数据结构与算法(六)树的入门
树的基本定义
树是我们计算机中非常重要的一种数据结构,同时使用树这种数据结构,可以描述现实生活中的很多事物,例如家谱、单位的组织架构、等等。
树是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
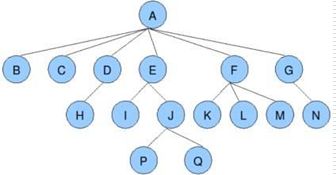
树具有以下特点:
- 每个结点有零个或多个子结点;
- 没有父结点的结点为根结点;
- 每一个非根结点只有一个父结点;
- 每个结点及其后代结点整体上可以看做是一棵树,称为当前结点的父结点的一个子树;
树的相关术语
- 结点的度:一个结点含有的子树的个数称为该结点的度。
- 树的度:树中所有结点的度的最大值。
- 叶子结点:度为0的结点称为叶结点,也可以叫做终端结点。
- 分支结点:度不为0的结点称为分支结点,也可以叫做非终端结点。
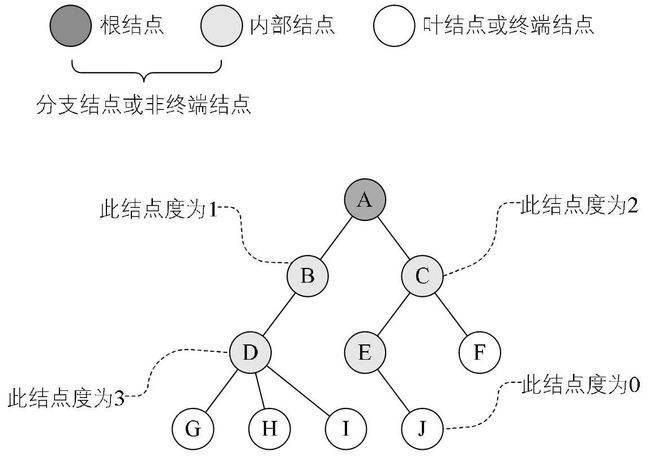
- 结点的层次:从根结点开始,根结点的层次为1,根的直接后继层次为2,以此类推。
- 结点的层序编号:将树中的结点,按照从上层到下层,同层从左到右的次序排成一个线性序列,把他们编成连续的自然数。
- 树的高度(深度):树中结点的最大层次。
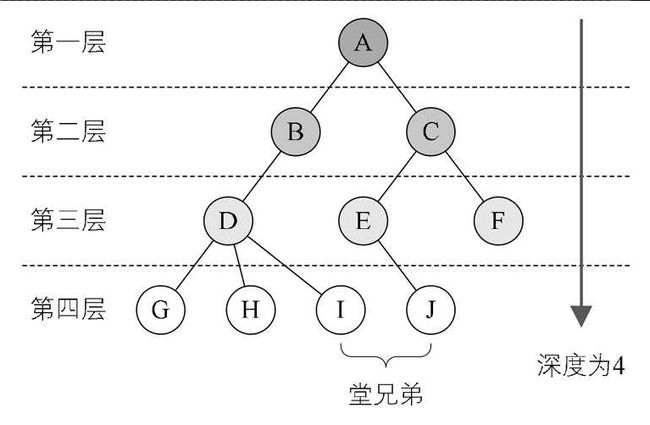
- 森林:m(m>=0)个互不相交的树的集合,将一颗非空树的根结点删去,树就变成一个森林;给森林增加一个统一的根结点,森林就变成一棵树
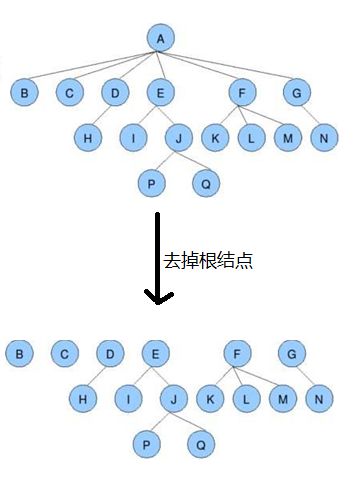
- 孩子结点:一个结点的直接后继结点称为该结点的孩子结点。
- 双亲结点(父结点):一个结点的直接前驱称为该结点的双亲结点。
- 兄弟结点:同一双亲结点的孩子结点间互称兄弟结点。

二叉树的基本定义
二叉树就是度不超过2的树(每个结点最多有两个子结点)
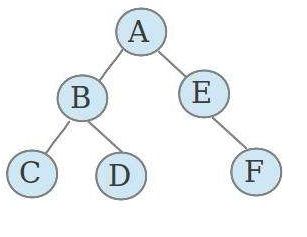
满二叉树
在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
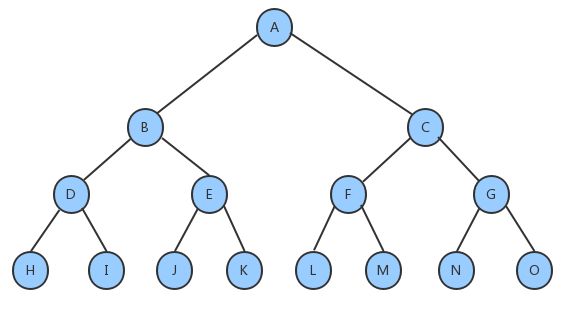
完全二叉树
叶子节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
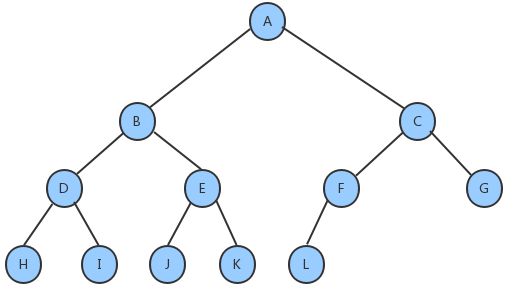
满二叉树一定是一棵完全二叉树,但完全二叉树不一定是满的。
判断某二叉树是否是完全二叉树
完全二叉树的特点:
- 叶子结点只能出现在最下两层。
- 最下层的叶子一定集中在左部连续位置。
- 倒数二层,若有叶子结点,一定都在右部连续位置。
- 如果结点度为1,则该结点只有左孩子,即不存在只有右子树的情况。
- 同样结点数的二叉树,完全二叉树的深度最小。
给每个结点按照满二叉树的结构逐层顺序编号,如果编号出现空档,就说明不是完全二叉树,否则就是。
二叉查找树的创建
二叉树的结点类
根据对图的观察,我们发现二叉树其实就是由一个一个的结点及其之间的关系组成的,按照面向对象的思想,我们设计一个结点类来描述结点这个事物。
结点类设计
| 类名 | Node |
|---|---|
| 构造方法 | Node(K key, V value, Node:创建Node对象 |
