初阶数据结构(12)反射(概念、用途、基本信息、反射相关的类)、枚举(枚举和反射)以及lambda表达式(Lambda表达式的语法和基本使用、函数式接口、变量捕获 、Lambda在集合当中的使用 )
接上次博客:初阶数据结构(11)(字符串常量池【创建对象的思考、字符串常量值(StringTable)、再谈String对象创建】、泛型进阶:通配符【通配符解决什么问题、通配符上界、通配符下界】)_di-Dora的博客-CSDN博客
目录
反射
概念
用途
反射基本信息
反射相关的类(重要)
Class类(反射机制的起源 )
Class类中的相关方法(方法的使用方法在后边的示例当中)
反射示例
获得Class对象的三种方式
反射的使用
反射优点和缺点
优点:
缺点:
枚举的使用
背景及定义
使用
1、switch语句
2、Enum 类的常用方法
枚举优点缺点
优点:
缺点:
枚举和反射
枚举是否可以通过反射,拿到实例对象呢?
Lambda表达式
背景
Lambda表达式的语法
函数式接口
函数式接口定义:
@FunctionalInterface 注解:
Lambda表达式与函数式接口:
Lambda表达式的基本使用
变量捕获
匿名内部类的变量捕获
Lambda的变量捕获
Lambda在集合当中的使用
Collection接口:
List接口 :
Map接口 :
Lambda表达式的优缺点
反射
概念
Java语言的反射(reflection)机制是Java语言的一项强大功能,它允许在运行时获取、检查和操作类的信息,包括类的属性、方法、构造函数和其他成员。即在运行状态中,对于任意一个类,我们都能够知道这个类的所有属性和方法;对于任意一个对象,我们都能够调用它的任意方法和属性。
既然能拿到那么,我们就可以修改。
该功能使得Java程序在运行时可以检查和修改代码结构、部分类型信息,以及动态地获取类的结构和信息,并且可以实例化对象、动态调用方法和动态访问成员变量,即使在编译时并不知道这些类的具体信息。这为编写更加灵活、通用和动态的代码提供了便利。
用途
首先在日常的第三方应用开发过程中,经常会遇到某个类的某个成员变量、方法或是属性是私有的或是只对系统应用开放,这时候就可以利用Java的反射机制通过反射来获取所需的私有成员或是方法 。
主要的反射机制功能包括:
1. 获取类信息:通过反射,可以获取类的名称、父类、实现的接口、字段、方法、构造函数等信息。这使得我们可以在运行时了解类的结构和特性。也就是说,一旦获取了Class对象,我们就可以通过它来获取类的信息。
Class类提供了许多方法来查询类的结构,比如:
- getName(): 获取类的全限定名。
- getModifiers(): 获取类的修饰符,如public、abstract、final等。
- getSuperclass(): 获取类的父类。
- getInterfaces(): 获取类实现的接口数组。
- getFields(): 获取类的公共成员变量数组。
- getMethods(): 获取类的公共方法数组。
- getConstructors(): 获取类的公共构造函数数组。
2. 实例化对象:通过反射,我们可以实例化一个类的对象。即使在编译时并不知道具体的类名。这为动态地创建对象提供了便利。我们可以使用Class对象的 newInstance() 方法( 在Java 9中标记为过时,推荐将 getDeclaredConstructor() ,和 newInstance() 组合使用 )或者调用相应构造函数的 newInstance() 方法来创建对象。
3. 访问成员变量(属性):反射可以使我们访问类的成员变量,包括私有的。我们可以通过Field类来获取、设置和修改类的成员变量值(字段值),即使字段是私有的。这样可以在运行时读取和修改对象的状态。
4. 调用方法:通过反射,我们可以调用类(对象)的方法,包括私有方法。可以使用Method类来实现对方法的调用。这使得程序可以在运行时根据需要动态地调用不同的方法。
5. 动态代理:Java反射机制还支持动态代理,允许在运行时创建实现特定接口的代理对象,用于拦截和处理方法调用。
6. 修改类型信息:反射允许修改类的访问控制权限,使得原本无法访问的成员也可以被调用。
7. 构造函数:通过反射,我们可以获取类的构造函数信息并实例化对象。
需要注意的是,虽然反射提供了强大的动态性和灵活性,但它的使用也要谨慎,因为反射操作可能会破坏封装性、降低性能并引发安全隐患。在普通情况下,应优先考虑静态编译期间的类型安全性,只有在确实需要在运行时进行动态操作时才使用反射。
虽然反射为Java提供了很强的灵活性和动态性,但它也有一些缺点:
- 性能较差:与直接调用相比,反射操作的性能较差,因为它需要在运行时进行额外的检查和查找。
- 安全性问题:反射可以突破访问控制权限,可能导致一些安全问题。
- 代码可读性:使用反射可能使代码变得复杂和难以理解。
因此,使用反射时应该谨慎,只在确实需要在运行时动态处理不同类型的情况下使用它。
在大多数情况下,应该优先考虑静态编译期间的类型安全性。
其次,在实际开发中,反射通常用于像框架、ORM(对象关系映射)工具、依赖注入容器等需要在运行时动态处理不同类型的情况下。 反射最重要的用途就是开发各种通用框架,比如在spring中,我们将所有的类Bean交给spring容器管理,无 论是XML配置Bean还是注解配置,当我们从容器中获取Bean来依赖注入时,容器会读取配置,而配置中给的 就是类的信息,spring根据这些信息,需要创建那些Bean,spring就动态的创建这些类。
反射基本信息
在Java中,许多对象在运行时会表现出两种类型:编译时类型和运行时类型,这种特性被称为运行时类型信息(RTTI,Run-Time Type Information)。这是由于Java是一种静态类型语言,在编译时需要确定对象的类型以进行类型检查,但在运行时对象的具体类型可能会有所改变。
考虑下面的例子:
Person p = new Student();在这个例子中,变量 p 的编译时类型是 Person ,因为它声明为 Person 类型,而运行时类型是 Student ,因为它实际指向一个`Student`对象。
Java的反射机制允许我们在运行时动态地获取和操作对象的实际类型信息。通过反射,我们可以获取对象的运行时类型,以及该类型所属的类的信息。例如,我们可以通过以下方式获取对象 p 的运行时类型:
Class runtimeType = p.getClass();在上面的代码中,getClass() 方法返回对象 p 的运行时类型的 Class 对象。然后,我们可以使用反射获取该类型的相关信息,如类名、父类、实现的接口、成员变量、方法等。
String className = runtimeType.getName();
Class parentClass = runtimeType.getSuperclass();
Class[] interfaces = runtimeType.getInterfaces();除此之外,我们还可以使用反射来判断对象的实际类型是否为某个特定类或接口:
boolean isStudent = runtimeType.isAssignableFrom(Student.class);上述代码可以用来判断对象 p 的运行时类型是否为 Student 类或其子类。
通过反射,Java程序能够在运行时发现对象和类的真实信息,这使得我们可以编写更加灵活和通用的代码,适应不同类型的对象。
然而,再强调一次,反射的使用需要谨慎,因为其性能较差,可能会导致安全问题,并且会让代码变得复杂难以维护。在大多数情况下,应优先考虑静态编译期间的类型安全性,只有在需要动态处理不同类型对象的情况下才使用反射。
反射相关的类(重要)
反射的主要类位于Java的 java.lang.reflect 包中,其中包含了 Class 、Constructor 、 Field 和 Method 等类,它们提供了反射所需的主要功能。
