DPU应用场景系列(一)网络功能卸载
DPU应用场景系列(一)网络功能卸载
网络功能卸载是伴随云计算网络而产生的,主要是对云计算主机上的虚拟交换机的能力做硬件卸载,从而减少主机上消耗在网络上的CPU算力,提高可售卖计算资源。
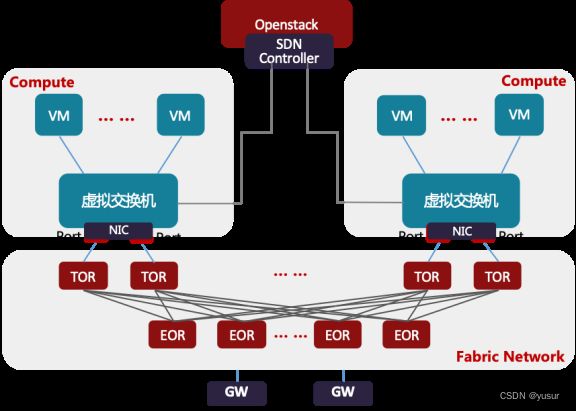
图 云计算网络架构
目前除了公有云大厂采用自研云平台,绝大部分私有云厂商都使用开源的OpenStack云平台生态。在OpenStack云平台中,虚拟交换机通常是Open vSwitch,承担着云计算中网络虚拟化的主要工作,负责虚拟机(VM)与同主机上虚拟机(VM)、虚拟机(VM)与其它主机上虚拟机(VM)、虚拟机(VM)与外部的网络通信。虚拟交换机与网关路由器(GW)通常由同一SDN控制器来管理控制,为租户开通VPC网络以及和外部通信的网络。主机与主机间的网络通常是Underlay网络,是由TOR/EOR构建的Spine-Leaf结构的Fabric Network。虚拟机(VM)与虚拟机(VM)通信的网络是Overlay网络,是承载在Underlay网络构建的VxLAN,NVGRE或Geneve隧道之上的。通常VxLAN,NVGRE或Geneve的隧道端点(VTEP)在虚拟交换机和网关路由器(GW)上。也有部分对网络性能要求比较高的场景,采用SR-IOV替代虚拟交换机,VF直通到虚拟机(VM)内部,这样就要求隧道端点(VTEP)部署在TOR上,TOR与网关路由器(GW)创建隧道,提供Overlay网络服务。虚拟交换机的场景是最通用的应用场景,所以,虚拟交换机的技术迭代也直接影响着虚拟化网络的发展。
一、虚拟化网络功能(Virtual Network Function)
行业内主流的Hypervisor主要有Linux系统下的KVM-Qemu,VMWare的ESXi,微软Azure的Hyper-V,以及亚马逊早期用的Xen(现在亚马逊已经转向KVM-Qemu)。KVM-Qemu有着以Redhat为首在持续推动的更好的开源生态,目前行业内90%以上的云厂商都在用KVM-Qemu作为虚拟化的基础平台。
在KVM-Qemu这个Hypervisor的开源生态里,与网络关系最紧密的标准协议包括virtio和vhost,以及vhost衍生出来的vhost-vdpa。Virtio在KVM-Qemu中定义了一组虚拟化I/O设备,和对应设备的共享内存的通信方法,配合后端协议vhost和vhost-vdpa使用,使虚拟化I/O性能得到提升。
(1)内核虚拟化网络(vhost-net)
在虚拟化网络的初期,以打通虚拟机(VM)间和与外部通信能力为主,对功能诉求远高于性能,虚拟交换机OVS(Open vSwitch)的最初版本也是基于操作系统Linux内核转发来实现的。vhost协议作为控制平面,由Qemu做代理与主机kernel内的vhost-net通信,主机内核vhost-net作为virtio的backend,与虚拟机(VM)内部的virtio NIC通过共享内存的方式进行通信。实现了虚拟机(VM)间和虚拟机(VM)与外部的通信能力,但是内核转发效率和吞吐量都很低。目前在虚拟化网络部署中已经很少使用。
