mybatis学习笔记
Mybatis
- 1.概述
-
- 1.1mybatis初理解
- 2. 入门案例
-
- 2.1 测试准备
- 2.2 过程展示
-
- 2.2.1 数据库创建、新增
- 2.2.2 IDEA创建Maven工程
- 2.2.3 导入相关的Maven依赖
- 2.2.4 创建类
- 2.2.5 使用JDBC完成查询
-
- 2.2.5.1 在Emp类中封装所有的员工信息, 代码如下:
- 2.2.5.2 查询yonghedb.emp表中的所有数据
- 2.2.6 使用Mybatis完成查询
-
- 2.2.6.1 创建并配置:mybatis-config.xml文件
- 2.2.6.2 创建并配置:EmpMapper.xml文件
- 2.2.6.3 提供一个 cn.ggs.pojo.Emp 类
- 2.2.6.4 完成 cn.ggs.MybatisDemo1中的代码, 并运行测试
- 2.2.7:总结与心得
- 2.2.8:拓展
- 3.常见问题总结
-
- 3.1 在xml文件中书写代码时没有代码提示
- 3.2 Emp类中添加了有参构造函数,但没有添加无参构造函数!
- 3.3 执行SQL语句时, namespace或id写错了, 找不到要执行的SQL语句就会报错!
- 3.4 mapper文件中标签的id值重复了
- 3.5 连接数据库的基本信息书写错误, 导致连接不上数据库
- 3.6 出现xml文件找不到异常
- 4.mybatis封装查询结果的过程:
-
- 4.1 过程分析
- 4.2 常见问题
-
- 4.2.1如果emp表中的列名 和 Emp对象中的属性名不相同, 查询的结果能封装到Emp对象中吗?
- 5.mybatis的增删改查操作
-
- 5.1 练习:
- 5.2 Log4j引入
-
- 5.2.1 初理解
- 5.2.2 环境配置
- 5.2.3 测试
-
- 5.2.3.1 输出到控制台
- 5.2.3.2 输出到文件
- 5.2.4 补充
- 5.3 Mybatis的占位符
-
- 5.3.1 概述
- 5.3.2 占位符初使用
- 5.3.3 占位符接收参数
-
- 5.3.3.1 #{}占位符
-
- 5.3.3.1.1 通过Map方式传参
- 5.3.3.1.2 通过POJO对象封装SQL参数进行传参
- 5.3.3.2 ${}占位符
- 5.4 Mybatis的动态SQL
-
- 5.4.1 引言:
- 5.4.2 入门案例
-
- 5.4.2.1 if、where标签
- 5.4.2.1 foreach标签
- 6.Mybatis的接口开发
-
- 6.1 概述
- 6.2 入门测试
-
- 6.2.1 mapper接口开发测试: 查询emp表中的所有员工信息
- 6.2.2 模拟mybatis提供的EmpMapper接口的实现类
- 7.Mybatis注解开发
-
- 7.1 概述
- 7.2 入门案例
-
- 7.2.1 在xml文件中引入接口的方式
- 7.2.2 练习
1.概述
1.1mybatis初理解
是什么:
mybatis是一个应用于持久层(数据库)的框架,它由Apache公司出品(就是做Tomcat的那家公司),有了mybatis之后就不用像之前学JDBC那样子,写一些繁琐又重复的代码,节省了时间,同时能够将数据库查询的结果交给java对象进行保存处理,提高了效率,并且JDBC没有连接池的概念,mybatis有连接池,总而言之,可以理解为mybatis就是对JDBC进行了封装并且优化,技术总在发展,令人不由得想起,大江东去,浪淘尽千古风流人物~
为什么要学:
- mybatis是当前主流框架SSM三大框架之一,很流行呗!
- mybatis有连接池的概念,便于我们对数据库进行管理
- 以前我们每次对数据库进行操作都要写一次数据库的操作语句:例如:select * from stu;当我有多个相同的需求要执行这句语句时,就得反复书写,太lay了!而mybatis将数据库的增删改查放入一个mapper.xml的配置文件中,以后java要用,使用路径访问即可!
- JDBC执行查询后得到的ResultSet我们需要手动处理,而mybatis执行查询后得到的结果会处理完后,将处理后的结果返回
- 总之优点太多了,一言难尽,边学边总结吧!
怎么学:
- 工欲善其事,必先利其器!首先在学mybatis前,强烈建议先学习一下Maven,我们都知道java在写代码的过程中要导入大量的包的(比如我们的单元测试junit和mysql驱动包等等),这个时候maven就显得格外的重要,他能够帮你解决很多导包以及包应该如何存放的问题(这里补充一下maven的包存放,maven最伟大的成就之一,就是完成了一件统一的事情,具体是什么呢,它规定了,根目录里放src和pom.xml,src下放main和test文件夹,顾名思义,main有来存放正式代码,test存放测试代码,以及还有很多相关规定,此处不做详细介绍了,感兴趣的可以自行了解),因此业内有一句术语,“约定大于配置” 指的就是这样一个现象。
- 学习怎么导入依赖(也就是导包,maven将导包操作变为依赖),比如mybatis使用的依赖等等
- 学习固定的模板格式:创建mapper.xml,mybatis-config.xml文件(名字可以自定义),创建pojo(全称:plain old/ordinary java object,简单java对象)等。
- 核心还是对数据库的操作,比如增删改查语句的使用,忘记的还得多多复习
- 复习java的知识,有时候会用到集合等等的操作``
2. 入门案例
需求:
查询数据库中emp表中的所有数据, 并将所有员工数据封装到Emp对象中, 最后将Emp对象封装到List集合中
2.1 测试准备
- 数据库(创建、新增数据)
- 创建Maven工程(使用IDEA)
- 导入相关的Maven依赖(解决导包问题)
2.2 过程展示
2.2.1 数据库创建、新增
代码直接复制粘贴运行即可
--准备数据(创建yonghedb库,并在其中创建emp表,并往emp中插入8条记录)
-- 1、创建数据库 yonghedb 数据库
create database if not exists yonghedb charset utf8;
use yonghedb; -- 选择yonghedb数据库
-- 2、删除emp表(如果存在)
drop table if exists emp;
-- 3、在 yonghedb 库中创建 emp 表
create table emp(
id int primary key auto_increment,
name varchar(50),
job varchar(50),
salary double
);
-- 4、往 emp 表中, 插入若干条记录
insert into emp values(null, '王海涛', '程序员', 3300);
insert into emp values(null, '齐雷', '程序员', 2800);
insert into emp values(null, '刘沛霞', '程序员鼓励师', 2700);
insert into emp values(null, '陈子枢', '部门总监', 4200);
insert into emp values(null, '刘昱江', '程序员', 3000);
insert into emp values(null, '董长春', '程序员', 3500);
insert into emp values(null, '苍老师', '程序员', 3700);
insert into emp values(null, '韩少云', 'CEO', 5000);
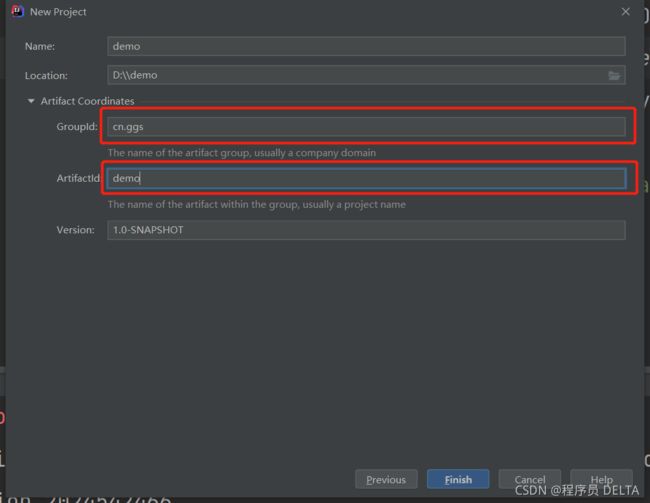
2.2.2 IDEA创建Maven工程
1.创建工程
2.配置相关Maven环境
3.设置maven环境
4.创建完成(结构如图所示)



2.2.3 导入相关的Maven依赖
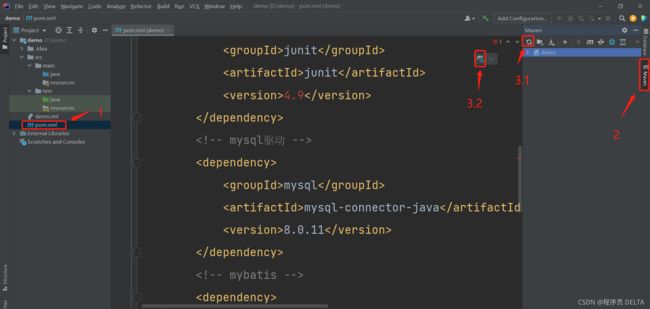
在pom.xml中导入mybatis的、mysql驱动的 以及 log4j的jar包(直接复制粘贴进pom.xml即可)
