【MySQL】索引
1.索引
1.1 为啥需要索引?
对于数据库而言,查询始终是一个高频的操作;假设在数据量到百万级的时候,查询一个用户信息就要花5秒中,那用户肯定不愿意等待你的系统响应,这就造成了用户流失。
所以,MySQL必须使用某种方式来保证查询的高速可靠,索引就诞生了;
对于使用者而言,索引是很香的,因为你只需要执行create index给指定的列,那么MySQL就会自动帮你维护一系列索引创建的操作,查询嘎嘎快!
但,查询速度的提高是以插入、更新、删除等操作的速度为代价的,这些写操作会增加大量的IO;索引的价值在于提高海量数据的查询速度;
常见的索引
- 主键索引
- 唯一键索引
- 普通索引
- 复合索引
- 全文索引
1.2 索引的效果
通过如下的大数据用例,我们能看到索引的效果几何
drop database if exists `bit_index`;
create database if not exists `bit_index` default character set utf8;
use `bit_index`;
-- 构建一个8000000条记录的数据
-- 构建的海量表数据需要有差异性,所以使用存储过程来创建, 拷贝下面代码就可以了,暂时不用理解
-- 产生随机字符串
delimiter $$
create function rand_string(n INT)
returns varchar(255)
begin
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
delimiter ;
-- 产生随机数字
delimiter $$
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
delimiter ;
-- 创建存储过程,向雇员表添加海量数据
delimiter $$
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i + 1;
insert into EMP values ((start+i)
,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
commit;
end $$
delimiter ;
-- 雇员表
CREATE TABLE `EMP` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
-- 执行存储过程,添加8000000条记录
call insert_emp(100001, 8000000);
在这个表里面,有大量的数据,其默认状态下,并没有配置索引
MariaDB [bit_index]> desc EMP;
+----------+--------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+--------------------------+------+-----+---------+-------+
| empno | int(6) unsigned zerofill | NO | | NULL | |
| ename | varchar(10) | YES | | NULL | |
| job | varchar(9) | YES | | NULL | |
| mgr | int(4) unsigned zerofill | YES | | NULL | |
| hiredate | datetime | YES | | NULL | |
| sal | decimal(7,2) | YES | | NULL | |
| comm | decimal(7,2) | YES | | NULL | |
| deptno | int(2) unsigned zerofill | YES | | NULL | |
+----------+--------------------------+------+-----+---------+-------+
8 rows in set (0.001 sec)
此时如果你直接全列查询,进程就会阻塞在这里

进MySQL的文件路径看看,会发现这张表的大小已经到了惊人的564mb,虽然我们的内存也许能存的下这么大的数据,但实际IO读写这么大量的数据是非常耗时的
[root@vm-cnt8:/var/lib/mysql/bit_index]# ll -h
total 565M
-rw-rw----. 1 mysql mysql 61 Sep 6 05:36 db.opt
-rw-rw----. 1 mysql mysql 770 Sep 6 05:36 EMP.frm
-rw-rw----. 1 mysql mysql 564M Sep 6 05:39 EMP.ibd
在之前的查询操作中提到过,对于这种大数据表的时候,我们应该避免使用全列查询,而应该设置limit只查询出少量用例数据,来判断这个表的数据结构和作用
MariaDB [bit_index]> select * from EMP limit 3;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 100002 | FNXAKX | SALESMAN | 0001 | 2023-09-06 00:00:00 | 2000.00 | 400.00 | 327 |
| 100003 | rQbLBy | SALESMAN | 0001 | 2023-09-06 00:00:00 | 2000.00 | 400.00 | 394 |
| 100004 | wRVdDF | SALESMAN | 0001 | 2023-09-06 00:00:00 | 2000.00 | 400.00 | 195 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
3 rows in set (0.001 sec)
在没有索引的情况下进行一个查询,用时大约在1.6秒左右

这时候我们来对empno列创建一个主键索引
alter table EMP add primary key(empno);
因为表中的数据很多,所以设置主键索引也需要耗费一定时间,这个时间内,其实就是MySQL在后台帮我们创建索引所需要的数据结构的过程
MariaDB [bit_index]> alter table EMP add primary key(empno);
Query OK, 0 rows affected (17.184 sec)
Records: 0 Duplicates: 0 Warnings: 0
再来查询一下刚刚查询的数据,可以看到,用时只有0.000 sec,直接秒回!