(2)用户空间DPDK虚拟化网络(vhost-user)
随着虚拟化网络的发展,虚拟机(VM)业务对网络带宽的要求越来越高,另外,英特尔和Linux基金会推出了DPDK(Data Plane Development Kit)开源项目,实现了用户空间直接从网卡收发数据报文并进行多核快速处理的开发库,虚拟交换机OVS将数据转发平面通过DPDK支持了用户空间的数据转发,进而实现了转发带宽量级的提升。OVS-DPDK通过将virtio的backend实现在用户空间,实现了虚拟机(VM)与用户空间OVS-DPDK的共享内存,这样虚拟机(VM)在收发报文时,只需要OVS-DPDK将从网卡收到的报文数据写入虚拟机(VM)的内存,或从虚拟机(VM)内存将要发送的报文拷贝到网卡DMA的内存,由于减少了内存拷贝次数和CPU调度干扰,提升了转发通道的整体效率和吞吐量。
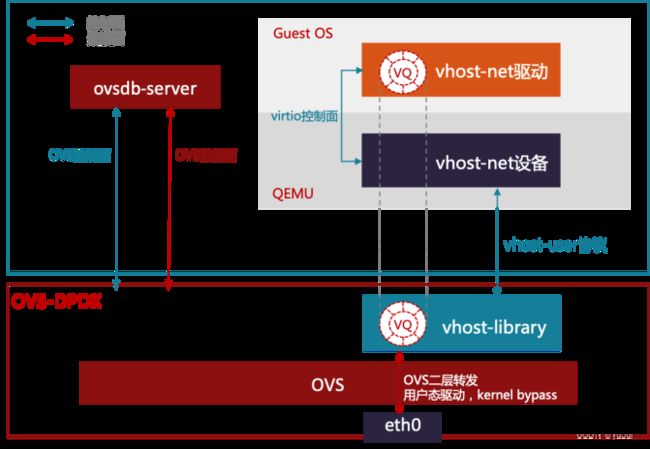
图 基于DPDK的虚拟化网
OVS-DPDK相对转发能力有所提高,但也存在新的问题。首先,目前大多数服务器都是NUMA(多CPU)结构,在跨NUMA转发时性能要比同NUMA转发弱。而物理网卡只能插在一个PCIe插槽上,这个插槽只会与一个NUMA存在亲和性,所以OVS-DPDK上跨NUMA转发的流量不可避免。第二,在虚拟机(VM)与OVS-DPDK共享内存时,初始化的队列数量通常是与虚拟机(VM)的CPU个数相同,才能保证虚拟机上每一个CPU都可以通过共享内存收发数据包,这样导致不同规格的虚拟机(VM)在OVS-DPDK上收发队列所接入的CPU是非对称的,在转发过程中需要跨CPU转发数据。最后,OVS-DPDK在转发数据时,不同虚拟机(VM)的流量由于CPU瓶颈导致拥塞,会随机丢包,无法保障租户带宽隔离。
(3)高性能SR-IOV网络(SR-IOV)
在一些对网络有高性能需求的场景,如NFV业务部署,OVS-DPDK的数据转发方式,无法满足高性能网络的需求,这样就引入的SR-IOV透传(passthrough)到虚拟机(VM)的部署场景。
在SRIOV passthrough的场景下,虚拟机(VM)可以获得与裸金属主机上相比拟的网络性能。但是,仍然存在两个限制:
(1)SRIOV VF passthrough到VM后,VM的迁移性会受限,主要原因在于SRIOV这种passthrough I/O借助了Intel CPU VT-d(Virtualization Technology for Directed I/O)或AMD的IOMMU(I/O Memory Management Unit)技术,在VM上VF网卡初始化的时候,建立了Guest虚拟地址到Host物理地址的映射表,所以这种“有状态”的映射表在热迁移的过程中会丢失。
(2)由于SRIOV VF passthrough到VM,而SRIOV PF直接连接到TOR上,在这种部署环境中虚拟机(VM)对外的网络需要自定义,如需要像OVS-DPDK那样自动开通网络,则需要将TOR加入SDN控制器的管理范畴,由SDN控制器统一管控,这样做通常会使网络运营变的非常复杂。
