kettle开发-Day42-远程执行作业
目录
前言:
一、远程执行
1、先看定义
2、前置条件
2.1网络畅通
2.2数据库DB连接一致
二、实战案例-Windows
1、初始配置-被远程端
1.1启动carte服务
1.2cmd 命令启动carte服务
2、初始化-远程端
3、实际应用
3.1、错误案例
3.2、正确案例
三、总结
前言:
刚开始研究远程执行作业,是为了处理在家里可以在自己电脑上远程处理服务器的作业,后来经过一次次研究,好像事情有点不朝我刚预想的方向转动。但最终还是完成了远程执行的功能,因此记录下对应远程执行作业的一些方法,并校正网上的一些错误,方便一起学习进步。这是最终的执行结果。

一、远程执行
1、先看定义
"Kettle远程执行"通常指在一个计算机上通过网络连接另一台计算机,并在远程计算机上执行Kettle ETL(Extract, Transform, Load)任务或转换。这通常需要使用一些远程连接工具或软件,例如SSH、Telnet或VNC等。这种方式允许用户在不亲自操作远程计算机的情况下,轻松地在远程计算机上运行和监控Kettle任务或转换。
2、前置条件
2.1网络畅通
从上面的定义可以知道,需要远程服务器/电脑来被远程服务器/电脑之间网络畅通。
2.2数据库DB连接一致
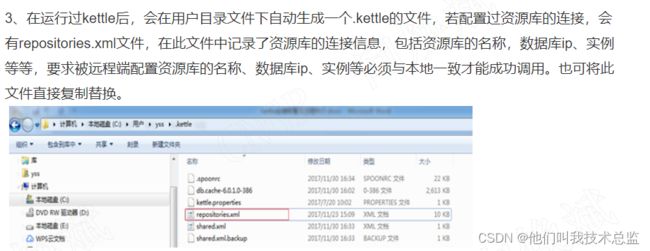
从字面意思来看就是都能访问到对应的数据库,而且对应数据JDBC信息都在两端计算机。并且对应数据库连接名称一致。即在两端有相同的DB连接,即IP/端口/资源名称都一致。

PS:在网上的教程一般是叫你直接替换你远程端的repositories.xml文件,如果你两端的DB连接是不一致的,这样可能会导致远程端的DB连接出现问题,导致远程端的作业出现异常。对应替换repositories.xml文件的操作,可参考下面的操作。
二、实战案例-Windows
1、初始配置-被远程端
1.1启动carte服务
启动cmd,将cmd目录路径切换至被远程端kettle 安装目录Carte.bat的位置,如此次被远程端Carte.bat位于D:\kettle\pdi-ce-5.4.0.1-130\data-integration下。

1.2cmd 命令启动carte服务
此时启动carte服务大致分为下面三步:
--win+R启动运行框,输入cmd,弹出cmd黑框
--切换至D盘
D:
--切换至Carte.bat对应目录
cd D:\kettle\pdi-ce-5.4.0.1-130\data-integration
--启动Carte服务,如 carte 10.100.21.34 8080
carte ip 端口 --如 carte 10.100.21.34 8080当出现这句话的时候,证明carte服务启动成功。

2、初始化-远程端
除了上面说的前置条件,即保持两端网络畅通+有相同的DB连接。此时还需要在远程端建立一个子服务器。

如上图所示我们在kettle的应用端的主对象树,对应下面的子服务器,右键点击新建子服务器,对应服务器名称可以自定义,然后就是上面启动好的Crate服务的ip和端口,默认的用户名密码都是cluster,这样就完成了对应子服务的配置。
3、实际应用
3.1、错误案例
在实际应用中也非常简单,我们只需要按正常配置对应的作业,需要注意的是,要保证对应被调用的转换文件或者作业在被远程端是存在的。即可以在被远程端没有对应的作业,但是需要在对应位置保存对应的转换即被远程的.ktr文件。

如上图所示在被远程端,对应文件夹存在对应test_zy.ktr的文件。因此我们在远程端配置作业的时候,在被调用的转换配置对应目录的转换即可。如下图所示。

PS:在此处,我们最好使用绝对路径,因为我们在被远程端是可以没有对应的作业的,而且使用了相对路径的话,会提示文件不存在,导致carte,默认会从carte所在盘符去扫描对应的转换,及此时默认会认为需远程执行的转换位于D:\test_zy.ktr的。
即会出现如下报错,这也是最容易忽略的问题,血的教训啊。

因此使用绝对路径,绝对路径,绝对路径!!!重要的事情说三遍!
3.2、正确案例
上面介绍了实际应用中的一些配置和容易出现错误的地方,下面来介绍正确远程执行作业是怎样的经过。
此时我们远程执行作业时,我们选择“远程执行”,对应远程主机选择我们配置的子服务器的主机即可。点击后会跳转至远程执行作业的控制面板。

如下图所示我们可以在远程执行控制面板查看对应远程执行作业的整个过程。

如上图所示,我们在控制面板就可以看到对应的执行过程,及对应的执行日志。对应日志内容和本地执行差不多,就是数据整个处理过程。
当面我们也可以在被远程端的carte服务看到对应整个执行过程的日志。

三、总结
其实kettle的远程执行的设计之初,是为了并行开发和集群做的准备。因此当多人开发的时候,我们可以建议共享资源池,这样前面说的前置条件都能轻松完成了。对应网络肯定是畅通的,而且DB连接也是一致的。因为是共享的资源池,我们也能轻松同步对应的转换或者作业到不同的服务器或者电脑。这样我们就可以轻松在本地或者远程执行最新的作业来保证作业执行的最终效果是我们想要的。
当然,如果我们只是想远程执行部分作业,来临时处理一些作业的需求,可参考我的上述操作。当然这样也更好去理解kettle的集群的背后原理。因此我们根据实际应用需求灵活选择吧~