这便是索引在提升性能方面的重大作用!
1.3 MySQL和文件系统
1.3.1 Linux文件系统
在之前对Linux文件系统的学习中,我们知道在磁盘中,一个区块是512KB,在Linux系统中,为了提高效率,会采用4KB的分块对数据进行读取。哪怕你只是修改1KB,也是需要将4KB完整读取,再写入回去的。
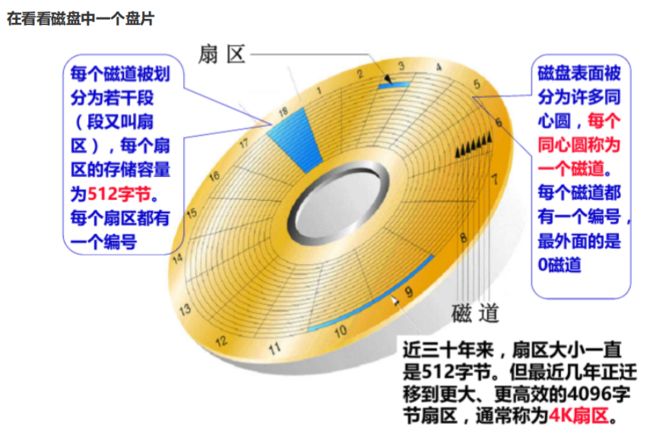
因为机械硬盘物理结构的限制,随机读取的性能不佳,一次性读取100KB数据,远远优于100次读取1KB。因为一次性读取的时候,只需要一次寻道就能将磁头摆到正确的位置,往里面写数据就完事了。但多次读取小数据的时候,尽管相邻的两次IO操作在同一时刻发出,但如果它们的请求的扇区地址相差很大的话也只能称为随机访问,而非连续访问。
随机访问就要多次寻道,每次写入的量又很少,大大增加了IO的负担。
1.3.2 MySQL和磁盘交互基本单位 16KB
而MySQL中,为了更好的实现对数据IO量的缩减和控制,其内部将16KB作为一次IO的基本单位,这个大小我们叫做MySQL的文件Page;
- MySQL中的数据文件,都是以Page为基本单位保存至磁盘里面的;
- MySQL中的CURD操作,都需要通过计算来定位到需要修改和访问的数据的位置;
- 涉及到计算的操作都需要CPU参与,CPU只能处理内存中的数据,这就要求MySQL需要提前将一部分数据加载到内存中;
- 所以在MySQL运行的这段时间内,其操作的数据会同时存在于内存和磁盘中,需要以特定的策略将内存中的数据刷新到磁盘中;这个操作就是IO,基本单位是Page;
- 为了更好的管理这些操作,MySQL会自己维护一个
buffer pool的内存空间,来进行缓存。 - MySQL是一个应用程序,它的所有文件IO操作都需要通过操作系统提供的接口来实现!但内部的刷盘逻辑是可以由MySQL来调用系统接口来自主控制的,而不需要呆板地遵守操作系统的自动策略;(MySQL创建
buffer pool也是基于更高的自主性来考虑的) - 最终目标是尽可能地减少IO操作,提高运行效率;
运行如下命令可以看到MySQL中关于Page设置的全局变量,即16KB
MariaDB [bit_index]> SHOW GLOBAL STATUS LIKE 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.001 sec)
1.3.3 为什么要用Page为单位进行交互?
为何MySQL和磁盘进行IO交互的时候,要采用Page的方案进行交互呢?用多少,加载多少不香吗?
