Linux内核角度分析tcpdump原理(二)
上篇文章介绍了在内核角度tcpdump的抓包原理(1),主要流程如下:
-
应用层通过libpcap库:调用系统调用创建socket,
sock_fd = socket(PF_PACKET, SOCK_RAW, htons(ETH_P_ALL));tcpdump在socket创建过程中创建packet_type(struct packet_type),并挂载到全局的ptype_all链表上。(同时在packet_type设置回调函数packet_rcv。 -
网络收包/发包时,会在各自的处理函数(收包时:
__netif_receive_skb_core,发包时:dev_queue_xmit_nit)中遍历ptype_all链表,并同时执行其回调函数,这里tcpdump的注册的回调函数就是packet_rcv。 -
packet_rcv函数中会将用户设置的过滤条件,通过BPF进行过滤,并将过滤的数据包添加到接收队列中。
-
应用层调用recvfrom 。PF_PACKET 协议簇模块调用packet_recvmsg 将接收队列中的数据copy应用层,到此将数据包捕获到。
本文围绕的重点是:BPF的过滤原理,如下源码所示:run_filter(skb, sk, snaplen),本次文章将对BPF的过滤原理进行一些分析。
static int packet_rcv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *pt, struct net_device *orig_dev)
{
......
res = run_filter(skb, sk, snaplen); //将用户指定的过滤条件使用BPF进行过滤
......
__skb_queue_tail(&sk->sk_receive_queue, skb);//将skb放到当前的接收队列中
......
}
tcpdump依附标准的的BPF机器,tcpdump的过滤规则会被转化成一段bpf指令并加载到内核中的bpf虚拟机器上执行,显然,由用户来写过滤代码太过复杂,因此 libpcap 允许用户书写高层的、容易理解的过滤字符串,然后将其编译为BPF代码,tcpdump自动完成,不为用户所见。
一、BPF汇编指令集
关于BPF的介绍以及学习路线可以参考该链接的文章(https://linux.cn/article-9507-1.html),该文章给出了一些阅读清单。
BPF指令集
是一个伪机器码,与能够在物理机上直接执行的机器码不同,BPF指令集是可以在BPF虚拟机上执行的指令集。bpf在内核中实际就是一个虚拟机,有自己定义的虚拟机寄存器组。在最早的cBPF汇编框架中的三种寄存器:
Element Description
A 32 bit wide accumulator//所以加载指令的目的地址和所有指令运算结果的存储地址
X 32 bit wide X register//二元指令计算A中参数的辅助寄存器(例如移位的位数,除法的除数)
M[] 16 x 32 bit wide misc registers aka "scratch memory
store", addressable from 0 to 15// 0-15共16个32位寄存器,可以自由使用
在cBPF每条汇编指令如下这种格式:
// include\uapi\linux\filter.h
struct sock_filter { /* Filter block */
__u16 code; /* 真正的bpf汇编指令 */
__u8 jt; /* 结果为true时跳转指令 */
__u8 jf; /* 结果为false时跳转 */
__u32 k; /* 指令的参数 */
};
我们最常见的用法莫过于从数据包中取某个字的数据来做判断。按照bpf的规定,我们可以使用偏移来指定数据包的任何位置,而很多协议很常用并且固定,例如端口和ip地址等,bpf就为我们提供了一些预定义的变量,只要使用这个变量就可以直接取值到对应的数据包位置。例如:
len skb->len
proto skb->protocol
type skb->pkt_type
poff Payload start offset
ifidx skb->dev->ifindex
nla Netlink attribute of type X with offset A
nlan Nested Netlink attribute of type X with offset A
mark skb->mark
queue skb->queue_mapping
hatype skb->dev->type
rxhash skb->hash
cpu raw_smp_processor_id()
vlan_tci skb_vlan_tag_get(skb)
vlan_avail skb_vlan_tag_present(skb)
vlan_tpid skb->vlan_proto
rand prandom_u32()
cBPF在一些平台还在使用,这个代码就和用户空间使用的那种汇编是一样的,但是在X86架构,现在在内核态已经都切换到使用eBPF作为中间语言了。由于用户可以提交cBPF的代码,所以首先是将用户提交来的结构体数组进行编译成eBPF代码(提交的是eBPF就不用了)。然后再将eBPF代码转变为可直接执行的二进制。eBPF汇编框架下的bpf语句如下:
// include\uapi\linux\bpf.h
struct bpf_insn {
__u8 code; /* 存放真正的指令码 */
__u8 dst_reg:4; /* 存放指令用到的寄存器号(R0~R10) */
__u8 src_reg:4; /* 同上,存放指令用到的寄存器号(R0~R10) */
__s16 off; /* signed offset 取决于指令的类型*/
__s32 imm; /* 存放立即值 */
};
tcpdump -d
tcpdump支持使用-d参数来显示过滤规则转换后的bpf汇编指令。在抓包时我们并不关心如何具体的编写struct sock_filter内的东西,因为tcpdump已经内置了这样的功能。如想要对所接受的数据包过滤,只想抓取TCP协议、端口为8080数据包,那么在tcpdump当中的命令就是tcpdump ip and tcp port 8080 。如果你想让tcpdump帮你编译这样的过滤器,则用tcpdump -d 'ip and tcp port 8080',如下案例(参考《Linux内核观测技术BPF》)如下图所示,显示“tcpdump抓取tcp端口8080数据包”的bpf汇编指令:
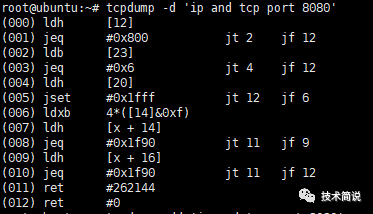
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 12
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 12
(004) ldh [20]
(005) jset #0x1fff jt 12 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 14]
(008) jeq #0x1f90 jt 11 jf 9
(009) ldh [x + 16]
(010) jeq #0x1f90 jt 11 jf 12
(011) ret #262144
(012) ret #0
为了进一步分析这条案例的流程,先把数据包的帧格式和ip数据报的格式放下面便于分析:
以太网帧格式:

IP数据报格式:

001-003条bpf汇编指令进行解释:
(000) ldh [12]:
ldh指令表示累加器在偏移量12处进行加载一个半字(16位),从以太网帧的格式中可以看到偏移量为12字节处为以太网类型字段。
(001) jeq #0x800 jt 2 jf 12:
jeq指令bioassay如果相等则跳转,也就是检查上一条指令返回的以太网类型的值是否为ox800(ipv4的标识),如果为true(jt),就跳转到指令2,否则跳转到指令12。
(002) ldb [23]:
ldb指令在偏移量23字节处进行加载(计算一下:以太网帧的头部是14个字节,那么第23个字节,也就是IP头部的第9个字节),根据IP数据报的格式可以看到第9个字节是“协议”字段。
(003) jeq #0x6 jt 4 jf 12:
jeq指令根据第9个字节的值进行再一次的判断和跳转,如果第9个字节“协议字段”为0x6(TCP),如果是TCP则跳转到下一条指令004,否则跳转到012,数据包进行丢弃。
上面的规则对应代码结构体在Linux内核中的表示其实就是struct sock_filter,在libpcap库中对应的结构体为struct bpf_insn
struct bpf_insn {
u_short code;
u_char jt;
u_char jf;
bpf_u_int32 k;
};
tcpdump -dd
上述使用tcpdump -d看到了过滤规则转换后的bpf汇编指令,上面几个指令:ld开头的表示加载某地址数据,jeq是比较,jt就是jump when true,jf就是jump when false,后面表示行号;tcpdump支持使用-dd参数将匹配信息包的代码以c语言程序段的格式给出:
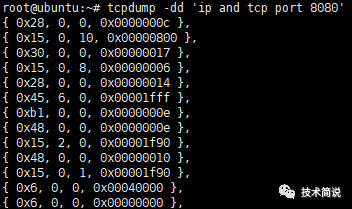
像c当中的数组的定义,这个就是过滤tcp8080数据包的struct sock_filter的数组代码。
二、tcpdump设置BPF过滤器
在libpcap 设置过滤规则用到了两个接口,pcap_compile()和 pcap_setfilter ()
pcap_compile 函数的主要工作就是创建一个bpf的结构体,后面pcap_setfilter 会把生产的规则设置到内核,让规则生效。
struct pcap
在进行分析pcap_compile()和 pcap_setfilter ()前,先介绍一个结构体:struct pcap,介绍后面的过程便于查阅该结构体的成员变量,该结构体在libpcap源码的pcap-int.h中定义,该结构体抓包过程的一个句柄。
struct pcap
{
int fd; /* 文件描述字,实际就是 socket */
/* 在 socket 上,可以使用 select() 和 poll() 等 I/O 复用类型函数 */
int selectable_fd;
int snapshot; /* 用户期望的捕获数据包最大长度 */
int linktype; /* 设备类型 */
int tzoff; /* 时区位置,实际上没有被使用 */
int offset; /* 边界对齐偏移量 */