- Class类:Class类是Java反射机制的核心类之一,它代表了类的实体,在运行的Java应用程序中表示类和接口。每个类在JVM中都有一个对应的Class对象。通过Class类,我们可以获取类的信息,如类名、父类、实现的接口、成员变量、方法等。也可以使用Class类动态地创建对象,调用类的方法和访问成员变量。Class类是实现反射功能的入口点。
- Field类:Field类是Java反射机制中用于代表类的成员变量(也称为属性)的类。通过Field类,我们可以获取和修改类的成员变量值,即使成员变量是私有的。可以使用Field类的`get()`方法获取成员变量的值,使用`set()`方法设置成员变量的值。Field类允许我们在运行时动态地访问和操作类的成员变量。
- Method类:Method类是Java反射机制中用于代表类的方法的类。通过Method类,我们可以调用类的方法,包括私有方法。可以使用Method类的`invoke()`方法来执行方法调用。Method类允许我们在运行时动态地调用类的方法,这为编写通用且动态的代码提供了便利。
- Constructor类:Constructor类是Java反射机制中用于代表类的构造方法的类。通过Constructor类,我们可以实例化对象,即在运行时创建类的实例。可以使用Constructor类的`newInstance()`方法来创建对象。Constructor类允许我们在运行时动态地实例化对象,这在某些情况下非常有用,例如在依赖注入、动态代理和反序列化中。
Class类(反射机制的起源 )
Class类位于java.lang包中,是Java反射机制的入口点。
在Java中,代表类的实体、表示类和接口的类就是 java.lang.Class 。Java文件经过编译后生成了.class文件,其中包含了编译后的字节码指令,而 JVM 在运行时需要解析这些 .class文件,将其加载到内存中,并转换为一个 java.lang.Class 对象。
java.lang.Class 类是Java反射机制的核心,它的一个实例代表了 JVM 中的一个类或接口。每个类或接口在 JVM 中都有唯一的一个 Class 对象与之对应。因此,可以说当程序在运行时,每个Java文件最终都会被解析为一个 java.lang.Class 类的实例。我们通过Java的反射机制应用到这个实例,就可以去获得甚至去添加改变这个类的属性和动作,使得这个类成为一个动态的类 。
Class类中的相关方法(方法的使用方法在后边的示例当中)
(重要)常用获得类相关的方法
- getClassLoader(): 这个方法是 java.lang.Class 类的一个成员方法,用于获取加载该类的类加载器(ClassLoader)。类加载器负责加载 Java 类到 JVM 中,它按照一定的规则搜索类路径,并将类的字节码加载到内存中。通过 getClassLoader() 方法,我们可以获得用于加载当前类的 ClassLoader 对象,从而可以进行一些与类加载器相关的操作。
- getDeclaredClasses(): java.lang.Class 类的成员方法,它返回一个包含该类中所有类和接口类的 Class 对象的数组。这个数组包括了类中定义的所有内部类、匿名类和本地类。不仅包括公共的类和接口,还包括私有的类和接口。通过调用 getDeclaredClasses() 方法,我们可以动态地获取当前类中定义的所有类的 Class 对象,从而进行一些与内部类相关的操作。
- forName( String className ): 这是 java.lang.Class 类的一个静态方法,它根据传入的类名字符串返回对应类的 Class 对象。该方法常用于在运行时动态加载类。传入的类名应该是类的全限定名,包括包名和类名。如果类名不正确或找不到对应的类,会抛出 ClassNotFoundException 异常。通过 forName( ) 方法,我们可以根据类名字符串获取对应类的Class对象,进而实现动态地加载和使用类。
- newInstance(): 这是 java.lang.Class 类的一个成员方法,在 Java 9 中被标记为过时,不推荐使用。它用于创建当前类的一个新实例(对象)。使用这个方法要求当前类必须有一个无参构造方法。通过 newInstance() 方法,我们可以在运行时动态地创建类的对象。在 Java 9 及以后的版本,推荐使用更加灵活的 getDeclaredConstructor() 方法配合 newInstance() 来实现对象的创建。
- getName(): 这是 java.lang.Class 类的一个成员方法,用于获取类的完整路径名字(包括包名和类名)。通过调用 getName() 方法,我们可以获得表示当前类的全限定名,例如: " com.example.MyClass "。该方法常用于输出类的名称和调试信息。
(重要)常用获得类中属性相关的方法(以下方法返回值为Field相关)
- getField(String name): 这是 java.lang.Class 类的一个成员方法,用于获取指定公有(public)属性(字段)的 Field 对象。Field 类代表类的成员变量,包括公有、私有和受保护的。通过getField( String name )方法,我们可以根据属性名(name参数)获取指定类中的公有属性对象。如果属性不存在或不是公有的,将会抛出 NoSuchFieldException 异常。
- getFields(): 这是java.lang.Class类的成员方法,用于获取所有公有(public)属性的Field对象数组。通过调用 getFields() 方法,我们可以获取指定类中的所有公有属性对象的集合,然后可以对这些属性进行遍历和操作。
- getDeclaredField(String name): 这是 java.lang.Class 类的一个成员方法,用于获取指定名称的属性(字段)的 Field 对象,包括公有的、私有的和受保护的属性。与 getField() 方法不同, getDeclaredField(String name) 方法可以获取所有类型的属性对象,而不仅限于公有属性。如果属性不存在或不可访问,将会抛出NoSuchFieldException异常。
- getDeclaredFields(): 这是 java.lang.Class 类的成员方法,用于获取所有属性的Field对象数组,包括公有的、私有的和受保护的属性。通过调用 getDeclaredFields() 方法,我们可以获取指定类中的所有属性对象的集合,然后可以对这些属性进行遍历和操作。
这些方法在反射机制中对属性的获取提供了不同的选项。getField() 和 getFields() 方法适用于获取公有属性,前者用于获取指定名称的公有属性,后者用于获取所有公有属性。而 getDeclaredField() 和 getDeclaredFields() 方法则适用于获取类中所有类型的属性,包括公有的、私有的和受保护的属性。
(了解)获得类中注解相关的方法
- getAnnotation( Class annotationClass ): 这是 java.lang.Class 类的一个成员方法,用于返回指定类型的公有注解对象。注解(Annotation)是一种元数据,它可以用于为类、方法、字段等元素添加额外的信息。通过 getAnnotation(Class annotationClass) 方法,我们可以获取指定类型的公有注解对象,如果该类型的注解不存在,则返回null。
- getAnnotations(): 这是 java.lang.Class 类的成员方法,用于返回该类中所有的公有注解对象。通过调用 getAnnotations() 方法,我们可以获取该类中所有公有注解对象的集合。返回的数组包含了所有在类定义中声明为公有的注解。
- getDeclaredAnnotation( Class annotationClass ): 这是 java.lang.Class 类的一个成员方法,用于返回指定类型的所有注解对象,包括公有的和非公有的。与 getAnnotation() 方法不同, getDeclaredAnnotation( Class annotationClass ) 方法可以获取该类中所有类型的注解对象,无论公有或私有。如果该类型的注解不存在,则返回null。