先来个测试用例看看吧,这是一个非常简单的用户表
-- 主键默认生成主键索引
create table if not exists user (
id int primary key,
age int not null,
name varchar(16) not null
);
-- 插入多条记录,主键没有按顺序插入
mysql> insert into user (id, age, name) values(3, 18, '杨过');
Query OK, 1 row affected (0.01 sec)
mysql> insert into user (id, age, name) values(4, 16, '小龙女');
Query OK, 1 row affected (0.00 sec)
mysql> insert into user (id, age, name) values(2, 26, '黄蓉');
Query OK, 1 row affected (0.01 sec)
mysql> insert into user (id, age, name) values(5, 36, '郭靖');
Query OK, 1 row affected (0.00 sec)
mysql> insert into user (id, age, name) values(1, 56, '欧阳锋');
Query OK, 1 row affected (0.00 sec)
-- 最终发现数据是有序的
mysql> select * from user;
+----+-----+-----------+
| id | age | name |
+----+-----+-----------+
| 1 | 56 | 欧阳锋 |
| 2 | 26 | 黄蓉 |
| 3 | 18 | 杨过 |
| 4 | 16 | 小龙女 |
| 5 | 36 | 郭靖 |
+----+-----+-----------+
5 rows in set (0.00 sec)
在上面的5条记录中,如果MySQL要查找id=2的记录,第一次加载id=1,第二次加载id=2,一次一条记录,那么就需要2次IO。如果要找id=5,那么就需要5次IO。
但,如果这5条(或者更多)都被保存在一个Page中(16KB,能保存很多记录),那么第一次IO查找id=2的时候,整个Page会被加载到MySQL的Buffer Pool中,这里完成了一次IO。但是往后如果在查找id=1,3,4,5等,完全不需要进行IO了,而是直接在内存中进行了。所以,就在单Page里面,大大减少了IO的次数!
虽然我们不能保证后续的几次IO一定在这次加载的Page中,但根据局部性原理,其访问相近的几条数据的概率是很大的!所以这样最终是能提升IO效率的!
往往IO效率低下的最主要矛盾不是IO单次数据量的大小,而是IO的次数。
1.4 B+树和Page
有了对Page的认识,接下来就需要用一个数据结构来维护这些加载到Buffer Pool当中的Page了。这时候,我们的B+树就登场了。
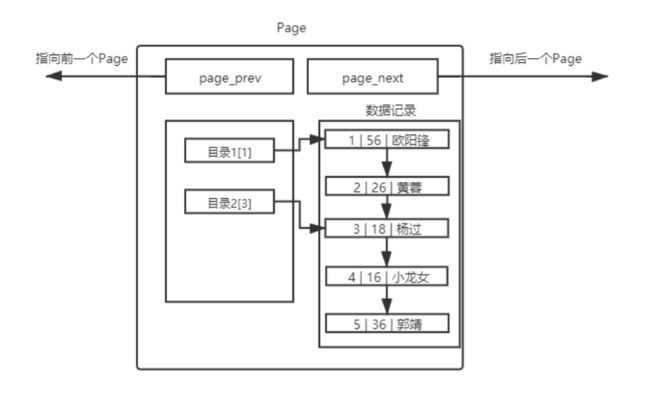
1.4.1 单个Page
单个Page里面存放的肯定是一部分的数据,我们可以加上前后指针,以双链表的形式将所有Page连起来,这样就能实现数据的遍历;在MySQL中,就是这么操作的。

因为存在主键,MySQL还会给单个Page中的数据依照主键进行排序,从上图就能看出阿里,单个Page中数据是依照主键按序排列的;且每一个数据都会链接到下一个数据上;
这样排序后,数据库在进行数据筛选的时候,就能更好的定位到数据的位置,减少查询耗时。插入时排序也能让后续在进行数据降序/升序输出的时候,无需二次对数据进行排序了;
1.4.2 多个Page
既然一个Page是如此,那多个Page呢?
- 前面提到了,当MySQL需要加载数据的时候,会将和这个数据相邻近的其他数据,以16KB为单位一起加载到一个Page里面,并连接到这个双向链表上;
- 这样,我们就可以通过多个Page的遍历来进行数据的定位
- 可链表是一个线性结构,MySQL肯定不可能用线性结构来维护数据吧?那样查询的效率也太低了,每次都需要O(N)的遍历,数据一多就慢慢慢!

所以,我们肯定要在双向链表的基础上添加其他的结构来进行查找的优化!这时候就可以引入目录了
页目录
在我们看书的时候,就会有目录来帮助我们快速查找到某一个章节。比如我们想看第九章的内容,那就可以先看目录,找到第九章的页码,再进行阅读。
对于MySQL中的数据,这个情景也是适用的,我们给数据上一个目录,查询的时候先根据目录定位到具体的page,我们可以知道1-10号数据都在这个page里面,那就直接去里面找就行了;这时候查找的效率就比单纯的从链表开头进行遍历快多了!
