无脑013—— win11配置mmdetection实现训练自己的vol格式(xml)数据集
昨天使用cascade——rcnn 实现了MSAR 1.0的训练,今天来回顾一下
参考资料:
http://t.csdn.cn/8A5WE
http://t.csdn.cn/ccOZg
电脑 笔记本电脑,拯救者Y7000P 2018款,GTX1060显卡6G显存 ,cmd输入代码nvcc-version显示的CUDA版本 10.1,以下所有程序都在wsl虚拟机中执行
1.conda 创建新环境
conda create -n mmdet python=3.8
conda activate mmdet
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch
2.安装mmcv
pip install -U openmim #最后安装结束显示的openmim=0.3.9
mim install mmengine #最后安装结束显示的mmengine=0.8.4
mim install mmcv==2.0.0rc4 #Successfully installed mmcv-2.0.0rc4
3.安装mmdetection
输入cd 进入文件夹进行mmdet安装
cd mmdet/
pip install -v -e .
#运行完成显示 Successfully installed mmdet-3.1.0 pycocotools-2.0.7 scipy-1.10.1 shapely-2.0.1 terminaltables-3.1.10
注意,安装完成后,如果测试图片报错,显示mmcv版本过低,可以自行升级。
4.图片推理测试
去官网下载他们已经训练好的模型权重文件进行测试
https://github.com/open-mmlab/mmdetection/tree/main/configs/rtmdet
比如我下载的RTMDet- tiny
为他新建一个文件夹pt,放入下载好的文件
输入测试语句:
python demo/image_demo.py demo/fenda.jpg configs/rtmdet/rtmdet_tiny_8xb32-300e_coco.py --weights rtmdet_tiny_8xb32-300e_coco_20220902_112414-78e30dcc.pth --show
文件保存到output文件夹中,
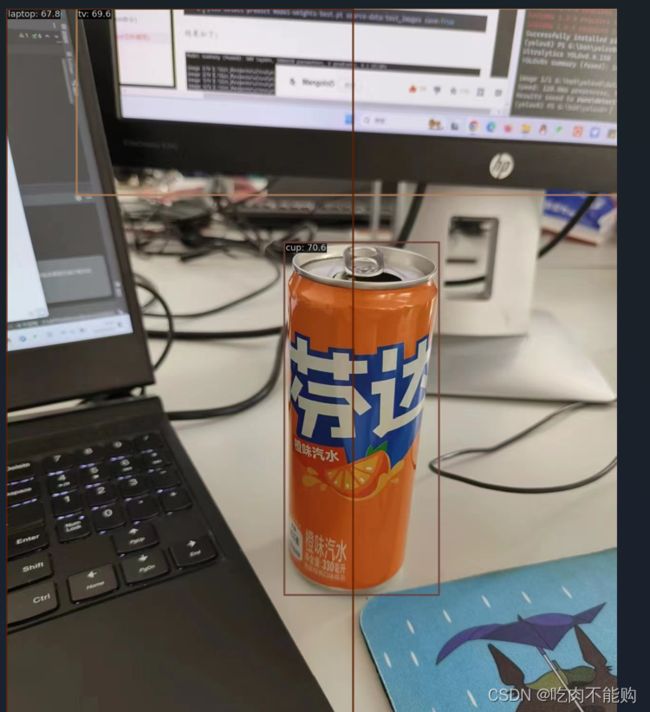
测试了三张图片
结果还可以
5. 准备训练自己的数据集
随便拍了十张图片,用labelimg进行标注
图片保存到G:\bsh\mmdet\data\images
这里使用的是xml格式