- getDeclaredAnnotations(): 这是 java.lang.Class 类的成员方法,用于返回该类中所有的注解对象,包括公有的和非公有的。通过调用 getDeclaredAnnotations() 方法,我们可以获取该类中所有注解对象的集合,无论它们是公有还是私有的。
加了Declared的权限更大。
(重要)获得类中构造器相关的方法(以下方法返回值为Constructor相关)
- getConstructor( Class... parameterTypes ): 这是 java.lang.Class 类的一个成员方法,用于获取指定参数类型的公有构造方法。构造方法是类在实例化对象时调用的特殊方法,它负责对象的初始化。通过 getConstructor( Class... parameterTypes ) 方法,我们可以获取该类中与指定参数类型( parameterTypes参数 )匹配的公有构造方法的 Constructor 对象。如果指定的构造方法不存在或不是公有的,将会抛出 NoSuchMethodException 异常。
- getConstructors(): 这是 java.lang.Class 类的成员方法,用于获取该类的所有公有构造方法。通过调用 getConstructors() 方法,我们可以获取该类中所有公有构造方法的数组,然后可以对这些构造方法进行遍历和操作。
- getDeclaredConstructor ( Class... parameterTypes ): 这是 java.lang.Class 类的一个成员方法,用于获取指定参数类型的构造方法,包括公有的、私有的和受保护的构造方法。与 getConstructor() 方法不同,getDeclaredConstructor ( Class... parameterTypes ) 方法可以获取所有类型的构造方法,而不仅限于公有构造方法。如果指定的构造方法不存在或不可访问,将会抛出 NoSuchMethodException 异常。
- getDeclaredConstructors(): 这是 java.lang.Class 类的成员方法,用于获取该类的所有构造方法,包括公有的、私有的和受保护的构造方法。通过调用 getDeclaredConstructors() 方法,我们可以获取该类中所有构造方法的数组,然后可以对这些构造方法进行遍历和操作。
(重要)获得类中方法相关的方法(以下方法返回值为Method相关)
- getMethod ( String name, Class... parameterTypes ) : 这是 java.lang.Class 类的一个成员方法,用于获取指定方法名和参数类型的公有方法。通过 getMethod ( String name, Class... parameterTypes ) 方法,我们可以获取该类中与指定方法名( name参数 )和参数类型( parameterTypes参数 )匹配的公有方法的Method对象。如果指定的方法不存在或不是公有的,将会抛出NoSuchMethodException异常。
- getMethods(): 这是 java.lang.Class 类的成员方法,用于获取该类的所有公有方法。通过调用 getMethods() 方法,我们可以获取该类中所有公有方法的数组,然后可以对这些方法进行遍历和操作。
- getDeclaredMethod ( String name, Class... parameterTypes ) : 这是 java.lang.Class 类的一个成员方法,用于获取指定方法名和参数类型的方法,包括公有的、私有的和受保护的方法。与 getMethod() 方法不同,getDeclaredMethod ( String name, Class... parameterTypes ) 方法可以获取所有类型的方法,而不仅限于公有方法。如果指定的方法不存在或不可访问,将会抛出NoSuchMethodException异常。
- getDeclaredMethods(): 这是 java.lang.Class 类的成员方法,用于获取该类的所有方法,包括公有的、私有的和受保护的方法。通过调用 getDeclaredMethods() 方法,我们可以获取该类中所有方法的数组,然后可以对这些方法进行遍历和操作。
反射示例
获得Class对象的三种方式
在反射之前,我们需要做的第一步就是先拿到当前需要反射的类的Class对象,然后通过Class对象的核心方法,达到反射的目的,即:在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象, 都能够调用它的任意方法和属性,既然能拿到那么,我们就可以修改部分类型信息。
第一种,使用 Class.forName( "类的全路径名" ); 静态方法。
前提:已明确类的全路径名。
第二种,使用 .class 方法。
说明:仅适合在编译前就已经明确要操作的 Class
第三种,使用类对象的 getClass() 方法
以上3种方法,第1方法用的最多。
class Student{
//私有属性name
private String name = "S.coups";
//公有属性age
public int age = 18;
//不带参数的构造方法
public Student(){
System.out.println("Student()");
}
private Student(String name,int age) {
this.name = name;
this.age = age;
System.out.println("Student(String,name)");
}
private void eat(){
System.out.println("i am eating");
}
public void sleep(){
System.out.println("i am sleeping");
}
private void function(String str) {
System.out.println(str);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public class Test {
//Class对象 只有一个
public static void main(String[] args) {
/*1.通过 Class 对象的 forName() 静态方法来获取,用的最多,
但可能抛出 ClassNotFoundException 异常*/
Class c1;
try {
c1 = Class.forName("reflectdemo.Student");
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
/*2.直接通过 类名.class 的方式得到,该方法最为安全可靠,程序性能更高
这说明任何一个类都有一个隐含的静态成员变量 class*/
Class c2;
c2 = Student.class;
//3.通过getClass获取Class对象
Student student = new Student();
Class c3 = student.getClass();
//一个类在 JVM 中只会有一个 Class 实例,即我们对上面获取的
//c1,c2,c3进行 equals 比较,发现都是true
System.out.println(c1.equals(c2));
System.out.println(c1.equals(c3));
System.out.println(c3.equals(c2));
}
}反射的使用
接下来我们开始使用反射,我们依旧反射上面的Student类,把反射的逻辑写到另外的类当中进行理解