| 成员变量 | private Node:记录左子结点private Node:记录右子结点private K key:存储键private V value:存储值 |
结点类代码实现
/**
* 二叉查找树结点
*
* @param
* @param
*/
@NoArgsConstructor
@AllArgsConstructor
@Data
private static class Node<K, V> {
private K key;
private V value;
private Node<K, V> left;
private Node<K, V> right;
}
二叉查找树设计
| 类名 | BinaryTree |
|---|---|
| 构造方法 | BinaryTree():创建BinaryTree对象 |
| 成员变量 | private Node:记录根结点private int n:记录树中元素的个数 |
| 成员方法 | public void put(K key,V value):向树中插入一个键值对private Node put(Node:给指定树x上,添加键一个键值对,并返回添加后的新树public V get(K key):根据key,从树中找出对应的值private V get(Node:从指定的树x中,找出key对应的值public void delete(K key):根据key,删除树中对应的键值对private Node delete(Node:删除指定树x上的键为key的键值对,并返回删除后的新树public int size():获取树中元素的个数 |
二叉查找树代码实现
public class BinaryTree<K extends Comparable<K>, V> {
/**
* 记录根结点
*/
private Node<K, V> root;
/**
* 记录树中元素的个数
*/
private int n;
public BinaryTree() {
}
/**
* 插入一个键值对
*/
public void put(K key, V value) {
root = put(root, key, value);
}
/**
* 1.如果当前树中没有任何一个结点,则直接把新结点当做根结点使用
* 2.如果当前树不为空,则从根结点开始:
* 2.1 如果新结点的key小于当前结点的key,则继续找当前结点的左子结点
* 2.2 如果新结点的key大于当前结点的key,则继续找当前结点的右子结点
* 2.3 如果新结点的key等于当前结点的key,则树中已经存在这样的结点,替换该结点的value值即可
*/
private Node<K, V> put(Node<K, V> x, K key, V value) {
if (x == null) {
n++;
return new Node<>(key, value, null, null);
}
var cmp = key.compareTo(x.key);
if (cmp > 0) {
// 找右子树
x.right = put(x.right, key, value);
} else if (cmp < 0) {
// 找左子树
x.left = put(x.left, key, value);
} else {
