2023-大数据应用开发-工业数据实时处理-参考结果
工业数据实时处理-答案
任务一:实时数据采集
1、 在主节点使用Flume采集/data_log目录下实时日志文件中的数据,将数据存入到Kafka的Topic中(Topic名称分别为ChangeRecord、ProduceRecord和EnvironmentData,分区数为4),将Flume采集ChangeRecord主题的配置截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下;
flume配置内容
a1.sources = r1 r2 r3
a1.sinks = k1 k2 k3
a1.channels = c1 c2 c3
# r1
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume/changerecord/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data_log/.*changerecord.csv
# r2
a1.sources.r2.type = TAILDIR
a1.sources.r2.positionFile = /opt/module/flume/producerecord/taildir_position.json
a1.sources.r2.filegroups = f1
a1.sources.r2.filegroups.f1 = /data_log/.*producerecord.csv
# r3
a1.sources.r3.type = TAILDIR
a1.sources.r3.positionFile = /opt/module/flume/environmentdata/taildir_position.json
a1.sources.r3.filegroups = f1
a1.sources.r3.filegroups.f1 = /data_log/.*environmentdata.csv
# k1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = ChangeRecord
a1.sinks.k1.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# k2
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.topic = ProduceRecord
a1.sinks.k2.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
a1.sinks.k2.kafka.flumeBatchSize = 20
a1.sinks.k2.kafka.producer.acks = 1
a1.sinks.k2.kafka.producer.linger.ms = 1
# k3
a1.sinks.k3.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k3.kafka.topic = EnvironmentData
a1.sinks.k3.kafka.bootstrap.servers = master:9092,slave1:9092,slave2:9092
a1.sinks.k3.kafka.flumeBatchSize = 20
a1.sinks.k3.kafka.producer.acks = 1
a1.sinks.k3.kafka.producer.linger.ms = 1
# c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
# c2
a1.channels.c2.type = memory
a1.channels.c2.capacity = 10000
a1.channels.c2.transactionCapacity = 10000
# c3
a1.channels.c3.type = memory
a1.channels.c3.capacity = 10000
a1.channels.c3.transactionCapacity = 10000
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel = c2
a1.sources.r3.channels = c3
a1.sinks.k3.channel = c3
2、 编写新的Flume配置文件,将数据备份到HDFS目录/user/test/flumebackup下,要求所有主题的数据使用同一个Flume配置文件完成,将Flume的配置截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下。
flume配置内容
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume/tail_dir.json
a1.sources.r1.filegroups = f1 f2 f3
#f1
a1.sources.r1.filegroups.f1 = /data_log/.*producerecord.csv
a1.sources.r1.headers.f1.headerKey1 = producerecord
#f2
a1.sources.r1.filegroups.f2 = /data_log/.*changerecord.csv
a1.sources.r1.headers.f2.headerKey1 = changerecord
#f3
a1.sources.r1.filegroups.f3 = /data_log/.*environmentdata.csv
a1.sources.r1.headers.f3.headerKey1 = environmentdata
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs:///user/test/flumebackup/%Y%m%d/%H/%{headerKey1}
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 60
#设置每个文件的滚动大小大概是128M
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
任务二:使用Flink处理Kafka中的数据
编写Scala工程代码,使用Flink消费Kafka中的数据并进行相应的数据统计计算。
ProduceRecord
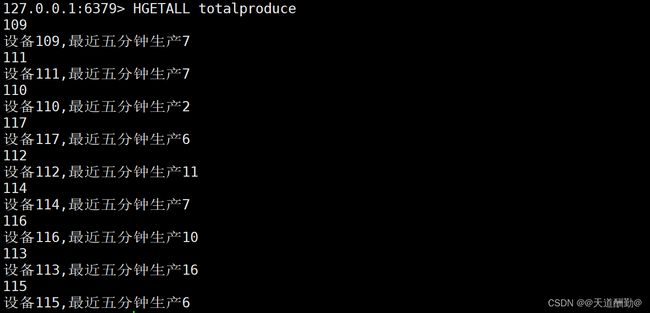
totalproduce
1、 使用Flink消费Kafka中ProduceRecord主题的数据,统计在已经检验的产品中,各设备每5分钟生产产品总数,将结果存入Redis中,key值为“totalproduce”,value值为“设备id,最近五分钟生产总数”。使用redis cli以HGETALL key方式获取totalproduce值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔5分钟以上,第一次截图放前面,第二次截图放后面;
注:ProduceRecord主题,生产一个产品产生一条数据;
change_handle_state字段为1代表已经检验,0代表未检验;
时间语义使用Processing Time。
第一次截图

