NeRF数据预处理概述
对于NeRF,可以先回顾NeRF神经辐射场ECCV2020;
首先,我们需要准备多张从不同角度拍摄的同一场景的2D图像,然后用COLMAP估计与相机相关的参数,通过COLMAP可以得到场景的稀疏重建结果,其输出文件包括相机内参,相机外参和3D点的信息,然后进一步利用LLFF开源代码中的imgs2poses文件将内外参整合到一个文件poses_boudns.npy中,假设该场景有 N N N张图像,则poses_boudns.npy存储了一个形状为 N × 17 N\times17 N×17的数组,对于每一行,即每张图像,存储以下信息:
- 该文件记录了相机的内参:包括图片分辨率(图片高度与宽度)、焦距,共3个维度;
- 外参:包括世界坐标到相机坐标转换的平移矩阵 t ∈ R 3 × 1 \textbf{t}\in R^{3\times1} t∈R3×1与旋转矩阵 R ∈ R 3 × 3 \textbf{R}\in R^{3\times3} R∈R3×3,共3+9=12维;
通常,三维场景或3D对象上的每个点 ( x , y , z ) (x,y,z) (x,y,z)是在世界坐标下定义的。坐标1下的位置变换到坐标2下的位置可以利用线性变换完成。 - 另外还有光线的始发深度和终止深度,共2维(COLMAP根据粗略重建的场景大小范围确定光线的深度范围);
论文中提到MLP的输入是 ( x , y , z , θ , ϕ ) (x,y,z,\theta,\phi) (x,y,z,θ,ϕ)是什么,和相机内参外参有什么联系?要明白这个问题,先要理解坐标变换。
总的来说,坐标变换的目的在于将不同视角下视角特定的坐标系投影到一个统一的世界坐标中进行三维重建,见get_rays_np函数。首先,我们在像素坐标下进行网格点采样,得到特定分辨率图像的各个像素点坐标。
然后,进行像素坐标到相机坐标的变换。像素坐标到相机坐标的变换属于投影变换的逆变换,即2D点到3D的变化,即我们需要根据像素点的坐标 ( u , v ) (u,v) (u,v)计算该像素点在相机坐标系下的三维坐标 ( x c , y c , z c ) (x_c,y_c,z_c) (xc,yc,zc);
然后,我们进行相机坐标到世界坐标的转换得到光线始发点与方向向量:
- 首先因为相机坐标与世界坐标的坐标原点不一致,要解决这个问题只需要将相机坐标进行平移即可进行对齐,实现平移的方式在是相机坐标系下减去一个平移矩阵,即相机外参中的平移矩阵 t \textbf{t} t;
- 此外,由于相机坐标与世界坐标的各个轴的朝向也是不同的,因此需要进一步通过旋转来对齐坐标轴的朝向,实现旋转的方式是在平移对齐坐标原点之后的基础上进行旋转,即与相机外参中的旋转矩阵 R \textbf{R} R的逆做矩阵乘法;最后我们得到 r o \textbf{r}_{o} ro(像素是光线渲染的, r o \textbf{r}_{o} ro相当于是世界坐标下的当前光线出发位置,详情看图1)和得到 r d \textbf{r}_{d} rd(世界坐标下,当前光线的方向);
现在,我们通过了相机的内外参数将像素坐标转换为了统一的世界坐标下的光线始发点与方向,结合深度 t t t(范围在光线的始发深度和终止深度内),可以得到当前光线上任意一点的位置 r ( t ) = r o + t r d \textbf{r}(t)=\textbf{r}_{o}+t\textbf{r}_{d} r(t)=ro+trd;
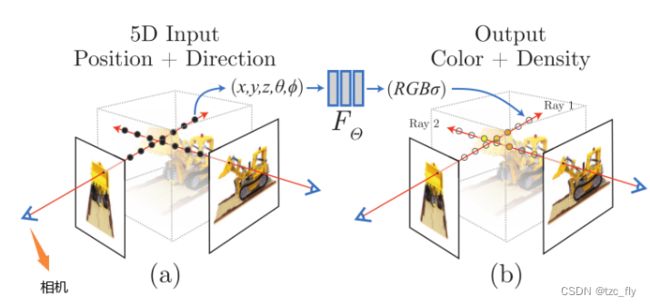
- 图1:观察a,可以看到图像,相机,真实场景的对应关系。相机射出光线穿过当前图像的某个像素,我们从像素坐标开始(即图像),然后获得该像素在相机坐标下的位置,又获得在世界坐标下的位置,此时的位置为光线的发出点 r o \textbf{r}_{o} ro,结合光线的方向 r d \textbf{r}_{d} rd(相机连接该像素的方向),我们就能追踪该光线上的每个点。
所以实际上,NeRF的MLP并不是5D的输入 ( x , y , z , θ , ϕ ) (x,y,z,\theta,\phi) (x,y,z,θ,ϕ),而是 r ( t ) \textbf{r}(t) r(t)(在世界坐标下看还是 ( x , y , z ) (x,y,z) (x,y,z))和标准化处理的 r d \textbf{r}_{d} rd(对应观察方向 ( θ , ϕ ) (\theta,\phi) (θ,ϕ),但 r d \textbf{r}_{d} rd是三维的);
渲染时,我们沿着 r d \textbf{r}_{d} rd采样出很多 r ( t ) \textbf{r}(t) r(t),对这些点上的MLP输出的RGB结果求和作为最终的RGB。
注意NeRF中所说的观察方向,严格来说,是相机连接某个像素的方向,因为我们要沿着这个方向去渲染得到像素的值。