当然,和书籍的目录需要消耗纸张一样,在MySQL中对数据设置目录也是需要消耗空间的,这就是一种用空间换时间的做法,而在生产环境中,时间显然更加宝贵!
单页目录
在单个Page里面,我们可以安如下的方式设定一个目录,嗝一定间隔就设置一个新的节点作为目录。在数据量小的时候,这个目录的作用不算大,但数据量一大,目录对搜索效率的提升是非常可观的!
比如,我们要查找id=4记录,之前必须线性遍历4次,才能拿到结果。现在直接通过目录2[3],直接进行定位新的起始位置,只需要遍历3次就能找到结果,提高了效率。
即便在单个Page中添加目录会导致这个Page实际存放的数据变少,但这是必要的牺牲!
多页目录
前面提到,MySQL会自动把新的数据加载到一个Page中,并链接到已有链表上;但是线性遍历需要大量的IO,每次遇到新的Page的时候,就需要将其加载到内存里面,进行遍历,这就使得单个Page中的目录不那么实用了;
- 单个Page的目录是小节目录
- 多个Page的目录是章节目录
所以我们必须给多个Page也加上一个顶层的章节目录,进一步优化效率!
- 使用一个Page来指向多个Page,存放每个Page的起始key值(假设每个Page中的key都有序且为升序);这个Page中不存放实际的数据,只有目录值;
- 遍历的时候,先通过多Page的目录找到我们要去的Page,再去访问该实际存储数据的Page中的单Page目录,最终查找到目标数据;
- 所以,每个多Page的目录项中就是一个键值+对应普通Page的指针

一层目录Page不够,我们还可以再加一层。这样就实现了一个类似于二叉树的结构,只不过每一个节点Page中都包含多个Page的key+指针,最终只有叶子节点是实际存储数据的!
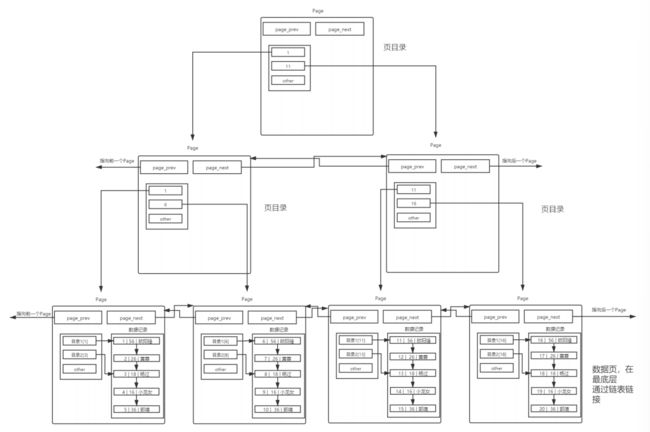
这个数据结构就叫做B+树(注意,不是B树!)而整个上图中的数据接就是MySQL中对user表做的索引!
此时的查询,需要经过的节点肯定变少了,比如我们需要查询id=12的用户:
- 顶层判断,12>11>1,向右走【2次比较】
- 第二层判断,12>11且12<16,向左走,来到具体的Page【2次比较】
- 查找单页目录,12>11且12<13;【2次比较】
- 从11开始遍历,走一步就能找到【1次比较】
最终,我们查找12的操作只用了7次就成功了。而从投开始遍历需要12次才能找到它;
遍历次数的减少,就等同于IO次数的减少,最终查询的效率就变高了!
这里的分析可能有误,不过结论是没有问题的,分页肯定能增加查找的效率!
另外,MySQL还可以根据访问的频率,定期的释放一些Page;比如在B+树中,可能树的右半部分很少被访问,那就可以暂时释放这部分Page的空间,给其他表使用,真到遇到访问的时候,再去读盘去除这部分数据。这是由MySQL的缓存策略来自主决定的;
毕竟当一个表非常大的时候,将其全部加载到内存里面是不可行的!必须要用缓存策略和局部性原理来加载频繁使用的数据到内存中,才能在效率和负载上达到平衡;
不然你的MySQL无脑缓存Page导致占用过多内存,操作系统看不下去直接给你KILL了,那业务就完蛋了!