针对上面第二个问题,Mellanox最早提出在其智能网卡上支持OVS Fastpath硬件卸载,结合SRIOV VF passthrough到VM一起使用,提供临近线速转发的网络能力,解决了虚拟机(VM)租户网络自动化编排开通的问题。
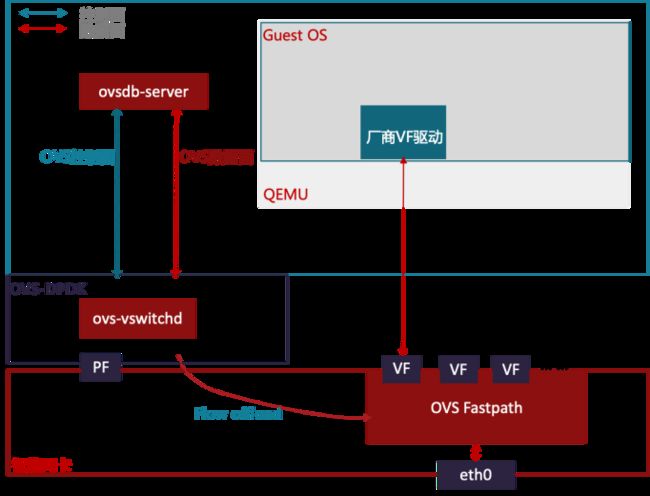
图 OVS Fastpath硬件卸载虚拟化网络
在OVS Fastpath卸载后,OVS转发报文时,数据流首包仍然做软件转发,在转发过程中生成Fastpath转发流表并配置到硬件网卡上,这个数据流的后续报文则通过硬件直接转发给虚拟机(VM)。由于早期的Mellanox智能网卡还没有集成通用CPU核,OVS的控制面依然在物理主机上运行。
(4)Virtio硬件加速虚拟化网络(vDPA)
为了解决高性能SRIOV网络的热迁移问题,出现了很多做法和尝试,尚未形成统一的标准。在Redhat提出硬件vDPA架构之前,Mellanox实现了软件vDPA(即VF Relay)。理论上讲,Mellanox的软件vDPA并不能算是vDPA,其实就是将数据在用户空间的virtio队列和VF的接收队列做了一次数据Relay。Redhat提出的硬件vDPA架构,目前在DPDK和内核程序中均有实现,基本是未来的标准架构。Qemu支持两种方式的vDPA,一种是vhost-user,配合DPDK中的vDPA运行,DPDK再调用厂商用户态vDPA驱动;另一种方式是vhost-vdpa,通过ioctl调用到内核通用vDPA模块,通用vDPA模块再调用厂商硬件专有的vDPA驱动。
1) 软件vDPA: 软件vDPA也叫VF relay,由于需要软件把VF上接收的数据通过virtio转发给虚拟机(VM),如Mellanox在OVS-DPDK实现了这个relay,OVS流表由硬件卸载加速,性能上与SR-IOV VF直通(passthrough)方式比略有降低,不过实现了虚拟机(VM)的热迁移特性。
2) 硬件vDPA: 硬件vDPA实际上是借助virtio硬件加速,以实现更高性能的通信。由于控制面复杂,所以用硬件难以实现。厂商自己开发驱动,对接到用户空间DPDK的vDPA和内核vDPA架构上,可以实现硬件vDPA。目前Mellanox mlx5和Intel IFC对应的vDPA适配程序都已经合入到DPDK和kernel社区源码。
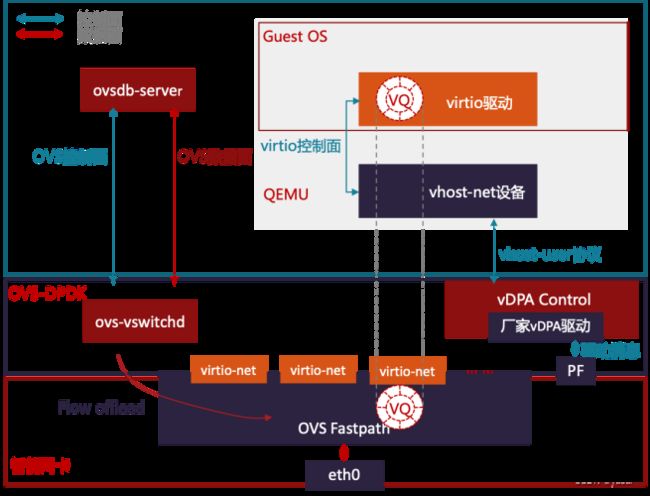
图 virtio硬件加速虚拟化网络
在硬件vDPA场景下,通过OVS转发的流量首包依然由主机上的OVS转发平面处理,对应数据流的后续报文由硬件网卡直接转发。
后来在Bluefield-2上,由于集成了ARM核,所以NVIDIA在与UCloud的合作中,将OVS的控制面也完全卸载到网卡到ARM核上,这样主机上就可以将OVS完全卸载到网卡上。
二、网络功能虚拟化(Network Function Virtualization)