// 替换值
x.value = value;
}
return x;
}
public V get(K key) {
return get(root, key);
}
private V get(Node<K, V> x, K key) {
if (x == null) {
return null;
}
var cmp = key.compareTo(x.key);
if (cmp > 0) {
return get(x.right, key);
} else if (cmp < 0) {
return get(x.left, key);
} else {
return x.value;
}
}
public void delete(K key) {
delete(root, key);
}
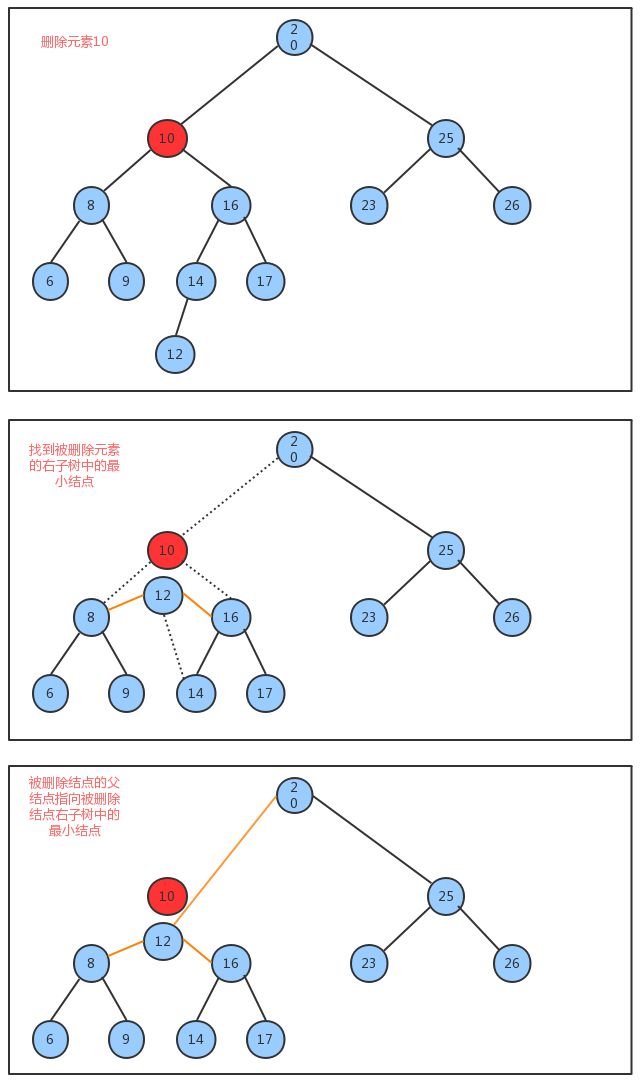
/**
* 1. 找到被删除结点
* 2. 找到被删除结点右子树中的最小结点minNode
* 3. 删除右子树中的最小结点
* 4. 让被删除结点的左子树称为最小结点minNode的左子树,让被删除结点的右子树称为最小结点minNode的右子树
* 5. 让被删除结点的父节点指向最小结点minNode
*/
private Node<K, V> delete(Node<K, V> x, K key) {
if (x == null) {
return null;
}
var cmp = key.compareTo(x.key);
if (cmp > 0) {
// 找右子树
x.right = delete(x.right, key);
} else if (cmp < 0) {
// 找左子树
x.left = delete(x.left, key);
} else {
// 先找到右子树中最小的结点
n--;
if (x.right == null) {
return x.left;
}
if (x.left == null) {
return x.right;
}
// 遍历获取右子树最左结点
var minNode = min(x.right);
// 删除右子树中最小的节点
var n = x.right;
while (n.left != null) {
if (n.left.left == null) {
n.left = null;
} else {
n = n.left;
}
}
// 让x结点的左子树成为minNode的左子树
minNode.left = x.left;
// 让x结点的右子树成为minNode的右子树
minNode.right = x.right;
// 让x节点的父节点指向minNode
x = minNode;
}
return x;
}
public int size() {
return n;
}
public Node<K, V> min() {
return min(root);
}
private Node<K, V> min(Node<K, V> x) {
if (x.left != null) {
return min(x.left);
} else {
return x;
}
}
public Node<K, V> max() {
return max(root);
}
private Node<K, V> max(Node<K, V> x) {