1.4.3 小结
- Page分为目录页和数据页。目录页只放各个下级Page的最小键值和该Page的指针。
- 查找的时候,自顶向下找,只需要加载部分目录页到内存,即可完成算法的整个查找过程,大大减少了IO次数
- 范围查询的时候,可以找到区间边界的两个节点的位置,然后直接通过叶子节点的链表进行遍历,取出数据即可!
- MySQL可以根据访问频率,适当地预先加载或者释放一些Page的空间,并不是说一张表的所有数据都必须全部加载到内存里面;
后续我还会学习B树和B+树数据结构在CPP中的实现,敬请关注我的博客!
1.5 为什么其他数据结构不适合索引?
在认识这个问题之前,我们首先要记住上文提到的一个结论:真正影响索引性能的,是和硬盘IO的次数,IO次数越少,性能越高;
- 链表、线性表:都是线性遍历,压根没有索引的功能
- 二叉搜索树:在极端场景下会退化成普通二叉树,还是线性遍历
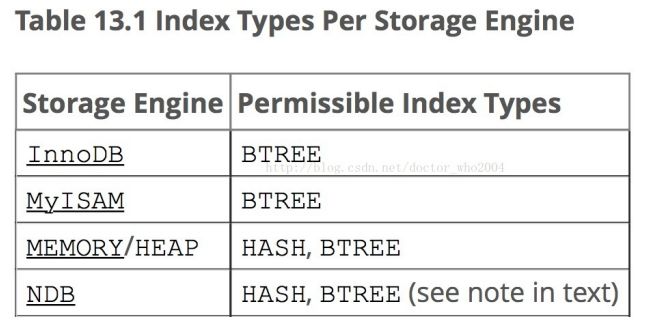
AVLTree/RBTree:虽然相对平衡,但二叉结构会导致树的整体过高,自顶向下查询的时候,需要经过多层的多次IO,才能找到目标数据(B+树的层数更少,在这种情况下B+树更优秀)- HASH:虽然查找的时候很快,基本能做到O(1),但范围查询的效果不佳;在MySQL中也是支持HASH索引的,比如
MEMOY/HEAP/NDB存储引擎;
那B树为什么不适合呢?作为一个多叉树结构,B树的同层能比红黑树存储更多信息,看上去也是可以做索引的呀?
牵扯到B树和B+树的区别了,来看看二者的结构图

文字说明如下:
- B树的每一个节点都会存放一定的数据和page指针;
- B+树只有叶子节点会存放数据,非叶子节点只有page的目录;
- B+树的叶子节点全部相连;
这就引出了B+树的两个优点:
- 因为B+树的非叶子节点只需要存储page目录,所以在一个非叶子节点中就能存放较多的目录索引,使得树整体更矮;
- B+树的叶子节点全部相连,方便进行范围遍历,比如
where sal>100 and sal < 300的这种范围条件,就可以直接通过叶子节点的链表向后遍历来解决;
最终的效率问题依旧落到了如何让树更矮来减少IO次数,因为在整体上B+树都能做到较矮,查询效率优秀,方便范围查询;所以MySQL主要选用了B+树作为索引结构。
1.6 聚簇/非聚簇索引
1.6.1 说明
InnoDB的数据是和B+树一起存放的,叶子节点里面有数据;这种数据和索引在一起的形式,叫做聚簇索引。

MyISAM的叶子中没有数据,而是存放的指向数据表对应位置的指针,有额外的一张表来存放所有数据;这种数据和索引分离的形式,叫做非聚簇索引;
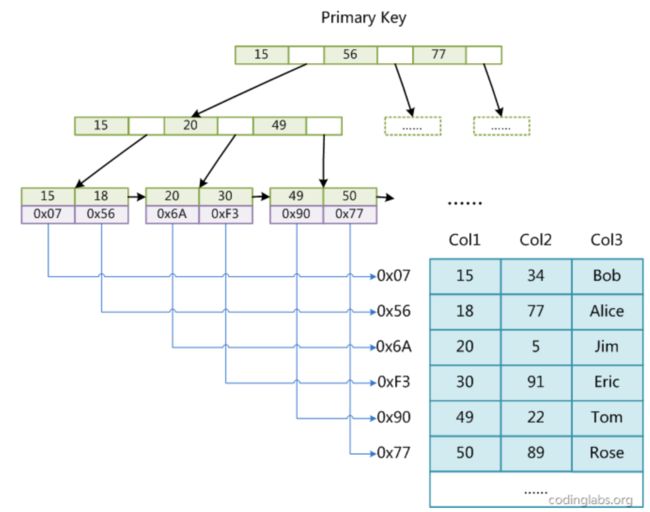
对于MyISAM存储引擎来说,其很适合进行查询,特别是大文本查找和全文索引(后文会提到);
1.6.2 实机演示
在MySQL中,我们可以通过实际文件的数量看出InnoDB和MyISAM存储引擎的区别;其也反映了聚簇/非聚簇索引的性质。
这里我们新建一个数据库,创建user1表,默认采用的是InnoDB作为存储引擎
MariaDB [hello_mysql]> create table user1( id int unsigned primary key, name varchar(200) NOT NULL );
Query OK, 0 rows affected (0.008 sec)
在MySQL的文件存储路径中,可以查看到user1表对应了两个文件,其中.ibd后缀指的就是InnoDB,其内部同时包含了该表中的数据和索引值;
[root@vm-cnt8:/var/lib/mysql/hello_mysql]# ll
total 104
-rw-rw----. 1 mysql mysql 61 Sep 7 02:59 db.opt
-rw-rw----. 1 mysql mysql 1545 Sep 7 03:00 user1.frm
-rw-rw----. 1 mysql mysql 98304 Sep 7 03:00 user1.ibd
再来创建一个属性完全相同的user2表,但采用MyISAM存储引擎
MariaDB [hello_mysql]> create table user2( id int unsigned primary key, name varchar(200) NOT NULL ) engine=MyISAM;
Query OK, 0 rows affected (0.002 sec)
此时能看到,MyISAM对应的存储文件有3个,.MYI包含的是索引,.MYD包含的是实际数据;
