【MySQL】数据库的约束
MySQL 数据库的约束
文章目录
- MySQL 数据库的约束
-
- 01 数据库的约束
-
- 1.1 约束类型
-
- 1.1.1 NOT NULL
- 1.1.2 UNIQUE
- 1.1.3 DEFAULT
- 1.1.4 PRIMARY KEY
- 1.1.5 FOREIGN KEY
- 1.1.6 CHECK
继上文 MySQL基础(一), MySQL基础(二),接下来的大块知识点是 MySQL 查询的进阶~
因为增删改其实没什么进阶的~
但是!在此之前,我们先来讲讲另外的一些知识点,再开始讲查询的进阶~
01 数据库的约束
有些时候,数据库中的数据是有一定约束的~
有些数据是合法数据,有些是非法数据~那我们该怎么判断数据是否合法呢?人工检查靠谱不?
当然是不靠谱的,相对于计算机来说~
数据库,自动地对数据合法性进行校检检查地一系列机制~~目的就是为了保证数据库中能够避免被插入/修改一些非法的数据
1.1 约束类型
MySQL中提供了以下约束:
- NOT NULL :指示某列不能存储NULL值
- UNIQUE :保证某列的每行必须有唯一的值
- DEFAULT :规定没有给列赋值时的默认值
- PRIMARY KEY :NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY:保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK:保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
在讲解之前,我们先把以前的测试用例删除~
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test |
+--------------------+
5 rows in set (0.00 sec)
mysql> show tables;
ERROR 1046 (3D000): No database selected
mysql> use test;
Database changed
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| exam_result |
| student |
+----------------+
2 rows in set (0.01 sec)
mysql> drop table student;
Query OK, 0 rows affected (0.02 sec)
mysql> drop table exam_result;
Query OK, 0 rows affected (0.01 sec)
mysql> show tables;
Empty set (0.00 sec)
1.1.1 NOT NULL
我们先正常操作,不添加任何约束。
mysql> create table student(id int, name varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> insert student values(null, null);
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+------+------+
| id | name |
+------+------+
| NULL | NULL |
+------+------+
1 row in set (0.00 sec)
再者我们添加NOT NULL约束看看区别~
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int not null, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student values (null, null);
ERROR 1048 (23000): Column 'id' cannot be null
-- Column 'id' cannot be null 这时他就会报错,那么我们再次查询表看看
mysql> select * from student;
Empty set (0.00 sec)
-- 表是空的~
-- 下面我们看看not null也同样适用于插入
mmysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
+----+------+
1 row in set (0.01 sec)
mysql> update student set id = null where name = '张三';
ERROR 1048 (23000): Column 'id' cannot be null
1.1.2 UNIQUE
唯一值~
见以下代码:
mysql> create table student(id int, name varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
| 1 | 张三 |
| 1 | 张三 |
| 1 | 张三 |
+------+------+
4 rows in set (0.00 sec)
-- ==============================================================
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int unique, name varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(1, '张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'id'
mysql> insert into student values(1, '张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'id'
-- Duplicate(重复) entry(条目) 哈哈 重复不了咯 ~
mysql> select * from student;
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
+------+------+
1 row in set (0.00 sec)
这个UNIQUE不仅仅是在限制插入,也会限制修改~
同时,我们要知道,unique约束,会让后续插入/修改数据的时候,都会触发一次查询操作,
通过这个查询,来确定当前这个记录是否已经存在~~
因此!数据库引入约束之后,执行效率就会受到影响,就可能会降低很多,这就意味着,数据库其实是一个比较慢的系统,也是比较吃资源的系统,部署数据库的服务器,很容易称为一整个系统的“性能瓶颈”。
1.1.3 DEFAULT
默认值 ~
-- 实际上我们在 desc 表名; 就可以看出来 ~
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | UNI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
-- 这其中的 Default 那一列,其实就是在描述这一列的默认值 默认的默认值就是NULL,我们可以通过default约束来修改这一默认值
这里针对上述的desc来插嘴一句,
desc 表名;
-- desc => describe 描述
order by 列名 desc;
-- desc => descend 降序
看看default的效果如下代码~
mysql> create table student(id int, name varchar(20) default '未命名');
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | 未命名 | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
那么这样,后续插入数据的时候,default就会在没有显示指定插入的值的时候生效了~
如下:
mysql> insert into student (id) values (1);
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+------+--------+
| id | name |
+------+--------+
| 1 | 未命名 |
+------+--------+
1 row in set (0.00 sec)
1.1.4 PRIMARY KEY
这个是最重要的一个约束
是一行记录的身份标识~
指定id为主键:
create table student (id int primary key, name varchar (20));
✍️✍️一张表里只能有一个primary key,一个表里的记录,只能有一个作为身份标识的数据~~
或许你就会产生一个问题,为什么就只能一个呢???
那么我们假设这个表里有多个primary key,那么我们以谁位基准呢?