注意:所有和反射相关的包都在 import java.lang.reflect 包下面。
import java.lang.reflect.Constructor;
import java.lang.reflect.Field;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class ReflectDemo {
//如何通过反射 实例化对象
public static void reflectNewInstance() {
Class c1;
try {
c1 = Class.forName("reflectdemo.Student");
Student student = (Student) c1.newInstance();
System.out.println(student);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
// 反射私有的构造方法 屏蔽内容为获得公有的构造方法
public static void reflectPrivateConstructor() {
Class c1;
try {
c1 = Class.forName("reflectdemo.Student");
Constructor con =
(Constructor)c1.getDeclaredConstructor(String.class,int.class);
con.setAccessible(true);
//这里的newInstance不再是Class的newInstance,而是Constructor的
Student student = con.newInstance("S.coups",18);
System.out.println(student);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e);
} catch (InvocationTargetException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
// 反射私有属性
public static void reflectPrivateField() {
Class c1;
try {
c1 = Class.forName("reflectdemo.Student");
Field field = c1.getDeclaredField("name");
field.setAccessible(true);
Student student = (Student) c1.newInstance();
field.set(student,"wangwu");
System.out.println(student);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
} catch (NoSuchFieldException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
// 反射私有方法
public static void reflectPrivateMethod() {
Class c1;
try {
c1 = Class.forName("reflectdemo.Student");
Method method = c1.getDeclaredMethod("function",String.class);
method.setAccessible(true);
Student student = (Student) c1.newInstance();
method.invoke(student,"我是一个参数");
//System.out.println(student);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
} catch (InvocationTargetException e) {
throw new RuntimeException(e);
}
} 私有的一定要调用一下 setAccessible() 方法:
con.setAccessible(true); 表示你确定的态度。
由于反射可以获取私有信息,这和我们之前学过的封装矛盾了。所以反射是一把双刃剑,要用好它!
反射优点和缺点
反射机制在Java中具有一系列优点和缺点,让我们一起来详细了解它们:
优点:
1. 动态获取类信息:通过反射,我们可以在运行时动态地获取类的属性、方法、构造函数等信息。这使得我们可以在不知道类的具体信息的情况下,灵活地操作类和对象,为编写通用、灵活的代码提供了便利。
2. 增加灵活性和扩展性:反射可以在运行时动态地加载和使用类,这为程序的扩展性和灵活性提供了很大的优势。通过反射,我们可以在程序运行时根据不同的需求加载不同的类,而不需要在编译期就确定所有的类和对象。
3. 降低耦合性:反射允许程序在运行时通过字符串的形式来调用方法和访问属性,这减少了代码之间的耦合性。代码不再依赖于具体的类,而是通过类名字符串来实现动态调用,从而降低了代码之间的直接依赖。
4. 应用于流行框架:反射已经广泛应用于许多流行的Java框架,如Struts、Hibernate、Spring等。这些框架能够利用反射机制动态地处理不同的类和对象,实现各种功能,使得框架更加灵活和强大。
缺点:
1. 低效率:反射是通过字符串解析、查找类的成员并动态调用的过程,因此比直接调用代码的效率要低。比如之前我们只是想要实例化一个对象,但是却调用了不止一个方法。调用方法就得开辟栈帧,开辟栈帧就得浪费资源。频繁使用反射可能会导致程序的性能下降。所以,在性能要求较高的场景下,应该谨慎使用反射。
参考链接:大家都说 Java 反射效率低,你知道原因在哪里么_慕课手记 (imooc.com)
2. 维护问题:反射绕过了源代码的技术,使得代码更加复杂和晦涩。反射的使用可能会导致一些维护问题,因为它不遵循常规的编译时类型检查,容易引入错误或难以调试。
3. 安全性问题:反射可以访问和修改类的私有成员,这可能导致安全性问题。恶意使用反射可能会绕过访问控制权限,造成潜在的安全漏洞。因此,在使用反射时要格外小心,确保只访问合法和安全的成员。
总结来说,反射机制是一项强大而灵活的特性,它在很多场景下都能带来巨大的便利和优势。然而,合理使用反射非常重要,应该在性能、安全性和维护性方面权衡利弊。在需要动态操作类和对象的场景下,合理使用反射可以提高代码的灵活性和可维护性,但也需要谨慎考虑性能和安全问题。
枚举的使用
背景及定义
枚举是在 JDK1.5 以后引入的。
枚举的主要用途是:将一组常量组织起来,在 JDK1.5之前,为了表示一组常量,通常使用定义常量的方式,例如:
public static final int RED = 1;
public static final int GREEN = 2;
public static final int BLACK = 3;
但是常量举例有不好的地方。这种方式存在一些问题,比如可读性差,容易出现错误,没有类型安全性等。为了解决这些问题,JDK1.5引入了枚举(Enum)类型,枚举提供了一种更好的方式来表示一组常量。
例如:可能碰巧有个数字1,但是他有可能误会为是RED,现在我们可以直接用枚举来进行组织,这样一来,就拥有了类型,枚举类型。而不是普通的整形1。
枚举是一种特殊的类,它限制实例化数量为预定义的常量集合。 以下是使用枚举来表示上述常量的示例:
public enum TestEnum {
RED,BLACK,GREEN;
}
在这个例子中,Color是一个枚举类型,它定义了三个枚举常量:RED、GREEN和BLACK。每个枚举常量实际上是Color类型的一个实例,这些实例在运行时只能是唯一的,因此保证了类型安全性。
枚举的用途包括:
1. 代替一组常量:枚举提供了一种更清晰、更简洁的方式来组织一组常量,使得代码可读性更好。