[root@vm-cnt8:/var/lib/mysql/hello_mysql]# ll
total 112
-rw-rw----. 1 mysql mysql 61 Sep 7 02:59 db.opt
-rw-rw----. 1 mysql mysql 1545 Sep 7 03:00 user1.frm
-rw-rw----. 1 mysql mysql 98304 Sep 7 03:00 user1.ibd
-rw-rw----. 1 mysql mysql 1545 Sep 7 03:03 user2.frm
-rw-rw----. 1 mysql mysql 0 Sep 7 03:03 user2.MYD
-rw-rw----. 1 mysql mysql 1024 Sep 7 03:03 user2.MYI
两表都有一个占用空间完全相同的.frm文件,这个文件中存储的就是该表的结构属性信息,因为两个表的结构完全相同,所以这个文件的大小也相同;
1.7 回表查找
创建辅助索引的时候,MyISAM依旧创建一个B+树,叶子节点也是指向对应位置的指针;所以在MyISAM中,主键/非主键索引区别不大,无非是是否允许冗余数据的问题。

InnoDB的辅助索引中,不再直接存放节点数据,而是存放主键key值,查询的时候根据key值回到主键索引表中进行查询,需要查询两次才能获取到结果。
如果辅助索引中还保存数据,就会造成极大的空间浪费,一份数据被保存两次甚至更多次,显然是不合理的。
InnoDB这个先查辅助索引表,再回到主键表中查询的动作,叫做回表查询;
话虽是这么说,但也并不是每次查询我们都需要回表的。比如下图是一个复合键的索引表,假设数字是用户ID(主键),文字是用户姓名,在这种情况下,我们通过用户姓名查询用户ID的时候,就不需要回到主键表也能获取到结果。
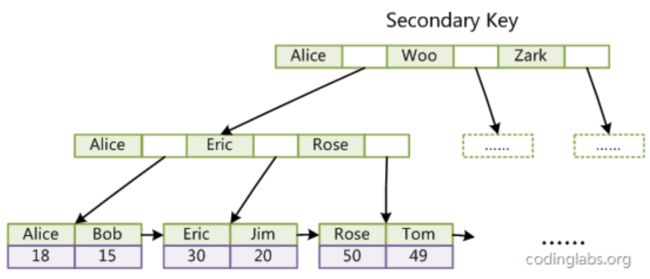
另外,在一般的数据库中,B+树并不会很深,所以即便需要进行回表的两次查询,效率也不会受到较大影响;(但肯定会有一定损失)
2.索引操作
2.1 创建索引的原则
- 比较频繁作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合作创建索引(因为每次更新都得重置索引,增加IO压力)
- 不会出现在where子句中的字段不该创建索引(不作为查询条件的字段)
2.2 创建主键索引
创建表的时候指定primary key,默认就会创建主键索引
create table user1( id int unsigned primary key, name varchar(200) NOT NULL );
创建表的最后,指定某列为主键索引,这个和第一种方式本质上没区别
create table user1( id int unsigned , name varchar(200) NOT NULL, primary key(id) );
创建表了之后再添加主键
-- 创建表
create table user1( id int unsigned , name varchar(200) NOT NULL);
-- 添加主键
alter table user1 add primary key(id);
主键索引的特点:
- 一个表里面本来就只能有一个主键,所以主键索引也只有一个(复合主键也只算一个主键)
- 主键索引的效率高(主键列不可重复)
- 主键列不能为NULL,所以也不存在无法被索引的值
- 一般都会用数字来作为主键,在索引中方便数据比较
2.3 唯一键索引
当你给某一列设置为唯一键的时候,MySQL就会自动创建唯一键索引;唯一键索引其实就是普通的辅助索引,只不过其和主键一样都包含唯一的键值约束;
-- 直接指定唯一键
create table user2(id int primary key, name varchar(200) unique);
-- 创建语句末尾指定唯一键
create table user2(id int primary key, name varchar(200),unique(name));
-- 创建后再添加唯一键
create table user2(id int primary key, name varchar(200));
alter table user2 add unique(name);
唯一索引的特点:
- 一个表中,可以有多个唯一索引,包括复合唯一键的索引;
- 查询效率高;
- 如果在某一列建立唯一索引,必须保证这列不能有重复数据;
- 如果一个唯一索引上指定
not null,等价于主键索引; - 如果删除唯一键索引,也会同时删除唯一的约束属性;
2.4 普通键索引
创建普通索引依旧有3种方式