简单粗暴,我们通过 MYSQL 直接来看就好~
mysql> create table student2 (id int primary key, name varchar(20) primary key);
ERROR 1068 (42000): Multiple primary key defined -- 已定义多个主键
虽然我们只有一个主键,但是逐渐不一定是一个列,也可以是多个列共同构成的一个主键(联合主键)。
mysql> insert into student values (1, '张三');
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values (1, '张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
mysql> insert into student values (null, '张三');
ERROR 1048 (23000): Column 'id' cannot be null
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
-- PRI 主键
对于带有主键的表来说,每次插入数据/修改数据,也会涉及到进行先查询的操作
MySQL 会把带有unique和primary key 的列自动生成索引,从而加快查询速度
那么我们怎么保证主键唯一呢?
MySQL 提供了一种 “ 自增主键 ”的机制。
主键经常会使用int/bigint
在我们插入数据的时候,不必手动指定主键值~由数据库服务器自己给你分配一个主键,会从 1 开始,依次递增的分配主键的值~
这里提供自动主键的一个例子:
create table student (id int primary key auto_increment, name varchar(20));
mysql> desc student;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
对于整数类型的主键,常配搭自增长auto_increment来使用。插入数据对应字段不给值时,使用最大值+1。
mysql> insert into student values(null, '张三');
Query OK, 1 row affected (0.01 sec)
-- 这里的null也就是我们的自增主键 id : 1,也就是交给数据库服务器自行分配~
mysql> select * from student;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
+----+------+
1 row in set (0.00 sec)
一些自增主键的注意点:
mysql> insert into student values(null, '李四');
Query OK, 1 row affected (0.01 sec)
mysql> insert into student values(null, '王五');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+----+------+
3 rows in set (0.00 sec)
mysql> insert into student values(10, '李六');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
| 10 | 李六 |
+----+------+
4 rows in set (0.00 sec)
mysql> insert into student values(null, '田七');
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
+----+------+
| id | name |
+----+------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
| 10 | 李六 |
| 11 | 田七 |
+----+------+
5 rows in set (0.00 sec)
就是从刚才 最大的数值 开始,继续往后分配的~~
相当于使用了一个变量,来保存当前表的id的最大值,后续分配自增主键都是根据这个最大值来分配的
如果手动指定 id ,也会更新最大值。4-9之间的id也就是浪费了。
比处这里的id的自动分配,也是有一定局限性的~~
如果是单个mysql服务器,那是没问题的.
如果是一个分布式系统有多个ysql服务器构成的集群,这个时候依靠自增主键就不行了~
1.1.5 FOREIGN KEY
外键~描述两个表之间的关联关系
下面来点例子:
| class | class | name |
|---|---|---|
| 100 | MySQL100班 | |
| 101 | MySQL101班 | |
| 102 | Java100班 | |
| 103 | Java101班 |
| student | id | name | class id |
|---|---|---|---|
| 1 | 张三 | 100 | |
| 2 | 李四 | 100 | |
| 3 | 王五 | 101 | |
| 4 | 赵六 | 300 |
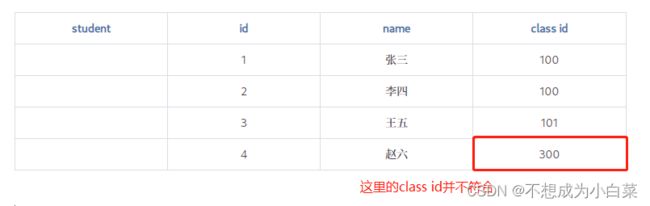
外键就是用来描述这样的约束过程的~
class 表中的数据,约束了student 表中的数据,把class表,称为“父表”,也就是约束别人的表;把student 表,称为“子表”,也就是别人约束的表。
见以下示例代码:
references引用,此处表示了当前这个表的这一列中的数据,应该出自另一个表的哪一列
mysql> create table class(
-> class int primary key,
-> name varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into class values (100, 'MySQL100班'), (101, 'MySQL101班'), (102, 'Java100班'), (103, 'Java101班');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> create table student (id int primary key, name varchar(20), classid int);
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student values (1, '张三', 200);
Query OK, 1 row affected (0.01 sec)
mysql> select * from class;
+-------+------------+
| class | name |
+-------+------------+
| 100 | MySQL100班 |
| 101 | MySQL101班 |
| 102 | Java100班 |
| 103 | Java101班 |
+-------+------------+
4 rows in set (0.00 sec)
mysql> select * from student;
+----+------+---------+
| id | name | classid |
+----+------+---------+
| 1 | 张三 | 200 |
+----+------+---------+
1 row in set (0.00 sec)
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
-- -----------------------------------------------------------------------------------------
mysql> create table student
mysql> (id int primary key, name varchar(20), classid int, foreign key(classid) references class(class));
-- foreign key(classid) 这里的classid是被约束的列
-- class(class) 数据是被class表的class这一列约束的
-- 即 student的classid的数据出自于class表的class这一列
Query OK, 0 rows affected (0.02 sec)
mysql> insert into student values(1, '张三', 100);
Query OK, 1 row affected (0.01 sec)
-- 执行这个插入操作,就会触发针对class表的查询.就会查100是否是在class中存在~~
mysql> insert into student values(2, '李四', 200);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`test`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classid`) REFERENCES `class` (`class`))
-- 约束失败
mysql> update student set classid = 200 where id = 1;
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`test`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classid`) REFERENCES `class` (`class`))
父表约束子表,言传身教~
比如,针对父表进行修改/删除操作,如果当前被修改/删除的值,已经被子表引用了,这样的操作也会失败!