伴随着越来越多的业务上云,一些原来运行在专用设备或者特定主机上的网络产品也开始重视上云后的按需扩缩容能力,所以出现了网路功能虚拟化(NFV)产品。NFV产品主要以虚拟机(VM)或者容器(Container)的形态部署到云计算平台上,对外提供对应的网络功能,如Load Balance,Firewall,NAT,vRouter,DPI和5G边缘计算UPF等。这些NFV产品之前全部基于DPDK在X86 CPU上运行,由于CPU算力上限问题,通常难以提供对应网络带宽的吞吐能力。DPU智能网卡的出现,为NFV加速提供了资源和可能。
(1)5G 边缘计算UPF(User Plane Function)
5G垂直行业对5G网络提出了更高的要求,如大带宽,高可靠,低时延,低抖动等,这对用户面数据转发的核心5G UPF,提出了更高的实现要求。尤其在边缘网络,交互式VR/AR在大带宽的要求下,还需要低时延,从而提高业务的用户体验;而车路协同系统等,对高可靠和低时延低抖动的要求更高,这是保障车路协同能够实时做出正确决策的关键;一些工业控制实时自动化应用,也是要求视频数据实时传输到服务端,并通过视频识别等功能实时做出控制指令下发等等。这些典型的应用,都对边缘计算中5G UPF提出了更严苛的要求。
在5G边缘计算中,未来的主要应用场景包括:增强型视频服务,监测与追踪类服务,实时自动化,智能监控,自动机器人,危险和维护传感,增强现实,网联车辆和远程操控等。对应的5G技术指标和特征也比较明显。首先,超大带宽(eMBB,Enhanced Mobile Broadband)要求单用户峰值带宽可达20Gbps,用户体验数据速率在100Mbps;其次,超密连接(mMTC,Massive Machine Type Communication)要求每平方公里设备数量在10k到1M个终端,流量密度10Mbps每平方米;最后,超低时延(uRLLC, Ultra Reliable Low Latency Communication)要求时延在1~10ms,高可靠性达到99.999%。
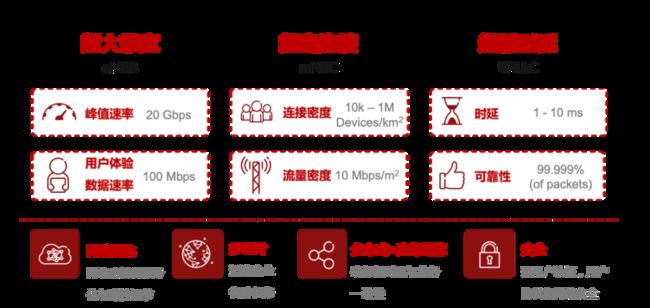
图 5G业务网络特征
传统的5G UPF通常由软件实现,运行在X86 CPU上,虽然在吞吐上可以通过增加CPU来实现更大能力,但是,时延和抖动通常都会比较高,很难稳定支撑低时延低抖动业务。对于超大带宽,超低时延的需求,这类数据转发业务更适合在硬件中实现,硬件实现更容易做到低时延低抖动和大带宽。
5G UPF业务模型复杂,需要选择性卸载转发,将高可靠低时延低抖动业务要求的用户会话卸载到硬件中。如图3-5所示,数据流首包通过软件转发,然后将对应的流表卸载到智能网卡,后续报文通过智能网卡硬件转发,这样可以在5G边缘计算中,提供低时延低抖动和超大带宽网络能力的同时,还能降低边缘计算的整体功耗。
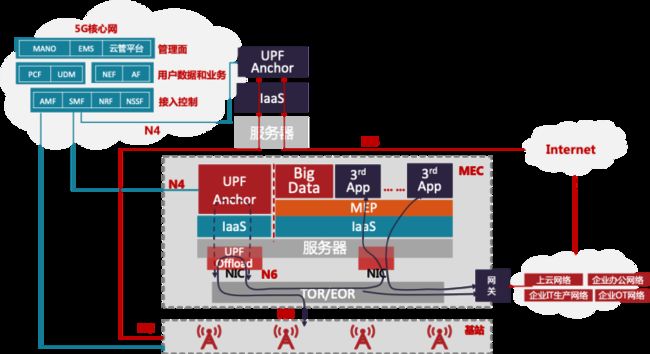
图 5G边缘计算 UPF硬件卸载方式
(2)智能DPI(Deep Packet Inspection)
DPI不论在运营商网络还是互联网数据中心,都是重要的配套设备。而且DPI功能是很多网络功能产品的基础功能,如IPS/IDS,5G UPF,DDoS防攻击设备等,具有重要的产品价值。DPI具有高新建、高并发、高吞吐等特点,使得性能成为虚拟化部署的瓶颈。通过DPU智能网卡实现DPI流量卸载,性能可以提升在30%以上。