2. 类型安全:使用枚举可以确保编译器对枚举值的类型进行检查,防止传入错误类型的常量。
3. 简化代码:使用枚举可以简化代码的编写,避免手动管理常量值。
4. 扩展性:枚举可以包含方法和字段,使其具备更多功能和特性。
5. 使用枚举集合:枚举可以很方便地用于集合操作,例如遍历、过滤等。
优点:
将常量组织起来统一进行管理 :枚举允许将相关的常量组织在一起,形成一个有意义的集合,从而提高代码的可维护性和可读性。通过枚举,可以将所有相关的常量放在一个地方,便于集中管理和维护。
场景:
1. 错误状态码:在处理错误和异常情况时,可以使用枚举来表示不同的错误状态码,而不是使用散落在代码中的魔法数字。这样可以更清晰地理解错误状态,避免混淆和错误使用。
2. 消息类型:在网络通信或者消息传递的场景中,可以使用枚举来表示不同类型的消息,从而提高代码的可读性和稳定性。
3. 颜色的划分:颜色常常用于图形界面或者数据可视化,通过枚举来表示不同的颜色可以使代码更加简洁和易懂。
4. 状态机:状态机是一种常见的程序设计模式,用于描述对象在不同状态下的行为转换。枚举可以用来表示状态机的不同状态和状态之间的转换。
5. 其他用途:枚举还可以用于表示一组选项、一组权限或者一组固定的选项等。
本质:
枚举本质上是java.lang.Enum的子类,即使没有显式地继承Enum类,Java编译器也会隐式地将自己写的枚举类继承自Enum。这也是为什么枚举类型不能再继承其他类的原因,因为Java不支持多继承。
由于枚举类继承自Enum类,所以枚举具有Enum类提供的一些特性,例如:
a. values()方法:通过该方法可以获取枚举类中所有的枚举常量数组。
b. ordinal()方法:获取枚举常量在枚举声明中的位置,从0开始计数。
c. name()方法:获取枚举常量的名称。
d. compareTo()方法:用于枚举常量之间的比较。
e. valueOf()方法:根据给定的枚举常量名称获取对应的枚举常量。
综上所述,枚举是在JDK1.5中引入的,在Java中有着广泛的应用场景,通过将常量组织起来统一进行管理,可以提高代码的可维护性和可读性。同时,枚举的本质是Enum类的子类,因此具有Enum类提供的一些特性,可以更方便地操作枚举常量。因此,使用枚举比传统的常量定义方式更加推荐。
使用
1、switch语句
package enumdemo;
public enum TestEnum {
//枚举对象
RED(1,"RED"),
WHITE(2,"WHITE"),
GREEN(3,"GREEN");
public String color;
public int ordinal;
private TestEnum(int ordinal,String color) {
this.ordinal = ordinal;
this.color = color;
}
public static void main(String[] args) {
TestEnum testEnum = TestEnum.RED;
switch (testEnum) {
case RED:
System.out.println("红色");
break;
case GREEN:
System.out.println("绿色");
break;
case WHITE:
System.out.println("白色");
break;
default:
break;
}
}
}2、Enum 类的常用方法
1. values()方法:values() 方法是Enum类中的一个静态方法,它以数组形式返回枚举类型的所有成员。该方法非常有用,可以用于遍历枚举中的所有枚举常量。
public enum Color {
RED,
GREEN,
BLUE
}
Color[] colors = Color.values(); // 返回一个Color数组,包含所有枚举常量
2. ordinal()方法: ordinal() 方法是Enum类中的实例方法,用于获取枚举成员的索引位置(从0开始)。这个索引位置对应着枚举常量在枚举声明中的顺序。
public enum Weekday {
MONDAY, // ordinal()返回0
TUESDAY, // ordinal()返回1
WEDNESDAY, // ordinal()返回2
// ...
}
Weekday day = Weekday.WEDNESDAY;
int index = day.ordinal(); // 返回2,因为WEDNESDAY在声明中的索引位置为2
注意:尽量避免在代码中过度依赖 ordinal() 方法,因为它与枚举声明的顺序紧密相关。如果在后续修改枚举的顺序,可能会导致已有代码出错。
3. valueOf() 方法:valueOf() 方法是Enum类中的静态方法,它用于将普通字符串转换为枚举实例。字符串参数必须与枚举常量的名称完全匹配,否则会抛出 llegalArgumentException 异常。
String colorName = "GREEN";
Color color = Color.valueOf(colorName); // 将字符串"GREEN"转换为Color枚举实例Color.GREEN
注意:valueOf() 方法对于大小写敏感,如果传入的字符串与任何枚举常量的名称都不匹配,会抛出异常。
4. compareTo() 方法:compareTo() 方法是Enum类中的实例方法,用于比较两个枚举常量在枚举声明时的顺序。返回值是两个枚举常量的位置差值。
public enum Size {
SMALL,
MEDIUM,
LARGE
}
Size size1 = Size.SMALL;
Size size2 = Size.LARGE;
int result = size1.compareTo(size2); // 返回负数,因为SMALL在LARGE之前
compareTo() 方法的返回值遵循以下规则:
- 如果调用对象在参数对象之前,则返回负数。
- 如果调用对象等于参数对象,则返回0。
- 如果调用对象在参数对象之后,则返回正数。
注意:使用compareTo() 方法时需要保证枚举对象在同一个枚举类型中,否则会抛出 ClassCastException 异常。
Enum类的这些常用方法为枚举类型的使用提供了便捷性和灵活性,同时要注意 ordinal() 和 valueOf() 方法的潜在陷阱,确保正确使用并处理可能出现的异常情况。
以下是一些运用:
public enum TestEnum {
RED,BLACK,GREEN,WHITE;
public static void main(String[] args) {
TestEnum[] testEnums = TestEnum.values();
for (int i = 0; i < testEnums.length; i++) {
System.out.println(testEnums[i]+" "+testEnums[i].ordinal());
}
System.out.println("=====");
TestEnum testEnum = TestEnum.valueOf("RED");
System.out.println(testEnum);
System.out.println(RED.compareTo(WHITE));
}
public static void main1(String[] args) {
//拿到枚举实例BLACK
TestEnum testEnum = TestEnum.BLACK;
//拿到枚举实例RED
TestEnum testEnum21 = TestEnum.RED;
System.out.println(testEnum.compareTo(testEnum21));
System.out.println(BLACK.compareTo(RED));
System.out.println(RED.compareTo(BLACK));
}
}
你可能会疑惑,为什么这里枚举常量还有compareTo()方法?