int break_loop; /* 强制从读数据包循环中跳出的标志 */
struct pcap_sf sf; /* 数据包保存到文件的相关配置数据结构 */
struct pcap_md md; /* 具体描述如下 */
int bufsize; /* 读缓冲区的长度 */
u_char buffer; /* 读缓冲区指针 */
u_char *bp;
int cc;
u_char *pkt;
/* 相关抽象操作的函数指针,最终指向特定操作系统的处理函数 */
int (*read_op)(pcap_t *, int cnt, pcap_handler, u_char *);
int (*setfilter_op)(pcap_t *, struct bpf_program *);
int (*set_datalink_op)(pcap_t *, int);
int (*getnonblock_op)(pcap_t *, char *);
int (*setnonblock_op)(pcap_t *, int, char *);
int (*stats_op)(pcap_t *, struct pcap_stat *);
void (*close_op)(pcap_t *);
/*如果 BPF 过滤代码不能在内核中执行,则将其保存并在用户空间执行 */
struct bpf_program fcode;
/* 函数调用出错信息缓冲区 */
char errbuf[PCAP_ERRBUF_SIZE + 1];
/* 当前设备支持的、可更改的数据链路类型的个数 */
int dlt_count;
/* 可更改的数据链路类型号链表,在 linux 下没有使用 */
int *dlt_list;
/* 数据包自定义头部,对数据包捕获时间、捕获长度、真实长度进行描述 [pcap.h] */
struct pcap_pkthdr pcap_header;
};
/* 包含了捕获句柄的接口、状态、过滤信息 [pcap-int.h] */
struct pcap_md {
/* 捕获状态结构 [pcap.h] */
struct pcap_stat stat;
int use_bpf; /* 如果为1,则代表使用内核过滤*/
u_long TotPkts;
u_long TotAccepted; /* 被接收数据包数目 */
u_long TotDrops; /* 被丢弃数据包数目 */
long TotMissed; /* 在过滤进行时被接口丢弃的数据包数目 */
long OrigMissed; /*在过滤进行前被接口丢弃的数据包数目*/
#ifdef linux
int sock_packet; /* 如果为 1,则代表使用 2.0 内核的 SOCK_PACKET 模式 */
int timeout; /* pcap_open_live() 函数超时返回时间*/
int clear_promisc; /* 关闭时设置接口为非混杂模式 */
int cooked; /* 使用 SOCK_DGRAM 类型 */
int lo_ifindex; /* 回路设备索引号 */
char *device; /* 接口设备名称 */
/* 以混杂模式打开 SOCK_PACKET 类型 socket 的 pcap_t 链表*/
struct pcap *next;
#endif
};
pcap_compile
//函数用于将用户制定的过滤策略编译成BPF代码,然后存入bpf_program结构中
/*
p:pcap_open_live()返回的pcap_t类型的指针
fp:存放编译后的bpf
buf:过滤规则
optimize:是否需要优化过滤表达式
mask:指定本地网络的网络掩码,不需要时可以设置为0
*/
pcap_compile(pcap_t *p,struct bpf_program *fp,char *filterstr,int opt,bpf_u_int32 netmask);
pcap_setfilter
//将过滤的规则注入内核
int pcap_setfilter (pcap_t *p, struct bpf_program *fp)
函数原型:
int pcap_setfilter(pcap_t *p, struct bpf_program *fp)
{
return (p->setfilter_op(p, fp)); //在Linux中将调用pcap_setfilter_linux
}
调用pcap_setfilter_linux:
static int pcap_setfilter_linux(pcap_t *handle, struct bpf_program *filter)
{
return pcap_setfilter_linux_common(handle, filter, 0);
}
进一步调用pcap_setfilter_linux_common:
static int pcap_setfilter_linux_common(pcap_t *handle, struct bpf_program *filter,
int is_mmapped)
{
......
struct sock_fprog fcode;
......
if (install_bpf_program(handle, filter) < 0)//把BPF代码拷贝到pcap_t 数据结构的fcode上
......