<dependencies> <!-- junit单元测试 --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.9</version> </dependency> <!-- mysql驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.11</version> </dependency> <!-- mybatis --> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.2.8</version> </dependency> <!-- 整合log4j --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.6.4</version> </dependency> </dependencies>```
导入后记得刷新一下,完成包的导入
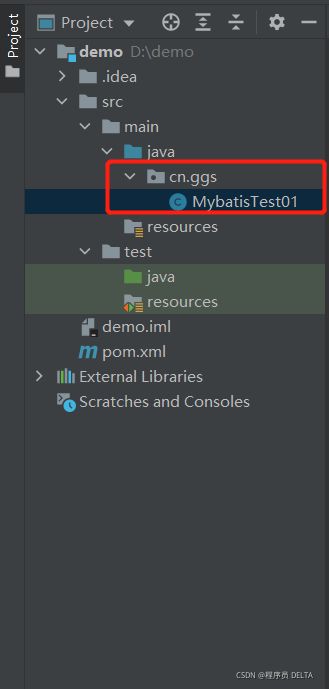
2.2.4 创建类
创建类:MybatisTest01(在这个类中查询emp表中的所有数据, 并将所有员工数据封装到Emp对象中, 最后将Emp对象封装到List集合中)
创建类:Emp(用于封装查询的员工信息)
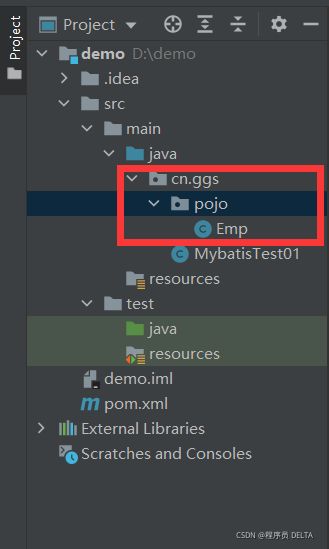
2.2.5 使用JDBC完成查询
2.2.5.1 在Emp类中封装所有的员工信息, 代码如下:
public class Emp {
//提供私有属性
private Integer id;
private String name;
private String job;
private Double salary;
//提供属性对应的get和set方法
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getJob() {
return job;
}
public void setJob(String job) {
this.job = job;
}
public Double getSalary() {
return salary;
}
public void setSalary(Double salary) {
this.salary = salary;
}
//toString方法
@Override
public String toString() {
return "Emp [id=" + id + ", name=" + name + ", job=" + job + ", salary=" + salary + "]";
}
}
2.2.5.2 查询yonghedb.emp表中的所有数据
public static void main(String[] args) {
try {
//注册驱动
Class.forName( "com.mysql.cj.jdbc.Driver" );
//获取连接
Connection conn = DriverManager.getConnection(
"jdbc:mysql:///yonghedb?characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useSSL=false",
"root","root");
//获取传输器
Statement stat = conn.createStatement();
//执行sql,返回结果
ResultSet rs = stat.executeQuery( "select * from emp" );
//遍历rs对象中的数据,将每一条数据封装为一个Emp对象
List<Emp> list = new ArrayList<Emp>();
Emp emp;
while( rs.next() ) {
int id = rs.getInt( "id" );
String name = rs.getString( "name" );
String job = rs.getString( "job" );
double salary = rs.getDouble( "salary" );
//将当前遍历的这条记录封装到emp对象中
emp = new Emp();
emp.setId(id);
emp.setName(name);
emp.setJob(job);
emp.setSalary(salary);
//将封装好数据的emp对象存到list集合中
list.add(emp);
}
//测试list集合中的数据是否是emp表中的所有记录
for ( Emp e : list ) {
System.out.println( e );
}
} catch (Exception e) {
e.printStackTrace();
}
}
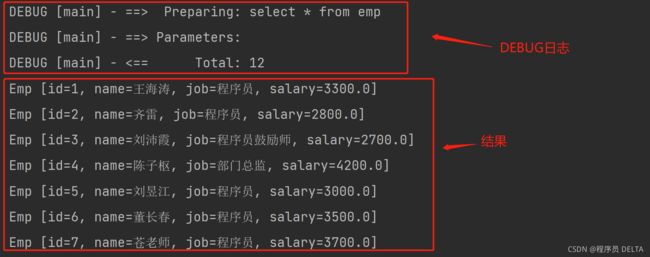
控制台结果:
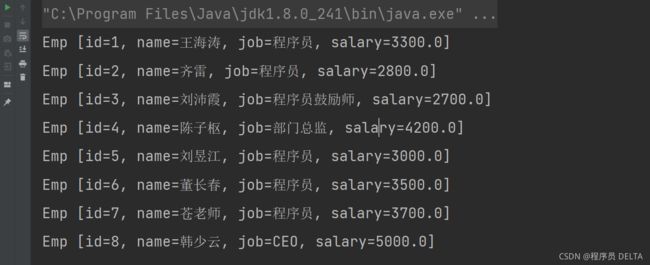
2.2.6 使用Mybatis完成查询
2.2.6.1 创建并配置:mybatis-config.xml文件
在这个文件中配置事务管理方式, 以及连接数据库的基本信息, 以及是否使用连接池等
在这个核心配置文件里,有固定的语法和格式,就和maven的pom.xml一样,因此,我们需要生成一个固定的模板格式(包含头信息等内容),不用我们什么都写,便于我们的开发。
模板格式如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- MyBatis的全局配置文件 -->
<configuration>
</configuration>
配置环境,完成mybatis-config.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<!-- MyBatis的全局配置文件 -->
<configuration>
<!-- 1.配置开发环境,default用于区别要使用哪一个环境,将来environments下
可能有很多的environment,因此default的值可以指定要使用哪个environment -->
<environments default="dev">
<environment id="dev"> <!-- id用于区别不同的environment -->
<!-- 1.1.配置事务管理方式
JDBC: 将事务交给JDBC管理(mybatis会自动开启事务,但需手动提交)
MANAGED: 自己手动管理事务 -->
<transactionManager type="JDBC"></transactionManager>
<!-- 1.2.配置连接池信息, type的取值:
JNDI: 已过时
UNPOOLED: 不使用连接池
POOLED: 使用连接池(可以减少连接创建次数,提高执行效率) -->
<dataSource type="POOLED">
<!-- property里name的值是固定的!不能随意修改,改的是value! -->
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql:///yonghedb?characterEncoding=utf-8&serverTimezone=Asia/Shanghai"/>
<property name="username" value="root"/>
<property name="password" value="root"/>
</dataSource>
</environment>
</environments>
<!-- 2.导入XxxMapper.xml文件(如果mapper文件有多个,
可以通过多个mapper标签导入)
resource属性会直接到类目录(classes)下去找指定位置的文件
-->
<mappers>
<mapper resource="EmpMapper.xml"/>
</mappers>
</configuration>
2.2.6.2 创建并配置:EmpMapper.xml文件
在这个文件中可以配置我们想执行的任何SQL语句(查询,新增,修改,删除等)
和上面的核心配置文件一样,这个文件也有它固定的模板格式,在这里也给大家提供!
