前端面试系列-输入url后全过程&&页面渲染机制&&DOM生成过程
文章目录
- 一、当输入url后,全过程
- 二、页面渲染机制
- 三、DOM
-
- 1.什么是 DOM
- 2.DOM 树如何生成
-
- HTML 解析器
- 3.JavaScript 是如何影响 DOM 生成的
-
- 内嵌JavaScript
- 引入 JavaScript 文件
- 引入css文件
- 四、拓展-CSS优化
-
- css异步加载
一、当输入url后,全过程
一般会经历以下几个过程:
1、首先,在浏览器地址栏中输入url
2、浏览器先查看浏览器缓存-系统缓存-路由器缓存,如果缓存中有,会直接在屏幕中显示页面内容。若没有,则跳到第三步操作。
3、在发送http请求前,需要域名解析(DNS解析),解析获取相应的IP地址。
4、浏览器向服务器发起tcp连接,与浏览器建立tcp三次握手。
5、握手成功后,浏览器向服务器发送http请求,请求数据包。
6、服务器处理收到的请求,将数据返回至浏览器
7、浏览器收到HTTP响应
8、读取页面内容,浏览器渲染,解析html源码,并请求html代码中的资源(如js、css、图片等)
9、断开TCP连接
10、浏览器对页面进行渲染呈现给用户
11、ajax查询
其中,步骤2的具体过程是:
浏览器缓存:浏览器会记录DNS一段时间,因此,只是第一个地方解析DNS请求;
操作系统缓存:如果在浏览器缓存中不包含这个记录,则会使系统调用操作系统,获取操作系统的记录(保存最近的DNS查询缓存);
路由器缓存:如果上述两个步骤均不能成功获取DNS记录,继续搜索路由器缓存;
ISP缓存:若上述均失败,继续向ISP搜索。
二、页面渲染机制
1、HTML的加载
HTML是一个网页的基础,下载完成后解析
2、其他静态资源加载
- html顺序加载,其中js会阻塞后续dom和资源加载,如果代码里引用了外部的 CSS 文件,那么在执行 JavaScript 之前,还需要等待外部的 CSS 文件下载完成,并解析生成 CSSOM 对象之后,才能执行 JavaScript 脚本。
- 浏览器会使用prefetch对引用的资源提前下载
- 没有defer或async,HTML的解析会停下来,浏览器会立即加载并执行指定的脚本,等JS下载完执行结束后才继续解析HTML,防止JS修改已经完成的解析结果。
- 有async,加载和渲染后续文档元素的过程将和script.js的加载与执行并行进行(下载一部,执行同步,加载完就执行)
- 有defer,加载后续文档元素的过程将和script.js的加载并行进行(异步),但是script.js的执行要在所有元素解析完成之后,DOMContentLoaded事件触发之前完成
3、DOM树构建
在HTML解析的同时,解析器会把解析完成的结果转换成DOM对象,再进一步构建DOM树
4、CSSOM树构建
CSS下载完之后对CSS进行解析,解析成CSS对象,然后把CSS对象组装起来,构建CSSOM树
5、渲染树构建
当DOM树和CSSOM树都构建完之后,浏览器根据这两个树构建一棵渲染树
6、布局计算
渲染树构建完成以后,浏览器计算所有元素大小和绝对位置
7、渲染
布局计算完成后,浏览器在页面渲染元素。经过渲染引擎处理后,整个页面就显示出来
构建DOM树->构建渲染树->布局渲染树:计算盒模型位置和大小->绘制渲染树
三、DOM
1.什么是 DOM
从网络传给渲染引擎的 HTML 文件字节流是无法直接被渲染引擎理解的,所以要将其转化为渲染引擎能够理解的内部结构,这个结构就是 DOM。DOM 提供了对 HTML 文档结构化的表述。
在渲染引擎中,DOM 有三个层面的作用:
- 从页面的视角来看,DOM 是生成页面的基础数据结构。
- 从 JavaScript 脚本视角来看,DOM 提供给 JavaScript 脚本操作的接口,通过这套接口,JavaScript 可以对 DOM 结构进行访问,从而改变文档的结构、样式和内容。
- 从安全视角来看,DOM 是一道安全防护线,一些不安全的内容在 DOM 解析阶段就被拒之门外了。
概述:DOM 是表述 HTML 的内部数据结构,它会将 Web 页面和 JavaScript 脚本连接起来,并过滤一些不安全的内容。
2.DOM 树如何生成
HTML 解析器
在渲染引擎内部,有一个叫HTML 解析器(HTMLParser)的模块。
HTML 解释器的工作就是将网络或者本地磁盘获取的 HTML 网页和资源从字节流解释成 DOM 树结构。
HTML 解析器并不是等整个文档加载完成之后再解析的,而是网络进程加载了多少数据,HTML 解析器便解析多少数据。
网络进程接收到响应头之后,会根据响应头中的 content-type 字段来判断文件的类型,比如 content-type 的值是“text/html”,那么浏览器就会判断这是一个 HTML 类型的文件,然后为该请求选择或者创建一个渲染进程。渲染进程准备好之后,网络进程和渲染进程之间会建立一个共享数据的管道,网络进程接收到数据后就往这个管道里面放,而渲染进程则从管道的另外一端不断地读取数据,并同时将读取的数据“喂”给 HTML 解析器。