-- 在表的定义最后,指定某列为索引
create table user3(id int primary key,
name varchar(20),
email varchar(30),
index(name)
);
-- 创建完表以后指定某列为普通索引
create table user3(id int primary key, name varchar(20), email
varchar(30));
alter table user3 add index(name);
-- 创建索引的时候指定名字
create table user3(id int primary key, name varchar(20), email
varchar(30));
create index idx_name on user3(name); -- 创建一个索引名为 idx_name 的索引
普通索引的特点:
- 一个表中可以有多个普通索引
- 普通索引中的键值可以重复,但不要在大量重复的键值上建立索引(比如性别)
2.5 复合/联合索引
给多个键值创建索引,操作如下
create index 索引名字 on 表名(字段1,字段2);
此时我们创建的索引,在字段1和字段2上会共用一个索引的Key_name,索引名字是相同的。
复合索引有一个好处,如果使用InnoDB时,需要查询的结果包含在索引字段中,那就可以节省一次返还到主键索引中查询的回表步骤,可以在一定程度上提高效率(在上文中已经提及此事)
- 上面这种操作叫做索引覆盖(覆盖索引),直接从普通索引表中查询到结果;
- 建立复合索引相比于建立多个单列索引,还能在一定程度上减少空间消耗,提高效率;
另外,在进行复合索引的查询的时候,我们只能使用用户名来查询用户ID,返过来是不行的。因为在MySQL对索引进行匹配的时候,只会匹配最左侧的索引值;比如下图中,充当判断条件的是用户名字,通过用户名字查用户ID是OK的,反过来就不行;
这种叫做MySQL索引的最左匹配原则
详解:联合索引-最左匹配原则
MySQL在创建复合索引的时候,首先会对最左边字段排序,也就是第一个字段,然后再在保证第一个字段有序的情况下,再排序第二个字段,以此类推。所以联合索引最左列是绝对有序的,其他字段无序。
举个例子:可以把联合索引看成“电话簿”,姓名作为联合索引,姓是第一列,名是第二列,当查找人名时,是先确定这个人姓再根据名确定人。只有名没有姓就查不到。
2.6 全文索引
如果对文章或者大量文字的字段进行检索的时候,就会使用到全文索引。MySQL提供全文索引机制,但是要求表的存储引擎必须是MyISAM;而且默认的全文索引只支持英文,不支持中文。如果对中文进行全文检索,可以使用sphinx的中文版(coreseek)。
-- 创建表,FULLTEXT设置全文索引
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
)engine=MyISAM;
-- 插入测试数据
INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
创建好表之后,查询表中索引信息,可以看到title和body字段都用上了索引名字为title的全文索引

假设我们查询这个表中有没有包含database的文字数据,虽然成功查询了结果,但是并没有使用到全文索引
select * from articles where body like '%database%';
+----+-------------------+------------------------------------------+
| id | title | body |
+----+-------------------+------------------------------------------+
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
| 5 | MySQL vs. YourSQL | In the following database comparison ... |
+----+-------------------+------------------------------------------+
2 rows in set (0.000 sec)
使用explain语句可以看出是否有使用全文索引,这里的key为NULL就代表么有使用上索引;这个工具的作用是预执行,并不会实际上运行这个语句,但是会告诉你我想怎么运行它;