模板格式如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="">
</mapper>
配置环境,完成EmpMapper.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace: 用于标识当前这个mapper文件(就是一个名字)
在mybatis程序中需要通过这个名字来定位当前这个mapper文件
通过namespace值+id值可以定位要执行的是哪条SQL语句
-->
<mapper namespace="EmpMapper">
<!-- 通过select,insert,update,delete标签来存放要执行的SQL -->
<!-- 查询emp表中的所有员工信息 -->
<!--
id属性:要求当前这个文件中的id值必须是独一无二的(不能重复)
resultType属性: 指定查询的结果要存放在哪个类型的对象中
-->
<select id="findAll" resultType="cn.ggs.pojo.Emp">
select * from emp
</select>
</mapper>
2.2.6.3 提供一个 cn.ggs.pojo.Emp 类
用于封装查询的员工信息(JDBC的实现中已经添加了,此处跳过)
2.2.6.4 完成 cn.ggs.MybatisDemo1中的代码, 并运行测试
public class MybatisDemo01 {
public static void main(String[] args) throws Exception {
//1.读取mybatis核心配置文件中的配置信息(mybatis-config.xml),此处也会读取EmpMapper.xml文件中的信息,因为config文件中绑定了EmpMapper.xml
InputStream in = Resources.getResourceAsStream( "mybatis-config.xml" );
//2.基于上面读取的配置信息获取SqlSessionFactory对象(工厂)
SqlSessionFactory fac = new SqlSessionFactoryBuilder().build( in );
//3.打开与数据库的连接(即通过工厂对象获取SqlSession对象)
SqlSession session = fac.openSession();
//4.通过namespace+id找到并执行SQL语句, 返回处理后的结果
//EmpMapper.xml, List结果如下:
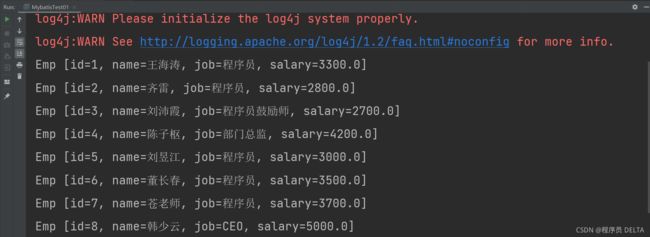
2.2.7:总结与心得
通过上面的案例可以发现,Mybatis对JDBC做了优化,但具体是怎么优化的呢?
我且这么分析,首先Mybatis将连接数据库的基本信息(驱动、连接的用户名,密码等)转移至一个config配置文件中,将对数据库语句的操作转移到一个mapper文件中,好处有很多:
- 其一,也是个人认为最核心的一点,就是使项目的维护更加的便利,我们都知道.java文件是给开发者看的,而计算机看不懂,计算机只能看懂.java文件经过编译后的.class文件,而将来我们进行项目发布的时候,上传到Linux系统时,需要上传我们编译后的class文件,那么问题就来了,如果将来我的数据库密码换了、数据库的驱动换了、数据库的查询语句想要新增或者修改了,怎么办?没有办法,因为原来上传的.class(字节码)文件我们是看不懂的,我们只能拿着源代码修改,重新编译后生成新的.class文件后再上传,如此循环往复,
oh!no!我裂开!显然,太麻烦了,因此,Mybatis就做了这样一种优化,将数据库的连接和语句这些基本信息放入xml文件中,这样以后要是想修改时,我们就改对应的xml文件,怎么样,是不是很便利,就这么一个简单的操作,将极大的提高我们项目的维护和开发效率。- 其二,以前一个java文件里要存放JDBC代码,java代码,数据库操作语句,整个文件很臃肿,不利于维护,有了mybatis的分层管理之后,代码更加清晰简洁。
古人云:祸兮福所倚,福兮祸所伏,凡事都有两面性,mybatis的加入也产生了一些问题:
- 首先错误的类型变多了,将来我们需要去练习和面对一些编程中可能遇到的错误。
- 并且要学习一些新的API,记忆的成本也会增加!所以,要努力克服这些缺点!反复练习!
2.2.8:拓展
为了封装员工信息而提供的Emp类, 我们称之为实体类(简单java对象, POJO: Plain Ordinary Java Object)
如果要查询所有的员工信息,员工信息查询出来后需要封装到Java对象中 因此这里需要提供的Emp(员工)类,这个类用于封装所有的员工信息
pojo(plain old/ordinary java object): 简单java对象
如果一个类只是用来封装数据的(比如为了封装员工信息而提供的Emp类)
这样的类我们称之为POJO类,通过该类生成的对象称之为POJO对象有哪些信息(数据)需要封装到Emp类中,就在Emp类中提供什么的属性/变量
在Emp中提供4个变量(id、name、job、salary)分别用来封装emp表中的id、name、job、salary四列数据。
再提供4个变量(id、name、job、salary)对应的Get和Set方法
关于Emp实体类中的id和salary为什么不用int和double类型, 而是用Integer和Double类型
因为int和double都属于基本类型, 基本类型的默认值(0, 0.0, 空字符,false ) 但如果使用包装类型,
包装类型的默认值是null, 可以避免一些误会产生int score;//默认值是0 Integer score;//默认值是null 分析:假如使用int类型,那么假设将来用户没有输入score的值,也会有默认值0, 问题来了,我怎么判断这个0是用户输入的,还是默认自带的,而使用包装类型则避免了这种误会!重写toString:是为了在打印Emp对象时,输出的是对象中所存储的值,而不是输出地址值
在编写实体类(POJO类)时,如果要添加有参构造函数,建议将无参构造函数也带上!
3.常见问题总结
3.1 在xml文件中书写代码时没有代码提示
解决方案:手动添加DTD
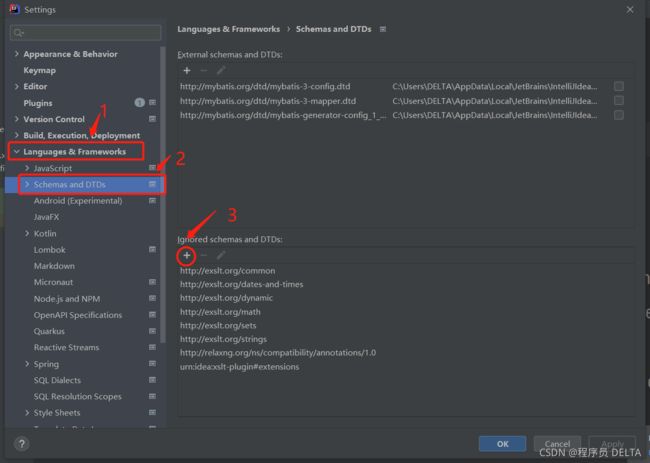
第一步:打开设置界面
第二步:找到Schemas and DTDs 设置列表,如图所示
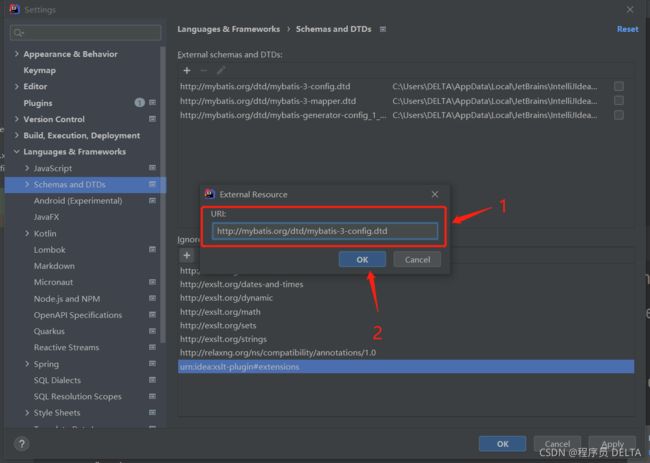
第三步:将头文件的DTD地址添加进来
结果如下,出现代码提示