字节流转换为 DOM 需要三个阶段:
- 第一个阶段,通过分词器将字节流转换为 Token。

- 后续的第二个和第三个阶段是同步进行的,需要将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中。
HTML 解析器维护了一个Token 栈结构,该 Token 栈主要用来计算节点之间的父子关系,在第一个阶段中生成的 Token 会被按照顺序压到这个栈中。具体的处理规则如下所示:
- 如果压入到栈中的是StartTag Token,HTML 解析器会为该 Token 创建一个 DOM 节点,然后将该节点加入到 DOM 树中,它的父节点就是栈中相邻的那个元素生成的节点。
- 如果分词器解析出来是文本 Token,那么会生成一个文本节点,然后将该节点加入到 DOM 树中,文本 Token 是不需要压入到栈中,它的父节点就是当前栈顶 Token 所对应的 DOM 节点。
- 如果分词器解析出来的是EndTag 标签,比如是 EndTag div,HTML 解析器会查看 Token 栈顶的元素是否是 StarTag div,如果是,就将 StartTag div 从栈中弹出,表示该 div 元素解析完成。
通过分词器产生的新 Token 就这样不停地压栈和出栈,整个解析过程就这样一直持续下去,直到分词器将所有字节流分词完成。
例子:
1
test
这段代码以字节流的形式传给了 HTML 解析器,经过分词器处理,
解析出来的第一个 Token 是 StartTag html,解析出来的 Token 会被压入到栈中,并同时创建一个 html 的 DOM 节点,将其加入到 DOM 树中
这里需要补充说明下,HTML 解析器开始工作时,会默认创建了一个根为 document 的空 DOM 结构,同时会将一个 StartTag document 的 Token 压入栈底。然后经过分词器解析出来的第一个 StartTag html Token 会被压入到栈中,并创建一个 html 的 DOM 节点,添加到 document 上,如下图所示

然后按照同样的流程解析出来 StartTag body 和 StartTag div,其 Token 栈和 DOM 的状态如下图所示:

接下来解析出来的是第一个 div 的文本 Token,渲染引擎会为该 Token 创建一个文本节点,并将该 Token 添加到 DOM 中,它的父节点就是当前 Token 栈顶元素对应的节点,如下图所示:
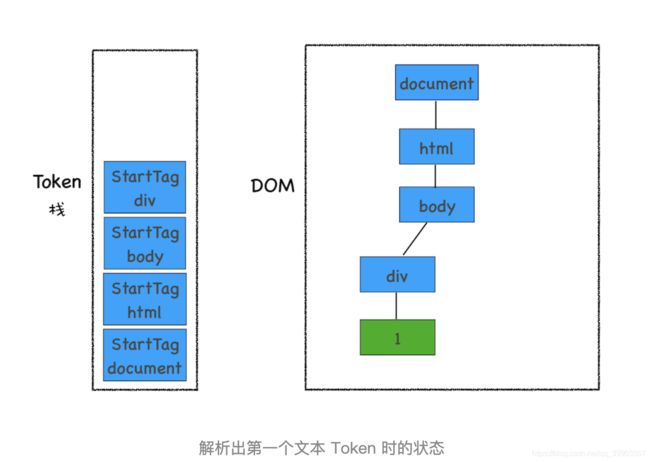
再接下来,分词器解析出来第一个 EndTag div,这时候 HTML 解析器会去判断当前栈顶的元素是否是 StartTag div,如果是则从栈顶弹出 StartTag div,如下图所示

