零拷贝浅析
前言
在介绍零拷贝之前,我们先通过简单的例子了解普通的数据传输模式有什么弊端,然后再看看零拷贝技术解决了哪些问题。
我们知道很多 Web 应用程序提供大量静态内容,这相当于从磁盘读取数据并将完全相同的数据写回响应套接字(也就是socket),然后再发送给客户端。这个过程似乎只需要相对较少的 CPU 活动,但其实这样做是较为低效的。首先我们需要知道内核从磁盘读取数据并将其跨内核用户边界推送到应用程序,然后应用程序将其推送回内核用户边界写入套接字。实际上,应用程序更相当于一个低效的搬运工,其从磁盘文件获取数据然后再将其转运到套接字。
为什么说上面的流程是低效的呢?首先我们需要明确每次数据穿越用户内核边界时(用户态与内核态的切换),都必须进行复制,这会消耗 CPU 周期和内存带宽。那有没有什么方法去减少这些不必要的复制呢?
答案自然是肯定的,有请我们今天的主角:零拷贝技术。
何为零拷贝
零拷贝(Zero-copy;也被称为零复制)技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。
使用零拷贝的应用程序请求内核直接将数据从磁盘文件复制到套接字,而不通过应用程序。零拷贝极大地提高了应用程序性能并减少了内核和用户模式之间的上下文切换次数。
Java 类库通过 java.nio.channels.FileChannel.transferTo()方法支持零拷贝技术,可以通过transferTo()方法将字节直接从调用它的channel传输到另一个可写字节channel,而无需数据经过应用程序。
具体流程剖析
接下来我们详细分析上面所说的流程,事实上这是一个很常见的场景,它描述了很多服务器应用程序的行为,包括FTP服务器、邮件服务器等等。
我们首先剖析传统方案(将字节从文件复制到socket)的处理流程:

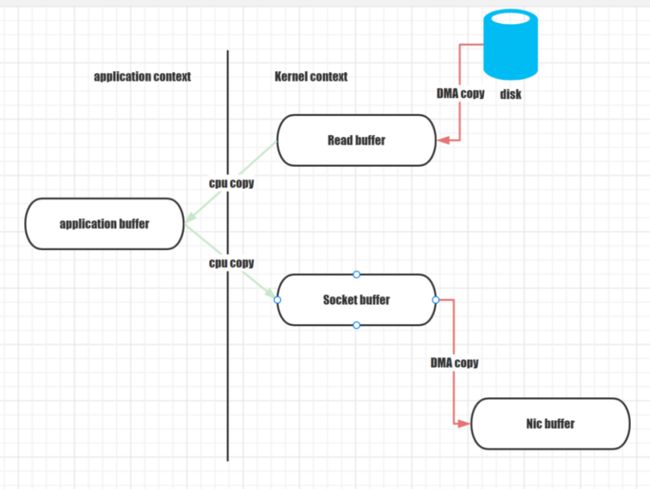
看上去好像很简单,但是实现起来需要在用户态和内核态之间进行四次上下文切换同时进行了四次数据复制,数据如何在内部从文件移动到socket如下图所示:
上下文切换过程如下图所示:
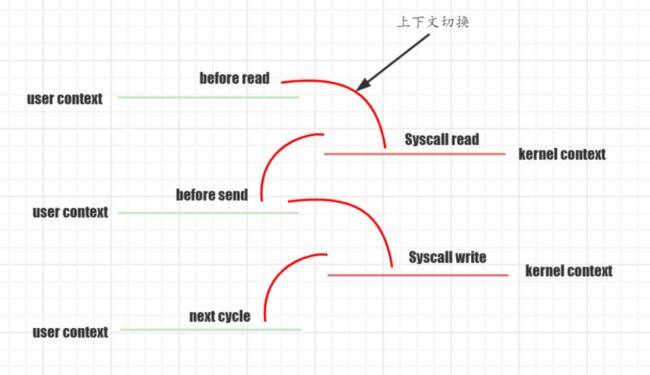
然后我们来分析一下具体的流程,大致分为以下几步:
-
Read()调用导致从用户模式到内核模式的上下文切换,并在内部发出一个sys_read()(或者其他等效的调用)以从文件中读取数据,第一个副本由DMA引擎执行,该引擎从磁盘读取文件内容并将它们存储到内核地址空间缓冲区中;
2.请求的数据从读取缓冲区复制到用户缓冲区,然后read()调用返回。调用的返回导致了内核态到用户态的切换,并且现在数据存储在用户地址空间缓冲区中;
3.send()调用导致从用户模式到内核模式的上下文切换,并执行第三次复制以再次将数据放入内核地址空间缓冲区。但是注意这一次数据被放入了一个不同的缓冲区,一个与目标套接字相关联的缓冲区。
4.系统send()调用返回,导致第四个上下文切换。当 DMA 引擎将数据从内核缓冲区传递到协议引擎时,会独立且异步地进行第四次复制。
零拷贝方法的实现过程
如果我们细心观察上面的流程,会发现实际上并不需要第二个和第三个数据副本。应用程序除了缓存数据并将其传输回套接字缓冲区外什么也不做。相反,数据可以直接从读取缓冲区传输到套接字缓冲区。在java中我们可以通过上述提到的transferTo()方法来实现。