3.2 Emp类中添加了有参构造函数,但没有添加无参构造函数!
//提供含参构造
public Emp(Integer id, String name, String job, Double salary) {
this.id = id;
this.name = name;
this.job = job;
this.salary = salary;
}
错误详情:
错误信息一般怎么看?
找Caused by(原因在),如果有多个就看第一个就可以了,一般都是一样的,然后看错误类型,比如这题是反射异常,接着看原因,错误的实例化一个类Emp,没有这个方法的异常,< init >(),这个代表无参构造,也就是没有无参构造

解决方案:
在写实体类时如果要添加有参构造函数, 尽量将无参构造也加上!
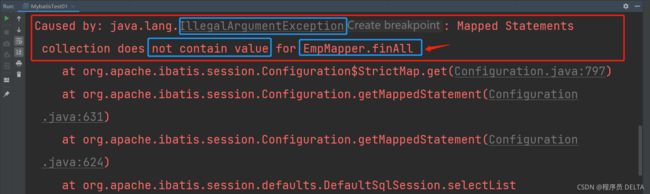
3.3 执行SQL语句时, namespace或id写错了, 找不到要执行的SQL语句就会报错!
现象:
错误详情:非法的参数异常,集合中不含有一个EmpMapper.finAll的值

解决方案:
每条SQL语句都有对应的 namespace+id, 而这些信息是存放在一个map中
例如:EmpMapper.findAll(key) : select * from emp(value)
因此,当出现这个报错时,要检查是否是自己的namespace和id写错了!
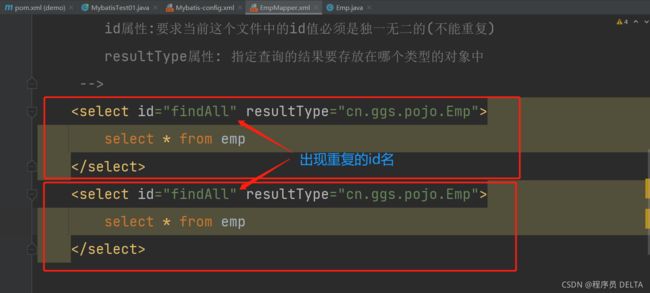
3.4 mapper文件中标签的id值重复了
现象:
错误详情:
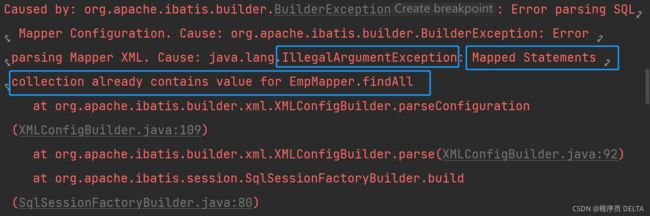
解决方案:
检查并修改Mapper文件中的id值,去重!
3.5 连接数据库的基本信息书写错误, 导致连接不上数据库
现象:
错误详情:数据源异常(也就是连接池异常),未知的数据源属性:usename

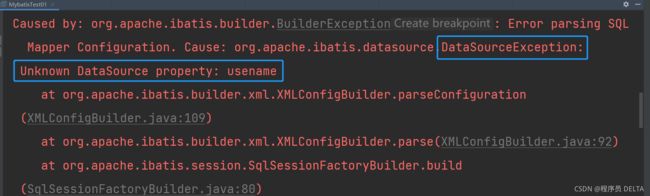
解决方案:
检查核心配置文件的连接池属性是否书写错误,不如username、password、url等,注意区分大小写
3.6 出现xml文件找不到异常
现象:
错误详情:IO异常,不能找到xml文件

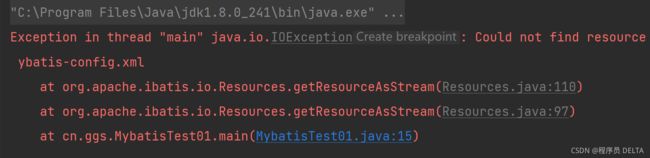
解决方案:
1.检查文件名与参数是否匹配
2.检查classes文件中是否有对应的xml文件,程序是到classes目录下去寻找对应的xml文件的,有时候maven让我挺无语的,我就在这里中过一次坑,运行程序classes里没有生成对应文件

4.mybatis封装查询结果的过程:
4.1 过程分析
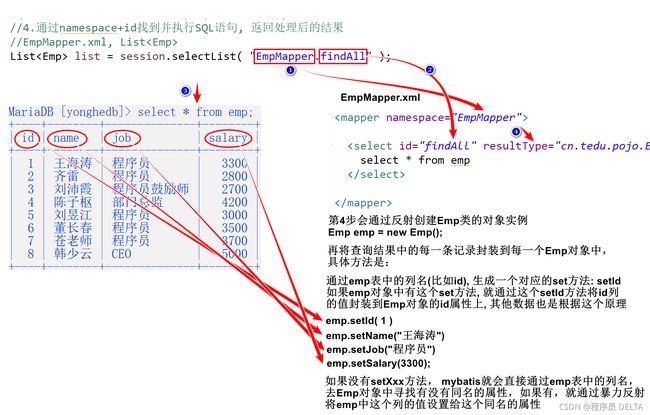
解析:
- 首先通过namespace找到对应的mapper文件:EmpMapper
- 通过id找到对应的SQL标签:findAll
- 执行SQL标签里的sql语句:select * from emp
- 根据提供的resultType去创建类的对象实例:new Emp();
此时分两种情况:
- 在实体类中有提供set方法,此时,会调用setXXX方法(例如,查询结果中,列名为id,则会生成一个对应的setId方法,规律是:列名首字母大写,前面加上set),通过这个方法给实体类中的对应的属性赋值,这句话的意思就是set方法默认会被调用!最后将数据封装成对象存入list集合中。
- 在实体类中没有提供set方法,此时,mybatis会通过数据库表中的列名去实体类对象中查找有没有同名的属性,如果有,则通过暴力反射的技术将查询到的表中的列的值赋值给这个同名的属性
4.2 常见问题
4.2.1如果emp表中的列名 和 Emp对象中的属性名不相同, 查询的结果能封装到Emp对象中吗?