if (x.right != null) {
return max(x.right);
} else {
return x;
}
}
/**
* 二叉查找树结点
*
* @param
* @param
*/
@NoArgsConstructor
@AllArgsConstructor
@Data
private static class Node<K, V> {
private K key;
private V value;
private Node<K, V> left;
private Node<K, V> right;
}
}
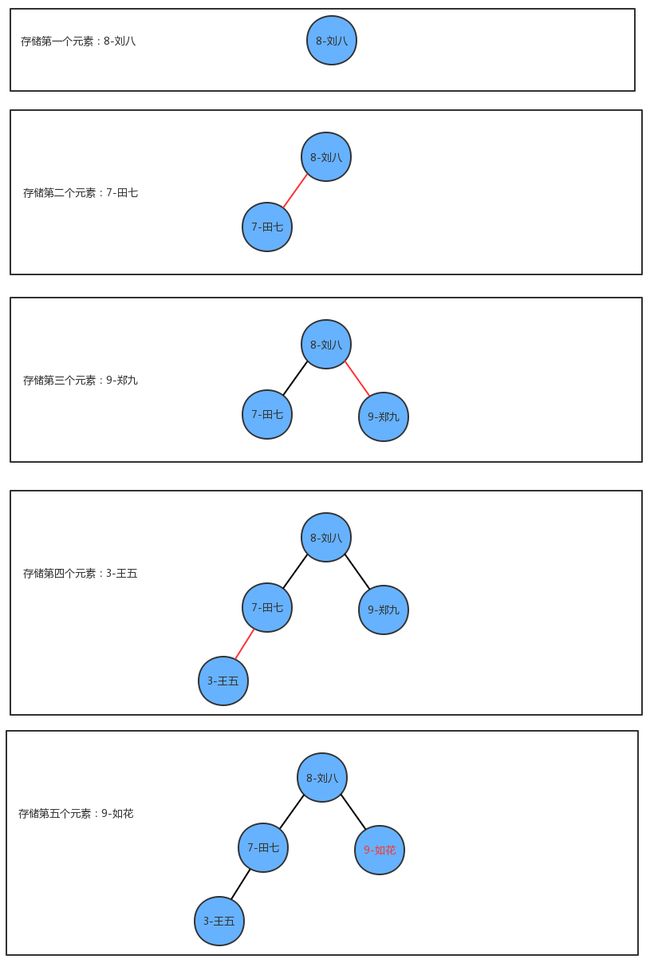
插入方法put实现思想
-
如果当前树中没有任何一个结点,则直接把新结点当做根结点使用
-
如果当前树不为空,则从根结点开始:
-
如果新结点的key小于当前结点的key,则继续找当前结点的左子结点;
-
如果新结点的key大于当前结点的key,则继续找当前结点的右子结点;
-
如果新结点的key等于当前结点的key,则树中已经存在这样的结点,替换该结点的value值即可。
-
查询方法get实现思想
从根节点开始:
- 如果要查询的key小于当前结点的key,则继续找当前结点的左子结点;
- 如果要查询的key大于当前结点的key,则继续找当前结点的右子结点;
- 如果要查询的key等于当前结点的key,则树中返回当前结点的value。
删除方法delete实现思想
- 找到被删除结点;
- 找到被删除结点右子树中的最小结点
minNode - 删除右子树中的最小结点
- 让被删除结点的左子树称为最小结点
minNode的左子树,让被删除结点的右子树称为最小结点minNode的右子树 - 让被删除结点的父节点指向最小结点
minNode
二叉树的基础遍历
很多情况下,我们可能需要像遍历数组数组一样,遍历树,从而拿出树中存储的每一个元素,由于树状结构和线性结构不一样,它没有办法从头开始依次向后遍历,所以存在如何遍历,也就是按照什么样的搜索路径进行遍历的问题。
我们把树简单的画作上图中的样子,由一个根节点、一个左子树、一个右子树组成,那么按照根节点什么时候被访问,我们可以把二叉树的遍历分为以下三种方式:
- 前序遍历:先访问根结点,然后再访问左子树,最后访问右子树
- 中序遍历:先访问左子树,中间访问根节点,最后访问右子树
- 后序遍历:先访问左子树,再访问右子树,最后访问根节点
如果我们分别对下面的树使用三种遍历方式进行遍历,得到的结果如下:

学习二叉树的遍历,一定要有递归思想,比如前序遍历,本质顺序是:根→左→右,先访问E,然后访问B,但是B也是一棵树,此时思维应该转换到以B为根结点的子树上,所以B下面是访问A。
前序遍历
根节点第一个(前面)访问,所以叫前序遍历
实现步骤:
- 把当前结点的key放入到队列中
- 找到当前结点的左子树,如果不为空,递归遍历左子树
- 找到当前结点的右子树,如果不为空,递归遍历右子树
/**
* 使用前序遍历,获取整个树中的所有键
*/
public Queue<K> preErgodic() {
var keys = new LinkedList<K>();
preErgodic(root, keys);
return keys;
}
/**
* 使用前序遍历,把指定树x中的所有键放入到keys队列中