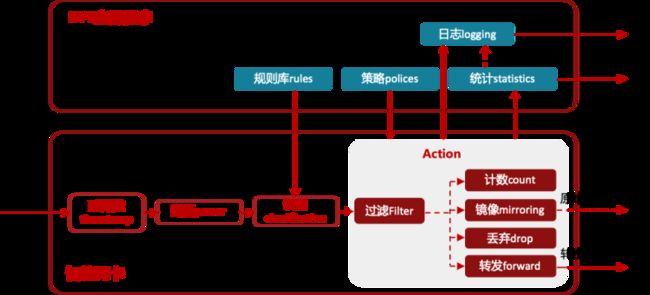
图 智能DPI硬件卸载
智能DPI基于智能网卡卸载DPI流量,软件规则库下发到硬件形成流识别的规则,再将软件策略下发到硬件形成对应的动作。这样数据流进入网卡通过打时间戳进行硬件解析,匹配识别规则库,根据匹配的规则寻找对应的策略,根据策略进行计数,镜像,丢弃和转发等行为。通过硬件卸载DPI流量,不仅可以节省虚拟化DPI的CPU,还可以提升其吞吐量,同时降低了整体TCO。一些公有云的运维系统也是通过DPI功能做流日志,除了运维使用以外,还对用户提供对应的流日志服务。
三、云原生网络功能
(1)云原生网络架构
云原生,从广义上来说,是更好的构建云平台与云应用的一整套新型的设计理念与方法论,而狭义上讲则是以docker容器和Kubernetes(K8S)为支撑的云原生计算基金会(CNCF)技术生态堆栈的新式IT架构。对比虚拟机,容器应用对磁盘的占用空间更小,启动速度更快,直接运行在宿主机内核上,因而无Hypervisor开销,并发支持上百个容器同时在线,接近宿主机上本地进程的性能,资源利用率也更高。以K8S为代表的云原生容器编排系统,提供了统一调度与弹性扩展的能力,以及标准化组件与服务,支持快速开发与部署。
容器平台包括容器引擎Runtime(如containerd,cri-o等),容器网络接口(CNI,如calico,flannel,contiv,cilium等)和容器存储接口(CSI,如EBS CSI,ceph-csi等)。
云原生平台可以部署在裸金属服务器上,也可以部署在虚拟机(VM)上。通常为了追求更高的性能,云原生平台会部署在裸金属上。如果考虑故障后更容易恢复,通常会部署在虚拟机(VM)上。
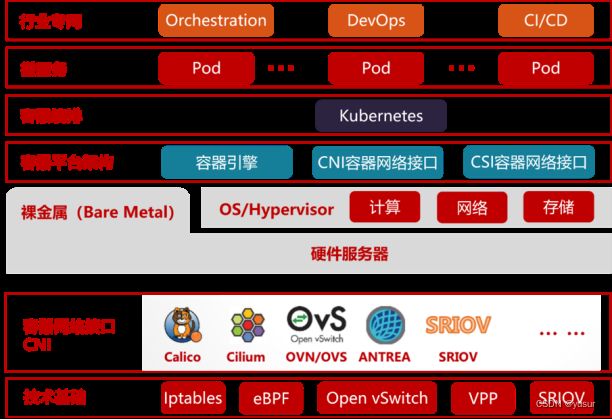
图 云原生网络架构介绍
云原生对于网络的需求,既有基础的二三层网络联通,也有四至七层的高级网络功能。二三层的网络主要是实现K8S中的CNI接口,具体如calico,flannel,weave,contiv,cilium等。主要是支持大规模实例,快速弹性伸缩,自愈合,多集群多活等。四至七层网络功能,主要是服务网格(Service Mesh)。服务网格的本质是提供安全、可靠、灵活、高效的服务间通信。服务网格还提供了一些更加高级的网络功能,如有状态的通信,路由限流,灰度流量切换,熔断监控等。
(2)eBPF的硬件加速
eBPF是一项革命性的技术,可以在Linux内核中运行沙盒程序,而无需重新编译内核或者加载内核模块。在过去几年,eBPF已经成为解决以前依赖于内核更改或者内核模块的问题的标准方法。对比在Kubernetes上Iptables的转发路径,使用eBPF会简化其中大部分转发步骤,提高内核的数据转发性能。Cilium是一个基于eBPF实现的开源项目,提供和保护使用Linux容器管理平台部署的应用程序服务之间的网络和API连接,以解决容器工作负载的新可伸缩性,安全性和可见性要求。Cilium超越了传统的容器网络接口(CNI),可提供服务解析,策略执行等功能,实现了组网与安全一体化的云原生网络。Cilium数据平面采用eBPF加速,能够以Service/pod/container为对象进行动态地网络和安全策略管理,解耦控制面等策略管理和不断变化的网络环境,具有应用感知能力(如https,gRPC等应用),从而实现对流量的精确化控制。同时它的状态通过K-V数据库来维护实现可扩展设计。