第二次截图
Produce5minAgg
2、 使用Flink消费Kafka中ProduceRecord主题的数据,统计在已经检验的产品中,各设备每5分钟生产产品总数,将结果存入HBase中的gyflinkresult:Produce5minAgg表,rowkey“设备id-系统时间”(如:123-2023-01-01 12:06:06.001),将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔5分钟以上,第一次截图放前面,第二次截图放后面;
注:ProduceRecord主题,每生产一个产品产生一条数据;
change_handle_state字段为1代表已经检验,0代表为检验;
时间语义使用Processing Time。
| 字段 | 类型 | 中文含义 |
|---|---|---|
| rowkey | String | 设备id-系统时间(如:123-2023-01-01 12:06:06.001) |
| machine_id | String | 设备id |
| total_produce | String | 最近5分钟生产总数 |
第一次截图

第二次截图

ChangeRecord
warning30sMachine
1、 使用Flink消费Kafka中ChangeRecord主题的数据,当某设备30秒状态连续为“预警”,输出预警信息。当前预警信息输出后,最近30秒不再重复预警(即如果连续1分钟状态都为“预警”只输出两次预警信息),将结果存入Redis中,key值为“warning30sMachine”,value值为“设备id,预警信息”。使用redis cli以HGETALL key方式获取warning30sMachine值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面;
注:时间使用change_start_time字段,忽略数据中的change_end_time不参与任何计算。忽略数据迟到问题。
Redis的value示例:115,2022-01-01 09:53:10:设备115 连续30秒为预警状态请尽快处理!
(2022-01-01 09:53:10 为change_start_time字段值,中文内容及格式必须为示例所示内容。)
截图一

截图二

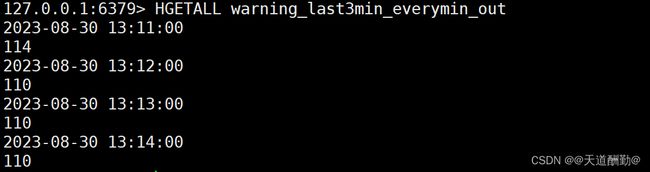
warning_last3min_everymin_out
2、 使用Flink消费Kafka中ChangeRecord主题的数据,每隔1分钟输出最近3分钟的预警次数最多的设备,将结果存入Redis中,key值为“warning_last3min_everymin_out”,value值为“窗口结束时间,设备id”(窗口结束时间格式:yyyy-MM-dd HH:mm:ss)。使用redis cli以HGETALL key方式获取warning_last3min_everymin_out值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面。
注:时间语义使用Processing Time。
第一次截图

第二次截图
threemin_warning_state_agg
3、 使用Flink消费Kafka中ChangeRecord主题的数据,统计每3分钟各设备状态为“预警”且未处理的数据总数,将结果存入MySQL数据库shtd_industry的threemin_warning_state_agg表中(追加写入,表结构如下)。请将任务启动命令复制粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,启动且数据进入后按照设备id升序排序查询threemin_warning_state_agg表进行截图,第一次截图后等待3分钟再次查询并截图,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下。
threemin_warning_state_agg表:
| 字段 | 类型 | 中文含义 |
|---|---|---|
| change_machine_id | int | 设备id |
| totalwarning | int | 未被处理预警的数据总数 |
| window_end_time | varchar | 窗口结束时间(yyyy-MM-dd HH:mm:ss) |
注:时间语义使用Processing Time。
第一次截图

