C++ string
目录
-
- string类介绍
- 访问:
-
- [ ] 遍历
- 迭代器遍历
- 范围for遍历
- 容量相关:
- 修改相关:
- 编码表的了解
- 写时拷贝的了解
- string的模拟
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。
string类介绍
string属于标准库,因为它的产生比stl早一些
C++为了避免跟c语言库冲突,头文件不带.h
string可以管理字符数组
求长度不能用strlen,strlen不能对自定义对象使用,而且自定义对象里面的内置类型的私有成员也不能随便访问,不同编译器下私有成员名字可能不一样。

平时用string没有用模板,实际上它是模板,只是库typedef过,因为大多数情况用的都是char,所以就实例化了

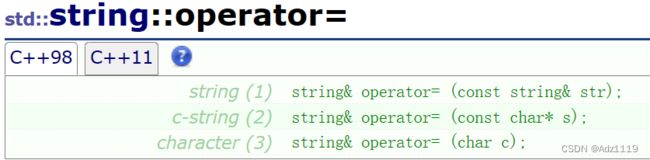
1、4是常用的构造,2是拷贝构造,3是用str对象的一部分去构造,5是用str的前n个初始化,6是用n个字符c去初始化,7可以用迭代区间去初始化

npos是string里的静态成员变量,类型是size_t, -1类型提升,全1的无符号是整形的最大值
string s1;
string s2("hello");
cin >> s1;
cout << s1 << endl;
cout << s2 << endl;
//char str[1600];对比c语言,c++按需申请使用会更方便
//scanf()
//想拼接两个string的话
string ret1 = s1 + s1;
cout << ret1 << endl;
//和字符串相加也可以
string ret2 = s1 + "你好";
cout << ret2 << endl;
//相比于c语言中的strcat可读性会更好,而且strcat也不能扩容
//strcat得找'\0',string中有size(),可以直接找到结尾
string s1("hello world");
string s2 = "hello world";
两种带参构造都可以用
用常量字符串初始化
第一种是构造
第二种是构造+拷贝构造,单参数的构造函数支持隐式类型转换
访问:
[ ] 遍历

// 遍历string
for (size_t i = 0; i < s1.size(); i++)
{
// 读
cout << s1[i] << " ";
}
cout << endl;
for (size_t i = 0; i < s1.size(); i++)
{
// 写
s1[i]++;
}
cout << s1 << endl;
at是一个函数跟[ ] 重载 不同的是at失败后(比如越界)会抛异常,[]是断言,会终止程序。

s2[0]++;
s2.at(0)++;
[]用起来会更直观
迭代器遍历
迭代器是遍历数据结构的一种方式,目前可以想象成指针,因为使用起来很像
每个数据结构的迭代器都是在类里面定义(或typedef)的,属于这个类域
// 迭代器
string::iterator it = s1.begin();
//while (it < s1.end())
//这里可以但是不建议,因为如果是别的数据结构就不支持了,比如list
while (it != s1.end()) // 推荐玩法,通用
{
// 读
cout << *it << " ";
++it;
}
cout << endl;
it = s1.begin();
while (it != s1.end())
{
// 写
*it = 'a';
++it;
}
cout << endl;
cout << s1 << endl;
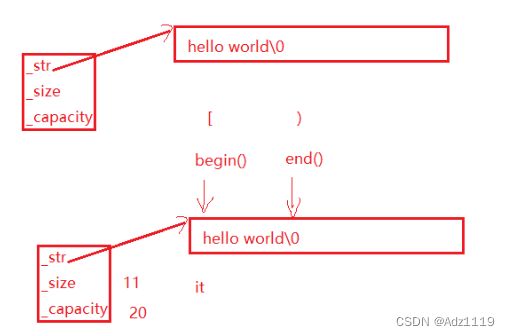
[ ]用起来方便但不是每个数据结构都能用,它针对底层是连续的物理空间的数据结构,迭代器才是通用的方式
迭代器屏蔽了底层细节,很好体现了c++的封装


cbegin这些是想把const iterator区分出来,但其实还是直接用begin就好


普通的iterator支持读和写,const iterator只能读
const对象要调用const版本的begin,const版本begin返回const的迭代器
所以迭代器要和s.begin()返回一致
void func(const string& s)
{
//string::const_iterator it = s.begin();
auto it = s.begin();
while (it != s.end())
{
// 不支持写
// *it = 'a';
// 读
cout << *it << " ";
++it;
}
cout << endl;
//string::const_reverse_iterator rit = s.rbegin();
auto rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit << " ";
++rit;
}
cout << endl;
}
void test_string4()
{
string s1("hello worldxxxxxxxxxxxxxxxxxxxxyyyyyyyyyyyyyyyy");
func(s1);
}
范围for遍历
// 原理:编译器编译器替换成迭代器
// 读
for (auto ch : s1)
{
cout << ch << " ";
}
cout << endl;
// 写
for (auto& ch : s1)//ch相当于*it的拷贝,所以加&才能修改
{
ch++;
}
cout << endl;
cout << s1 << endl;
容量相关:
size和length


string的产生比stl早,所以当时用的是length
size 具有通用性
‘\0’标识结束,size不算’\0’
动态增长的数组还需要’\0’是因为要兼容c语言
让string能和c的接口结合起来
string filename;
cin >> filename;
FILE* fout = fopen(filename.c_str(), "r");

clear清除数据,stl没有严格规定是否释放空间,一般是不会释放的,因为清掉之后可能还要继续插入数据
max_size本意是想告诉我们string最长有多长,不同平台下实现不同,它是写死的,在我们内存不够时告诉我们也开不了。所以基本用不上。
扩容是怎么扩的?
void test_string6()
{
string s;
size_t old = s.capacity();
cout << "初始" << s.capacity() << endl;
for (size_t i = 0; i < 100; i++)
{
s.push_back('x');
if (s.capacity() != old)
{
cout << "扩容:" << s.capacity() << endl;
old = s.capacity();
}
}
}