因为Java当中的枚举类十分特殊,都是默认继承于Java原生的Enum类
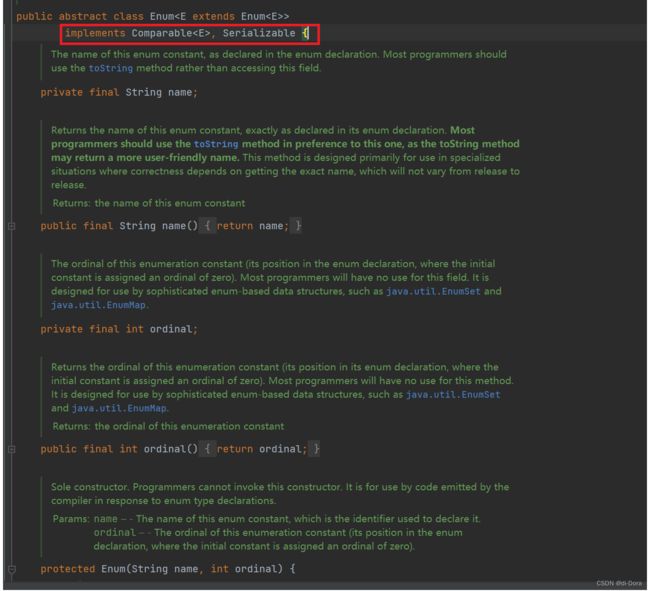
values() 方法不在 Enum 类中,而是在所有枚举类的编译后生成的具体枚举类中。这是因为values() 方法的实现是由编译器自动生成的,它返回一个包含枚举类所有枚举常量的数组。
在编译时,Java 编译器会根据枚举类的定义,自动生成一个包含枚举常量的数组,并将 values() 方法的实现插入到具体的枚举类中。
枚举类是一种特殊的类,它可以定义一组有限的常量对象,每个常量对象代表一个枚举实例。而编译器会在编译时自动将这些枚举常量转换为一个数组,以便可以通过 values() 方法获取这个数组。
enum Color {
RED, GREEN, BLUE;
}
// 编译后生成的枚举类大致如下所示
final class Color extends Enum {
public static final Color RED = new Color();
public static final Color GREEN = new Color();
public static final Color BLUE = new Color();
// 自动生成的 values() 方法
public static Color[] values() {
return new Color[] { RED, GREEN, BLUE };
}
} 因为 values() 方法在具体的枚举类中动态生成,所以可以通过 Enum 类型的引用直接调用 values() 方法。例如:
Enum enumRef = Color.RED;
Color[] colors = enumRef.values(); // 这里调用的其实是 Color.values() 注意,虽然我们可以通过 Enum 类型的引用调用 values() 方法,但实际上,它是根据具体的枚举类来执行的,返回的数组也是具体枚举类的数组。所以,在使用 values() 方法时,我们通常直接通过枚举类来调用,例如 Color.values()。
刚刚说过,在Java当中枚举实际上就是一个类。所以我们在定义枚举的时候,还可以这样定义和使用枚举:
public enum TestEnum {
RED("red",1),
BLACK("black",2),
WHITE("white",3),
GREEN("green",4);
private String name;
private int key;
/**
* 1、当枚举对象有参数后,需要提供相应的构造函数
* 2、枚举的构造函数默认是私有的 这个一定要记住
* @param name
* @param key
*/
private TestEnum (String name,int key) {
this.name = name;
this.key = key;
}
public static TestEnum getEnumKey (int key) {
for (TestEnum t: TestEnum.values()) {
if(t.key == key) {
return t;
}
}
return null;
}
public static void main(String[] args) {
System.out.println(getEnumKey(2));
}
}
这就引出了值得注意的一点,我们自己写的枚举类的构造方法默认是私有的。
而且,当你加了两个参数的时候,你会发现原来的枚举对象已经无法提供默认的构造方法了,所以会报错。
public enum TestEnum {
//枚举对象会报错
RED,WHITE,GREEN;
public String color;
public int ordinal;
private TestEnum(int ordinal,String color) {
this.ordinal = ordinal;
this.color = color;
}
枚举优点缺点
优点:
1. 枚举常量更简单安全:枚举常量在使用时更加简洁,通过枚举可以将一组常量集合在一起,避免了散乱定义常量的情况,提高了代码的可读性和可维护性。同时,枚举在编译期间会被编译器检查,确保类型安全,避免了传入错误类型的常量值,减少了潜在的错误。
2. 枚举具有内置方法,代码更优雅:枚举类型具有一些内置方法,如前面提到的 values() 、 valueOf() 、 ordinal() 和 compareTo() 等,这些方法在处理枚举常量时非常方便。此外,枚举常量可以拥有字段和方法,允许为每个常量添加更多信息和行为,使得代码更加优雅、模块化。
3. 类型安全:枚举常量在编译期间进行类型检查,避免了使用普通常量时出现的类型错误。这使得在代码中使用枚举更加可靠,减少了运行时错误的可能性。
缺点:
1. 不可继承,无法扩展:枚举是final类,因此无法继承其他类或者被其他类继承。这意味着枚举常量无法成为其他类的子类,也无法在现有枚举中添加新的常量。虽然这确保了枚举的稳定性,但有时也限制了其灵活性和扩展性。
2. 有限的实例:枚举常量是在编译时期固定的,每个枚举常量在运行时只有一个实例。这意味着枚举常量的数量是有限的,无法动态地创建新的实例。在某些情况下,这可能会限制其灵活性。
3. 内存占用:枚举常量在枚举类加载时被初始化,并在整个生命周期中存在于内存中。如果枚举常量非常多或者占用大量内存,可能会影响应用程序的性能和内存占用。
枚举是Java中非常有用的数据类型,具有许多优点,如类型安全、可读性好、代码更优雅等。但同时,也需要注意它的一些限制,如不可继承、有限的实例和可能的内存占用问题。因此,在使用枚举时,我们需要根据具体的场景权衡利弊,选择最合适的数据类型来实现需求。
枚举和反射
枚举是否可以通过反射,拿到实例对象呢?