按照同样的规则,一路解析,最终结果如下图所示:

3.JavaScript 是如何影响 DOM 生成的
内嵌JavaScript
例子:
1
test
我在两段 div 中间插入了一段 JavaScript 脚本,这段脚本的解析过程就有点不一样了。script标签之前,所有的解析流程还是和之前介绍的一样,但是解析到script标签时,渲染引擎判断这是一段脚本,此时 HTML 解析器就会暂停 DOM 的解析,因为接下来的 JavaScript 可能要修改当前已经生成的 DOM 结构。
通过前面 DOM 生成流程分析,我们已经知道当解析到 script 脚本标签时,其 DOM 树结构如下所示:

这时候 HTML 解析器暂停工作,JavaScript 引擎介入,并执行 script 标签中的这段脚本,因为这段 JavaScript 脚本修改了 DOM 中第一个 div 中的内容,所以执行这段脚本之后,div 节点内容已经修改为 time.geekbang 了。脚本执行完成之后,HTML 解析器恢复解析过程,继续解析后续的内容,直至生成最终的 DOM。
引入 JavaScript 文件
除了在页面中直接内嵌 JavaScript 脚本之外,我们还通常需要在页面中引入 JavaScript 文件,这个解析过程就稍微复杂了些,如下面代码:
//foo.js
let div1 = document.getElementsByTagName('div')[0]
div1.innerText = 'time.geekbang'
1
test
执行到 JavaScript 标签时,暂停整个 DOM 的解析,执行 JavaScript 代码,不过这里执行 JavaScript 时,需要先下载这段 JavaScript 代码。这里需要重点关注下载环境,因为JavaScript 文件的下载过程会阻塞 DOM 解析,而通常下载又是非常耗时的,会受到网络环境、JavaScript 文件大小等因素的影响。
Chrome 浏览器做了很多优化,其中一个主要的优化是预解析操作。当渲染引擎收到字节流之后,会开启一个预解析线程,用来分析 HTML 文件中包含的 JavaScript、CSS 等相关文件,解析到相关文件之后,预解析线程会提前下载这些文件。
再回到 DOM 解析上,我们知道引入 JavaScript 线程会阻塞 DOM,不过也有一些相关的策略来规避,比如使用 CDN 来加速 JavaScript 文件的加载,压缩 JavaScript 文件的体积。
另外,如果 JavaScript 文件中没有操作 DOM 相关代码,就可以将该 JavaScript 脚本设置为异步加载,通过 async 或 defer 来标记代码,使用方式如下所示:
async 和 defer 虽然都是异步的,不过还有一些差异,
- 使用 async 标志的脚本文件一旦加载完成,会立即执行;
- 而使用了 defer 标记的脚本文件,需要在 DOMContentLoaded 事件之前执行。
或者将 “script“ 元素放在 “body“ 元素后面。
引入css文件
引入外部css样式表
- 外链式
- 导入式
link和import导入外部样式区别:
-
加载顺序
当一个页面被加载的时候(就是被浏览者浏览的时候),link引用的CSS会同时被加载,而@import引用的CSS 会等到页面全部被下载完再被加载。所以有时候浏览@import加载CSS的页面时开始会没有样式。 -
使用DOM控制样式差别
当使用javascript控制dom去改变样式的时候,只能使用link标签,因为@import不是dom可以控制的.
一个例子:
1
test