_哔哩哔哩_bilibili
1.创建springboot工程,填写模块信息,勾选web开发相关依赖;
2.传建请求处理类,添加请求处理方法hello,并添加注解;
3.运行启动类,打开浏览器测试;
HTTP协议:
概述:
超文本传输协议,规定了浏览器和服务器之间数据传输的规则;
特点:

请求格式:
请求格式里面的第一行成为请求行,包括请求方式,请求资源路径,请求协议版本
中间是请求头,下面是有关表格:

最后一部分是请求体:
get请求数据在请求行,所以就没有请求体,但是post请求方式在请求体,所以就有请求体;
响应格式:
响应行:分为三部分:用空格分开来,分别是(协议和协议版本)(状态码)(描述状态码)
状态码和响应头的类型
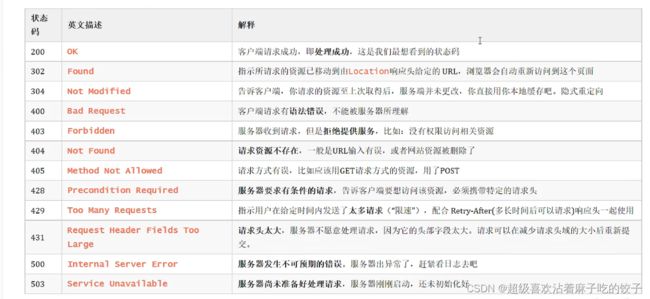

响应头:描述相应信息
响应体:结合前端代码即可展现相关的效果
三个最常用的响应状态码:200,处理成功,404,请求资源不存在,500,服务器不可预期的错误;
tomcat:
Web服务器:
1.对HTTP协议操作的进行封装,简化web程序开发
2.部署web项目,对外提供网上信息浏览服务
简介:
tomcat是一个轻量级的web服务器,支持servlet,jsp等少量javaEE
规范:
所以它也被称为web容器,servlet容器。
注意事项:
如果在ideal里面生成SpringBoot项目的话,选择jar包才会自带tomcat,war包不会

基本使用:
部署项目只需要将项目放到webapps目录下即可部署完成
实际应用:
创建SpringBoot框架的起步依赖:

servlet :
概念:
java提供的一门动态web资源开发技术。是javaEE的规范之一,是一个接口
web项目结构:

maven web项目打包成war包
入门级开发流程:
1.创建web项目,导入Servlet依赖坐标;
注意:创建web项目是有讲究的:具体参考:11-Servlet简介&快速入门_哔哩哔哩_bilibili
建议用第二种方法,第一种方法总是容易出问题 ,第二种方法创建完项目后重启一下idea再操作;注意每次操作完都要更新pom.xml文件
4.0.0
org.example
web-demo
1.0-SNAPSHOT
javax.servlet
javax.servlet-api
3.1.0
provided
8
8
org.apache.tomcat.maven
tomcat7-maven-plugin
2.2
2.写一个类实现 servlet接口,重写接口中所有方法;
public class ServletDemo001 implements Servlet {
@Override
public void init(ServletConfig servletConfig) throws ServletException {
}
@Override
public ServletConfig getServletConfig() {
return null;
}
@Override
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
//Servlet被访问的时候service方法会自动被执行
System.out.println("hello servlet");
}
@Override
public String getServletInfo() {
return null;
}
@Override
public void destroy() {
}
}
3.在类上使用@WebServlet注解,配置Servlet访问路径;
4.启动Tomcat,在浏览器中输入URL访问该Servlet
执行流程:
1.Servlet由web服务器创建,Servlet方法由web服务器调用;
2.我们自定义写的Servlet类必须实现Servlet接口,并复写其方法,而Servlet里面由Servlet方法
生命周期:
1.加载和实例化

默认是负整数
2.初始化,执行Servlet方法里面的init方法,只执行一次,在创建完Servlet对象之后
3.请求处理,可执行多次,每次访问对应url路径的时候就执行;
4.服务终止,执行一次,Servlet销毁前执行;
其他方法:
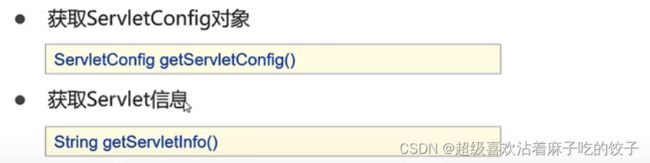
体系结构:
对于http协议,可以采用更加简便的实现类来做:继承该类,重写doGet和doPost方法;
这里来了解一下它的原理:
1.为什么要分两种方式来处理请求,由于不同的请求方式请求资源的位置是不一样的,这时候如果是Servlet也就是用原始的Servlet实现来写就要有以下步骤:
1.获取request并强转为HttpServletRequest类型;
2.根据request获取请求方式
3.根据不同的方式进行不同的处理
这时候HttpServlet出现就大大简化了这些步骤;
Servlet urlPattern配置:
1.一个Servlet可以配置多个访问路径@WebServlet(urlPatterns={"/demo1","demo2"})
urlPattern配置规则
1.精确匹配
2.目录匹配