我们刚刚在反射里边看到了,任何一个类,哪怕其构造方法是私有的,我们也可以通过反射拿到他的实例对象,那 么枚举的构造方法也是私有的,我们是否可以拿到呢?接下来,我们来实验一下:
package enumdemo;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
public class Constant {
public static final int RED = 1;
public static final int WHITE = 2;
public static final int GREEN = 3;
public static void main(String[] args) throws ClassNotFoundException {
Class c = Class.forName("enumdemo.TestEnum");
//注意传入对应的参数,获得对应的构造方法来构造对象,当前枚举类是提供了两个参数分别是String和int。
try {
Constructor constructor
= c.getDeclaredConstructor(int.class,String.class);
constructor.setAccessible(true);
TestEnum testEnum
= (TestEnum)constructor.newInstance(99,"hello");
System.out.println(testEnum);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e);
} catch (InvocationTargetException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}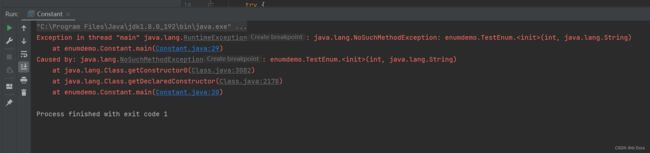
哦莫哦莫 !看到没有哇!
异常信息是: java.lang.NoSuchMethodException: TestEnum.(java.lang.String, int) ,什么意思啊?
意思就是没有对应的构造方法!
我的天呐!我们提供的枚举的构造方法就是两个参数分别是 String 和 int 啊!!!!问题出现在哪里呢?
还记不记得我们之前说过的,我们所有的枚举类,都是默认继承与 java.lang.Enum ,说到继承,继承了什么?继承了父类除构造函数外的所有东西,并且子类要帮助父类进行构造!而我们写的类,并没有帮助父类构造!
那意思是,我们要在自己的枚举类里面,提供super吗?
不是的,枚举比较特殊,虽然我们写的是两个参数,但是默认他还添加了两个参数,哪两个参数呢?我们看一下Enum类的源码: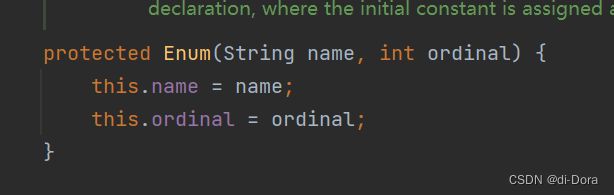
也就是说,我们自己的构造函数有两个参数一个是String一个是int,同时它默认后边还会给两个参数,一个是 String一个是int。也就是说,这里我们正确给的是4个参数:
try {
Class classStudent = Class.forName("TestEnum");
//注意传入对应的参数,获得对应的构造方法来构造对象,当前枚举类是提供了两个参数分别是
String和int。
Constructor declaredConstructorStudent =
classStudent.getDeclaredConstructor(String.class,int.class,String.class,int.class);
//设置为true后可修改访问权限
declaredConstructorStudent.setAccessible(true);
//后两个为子类参数,大家可以将当前枚举类的key类型改为double验证
Object objectStudent = declaredConstructorStudent.newInstance("父类参数",666,"子类参数",888);
TestEnum testEnum = (TestEnum) objectStudent;
System.out.println("获得枚举的私有构造函数:"+testEnum);
} catch (Exception ex) {
ex.printStackTrace();
}
}
package enumdemo;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
public class Constant {
public static final int RED = 1;
public static final int WHITE = 2;
public static final int GREEN = 3;
public static void main(String[] args) throws ClassNotFoundException {
Class c = Class.forName("enumdemo.TestEnum");
try {
Constructor constructor
= c.getDeclaredConstructor(String.class,int.class,int.class,String.class);
constructor.setAccessible(true);
TestEnum testEnum
= (TestEnum)constructor.newInstance("父类",999,99,"子类");
System.out.println(testEnum);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e);
} catch (InvocationTargetException e) {
throw new RuntimeException(e);
} catch (InstantiationException e) {
throw new RuntimeException(e);
} catch (IllegalAccessException e) {
throw new RuntimeException(e);
}
}
}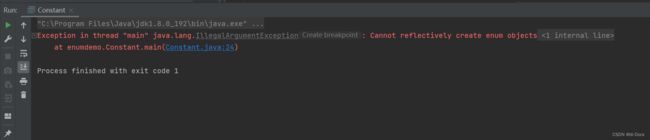
哇去!它又报错了,不过还好,这次就是我想要的结果!
此时的异常信息显示是我的一个方法: newInstance() 报错了!
没错,问题就是这里,我们来看一下这个方法的源码,为什么会抛出 java.lang.IllegalArgumentException: 异常呢?
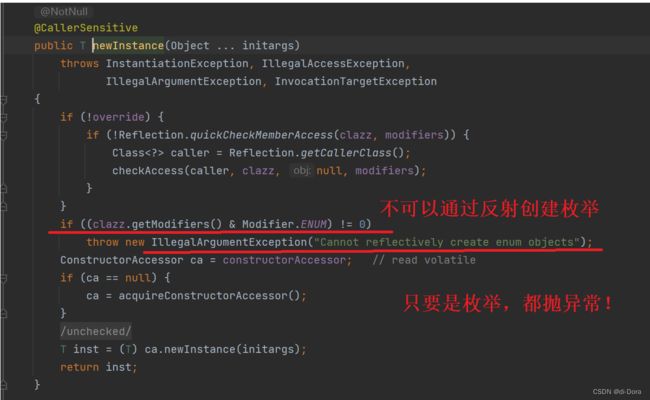
所以你不能通过反射获取枚举类的实例!所以呢,枚举非常的安全。
原版问题是:为什么枚举实现单例模式是安全的?