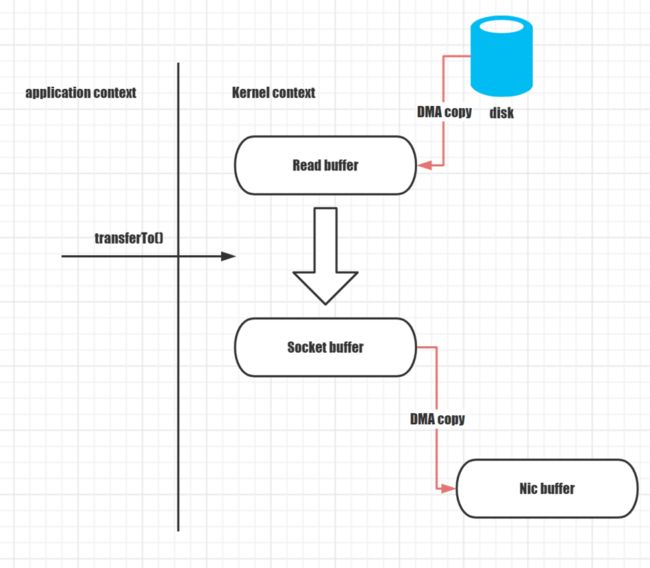
该方法将数据从文件通道传输到给定的可写字节通道。在具体实现中,取决于底层操作系统对零拷贝的支持;在 UNIX 和各种 Linux 系统中,此调用被路由到sendfile()系统调用,如下图所示,它将数据从一个文件描述符传输到另一个文件描述符:

然后我们分析一下具体的数据流转过程,如下图所示:
上下文切换过程如下图所示:

transferTo()方法使 DMA 引擎将文件内容复制到读取缓冲区中。然后内核将数据复制到与输出套接字关联的内核缓冲区中。
第三次复制发生在 DMA 引擎将数据从内核套接字缓冲区传递到协议引擎时。
我们明显可以发现上下文切换的数量从四个减少到两个,并且数据副本的数量从四个减少到三个(其中只有一个涉及 CPU)。但这还没有使我们达到零拷贝的目标。如果底层网络接口卡支持收集操作,我们可以进一步减少内核所做的数据复制。在 Linux 内核 2.4 及更高版本中,修改了套接字缓冲区描述符来支持该功能。这种方法不仅减少了多次上下文切换,而且还消除了需要 CPU 参与的重复数据副本。用户端的用法仍然保持不变,但具体的底层实现函数发生了变化:
transferTo()方法使 DMA 引擎将文件内容复制到内核缓冲区中。
注意此时没有数据被复制到套接字缓冲区中。相反,只有包含有关数据位置和长度信息的描述符才会附加到套接字缓冲区。也就是说相当于只把数据的元数据拷贝到套接字缓冲区,这份消耗通常是可以忽略不计的。DMA 引擎将数据直接从内核缓冲区传递到协议引擎,从而消除了剩余的最终 CPU 副本。
具体的流程如下图所示:

需要注意的是transferTo()方法的方法签名并没有改变,只是操作系统的底层调用函数进行了调整优化。
性能比较
测试环境:
![]()
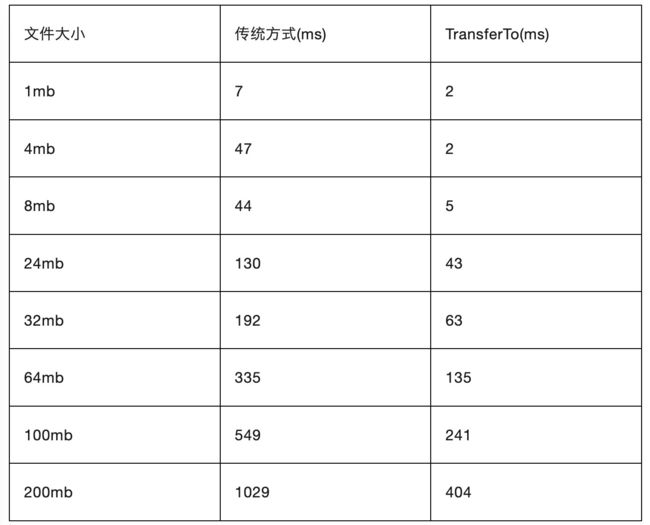
通过观察测试结果可以很明显的看到性能上的提升是非常明显的,对于很多适合的场景,使用零拷贝技术可以显著地提高性能。我们所熟知的kafka内部就采用了零拷贝技术来提高效率。
本文主要对零拷贝技术相对于传统数据传输的优化点进行了简单的分析,并没有深入探究底层的sendfile()系统调用具体是如何实现的,以及如何在编程中具体的实际操作,感兴趣的小伙伴可以自己去深入研究一下噢。

扩展概念
-
DMA(Direct Memory Access)
直译就是直接内存访问,是一种无需CPU的参与就可以让外设与系统内存之间进行双向数据传输的硬件机制。使用DMA可以使系统CPU从实际的I/O数据传输过程中摆脱出来,从而显著提高系统的吞吐率。DMA方式的数据传输由DMA控制器(DMAC)控制,在传输期间,CPU可以并发的执行其他任务。当DMA结束后,DMAC通过中断通知CPU数据传输已经结束,由CPU执行相应的中断服务程序进行后续处理。
-
中断
指处理机处理程序运行中出现的紧急事件的整个过程。程序运行过程中,系统外部、系统内部或者现行程序本身若出现紧急事件,处理机立即中止现行程序的运行,自动转入相应的处理程序(中断服务程序),待处理完后,再返回原来的程序运行,这整个过程称为程序中断;
举个简单的例子:比如小王正在工作(相当于处理机正在处理程序运行),突然接到外卖小哥的电话说外卖到了(相当于接收到中断信号),此时小王就暂时停掉手中的工作去拿外卖(相当于执行中断服务程序),然后再回到工位上继续工作(相当于返回原来的程序继续执行)。