*/
private void preErgodic(Node<K, V> x, Queue<K> keys) {
if (x == null) {
return;
}
// 把x结点的key放入queue
keys.add(x.key);
preErgodic(x.left, keys);
preErgodic(x.right, keys);
}
中序遍历
根节点在第二个(中间)访问,所以叫中序遍历
实现步骤:
- 找到当前结点的左子树,如果不为空,递归遍历左子树
- 把当前结点的key放入到队列中;
- 找到当前结点的右子树,如果不为空,递归遍历右子树
/**
* 使用中序遍历,获取整个树中的所有键
*/
public Queue<K> midErgodic() {
var keys = new LinkedList<K>();
midErgodic(root, keys);
return keys;
}
private void midErgodic(Node<K, V> x, Queue<K> keys) {
if (x == null) {
return;
}
midErgodic(x.left, keys);
// 把x结点的key放入queue
keys.add(x.key);
midErgodic(x.right, keys);
}
后序遍历
根节点在第三个(后面)访问,所以叫中序遍历
实现步骤:
- 找到当前结点的左子树,如果不为空,递归遍历左子树
- 找到当前结点的右子树,如果不为空,递归遍历右子树
- 把当前结点的key放入到队列中
/**
* 使用后序遍历,获取整个树中的所有键
*/
public Queue<K> postErgodic() {
var keys = new LinkedList<K>();
postErgodic(root, keys);
return keys;
}
private void postErgodic(Node<K, V> x, Queue<K> keys) {
if (x == null) {
return;
}
postErgodic(x.left, keys);
postErgodic(x.right, keys);
// 把x结点的key放入queue
keys.add(x.key);
}
二叉树的层序遍历
所谓的层序遍历,就是从根节点(第一层)开始,依次向下,获取每一层所有结点的值,有二叉树如下:
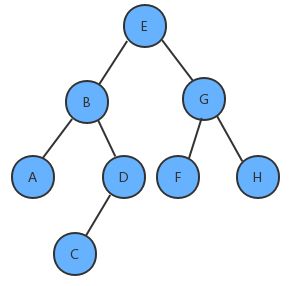
那么层序遍历的结果是:EBGADFHC
实现步骤:
-
创建队列,存储每一层的结点;
-
使用循环从队列中弹出一个结点:
-
获取当前结点的key;
-
如果当前结点的左子结点不为空,则把左子结点放入到队列中
-
如果当前结点的右子结点不为空,则把右子结点放入到队列中
-
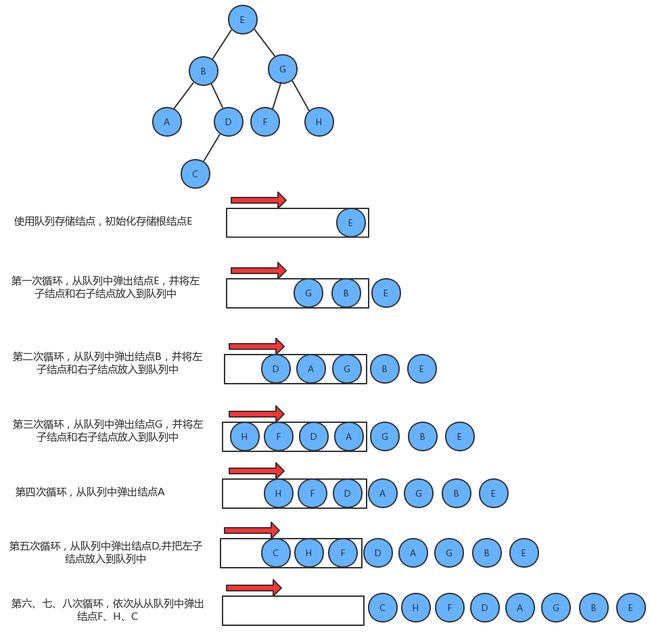
/**
* 层序遍历
* 1.创建队列,存储每一层的结点;
* 2.使用循环从队列中弹出一个结点:
* 2.1 获取当前结点的key;
* 2.2 如果当前结点的左子结点不为空,则把左子结点放入到队列中
* 2.3 如果当前结点的右子结点不为空,则把右子结点放入到队列中
*/
public Queue<K> layerErgodic() {
var keys = new LinkedList<K>();