外键约束始终要保持,子表中的数据在对应的父表的列中,要存在~~
此时万一把父表的这条数据删除了,也就打破了刚才的约束了~~
当你凝视深渊的时候,深渊也在凝视你!~
mysql> select * from class;
+-------+------------+
| class | name |
+-------+------------+
| 100 | MySQL100班 |
| 101 | MySQL101班 |
| 102 | Java100班 |
| 103 | Java101班 |
+-------+------------+
4 rows in set (0.00 sec)
mysql> select * from student;
+----+------+---------+
| id | name | classid |
+----+------+---------+
| 1 | 张三 | 100 |
+----+------+---------+
1 row in set (0.00 sec)
mysql> delete from class where class = 103;
Query OK, 1 row affected (0.01 sec)
mysql> select * from class;
+-------+------------+
| class | name |
+-------+------------+
| 100 | MySQL100班 |
| 101 | MySQL101班 |
| 102 | Java100班 |
+-------+------------+
3 rows in set (0.00 sec)
mysql> delete from class where class = 100;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`test`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classid`) REFERENCES `class` (`class`))
外键准确来说,是两个表的列产生关联关系其他的列是不受影响的
这里提出一个问题:如果想drop table class,是否可以删除整个表?
答案是不可以的!
要想删除表,就得先删除记录
父表没了,子表后续添加新的元素,就没有参考了~
mysql> drop table class;
ERROR 1217 (23000): Cannot delete or update a parent row: a foreign key constraint fails
mysql> delete from student;
Query OK, 1 row affected (0.01 sec)
mysql> select * from student;
Empty set (0.00 sec)
mysql> drop table class;
ERROR 1217 (23000): Cannot delete or update a parent row: a foreign key constraint fails
那该怎么办呢?
实际上我们先删子表,再删父表就ok了~
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> drop table class;
Query OK, 0 rows affected (0.01 sec)
那好,我们将表删完,来看看下面这个例子
mysql> create table class(classId int, name varchar(20));
Query OK, 0 rows affected (0.02 sec)
mysql> create table student(studentId int primary key, name varchar(20), classId int, foreign key(classId) references class(classId));
ERROR 1215 (HY000): Cannot add foreign key constraint
-- 为什么报错呢?
-- 实际上就是因为class表没有主键 正确的写法应该是:create table class(classId int primary key, name varchar(20));
-- 指定外键约束的时候,要求父表中被关联的这一列,得是主键或者 unique
再来看看下面这场景:
场景:电商网站
商品表(goodsId,.........);
1 男士女装
订单表(orderId,goodsId..)foreign key (goodsId) references 商品表 (goodsId);
过了一段时间,商家想把男士女装下架,那么我们后端怎么完成删除?
尝试删除附表数据的时候,如果父表的数据被子表运用了,是无法删除的
所以我们怎么保证外键约束存在的前提下首先“商品下架”的功能?
答案:
把要下架的商品隐藏起来,让顾客查询商品的时候查询不到下架的商品,但是商品表里对应的商品还存在,也就不会影响到之前下过的订单间接实现了商品的下架。
给商品表 新增一个单独的列,表示是否在线。(不在线,就相当于下架了)
商品表(goodsId, name, price..., isOk);
isOk -> 1 : 表示商品在线
-> 0 : 表示商品下线
如果需要下架商品,使用 update 把 isOk 从 1->0 即可
查询商品的时候,都加上where isOk = 1 这样的条件
这种思路也被称这为"逻辑删除"。比如说:
电脑上有个xx文件,你想删除掉,也是通过逻辑删除的方式实现的,
在硬盘上,数据还有,被标记成无效了.后续其他文件就可以重复利用这块硬盘空间了
比如想把电脑的某个文件彻底删除掉,通过扔进回收站,清空回收站.没有卵用的~~
硬盘上的数据啥时候彻底消亡,就需要时间,需要后续有文件把这块标记无效的空间重复利用,才会真正消失~~
按照逻辑删除的思路,表中的数据,会无限的扩张??
是否就会导致硬盘空间被占满??
当然是会有的写代码不要抠搜
硬盘,就比较便宜~~
也可以通过增加主机(分布式)来进一步的扩充存储空间.
1.1.6 CHECK
MySQL使用时不报错,但忽略该约束:
drop table if exists test_user;
create table test_user (
id int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
);