第二次截图

change_state_other_to_run_agg
4、 使用Flink消费Kafka中ChangeRecord主题的数据,实时统计每个设备从其他状态转变为“运行”状态的总次数,将结果存入MySQL数据库shtd_industry的change_state_other_to_run_agg表中(表结构如下)。请将任务启动命令复制粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,启动1分钟后根据change_machine_id降序查询change_state_other_to_run_agg表并截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,启动2分钟后根据change_machine_id降序查询change_state_other_to_run_agg表并再次截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下;
注:时间语义使用Processing Time。
change_state_other_to_run_agg表:
| 字段 | 类型 | 中文含义 |
|---|---|---|
| change_machine_id | int | 设备id |
| last_machine_state | varchar | 上一状态。即触发本次统计的最近一次非运行状态 |
| total_change_torun | int | 从其他状态转为运行的总次数 |
| in_time | varchar | flink计算完成时间(yyyy-MM-dd HH:mm:ss) |
第一次截图

第二次截图

EnvironmentData
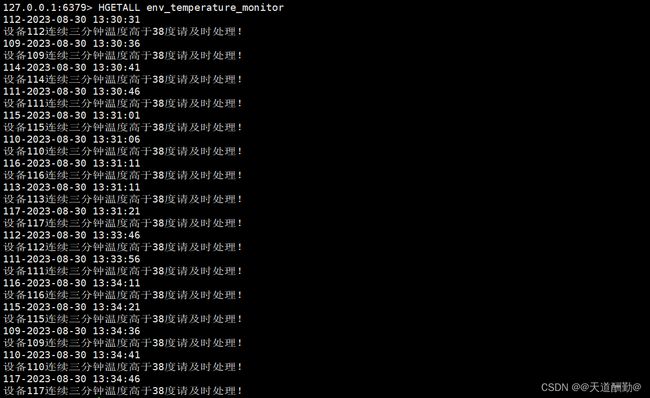
env_temperature_monitor
1、 使用Flink消费Kafka中EnvironmentData主题的数据,监控各环境检测设备数据,当温度(Temperature字段)持续3分钟高于38度时记录为预警数据。将结果存入Redis中,key值为“env_temperature_monitor”,value值为“设备id-预警信息生成时间,预警信息”(预警信息生成时间格式:yyyy-MM-dd HH:mm:ss)。使用redis cli以HGETALL key方式获取env_temperature_monitor值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需要Flink启动运行6分钟以后再截图;
注:时间语义使用Processing Time。
value示例:114-2022-01-01 14:12:19,设备114连续三分钟温度高于38度请及时处理!
中文内容及格式必须为示例所示内容。
同一设备3分钟只预警一次。
第一次截图
env_temperature_monitor
2、 使用Flink消费Kafka中EnvironmentData主题的数据,监控各环境检测设备数据,当温度(Temperature字段)持续3分钟高于38度时记录为预警数据。将结果存入HBase中的gyflinkresult:EnvTemperatureMonitor,key值为“env_temperature_monitor”,rowkey“设备id-系统时间”(如:123-2023-01-01 12:06:06.001),将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需要Flink启动运行6分钟以后再截图;
注:时间语义使用Processing Time。
中文内容及格式必须为示例所示内容。
同一设备3分钟只预警一次。
| 字段 | 类型 | 中文含义 |
|---|---|---|
| rowkey | String | 设备id-系统时间(如:123-2023-01-01 12:06:06.001) |
| machine_id | String | 设备id |
| out_warning_time | String | 预警生成时间 预警信息生成时间格式:yyyy-MM-dd HH:mm:ss |
截图