答:不能!mybatis会根据数据库查询结果的字段,生成对应的setXXX方法,此时,若列名与属性名不相同,则无法为属性设置值,即使要通过暴力反射,列名和属性名也要匹配,因为是根据列名来找的
解决方法:
- 更改属性名,和数据库的列名相匹配
- 在查询时为列起别名:例如数据库列名为userID,实体类属性字段为id,此时,在查询时
可以使用select userID as id from emp;这样列名和属性名就对应了
5.mybatis的增删改查操作
5.1 练习:
1.新增员工信息: 赵云 保安 6000
2.修改员工信息: 赵云 保镖 20000
3.删除员工信息: 删除名称为’赵云’的员工信息
创建类:MybatisTest02、Emp(上文已提供)
MybatisTest02:
public class MybatisTest02 {
//1.提供成员变量session,为了将来做多个单元测试时,可以节省代码的编写提高效率
SqlSession session = null;
/* @Before标记的方法会在 每个@Test标记的方法之前执行! */
@Before
public void beforeMethod() throws Exception{
//2.读取mybatis核心配置文件中的配置信息(mybatis-config.xml)
InputStream in = Resources.getResourceAsStream( "mybatis-config.xml" );
//3.基于上面读取的配置信息获取SqlSessionFactory对象(工厂)
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build( in );
//4.打开与数据库的连接(即通过工厂对象获取SqlSession对象)
session = factory.openSession( true );
//true: 表示自动提交事务, 默认是false, 表示关闭自动提交, 需要手动提交!
}
//5.创建单元测试类::新增员工信息: 赵云 保安 6000
@Test
public void testInsert() {
//通过namespace+id找到并执行SQL语句, 返回执行结果
int rows = session.insert( "EmpMapper.insert" );
System.out.println( "影响行数为: "+rows );
//提交事务
//session.commit();
}
//修改员工信息: 赵云 保镖 20000
@Test
public void testUpdate() {
//通过namespace+id找到并执行SQL语句, 返回执行结果
int rows = session.update( "EmpMapper.update" );
System.out.println( "影响行数为: "+rows );
}
//删除员工信息: 删除名称为'赵云'的员工信息
@Test
public void testDelete() {
//通过namespace+id找到并执行SQL语句, 返回执行结果
int rows = session.delete( "EmpMapper.delete" );
System.out.println( "影响行数为: "+rows );
}
}
EmpMapper.xml
<!-- 新增员工信息: 赵云 保安 6000 -->
<insert id="insert">
insert into emp value(null, '赵云', '保安', 6000 )
</insert>
<!-- 修改员工信息: 赵云 保镖 20000 -->
<update id="update">
update emp set job='保镖', salary=20000 where name='赵云'
</update>
<!-- 删除员工信息: 删除名称为'赵云'的员工信息 -->
<update id="update">
delete from emp where name='赵云'
</update>
总结:
mybatis开启事物的方式有两种:
方式一:通过打开数据库连接时,参数里写true
factory.openSession( true );//true: 表示自动提交事务, 默认是false, 表示关闭自动提交, 需要手动提交!
方式二:手动提交事物
调用.commit();方法
5.2 Log4j引入
5.2.1 初理解
是什么:
log4j,全称为:log for java(java日志),是Apache的开源项目,和它类似的还有dom4j(dom for java),好家伙,这家公司为编程界做出的贡献真多!简单来说就是用来记录程序运行的过程和结果的,和System.out.println()方法相似,但比它更灵活,更全面
为什么要学:
- 首先从程序方面来说,如果我们想要看程序运行的结果,肯定是要写打印语句的,这样子会出现一个问题,就是将来如果我想看的东西很多,那么就要写很多个打印语句了,一方面不方便,另一方面也不美观,因此,log4j的加入,可以在程序运行的过程中将结果记录下来。而不用人为的过度干预,在mybatis的运用中,也可以更快速直观的看到sql语句传参、执行的过程和结果。
- 以前我们只能将信息输出到控制台,而控制台能容纳的信息是有限的,现在我们可以将信息保存到一个文件中,便于我们查看和记录
- 信息包含很多,有错误信息、运行结果、过程等等,log4j允许我们选择自己想要的信息进行查阅
5.2.2 环境配置
- log4j的使用要分两步走:
- 导入jar包(添加依赖):mybatis集成了log4j
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.6.4</version> </dependency>
- 导入log4j的配置文件,放到resources下:(log4j.properties)
文件名是固定的!!配置文件内容如下:
# Global logging configuration
log4j.rootLogger=DEBUG, stdout
此句为将等级为DEBUG的日志信息输出到stdout这个目的地,stdout定义在下面的代码,可以任意起名。等级可分为OFF、FATAL、ERROR、WARN、INFO、DEBUG、ALL,如果配置OFF则不打出任何信息,如果配置为DEBUG只显示DEBUG、INFO、WARN、ERROR的log信息,而ALL信息不会被显示,有层级性,和maven生命周期类似
# Console output…
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
此句为定义名为stdout的输出端是哪种类型,可以是 org.apache.log4j.ConsoleAppender(控制台), org.apache.log4j.FileAppender(文件), org.apache.log4j.DailyRollingFileAppender(每天产生一个日志文件), org.apache.log4j.RollingFileAppender(文件大小到达指定尺寸的时候产生一个新的文件) org.apache.log4j.WriterAppender(将日志信息以流格式发送到任意指定的地方)
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
此句为定义名为stdout的输出端的layout是哪种类型,可以是 org.apache.log4j.HTMLLayout(以HTML表格形式布局), org.apache.log4j.PatternLayout(可以灵活地指定布局模式), org.apache.log4j.SimpleLayout(包含日志信息的级别和信息字符串), org.apache.log4j.TTCCLayout(包含日志产生的时间、线程、类别等等信息)
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
如果使用pattern布局就要指定的打印信息的具体格式ConversionPattern,打印参数 如下: %m 输出代码中指定的消息; 数字5代表显示字符的长度,例如5p:DEBUG会显示DEBUG,2p就会显示:DE; %M 输出打印该条日志的方法名; %p 输出优先级,即DEBUG,INFO,WARN,ERROR,FATAL; %r 输出自应用启动到输出该log信息耗费的毫秒数; %c 输出所属的类目,通常就是所在类的全名; %t 输出产生该日志事件的线程名; %n 输出一个回车换行符,Windows平台为"rn”,Unix平台为"n”; %d 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyyy-MM-dd HH:mm:ss,SSS},输出类似:2002-10-18 22:10:28,921; %l 输出日志事件的发生位置,及在代码中的行数; [QC]是log信息的开头,可以为任意字符,一般为项目简称。 输出的信息 [TS] DEBUG [main] AbstractBeanFactory.getBean(189) | Returning cached instance of singleton bean 'MyAutoProxy'点我了解更多:log4j的信息
5.2.3 测试
5.2.3.1 输出到控制台
1.将DEBUG级别的日志信息按照固定格式输出到控制台
log4j.properties文件信息如下:
# Global logging configuration
log4j.rootLogger=DEBUG, stdout
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
图示结果:
5.2.3.2 输出到文件
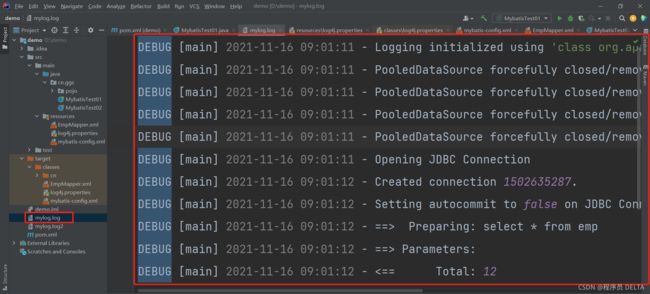
2.将DEBUG级别的日志信息按照固定格式输出到文件
log4j.properties文件信息如下:
# Global logging configuration
log4j.rootLogger=DEBUG, LOGFILE
# Console output...
log4j.appender.LOGFILE=org.apache.log4j.FileAppender
log4j.appender.LOGFILE.file=./mylog.log #可以更换自己的路径,如果.log文件不存在,会自动创建
log4j.appender.LOGFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.LOGFILE.layout.ConversionPattern=%5p [%t] %d{yyyy-MM-dd hh:mm:ss} - %m%n
图示结果:
5.2.4 补充
系统是到classes类目录下寻找log4j.properties文件

5.3 Mybatis的占位符
5.3.1 概述
是什么:
mybatis中有两种占位符, 分别是: #{}, ${}
其中最常用的就是 #{} 占位符
为什么学:
在 5.1练习 增删改查操作中,SQL语句中的值是写死在SQL语句中的,而在实际开发中,此处的值往往是用户提交过来的值,因此这里我们需要将SQL中写死的值替换为占位符。
5.3.2 占位符初使用
<!-- 优化 新增员工信息: null, 马云, 教师, 800 -->
<insert id="insert2">
<!-- 使用#{}占位符 -->
insert into emp value( null, #{name}, #{job}, #{salary} )
</insert>
/* 优化 新增员工信息: null, 马云, 教师, 800 */
@Test
public void testInsert2() {
//1.声明一个map集合,将SQL参数封装到map中
Map map = new HashMap();
map.put( "name", "马云" );
map.put( "job", "教师" );
map.put( "salary", 800 );
//2.根据namespace+id找到SQL语句, 将map作为参数传过去, 并执行SQL语句
int rows = session.insert( "EmpMapper.insert2", map );
System.out.println( "影响行数: "+rows );
}
5.3.3 占位符接收参数
5.3.3.1 #{}占位符
特点:
其实就是JDBC中的问号(?)占位符,在mybatis底层会将 #{}占位符翻译成问号(?)占位符
如果在SQL语句中占位符只有一个#{}占位符,{}中名称没有要求, 但不能是空的; 参数可以直接传递,不用封装;
如果在SQL语句中的#{}占位符,不止一个,参数值需要通过Map或者POJO对象进行封装;
5.3.3.1.1 通过Map方式传参
//测试代码
@Test
public void Testadd4(){
//1.声明Map集合
Map map = new HashMap();
map.put("name","关羽");
map.put("job", "快递员");
map.put("salary",12000);
int rows = session.insert("EmpMapper.add4",map);
System.out.println("受影响的行数:"+rows);
}
//Mapper代码
<insert id="add4">
insert into emp value (null ,#{name},#{job},#{salary})
</insert>
总结:
1.占位符名称必须要和Map里的Key保持一致,mybatis底层会去Map中寻找对应的Key匹配value
5.3.3.1.2 通过POJO对象封装SQL参数进行传参
@Test
public void testUpdate(){
//1.通过构造方法为属性赋值
// Emp emp = new Emp(15,"关羽","教授",9999.0);
//3.通过set方法为属性赋值
Emp emp = new Emp();
emp.setName("关羽");
emp.setJob("程序员");
emp.setSalary(8888.0);
//2.将emp的数据进行封装传参
session.update("EmpMapper.update1",emp);
}
@Test
public void testFind(){
//4.当只有一个占位符时,可以直接传值
List<Emp> list = session.selectList("EmpMapper.findAll", "关羽");
for (Emp e: list) {
System.out.println(e);
}
}
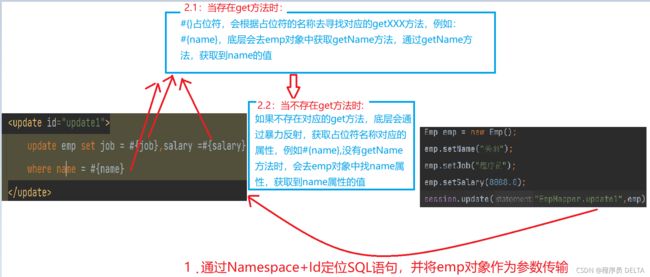
<update id="update1">
<!-- 通过姓名,修改职业和工资信息 -->
update emp set job = #{job},salary =#{salary}
where name = #{name}
</update>
<select id="findAll" resultType="cn.ggs.pojo.Emp">
<!-- 查询指定用户的信息 -->
select * from emp where name = #{name}
</select>
总结:
1.数据获取过程
补充:如果get方法和属性名都存在,默认优先通过get方法获取
2.如果只有一个占位符时,可以在传参时直接输入值
5.3.3.2 ${}占位符
特点:
是为SQL语句中的某一个SQL片段进行占位,将参数传递过来时,是直接将参数拼接在${}占位符所在的位置,因为是直接拼接,所以可能会引发SQL注入攻击,因此不推荐大量使用!
如果SQL语句中只有一个#{}占位符,参数可以不用封装,直接传递即可!
但如果SQL语句中哪怕只有一个${}占位符,参数也必须得先封装到Map或者POJO对象中,再把Map或者POJO对象传递过去!
mybatis底层在执行SQL语句时,使用的就是PreparedStatement对象来传输SQL语句!
测试:
//Mapper
//1.使用#{},查询emp表中的所有员工信息, 动态显示要查询的列
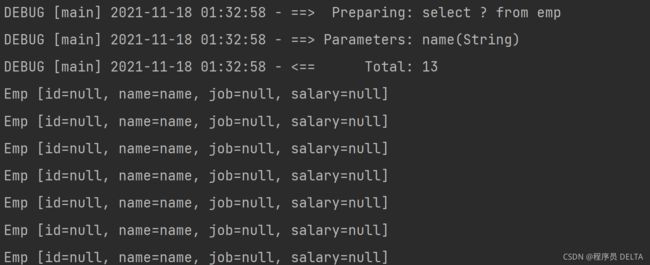
<select id="findCols" resultType="cn.ggs.pojo.Emp">
select #{colName} from emp
</select>
@Test
public void findCol(){
//2.给#{}占位符传递参数,name
List<Emp> list = session.selectList("EmpMapper.findCols", "name");
for (Emp emp:list) {
System.out.println(emp);
}
}
结果:
存在查询bug,因为#{}占位符其实就是JDBC的(?)占位符,因此,在传递参数时,会在参数左右两边添加单引号(’’),变成:select ‘name’ from emp
使用${}进行优化
//3.使用${}占位符优化
<select id="findCols" resultType="cn.ggs.pojo.Emp">
select ${colName} from emp
</select>
@Test
public void findCol(){
Map map = new HashMap();
map.put("colName", "name");
//4.${}占位符,哪怕sql语句只有一个占位符,参数也必须得先封装到Map或者POJO对象中,再把Map或者POJO对象传递过去!
List<Emp> list = session.selectList("EmpMapper.findCols", map);
for (Emp emp:list) {
System.out.println(emp);
}
}
结果:
是为SQL语句中的某一个SQL片段进行占位,将参数传递过来时,是直接将参数拼接在${}占位符所在的位置,因为是直接拼接,所以可能会引发SQL注入攻击,因此不推荐大量使用!