explain select * from articles where body like '%database%'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: articles
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where
1 row in set (0.000 sec)
要想使用全文索引,得这么写
SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database');
再用explain工具看看,此时就可以看到key里面显示的是title,成功使用上了全文索引
explain SELECT * FROM articles WHERE MATCH (title,body) AGAINST
-> ('database')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: articles
type: fulltext
possible_keys: title
key: title
key_len: 0
ref:
rows: 1
Extra: Using where
1 row in set (0.000 sec)
2.7 查询/删除索引
如果需要删除主键索引,直接把主键删了就行了
alter table 表名 drop primary key;
删除普通索引语句如下
alter table 表名 drop index 索引名字;
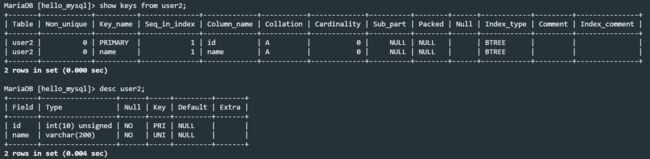
注意,索引的名字不一定和字段名相同(在创建索引的时候可以指定索引名字),需要使用如下语句查看
show keys from 表名;
比如user2表中包含id主键索引和name的主键索引,其结果查询如下;其中的Key_name才是索引的名字,不一定和字段名相同!删除索引的时候需要使用索引名字!
还可以用如下语句来更加清楚的看到每个索引的相关属性
show index from 表名\G;
我给user2表添加一个键值,并设置普通索引
alter table user2 add qq varchar(40); -- 添加一个键值
alter table user2 add index(qq); -- 添加普通索引
使用show index from 表名\G;语句查看user2表的索引属性;在这里可以看到,唯一键索引的属性和普通索引是完全相同的,所以才说唯一键的索引本质上还是普通索引。
这里还写明了索引的类型是BTREE,其就是B+树;
MariaDB [hello_mysql]> desc user2;
+-------+------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+------------------+------+-----+---------+-------+
| id | int(10) unsigned | NO | PRI | NULL | |
| name | varchar(200) | NO | UNI | NULL | |
| qq | varchar(40) | YES | MUL | NULL | |
+-------+------------------+------+-----+---------+-------+
3 rows in set (0.001 sec)
MariaDB [hello_mysql]> show index from user2\G;
*************************** 1. row ***************************
Table: user2
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row ***************************
Table: user2
Non_unique: 0
Key_name: name
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 3. row ***************************
Table: user2
Non_unique: 1
Key_name: qq
Seq_in_index: 1
Column_name: qq
Collation: A
Cardinality: NULL
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
3 rows in set (0.000 sec)
ERROR: No query specified