标签生成到这里:G:\bsh\mmdet\data\Annotations
然后使用我的代码生成数据加载的列表txt文件,
# coding:utf-8
import random
import argparse
import xml.etree.ElementTree as ET
import os
from os import getcwd
'''
如果你的数据集的路径长这样:
G:/bsh/dataset/luosi/Annotations
G:/bsh/dataset/luosi/images
'''
#这里是需要修改的地方,
ProjectPath = 'G:/bsh/mmdet/data/' #改成自己的路径,注意最后的/别拉下,否则不能合成路径
img_type = 'png' # 改成自己的图片类型,目前只支持三种类型jpg、png、bmg ,如果修改,自己去加到代码第140行
#下边的就不用管了
dataAllPath = ProjectPath
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default=ProjectPath+'Annotations', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main0
parser.add_argument('--txt_path', default=ProjectPath+'ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.8 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
sets = ['train', 'val', 'test']
print(dataAllPath)
print("生成成功,去检查一下吧~")
生成一个imageset文件夹,深层文件夹中存放的txt文件时所有图片的名称,不包括后缀
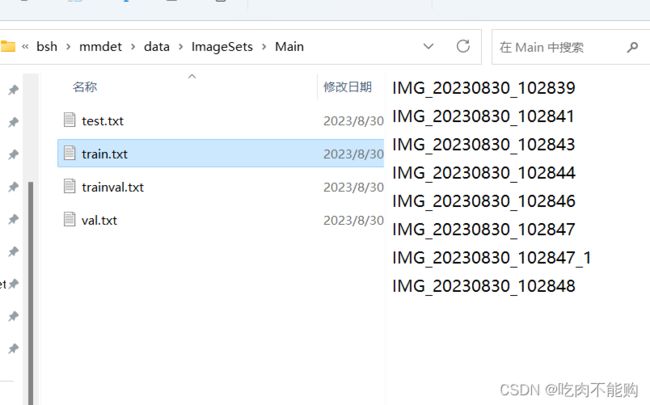
然后为了减少后续改代码的工作量,我们直接新建voc的文件夹来偷梁换柱,手动移动一下图片、标签、txt文件
G:\bsh\mmdet\data文件夹的内容如下:
data
│ └── VOCdevkit
│ └── VOC2007
│ ├── Annotations
│ │ ├── 003002_0.xml
│ │ ├── 003002_1.xml
│ │ └── ......
│ ├── ImageSets
│ │ └── Main
│ │ ├── test.txt
│ │ ├── train.txt
│ │ ├── trainval.txt
│ │ └── val.txt
│ └── JPEGImages
│ ├── 003002_0.jpg
│ ├── 003002_1.jpg
│ └── ......
然后开始配置代码文件
6.配置代码文件
这一部分我参考的资料是
http://t.csdn.cn/8A5WE
首先
6.1 修改configs文件夹
配置文件指的是 mmdetection/configs 下的文件,也就是你要训练的网络的一些配置。默认情况下,这些配置文件的使用的是 coco 格式,只有 mmdetection/pascal_voc 文件夹下的模型是使用 voc 格式,数量很少。如果要使用其他模型,则需要修改配置文件,这里以mmdetection/configs/cascade_rcnn/cascade_rcnn_r50_fpn_1x.py 为例。
1️⃣ 我们先在目录 mmdetection/configs/pascal_voc 下创建一个 cascade_rcnn_r50_fpn_1x_voc0712.py 作为cascade使用voc数据集的配置文件。就是我们的模型,使用以下基础配置文件,如果想要修改,可以直接去基础配置文件里面改。
_base_ = [
'../_base_/models/cascade_rcnn_r50_fpn_voc.py',
'../_base_/datasets/voc0712.py',
'../_base_/schedules/schedule_1x.py',
'../_base_/default_runtime.py',
]
runner = dict(type='EpochBasedRunner', max_epochs=7) # max_epochs就是我们要训练的总数,根据自己情况修改。
2️⃣继续在 mmdetection/configs/base/models 目录下的创建一个 cascade_rcnn_r50_fpn_voc.py配置文件,文件的内容从同目录下 cascade_rcnn_r50_fpn.py 里面复制一下,然后进行以下修改。
在 cascade_rcnn_r50_fpn_voc.py配置文件中搜索 num_classes ,改成自己的类别数量,比如说我有一个类,我就改成1,一共有三处num_class需要修改。
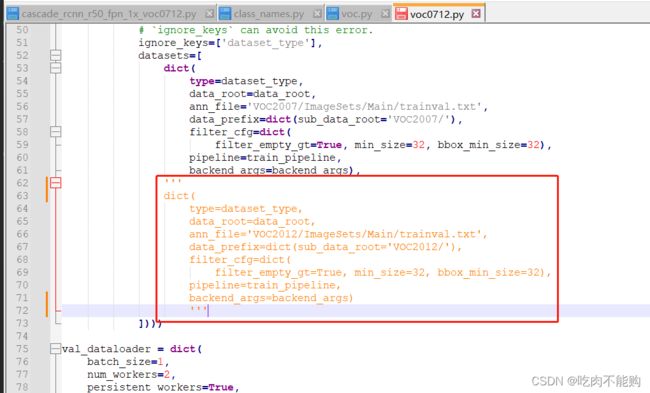
3️⃣继续在 mmdetection/configs/base/datasets/voc0712.py中注释掉voc2012的部分, 大概62-70行,都注释掉,如图
4️⃣
※ 【可选】如果自己的显存比较小的话,可以修改 base/datasets/voc0712.py 文件里面的 img_scale 共两处,例如改成(600,400)。
※【可选】为了让训练过程更直观,以及节省存储空间,可以修改 base/default_runtime.py 里面的 interval ,一共有两个,第一个是模型权重的保存间隔,一般我们设置的比较大一点,例如20(根据你训练的总epoch而定)。第二个是日志的保存间隔,一般我们设置的比较小一点,例如1(根据你训练的总epoch而定)。
6.2 修改mmdet文件夹(修改完这里边的内容需要重新编译)
1️⃣ 修改 G:\bsh\mmdet\mmdet\evaluation\functional\class_names.py ,把 voc_classes() 方法返回值,修改为自己的类别。例如我只有一类,我就改成下面这样,只有一类的后边加个逗号,有多类的不用加逗号。

2️⃣ 修改 mmdetection/mmdet/datasets/voc.py ,把 CLASSES ,修改为自己的类别。例如我只有一类,我就改成下面这样,只有一类的后边加个逗号,有多类的不用加逗号。
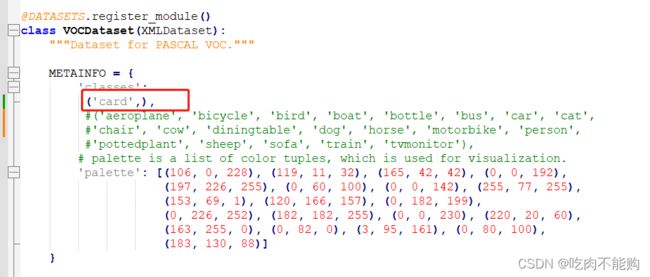
千万注意,我框起来的地方的位置,(‘card’)这一句是在’classes’后边的,上图是正确的,下图是错误的,会报错: elements in datasets sequence should be config or BaseDataset instance, but got

⚠️⚠️⚠️ 两个文件夹都修改完后,在mmdetection文件夹下,运行命令,python setup.py install,重新编译一下,为了让所修改的内容生效。这个过程大概10分钟能完成
7.开始训练
输入代码
python tools/train.py configs/pascal_voc/cascade_rcnn_r50_fpn_1x_voc0712.py