5.4 Mybatis的动态SQL
5.4.1 引言:
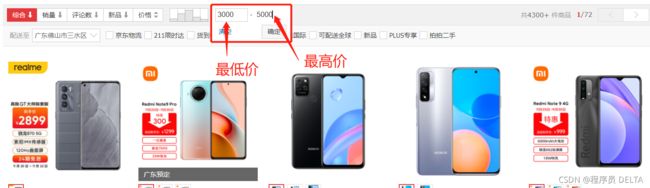
现实生活中我们总会遇到很多数据筛选的现象,例如上图根据手机价格筛选查询的数据,此时,作为程序员,我们应该如何去设计我们的代码结构呢,现象分析:首先,现实生活中我们会有如下4种需求:
- 不输入最低价和最高价,默认查询所有数据
- 输入最低价和最高价,查询在这二者间的数据
- 只输入最低价,查询所有大于最低价格的数据
- 只输入最高价,查询所有小于最高价格的数据
按照这个思路,我们一共有4条对应的SQL语句:
- select * from emp;表名随意
- select * from emp where salary > 最低价 and salary < 最高价
- select * from emp where salary > 最低价
- select * from emp where salary < 最高价
作为设计者来说,每一种查询我们都要写一个SQL语句,未免太麻烦了,何况现在只是4个需求,将来要是10几个或者更多,岂不是很爆炸,因此,我们引入动态SQL帮助我们解决这一需求
if标签、where标签、foreach标签
动态SQL指的是:SQL语句可以根据参数值的不同,来生成不同的SQL语句
5.4.2 入门案例
根据引言的描述,我们以上文的员工信息表(例子:2.2.1)为例子,根据员工的薪资查询员工信息。
创建类:
- cn.ggs.pojo.Emp(例子:2.2.6.3)
- cn.ggs.MybatisTest04
创建xml文件:
- mybatis-config(例子:2.2.6.1)
- EmpMapper(例子:2.2.6.2)
5.4.2.1 if、where标签
EmpMapper.xml:
//查询所有的员工信息
<select id="findAll" resultType="cn.ggs.pojo.Emp">
//1.使用1=1,解决and的连接问题
select * from emp where 1=1
</select>
//根据员工的薪资查询员工信息
<select id="selectbySal" resultType="cn.ggs.pojo.Emp">
select * from emp
where 1=1
//2.由于不同的员工信息有不同的方案,
//为此我们可以使用if标签,当满足条件时,执行if中的代码
//3.利用if标签判断
//test属性:用来存放一个布尔表达式,当为true时,执行标签中的代码
<if test="salMin != null">
and salary > #{salMin}
</if>
//4.当存在最大值时
<if test="salMax != null">
//5.在xml文件中小于号(<)会被当做标签的开始标记,
//使用<表示小于号
and salary < #{salMax}
</if>
</select>
//根据员工的薪资查询员工信息(优化)
//之前的where后要跟1=1,防止语法错误,对and和or连接符不能很好的处理
<select id="selectbySal2" resultType="cn.ggs.pojo.Emp">
select * from emp
//6.使用where标签解决连接符问题,where标签会自动去除多余的and或or
<where>
<if test="salMin != null">
and salary > #{salMin}
</if>
<if test="salMax != null">
and salary < #{salMax}
</if>
</where>
</select>
cn.ggs.MybatisTest04:
//查询所有的员工信息
@Test
public void findAll(){
List<Emp> list = session.selectList("EmpMapper.findAll");
for (Emp emp:list
) {
System.out.println(emp);
}
}
//根据员工的薪资区间查询员工
@Test
public void selectBySal(){
Map map = new HashMap();
map.put("salMin", 5000);
map.put("salMax", 9000);
List<Emp> list = session.selectList("EmpMapper.selectbySal",map);
for (Emp emp:list
) {
System.out.println(emp);
}
}
//根据员工的薪资查询员工信息(优化)
@Test
public void selectBySal2(){
Map map = new HashMap();
map.put("salMin", 5000);
map.put("salMax", 9000);
List<Emp> list = session.selectList("EmpMapper.selectbySal2",map);
for (Emp emp:list
) {
System.out.println(emp);
}
}
总结:
- if标签: 如果test属性中的布尔表达式为true, 那if标签中的SQL片段就会参与整个SQL语句的执行, 反之, 如果test属性中的布尔表达式为false, 那么if标签的中内容将不会执行!
- xml文件中,小于号(<)被赋予特殊意义,要使用小于号,使用<(全称:less than),大于号:>(greater than)
- where标签: 将if标签以及其中的条件都包裹在where标签内部, 只要有任何一个条件成立, where标签就会生成where关键字, 并且如果条件前面有多余的连接词(比如or,and),where标签会将多余的连接词去掉!
5.4.2.1 foreach标签
需求:根据员工的ID批量查询员工信息
EmpMapper.xml:
//查询id为2,4,6,8的员工
<select id="findByIds" resultType="cn.ggs.pojo.Emp">
//1.使用传统的in方式,有弊端,将来我们不知道具体的员工有几个,
//我们是用占位符的方式进行传参的,将来个数未知,#{}的个数也无法确定
select * from emp where id in (2,4,6,8)
</select>
//查询id为2,4,6,8的员工(使用foreach标签)
<select id="findByIds2" resultType="cn.ggs.pojo.Emp">
select * from emp where id in
//2.使用foreach标签遍历
//collection:将来用数组遍历,所以使用array,此处的值是固定的
//open:指定生成SQL语句的起始符号
//separator:声明分隔符,因为传过来的数组是用逗号隔开的,所以使用,
//item:遍历后的值保存的变量,一般和占位符名称保持一致
//close:指定生成SQL语句的结束符号
<foreach collection="array" open="(" separator="," item="id" close=")">
#{id}
</foreach>
</select>
cn.ggs.MybatisTest04:
//根据员工id查询信息
@Test
public void findByIds(){
int[] ids = {2,4,6,8};
List<Emp> list = session.selectList("EmpMapper.findByIds", ids);
for (Emp emp:
list) {
System.out.println(emp);
}
}
//根据员工id查询信息,使用foreach标签
@Test
public void findByIds2(){
int[] ids = {2,4,6,8};
List<Emp> list = session.selectList("EmpMapper.findByIds2", ids);
for (Emp emp:
list) {
System.out.println(emp);
}
}
总结:
foreach标签可以对传过来的数组或集合进行遍历,生成我们所需要的SQL片段
collection属性:如果传过来的只有一个数组(或List集合) collection指定的值则为array(或list);如果传过来的是一个map集合, 将数组或集合作为value封装到map中, collection属性的值就是数组或集合在map中的key;
open属性:指定所生成SQL片段的起始符号,通常是左圆括号 (
close属性:指定所生成SQL片段的结束符号,通常是右圆括号 )
item属性:指定占位符中的名称
separator属性:指定占位符中间的分隔符, 通常是逗号 ,
6.Mybatis的接口开发
6.1 概述
有xml文件开发不就好了?为什么需要接口开发?众所周知,以前我们写xml文件的namespace和id时,是不是总会面临一个问题,当我们的Mapper.xml文件中的SQL语句越来越多时,id也随之增加,这就产生了一个挺头疼的问题,那就是记不住我们自己写的id值,并且如果写错的话程序也不会给我们友好提示,只有到了程序运行时才会报错,然后又要倒回去查,大大减缓了我们的开发效率,而引入接口开发,则可以让我们在程序编译期对程序进行检查,查看SQL语句是否存在异常
6.2 入门测试
注意事项:
mapper接口开发要满足以下四个规则:
1)写一个接口, 要求接口的全类名(包名.接口名) 要等于XxxMapper文件的namespace值 namespace = 接口的全类名
2)mapper文件中要执行的SQL语句,在接口中得有对应的接口方法, 并且, SQL语句的id值要等于接口的这个方法名 SQL标签的id值 = 方法名
3)如果是查询SQL,resultType指定的类型要和接口方法的返回值类型对应
- a)如果接口返回的是某一个实体对象(Emp),此时resultType指定的是该对象的类型(cn.tedu.pojo.Emp)
- b)如果接口返回的是集合(List),
此时resultType指定的是集合中的泛型(cn.tedu.pojo.Emp)4)(可以忽略) SQL标签上的参数类型(paramterType属性)要和 接口方法的参数类型保持一致!