var nodes = new LinkedList<Node<K, V>>();
nodes.add(root);
while (!nodes.isEmpty()) {
var node = nodes.pop();
keys.add(node.key);
if (node.left != null) {
nodes.add(node.left);
}
if (node.right != null) {
nodes.add(node.right);
}
}
return keys;
}
二叉树的最大深度问题
给定一棵树,请计算树的最大深度(树的根节点到最远叶子结点的最长路径上的结点数)
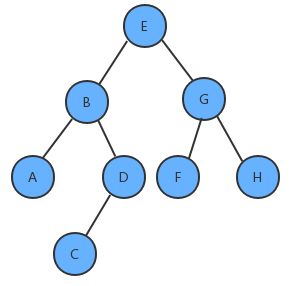
上面这棵树的最大深度为4。
实现步骤
- 如果根结点为空,则最大深度为0;
- 计算左子树的最大深度;
- 计算右子树的最大深度;
- 当前树的最大深度=左子树的最大深度和右子树的最大深度中的较大者+1
/**
* 计算整个树的最大深度
*/
public int maxDepth() {
return maxDepth(root);
}
/**
* 计算指定树x的最大深度
*/
private int maxDepth(Node<K, V> x) {
if (x == null) {
return 0;
}
var maxL = 0;
var maxR = 0;
// 计算左子树的最大深度
if (x.left != null) {
maxL = maxDepth(x.left);
}
// 计算右子树的最大深度
if (x.right != null) {
maxR = maxDepth(x.right);
}
// 比较左右子数的最大深度
return Math.max(maxL, maxR) + 1;
}
折纸问题
请把一段纸条竖着放在桌子上,然后从纸条的下边向上方对折1次,压出折痕后展开。此时折痕是凹下去的,即折痕突起的方向指向纸条的背面。如果从纸条的下边向上方连续对折2 次,压出折痕后展开,此时有三条折痕,从上到下依次是下折痕、下折痕和上折痕。
给定一 个输入参数N,代表纸条都从下边向上方连续对折n次,请从上到下打印所有折痕的方向。
例如:n=1时,打印: down;n=2时,打印: down down up
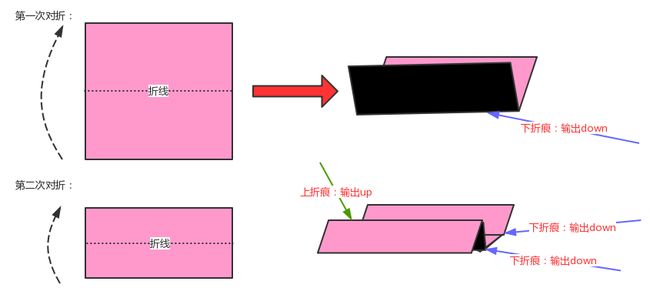
分析
我们把对折后的纸张翻过来,让粉色朝下,这时把第一次对折产生的折痕看做是根结点,那第二次对折产生的下折痕就是该结点的左子结点,而第二次对折产生的上折痕就是该结点的右子结点,这样我们就可以使用树型数据结构来描述对折后产生的折痕。
这棵树有这样的特点:
- 根结点为下折痕;
- 每一个结点的左子结点为下折痕;
- 每一个结点的右子结点为上折痕;
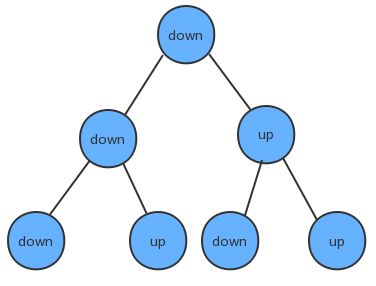
实现步骤
- 定义结点类
- 构建深度为n的折痕树;
- 第一次对折,只有一条折痕,创建根结点;
- 如果不是第一次对折,则使用队列保存根结点;
- 循环遍历队列:
- 从队列中拿出一个结点;
- 如果这个结点的左子结点不为空,则把这个左子结点添加到队列中;
- 如果这个结点的右子结点不为空,则把这个右子结点添加到队列中;