基于eBPF的Cilium已经被证明是Kubernetes云原生网络的最佳实践,国内阿里云和腾讯云匀已在自己的公有云中引用了Cilium构建自己的云原生平台。
为进一步提升性能,Netronome将eBPF路径上的部分功能卸载到硬件网卡,如XDP和Traffic Classifier cls-bpf,实现了对于用户无感知的eBPF卸载加速。硬件卸载的eBPF程序可以直接将报文送到任意内核eBPF程序,eBPF中map的维护对于用户程序和内核程序是透明的。
eBPF程序的编译需要在生成内核微码的基础上,加入编译硬件可识别的微码程序,并将对应的硬件微码程序装载到网卡中。从而实现eBPF硬件卸载。
(3)云原生Istio服务网格
Istio是CNCF主推的微服务框架,实现了云原生四至七层网络能力。Istio在数据平面通过Sidecar对流量进行劫持,实现了无代码侵入的服务网格。控制平面组件中,pilot负责下发控制,mixer收集运行的状态,citadel则负责安全证书方面的处理。

图 服务网格Istio架构
在Istio中,原生的七层代理使用的是Envoy,Envoy提供了动态服务发现,负载均衡的能力,同时支持TLS连接,可以代理HTTP/1.1 & HTTP/2 & gRPC等协议。同时支持熔断器,流量拆分,故障注入等能力和丰富的度量指标。另外,阿里还提出了MOSN作为Istio的七层代理,这里不再介绍细节。由于引入七层代理后,增加数据转发时延。Broadcom尝试在Stingray DPU智能网卡将Enovy以网关模式卸载到智能网卡的ARM核上,用了八个ARM核中的六个来做Enovy卸载支持100G网卡上的流量。这种方式是否能够适用于当前Sidecar上代理模式的Enovy,还有待探索,另外,编排和管理方式也需要进一步调研。

图 Envoy卸载实例
OVS硬件卸载的加速方式主要由OVN-Kubernetes和Antrea CNI做控制面。由于OVS的数据面在OpenStack云平台上已经有了硬件卸载的先例,所以,在云原生网络再做硬件卸载,基本上没有技术障碍,只需要增加NAT处理能力即可。但是,这种硬件卸载方式,由于没有涉及到七层代理,所以不可避免的还是会将报文上送到内核转发,进而在数据转发性能上的提升相对有限。

图 OVS硬件加速
总体而言,在云原生网络中智能网卡的应用场景还需要进一步探索,目前尚无一个相对完美的能够解决服务网格性能和时延问题的方案。
四、 RDMA网络功能
(1)RDMA网络功能介绍