6.2.1 mapper接口开发测试: 查询emp表中的所有员工信息
创建类:cn.ggs.pojo.Emp(案例:2.2.6.3)
创建xml文件:mybatis-config.xml(案例:2.2.6.1)、EmpMapper.xml(案例:2.2.6.2)
创建接口:cn.ggs.dao.EmpMapper
(一般接口名和Mapper.xml的文件名保持一致)
dao全称:(Data Access Object) 数据访问对象
package cn.ggs.dao;
import cn.ggs.pojo.Emp;
import java.util.List;
//1.创建接口
public interface EmpMapper {
//4.创建方法,方法名要和SQL语句的id值保持一致
//void findAll();
//5.返回值要和resultType的类型相对应,此处为list是因为
//查询语句返回有多条
List<Emp> findAll();
}
EmpMapper.xml:
//2.namespace的值要等于接口的全类名:cn.ggs.dao.EmpMapper
<mapper namespace="cn.ggs.dao.EmpMapper">
//3.为查询标签设置id值,resultType
<select id="findAll" resultType="cn.ggs.pojo.Emp">
select * from emp
</select>
</mapper>
创建类:cn.ggs.MybatisTest05
用来测试接口开发
public class MybatisTest04 {
SqlSession session = null;
@Before
public void beforeMethod() throws IOException {
InputStream in = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory fac = new SqlSessionFactoryBuilder().build(in);
session = fac.openSession(true);
}
@Test
public void findAll(){
//1.通过getMapper方法,利用反射获取EmpMapper对象的实例
/*接口有实例?没有,但接口的实现类有实例,因此Mybatis底层
其实为我们做了实例 详情见:6.2.2*/
EmpMapper mapper = session.getMapper(EmpMapper.class);
//2.通过实例调用方法
/*好处就是这里,在这里会为我们进行校验,如果调用错了,那么
对应的SQL语句也就错了,为我们提供检查*/
List<Emp> list = mapper.findAll();
for (Emp emp:
list) {
System.out.println(emp);
}
}
}
6.2.2 模拟mybatis提供的EmpMapper接口的实现类
创建类:cn.ggs.dao.EmpMapperImpl
public class EmpMapperImpl implements EmpMapper{
//1.提供变量session,将来能调用对应的SQL
private SqlSession session;
//2.通过构造方法为属性赋值
public EmpMapperImpl(SqlSession session){
this.session = session;
}
@Override
public List<Emp> findAll() {
//4.通过反射,获取全类名
String namespace = this.getClass().getInterfaces()[0].getName();
//5.通过线程获取当前方法名,也就是id名
String id = Thread.currentThread().getStackTrace()[1].getMethodName();
//3.通过session调用对应的查询语句,关键在于namespace+id,和之前xml的方式一样
List<Emp> list = session.selectList(namespace + "." + id);
return list;
}
}
cn.ggs.MybatisTest05
@Test
public void findAll3(){
//6.创建实现类对象,传入session
EmpMapperImpl empMapper = new EmpMapperImpl(session);
//7.调用方法
List<Emp> list = empMapper.findAll();
for (Emp emp:list) {
System.out.println(emp);
}
}
补充:全类名和方法名的获取
/*
获取当前这个类的父接口的全类名(=namespace)
通过当前类的对象(this)获取当前类的字节码对象, 再通过当前类的字节码对象获取当前类实现的所有
父接口组成的数组, 由于当前类实现的接口只有一个, 所有通过数组[0]获取当前类实现的接口
再通过接口获取接口的全类名(包名.接口名)
/
String interName = this.getClass().getInterfaces()[0].getName();
//获取当前方法的名字(=SQL标签的id值)
/
获取存放的方法调用栈信息(也就是所有方法的调用信息), 返回的是一个数组, getStackTrace
这个方法会在栈顶(也就是数组的第一个元素), 调用这个方法的是findAll方法, 这个方法在数组中的
第二个位置(也就是数组的第二个元素)
/
StackTraceElement[] st = Thread.currentThread().getStackTrace();
/
通过数组的中的第二个元素(其中方法所属类的全类名,方法名,当前方法所属文件的名字,也就方法调用的行数)
获取当前调用的方法的名字
*/
String methodName = st[1].getMethodName();
7.Mybatis注解开发
7.1 概述
使用xml方式和注解开发的区别?
优点:
使用xml方式配置SQL语句,写起来相比注解要麻烦一些; 而注解方式,不用写配置文件,直接在接口的方法上面添加一个注解(@Select,@Insert,@Update,@Delete…),将SQL语句直接写在注解的括号里即可;
缺点:
使用注解方式配置SQL语句又回到将SQL语句写在Java程序中,如果将来SQL语句一旦发生变化,就意味着要修改java源文件(.java),改完后要重新编译整个项目,再打包、部署到服务器上,相比来说较为麻烦。
7.2 入门案例
注意事项:
由于使用注解开发,要将SQL语句配置在注解中,因此EmpMapper.xml(案例:2.2.6.2)文件也就不需要了,在mybatis-config.xml(案例:2.2.6.1)文件中也就不需要引入EmpMapper.xml文件了
7.2.1 在xml文件中引入接口的方式
测试:
在mybatis-config.xml文件中引入SQL语句所在的mapper接口(因为SQL语句存放在接口中)
<mappers>
<!-- <mapper resource="EmpMapper.xml"/> -->
<!--
1.可以将每一个XxxMapper接口通过一个mapper标签的class属性引入
如果有多个XxxMapper接口,添加多个mapper标签引入即可!
-->
<!-- <mapper class="cn.tedu.dao.EmpMapper"/> -->
<!--
2.或者是直接引入XxxMapper接口所在的包, 这样mybais会直接扫描这个包下的
所有接口中的每个方法, 那么这些方法上所配置的SQL语句也会被读取到mybatis中
-->
<package name="cn.tedu.dao"/>
</mappers>
创建接口:cn.ggs.dao.EmpMapper
public interface EmpMapper {
//4.添加Select注解
//()内写SQL语句
@Select("select * from emp")
//3.声明方法
List<Emp> findAll();
}
创建类:cn.ggs.MybatisTest05
@Test
public void findAll(){
//5.获取EmpMapper对象实例
EmpMapper mapper = session.getMapper(EmpMapper.class);
//6.调用findAll方法
List<Emp> list = mapper.findAll();
for (Emp emp:list) {
System.out.println(emp);
}
}
总结:
注解开发的优势是效率高,但是劣势也有许多,比如现在是在注解里书写SQL语句,将来遇到动态SQL的场景时,不好优化。因此需要自己根据实际开发环境做出灵活选择
7.2.2 练习
EmpMapper:
/* 练习02: 新增员工信息(没有占位符) */
@Insert("insert into emp value(null, '赵云云', '高级Java工程师', 35000)")
public void insert();
/* 练习03:新增员工信息: null, 马云, 教师, 800(有占位符) */
@Insert("insert into emp value(null, #{name}, #{job}, #{salary})")
public void insert2(Map map);
/* 练习04: 修改员工信息: 将马云的职位改为"CEO", 薪资改为80000(有占位符) */
@Update("update emp set job=#{job}, salary=#{salary} where name=#{name}")
public void update2(Emp emp);
MybatisTest05:
@Test
public void insert(){
EmpMapper mapper = session.getMapper(EmpMapper.class);
Map map = new HashMap();
map.put("name", "赵云");
map.put("job", "程序员分析师");
map.put("salary", 20000);
mapper.insert2(map);
}
@Test
public void upadate(){
EmpMapper mapper = session.getMapper(EmpMapper.class);
Emp emp = new Emp();
emp.setName("赵云");
emp.setJob("Java程序员");
emp.setSalary(14000D);
mapper.update2(emp);
}