- 判断当前结点的左子结点和右子结点都不为空,如果是,则需要为当前结点创建一个值为
down的左子结点,一个值为up的右子结点。
- 使用中序遍历,打印出树中所有结点的内容;
public class PagerFolding {
/**
* 构建深度为n的折痕树
*
* @param n 深度
* @return 折痕树
*/
public static Node<String> createTree(int n) {
Node<String> root = null;
for (int i = 0; i < n; i++) {
if (i == 0) {
// 1.第一次对折,只有一条折痕,创建根结点;
root = new Node<>("down");
continue;
}
// 2.如果不是第一次对折,则使用队列保存根结点;
var nodes = new LinkedList<Node<String>>();
nodes.add(root);
//3.循环遍历队列:
while (!nodes.isEmpty()) {
//3.1从队列中拿出一个结点
var temp = nodes.pop();
//3.2如果这个结点的左子结点不为空,则把这个左子结点添加到队列中;
if (temp.left != null) {
nodes.add(temp.left);
}
//3.3如果这个结点的右子结点不为空,则把这个右子结点添加到队列中;
else if (temp.right != null) {
nodes.add(temp.right);
}
//3.4判断当前结点的左子结点和右子结点都不为空,如果是,则需要为当前结点创建一个值为down的左子结点,一个值为up的右子结点。
else {
temp.left = new Node<>("down");
temp.right = new Node<>("up");
}
}
}
return root;
}
/**
* 使用中序遍历打印结果
*
* @param x
*/
public static void printTree(Node<String> x) {
if (x == null) {
return;
}
if (x.left != null) {
printTree(x.left);
}
System.out.print(x.value + " ");
if (x.right != null) {
printTree(x.right);
}
}
/**
* 二叉查找树结点
*
* @param 值类型
*/
@NoArgsConstructor
@AllArgsConstructor
@Data
private static class Node<T> {
private T value;
private Node<T> left;
private Node<T> right;
public Node(T value) {
this.value = value;
}
}
}
测试
class PagerFoldingTest {
@Test
void createTree() {
var pagerFolding = PagerFolding.createTree(4);
// down down up down up down up
PagerFolding.printTree(pagerFolding);
}
}