面对高性能计算、大数据分析和浪涌型IO高并发、低时延应用,现有TCP/IP软硬件架构和应用高CPU消耗的技术特征根本不能满足应用的需求。这主要体现在处理时延过大——数十微秒,多次内存拷贝、中断处理,上下文切换,复杂的TCP/IP协议处理,以及存储转发模式和丢包导致额外的时延。而RDMA通过网络在两个端点的应用软件之间实现Buffer的直接传递,相比TCP/IP,RDMA无需操作系统和协议栈的介入,能够实现端点间的超低时延、超高吞吐量传输,不需要网络数据的处理和搬移耗费过多的资源,无需OS和CPU的介入。RDMA的本质实际上是一种内存读写技术。
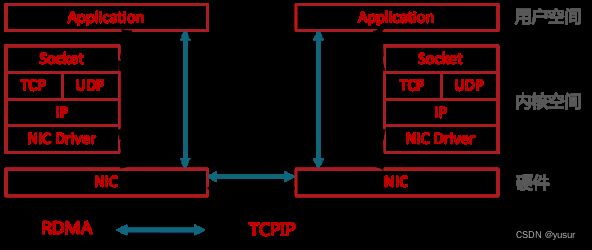
图 对比RDMA和TCP/IP收发数据
RDMA和TCP/IP网络对比可以看出,RDMA的性能优势主要体现在:
(1)零拷贝——减少数据拷贝次数,由于没有将数据拷贝到内核态并处理数据包头部到过程,传输延迟会显著减少。
(2)Kernel Bypass和协议卸载——不需要内核参与,数据通路中没有繁琐的处理报头逻辑,不仅会使延迟降低,而且也节省了CPU的资源。
(2)RDMA硬件卸载方式
原生RDMA是IBTA(InfiniBand Trade Association)在2000年发布的基于InfiniBand的RDMA规范;基于TCP/IP的RDMA称作iWARP,在2007年形成标准;基于Ethernet的RDMA叫做RoCE,在2010年发布协议,基于增强型以太网并将传输层换成IB传输层实现;在2014年,IBTA发布了RoCEv2,引入IP解决扩展性问题,可以跨二层组网,引入UDP解决ECMP负载分担等问题。
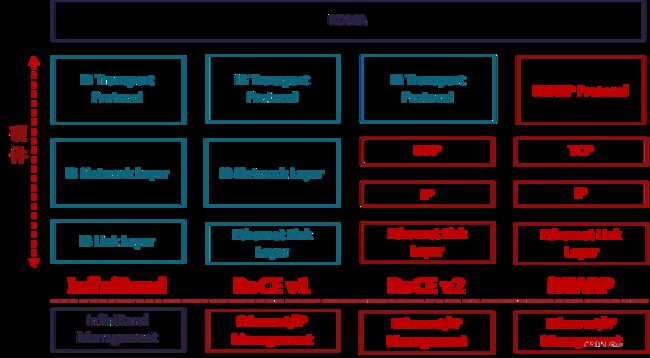
图 RDMA协议栈介绍
InfiniBand是一种专为RDMA设计的网络,从硬件级别保证可靠传输。全球HPC高算系统TOP500大效能的超级计算机中有相当多套系统在使用InfiniBand Architecture(IBA)。最早做InfiniBand的厂商是IBM和HP,现在主要是NVIDIA的Mellanox。InfiniBand从L2到L4都需要自己的专有硬件,成本非常高。
iWARP直接将RDMA实现在TCP上,优点就是成本最低,只需要采购支出iWARP的NIC即可以使用RDMA,缺点是性能不好,因为TCP协议栈本身过于重量级,即使按照iWARP厂商的通用做法将TCP卸载到硬件上实现,也很难超越IB和RoCE的性能。
RoCE(RDMA over Converged Ethernet)是一个允许在以太网上执行RDMA的网络协议。由于底层使用的以太网帧头,所以支持在以太网基础设施上使用RDMA。不过需要数据中心交换机DCB技术保证无丢包。相比IB交换机时延,交换机时延要稍高一些。由于只能应用于二层网络,不能跨越IP网段使用,市场应用场景相对受限。
RoCEv2协议构筑于UDP/IPv4或UDP/IPv6协议之上。由于基于IP层,所以可以被路由,将RoCE从以太网广播域扩展到IP可路由。由于UDP数据包不具有保序的特征,所以对于同一条数据流,即相同五元组的数据包要求不得改变顺序。另外,RoCEv2还要利用IP ECN等拥塞控制机制,来保障网络传输无损。RoCEv2也是目前主要的RDMA网络技术,以NVIDIA的Mellanox和Intel为代表的厂商,均支持RoCEv2的硬件卸载能力。