/*Linux内核设置过滤器时使用的数据结构是sock_fprog,而不是BPF的结构bpf_program,因此应做结构之间的转换*/
switch (fix_program(handle, &fcode, is_mmapped)) {
//严重错误直接退出
case -1:
default:
return -1;
//通过检查,但不能工作在内核中
case 0:
can_filter_in_kernel = 0;
break;
//BPF可以在内核中工作
case 1:
can_filter_in_kernel = 1;
break;
}
}
//通过检查后,如果可以则在内核中安装过滤器
if (can_filter_in_kernel) {
if ((err = set_kernel_filter(handle, &fcode)) == 0)
{
handlep->filter_in_userland = 0;
}
......
return 0;
}
上面涉及到的Linux内核中的struct sock_fprog和libpcap库中的struct bpf_program如下所示:
struct sock_fprog { /* Required for SO_ATTACH_FILTER. */ unsigned short len; /* Number of filter blocks */ struct sock_filter __user *filter; };struct bpf_program { u_int bf_len; struct bpf_insn *bf_insns;//该结构体上面介绍过,相当于Linux内核中的struct sock_filte };
install_bpf_program(handle, filter)的拷贝过程:
//该函数主要将libpcap bpf规则结构体,转换成符合liunx内核的bpf规则,同时校验规则是否符合要求格式。
int install_bpf_program(pcap_t *p, struct bpf_program *fp)
{
......
pcap_freecode(&p->fcode);//释放可能存在的BPF代码
prog_size = sizeof(*fp->bf_insns) * fp->bf_len;//计算过滤代码的长度,分配内存空间
p->fcode.bf_len = fp->bf_len;
p->fcode.bf_insns = (struct bpf_insn *)malloc(prog_size);
if (p->fcode.bf_insns == NULL) {
snprintf(p->errbuf, sizeof(p->errbuf),
"malloc: %s", pcap_strerror(errno));
return (-1);
}
//把过滤代码保存在捕获句柄中
memcpy(p->fcode.bf_insns, fp->bf_insns, prog_size);//p->fcode就是struct bpf_program
return (0);
}
pcap_setfilter_linux_common最终会在set_kernel_filter中调用setsockopt系统调用(执行到这才真正进入内核,开始在Linux内核上安装和设置BPF过滤器),通过SO_ATTACH_FILTER 下发给内核底层,从而让规则生效,设置过滤器。
static int set_kernel_filter(pcap_t *handle, struct sock_fprog *fcode)
{
......
ret = setsockopt(handle->fd, SOL_SOCKET, SO_ATTACH_FILTER,
fcode, sizeof(*fcode));
......
}
在liunx上,只需要简单的创建的filter代码,通过SO_ATTTACH_FILTER选项发送到内核,并且filter代码能通过内核的检查,这样你就可以立即过滤socket上面的数据了。
三、setsockopt()
Linux 在安装和卸载过滤器时都使用了函数 setsockopt(),其中标志SOL_SOCKET 代表了对 socket 进行设置,而 SO_ATTACH_FILTER 和 SO_DETACH_FILTER 则分别对应了安装和卸载。
-
在套接字socket 附加filter规则 :
setsockopt(sockfd, SOL_SOCKET, SO_ATTACH_FILTER, &val, sizeof(val));
-
·把filter从socket上移除 :
setsockopt(sockfd, SOL_SOCKET, SO_DETACH_FILTER, &val, sizeof(val));
Linux内核在sock_setsockopt函数中进行设置:
//: net\core\sock.c
int sock_setsockopt(struct socket *sock, int level, int optname,
char __user *optval, unsigned int optlen)
{
......
case SO_ATTACH_FILTER:
ret = -EINVAL;
if (optlen == sizeof(struct sock_fprog)) {
struct sock_fprog fprog;
ret = -EFAULT;
//把过滤条件结构体从用户空间拷贝到内核空间
if (copy_from_user(&fprog, optval, sizeof(fprog)))
break;
//在socket上安装过滤器
ret = sk_attach_filter(&fprog, sk);
}
break;
......
case SO_DETACH_FILTER:
//解除过滤器
ret = sk_detach_filter(sk);
break;
......
}
上面出现的 sk_attach_filter() 定义在 net/core/filter.c,它把结构sock_fprog 转换为结构 sk_filter, 最后把此结构设置为 socket 的过滤器:sk->filter = fp。
回到文章开始(抓包的引入):
static int packet_rcv(struct sk_buff *skb, struct net_device *dev,
struct packet_type *pt, struct net_device *orig_dev)
{
......
res = run_filter(skb, sk, snaplen); //将用户指定的过滤条件使用BPF进行过滤
......
__skb_queue_tail(&sk->sk_receive_queue, skb);//将skb放到当前的接收队列中
......
}
run_filter:
static unsigned int run_filter(struct sk_buff *skb,const struct sock *sk,unsigned int res)
{
struct sk_filter *filter;
rcu_read_lock();
filter = rcu_dereference(sk->sk_filter);//获取之前设置的过滤器
if (filter != NULL)
res = bpf_prog_run_clear_cb(filter->prog, skb);//进行数据包过滤
rcu_read_unlock();
return res;
}
综上,结合上一篇文章,和本文就将Linux内核角度将tcpdump的工作原理分析完毕。