3.扩展名匹配

4.任意匹配:/和/*,后者优先级更高,它们的区别在于,tomcat里面配置了前者,如果有/*就会覆盖里面的DefaultServlet,当其他的url-pattern都匹配不上的时候会走这个Servlet,而这个默认的会处理静态资源的访问,如果覆盖掉了静态资源就访问不了了,所以一般不用自己设置任意匹配
注意:前面四个匹配的优先级依次递减;
XML配置Servlet:
步骤:
在web.xml里面配置
1.编写Servlet类
2.在web.xml中配置该Servlet()

()
Ajax:

原生Ajax:
1.准备数据地址:
2.创建XMLHttpsRequest对象,用于和服务器交换数据
3.向服务器发送请求:
4.获取服务器的响应数据:
这里注意两个XMLHttpsRequest的两个数据:readyState为4表示请求已完成且响应已就绪,status为200表示请求已完成;

Axios:
对原生的Ajax进行分装,简化书写,用于快速开发;

可以根据请求方式别名来简化请求:

mysql:
基本查询:(稍微写一点)
如果要查询某个表里面的多有字段,有两种方式,
SELECT 要查询的字段名(如果有多个用逗号隔开) FROM 要查询的表名SELECT * FROM 表名但是 第二种性能较低
查询字段并起别名:(注意:如果这个字段有特殊字符的话,可以用引号括起来,但是这样会将引号带进去)
SELECT 要查询的字段 空格(as也可以)FROM 表名去除重复的查询:
SELECT distinct 字段 FROM 表名条件查询:(补上之前没学的)
对于模糊查询like关键字,后面跟上单引号其中_表示一个字符%标识任意个字符,比如要求查询某表里面某个字段的两个字的:
SELECT 字段名 FROM 表名 WHERE 该字段名 like '__';如果要求在名为person的表里面查询字段名为name并且姓张的人的信息:
SELECT *FROM WHERE name like '张%';聚合函数:
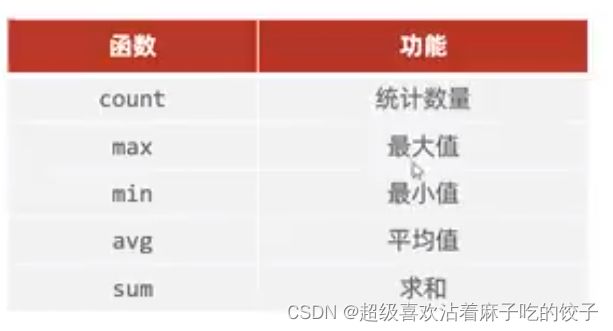
null不参与所有聚合函数的运算
统计某字段数量:(注意:不对null进行运算)
1.SELECT COUNT(字段) FROM 表名
2.SELECT COUNT(常量) FROM 表名(只要不为null就可以)
3.SELECT COUNT (*)FROM 表名(推荐使用,mysql数据库底层专门做了优化)
统计字段最值:
SELECT MIN/MAX(字段名) FROM 表名
统计字段平均值:(有小数)
SELECT AVG(字段名) FROM 表名
求字段和
SELECT SUM(字段) DROM 表名
分组查询:
假如有一个具体的职工信息表,然后要完成下面这些需求:(分组查询包含的字段主要包括两类,一类是分组字段,一类是聚合函数,并且在where之后是不可以用聚合函数的)
根据性别分组,统计男性和女性员工的数量
SELECT gender,count(*) FROM 表名 GROUP BY gender;这样得到的大概就是这样的数据:

注意:where和having的区别

执行顺序:where>聚合函数>having
排序查询:
升序:ASC(默认),降序DESC
基本格式:基本查询/条件查询/分组查询 ORDER BY 字段名 ASC/DESC
现在有一个需求:在一个公司员工信息表里面,根据入职信息对公司员工进行升序排序,如果入职时间相同,再按照更新时间进行降序排序
SELECT * FROM 表名 ORDER BY 入职时间 ASC, 更新时间 DESC;注意:对于多字段排序,只有前面的字段值相同后面的字段排序才会生效;
分页查询:
基本格式:(注意:分页查询是数据库的方言,不同数据库有着不同的实现。如果查询的是第一页数据,起始索引可以省略)
SELECT 字段列表 FROM 表名 limit 起始索引,查询记录数;
起始索引的公式:(页码-1)*每页展示的记录数=起始索引
DQL练习案例:
案例一:根据输入条件,查询第一页数据,每页显示十条记录,输入条件:姓名张,性别男,入职时间2000-01-01 2015-12-31
同时,页面开发规则为:
这里只要求书写上面的一条sql语句:
SELECT *FROM 表名 WHERE name LIKE '%张%' AND gender=1 AND entrydate BETWEEN '2000-01-01' AND '2015-12-31' ORDER BY DESC LIMIT 10
//注意先排序再分页案例二:
根据需求完成员工信息的统计:
1.员工信息的性别统计:

SELECT if(gender=1,'男性员工','女性员工') 性别,count(*) FROM 表名 GROUP BY gender;2.员工职位信息的统计:
![]()
SELECT
(CASE job WHEN 1 THEN '班主任'
WHEN 2 THEN '讲师'
WHEN 3 THEN '学工主管'
WHEN 4 THEN '教研主管'
ELSE '未分配职位' END)
COUNT (*)
FROM 表名 GROUP BY job;
多表设计:
1)一对多:
要将两个表关联起来要有外键约束:(如果使用外键约束的话会让数据迁移变得很麻烦)
外键约束的语法:

物理外键的缺点:
1.会影响增删改的效率;
2.仅用于单节点数据,不适用于分布式集群场景
3.容易引发数据库的死锁问题,消耗性能
所以在开发中用的逻辑外键;
2)一对一:
用于·单表拆分,将一张表的基础字段放在一张表里面,其他字段放在另一张表里面以提升操作效率;
通过在任意一方添加外键,关联另外一方的主键,并且设置外键为唯一的
3)多对多:
建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
多表查询:
内连接:
一般形式:(如果两个表中判断条件有为空的那么就查询不出来)
SELECT * FROM 表一,表二 WHERE 某个条件;上面的也称为隐式内连接,下面是显示内连接:(inner可以省略)
SELECT 字段 FROM 表一 INNER JOIN 表二 ON 连接条件外连接:
注意:这里说的左连接和右连接指的是保留的那部分,比如下面的左外连接,就是查询左边表1的所有数据
左外连接:
SELECT * FROM 表一 LEFT JOIN 表二 ON 联查条件
右外连接:
SELECT * FROM 表一 LEFT JOIN 表二 ON 联查条件子查询:
有些查询里面的某个条件是根据其他sql语句来实现的,最常见的就是查询语句;

标量子查询:
SELECT * FROM 表1 WHERE 字段=/其他运算符也可以 (另一个查询);列子查询:
SELECT *FROM 表1 IN/NOT IN(另一个查询条件);行子查询:
SELECT* FROM 表名 WHERE (字段名(多个用逗号隔开))=(查询语句);表子查询:
把子查询作为一张临时表来使用
事务:
概念:
事务是一组操作的集合,它是一个不可分割的工作单位,会把所有的操作作为一个整体一起向系统提交或撤销系统操作请求;
注意:默认MySQL语句里面事务是自动提交的,也就是说,当执行一条DML语句的时候,MySQL会立即隐式提交事务
操作事务:

说一下删除数据事务提交和没有提交的区别,如果一组事务只是执行但是没有提交的话那么在之前的表里面还是存在的,但是在当前页面搜索却已经查不到了,如果提交了就都看不见了;然后回滚也差不多,就是如果执行了事务里面其中有一条是出错了的,去查询的话会发现数据有的执行有的没有,但是如果这时候回滚了的话就可以保持所有数据都没有被改动也就是返回原来的值;
四大特性:(ACID)
原子性:不可再分,要么全部成功,要么全部失败;
一致性:事务完成时,(提交和回滚后都算是完成)必须使所有的数据都保持一致状态;
隔离性:保证事务不受外部并发操作的影响的独立环境下运行,隔离级别可以设置,但是级别越高越安全,但是性能越低;
持久性:事务一旦提交或者是回滚,对数据库中的数据改变就是永久;
索引:
帮助数据库高效获取数据的数据结构;

结构:
在MySQL数据库里面如果没有特别说明,索引的结构我们默认指的是B+Tree结构;
对于b+树索引,要注意以下几点:
1每一个节点,可以存储多个key(有n个key,就有n个指针);
2所有数据都存储在叶子节点。非叶子节点仅用于索引数据;
叶子节点形成了一颗双向链表,便于数据的排序及区间范围查询;
语法:
创建:CREATE (如果要创建唯一的索引就加上一个UNIQUE) INDEX 索引名 ON 表名(字段名) ;
查看:SHOW INDEX FROM 表名;
删除:DROP INDEX 索引名 ON 表名;
注意:主键会自动帮我们创建索引,而且主键索引的性能是最高的,一旦给一个字段创建了唯一约束,会自动创建一个索引,叫做唯一索引
这几天不停的赶进度,终于赶了这么多了,然后一看字数,我吓一跳,第一次创造高达一万字的文章好开心!!
心灵鸡汤来咯:
偶尔也羡慕别人更灿烂夺目有耀眼的光,自己却一身暗淡没有方向。但日子还长,机会也还会有的,不用总是匆匆忙忙那么慌张,认认真真生活就好,努力脚踏实地就好。