在vs上我们会发现string s,它没有存数据,容量居然是15,也就是16的空间,这是因为开了一个16字节的数组
小于16,字符串存到buff数组里面
大于等于16,存在_str指向的空间,buff里面的空间就不要了
这是为了避免系统频繁开小块内存而引发内存碎片
平时string也比较小
_buff[16]
_str
_size
_capacity
reserve和resize

g++下要100就会给100,vs2019下要100会给111
可以提前开空间,减少扩容,提高效率
stl没有规定reserve能不能减少空间,一般实现是不会减的(比如g++和vs)

不给c默认是给’\0’
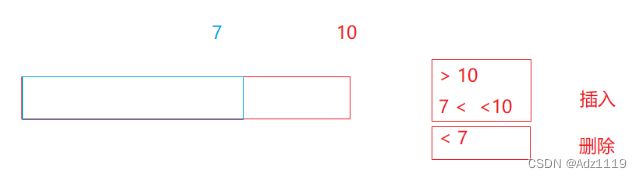
让size变到n
修改相关:
插入单个字符

插入字符串

//用的多的也就3和1
string ss("world");
string s;
s.push_back('#');
s.append("hello");
s.append(ss);
cout<<s<< endl;


s += '#';
s += "hello";
s += ss;
cout << s << endl;
string ret1 = ss + '#';
string ret2 = ss + "hello";
cout << ret1 << endl;
cout << ret2 << endl;
+的效率会较低(拷贝构造再传值返回),尽量用+=

assign,赋值,会把原来的数据覆盖
std::string str("xxxxxxx");
std::string base = "The quick brown fox jumps over a lazy dog.";
str.assign(base);
std::cout << str << '\n';

insert/erase/repalce能不用就尽量不用,因为他们都涉及挪动数据,效率不高
接口设计复杂繁多,需要时查一下文档即可

string中swap的有效使用场景
空格替换为20%
std::string s2("The quick brown fox jumps over a lazy dog.");
string s3;
for (auto ch : s2)
{
if (ch != ' ')
{
s3 += ch;
}
else
{
s3 += "20%";
}
}
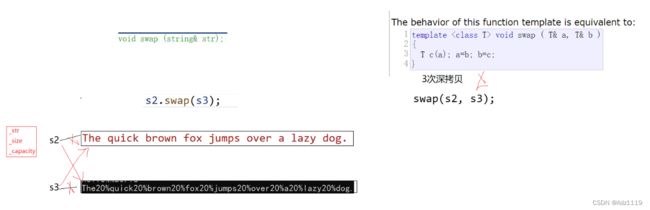
模板的swap代价太高,string全局函数还提供了一个swap,所以就不会调用模板的swap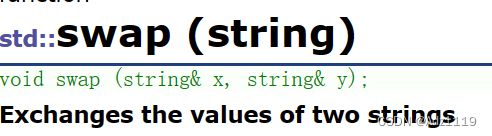
find系列
find从字符串pos位置开始往后找字符c
rfind从字符串pos位置开始往前找字符c
substr找子串:从pos位置开始,截取n个字符,然后返回

void test_string11()
{
//string s3("https://legacy.cplusplus.com/reference/string/string/rfind/");
string s3("ftp://www.baidu.com/?tn=65081411_1_oem_dg");
// 协议
// 域名
// 资源名
string sub1, sub2, sub3;
size_t i1 = s3.find(':');
if (i1 != string::npos)
sub1 = s3.substr(0, i1);
else
cout << "没有找到i1" << endl;
size_t i2 = s3.find('/', i1+3);
if (i2 != string::npos)
sub2 = s3.substr(i1+3, i2-(i1+3));
else
cout << "没有找到i2" << endl;
sub3 = s3.substr(i2 + 1);
cout << sub1 << endl;
cout << sub2 << endl;
cout << sub3 << endl;
}
编码表的了解
string为什么设计成模板?
内存中不能存a、b、c这种概念,内存中只有01,只能组合成值,值和符号之间要有联系就要建立一一映射的关系,这就是编码表
每个国家都需要一套编码表
我们的文字很多,一个字节一个汉字是不够表示的(8个bit有2^8个值)

各个国家文字数量的不同
主要有三类方案 UTF-8、UTF-16、UTF-32
这是国际上的,为了更好表示中文,我们也有自己的一份编码表比如GBK。

兼容ascll,常用的汉字用两个字节(110 10)编,相对生僻的用三个字节(110 10 10)编,特别生僻的用四个字节编


假设一段文字是用UTF-8写的,然后改成另外一个编码,查的时候对不上,就会出现乱码(存储格式和解释方式对应不上)
我们有时候会出现烫烫烫烫烫是因为数组没有初始化的时候是随机值,这个随机值是1开头被解释成汉字,查编码表正好是烫,取决于编译器用的是什么编码。
写时拷贝的了解



string的模拟
vs下:在类里定义静态成员变量时发现在类里可以定义的特例
const static size_t npos = -1;//针对const 静态的 整形类型开了一个特例
const static double npos = 1.1; //double就不行了
#include