这道题是2017年阿里巴巴曾经问到的一个问题,不看不知道,一看吓一跳!大家记住这个坑。
先简单记录一下,等学完单例模式再来回顾:
1、写一个单例模式。
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {}
public static Singleton getInstance() {
if (uniqueInstance == null) {
synchronized (Singleton.class){
if(uniqueInstance == null){//进入区域后,再检查一次,如果仍是null,才创建实例
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}2、用静态内部类实现一个单例模式。
class Singleton {
/** 私有化构造器 */
private Singleton() {
}
/** 对外提供公共的访问方法 */
public static Singleton getInstance() {
return UserSingletonHolder.INSTANCE;
}
/** 写一个静态内部类,里面实例化外部类 */
private static class UserSingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
}
public class Main {
public static void main(String[] args) {
Singleton u1 = Singleton.getInstance();
Singleton u2 = Singleton.getInstance();
System.out.println("两个实例是否相同:"+ (u1==u2));
}
}
3、用枚举实现一个单例模式。
public enum TestEnum {
INSTANCE;
public TestEnum getInstance(){
return INSTANCE;
}
public static void main(String[] args) {
TestEnum singleton1=TestEnum.INSTANCE;
TestEnum singleton2=TestEnum.INSTANCE;
System.out.println("两个实例是否相同:"+(singleton1==singleton2));
}
}
Lambda表达式
背景
Lambda表达式是Java SE 8中引入的一个重要特性,它为Java引入了函数式编程的思想。在传统的Java中,我们只能通过定义一个具体的类并实现某个接口的方式来创建可传递的功能,这样的代码通常显得冗长和繁琐。而Lambda表达式的引入使得代码更加简洁和灵活。
Lambda表达式允许我们使用更加紧凑的语法——表达式,来代替功能接口(Functional Interface)。
功能接口是指只有一个抽象方法的接口,这样的接口可以隐式转换为Lambda表达式。Lambda表达式提供了一个形式简洁的语法来表示这种单一方法的接口的实现。
Lambda表达式就和方法一样,提供了一个正常的参数列表和一个使用这些参数的主体(body,可以是一个表达式或一个代码块)。
语法如下:
(parameters) -> expression或
(parameters) -> { statements; }其中,parameters是方法参数列表,expression是一个单一的表达式,而 { statements; } 是一个代码块。
Lambda表达式和方法类似,都有参数列表和方法体,但是Lambda表达式的目的是为了简化代码,尤其是在创建函数式接口的实例时。
举个例子,假设我们有一个函数式接口 MathOperation 表示数学操作,它有一个抽象方法 int operate(int a, int b); ,我们可以使用 Lambda表达式来创建该接口的实例:
MathOperation addition = (a, b) -> a + b;
MathOperation subtraction = (a, b) -> a - b;
MathOperation multiplication = (a, b) -> a * b;
MathOperation division = (a, b) -> a / b;上面的代码用 Lambda表达式分别创建了加法、减法、乘法和除法的实例。这样的代码更加简洁,不需要显式地定义每个操作的实现类。
Lambda表达式的灵活性还体现在它可以捕获局部变量,并且这些局部变量不需要声明为final(但必须是事实上的final,即在Lambda表达式内部不能修改)。
Lambda表达式是基于数学中的λ演算的概念,而λ演算是一种用于研究函数定义、函数应用和递归的形式系统。这种名称显示了Lambda表达式的本质是用来表示函数(功能)的,并且它的引入使得Java能够更好地支持函数式编程范式。
总结来说,Lambda表达式是Java SE 8引入的一项重要特性,它允许我们通过简洁的语法来代替功能接口的实现,从而使代码更加简洁和灵活。。Lambda 表达式(Lambda expression),基于数学中的λ演算得名,也可称为闭包(Closure) 。它在函数式编程、并行处理等方面提供了强大的支持,是Java语言向现代编程范式发展的一大步
Lambda表达式的语法
基本语法: (parameters) -> expression 或 (parameters) ->{ statements; }
Lambda表达式由三部分组成:
1. 参数(Parameters):
在函数式接口里,参数指的是函数式接口的抽象方法中定义的形参列表,类似于普通方法中的形参。这些参数在使用 Lambda表达式来实现函数式接口时,需要被传递进 Lambda表达式中。
参数的类型可以明确地声明,也可以由Java虚拟机(JVM)根据上下文进行隐含推断。
例如,对于一个函数式接口 Consumer
明确声明参数类型:
Consumer consumer = (Integer num) -> {
// Lambda表达式的方法体,使用num进行操作
System.out.println(num);
}; 省略参数类型:
Consumer consumer = (num) -> {
// Lambda表达式的方法体,使用num进行操作
System.out.println(num);
}; 当只有一个参数时,甚至还可以省略圆括号,如下所示:
Consumer consumer = num -> {
// Lambda表达式的方法体,使用num进行操作
System.out.println(num);
}; 2. ->(箭头符号):
在Lambda表达式中,箭头符号 “ -> ” 用来分隔参数列表与 Lambda表达式的主体部分。你可以将箭头符号理解为 “ 被用于 ” 的意思,表示将参数用于后面的 Lambda表达式方法体的实现。箭头符号的左侧是参数列表,右侧是 Lambda表达式的主体部分。在上面的例子中,箭头符号将参数列表和 Lambda表达式的方法体分开。
3. 方法体(Body):
Lambda表达式的主体部分叫做方法体,它是函数式接口中抽象方法的具体实现。方法体可以是一个表达式,也可以是一个代码块。无论是表达式还是代码块,都可以用来返回一个值或者什么都不返回,取决于函数式接口的抽象方法定义。在Lambda表达式中,使用方法体来实现函数式接口的抽象方法。
表达式形式的方法体:
Function converter = num -> num % 2 == 0 ? "even" : "odd"; 代码块形式的方法体:
Function converter = num -> {
if (num % 2 == 0) {
return "even";
} else {
return "odd";
}
}; 在上述两个例子中,converter 是一个 Function 函数式接口,它接受一个 Integer 类型的参数,并返回一个 String 类型的结果。方法体可以是单行的表达式,也可以是使用花括号包裹的多行代码块。不论哪种形式,方法体都表示函数式接口的具体实现。
总结:
Lambda表达式的核心组成是参数、箭头符号和方法体。参数用于传递函数式接口中抽象方法的参数,箭头符号将参数与方法体分隔开,方法体是对抽象方法的具体实现,可以是表达式或者代码块。Lambda表达式的简洁性和灵活性使得函数式编程在Java中变得更加便捷。
如下是把优先级队列中的比较转换为 Lambda表达式的例子:
public static void main1(String[] args) {
PriorityQueue priorityQueue = new PriorityQueue<>(new Comparator() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
});
PriorityQueue priorityQueue2 = new PriorityQueue<>(((x, o2) -> x-o2));
} 函数式接口
要了解Lambda表达式,首先需要了解什么是函数式接口。
函数式接口定义:
函数式接口是指只包含一个抽象方法的接口。它可以有默认方法(Default Method)和静态方法(Static Method),但只能有一个抽象方法。由于函数式接口只有一个抽象方法,所以可以被隐式转换为Lambda表达式。Java中的许多常见接口,如Runnable、Comparator等,都是函数式接口。
定义方式:
@FunctionalInterface
interface NoParameterNoReturn {
//注意:只能有一个方法
void test();
}但是这种方式也是可以的:
@FunctionalInterface
interface NoParameterNoReturn {
void test();
default void test2() {
System.out.println("JDK1.8新特性,default默认方法可以有具体的实现");
}
}@FunctionalInterface 注解:
为了明确地指示一个接口是函数式接口,Java提供了@FunctionalInterface注解。该注解是非必需的,但推荐在函数式接口上使用它。如果你在一个接口上声明了@FunctionalInterface注解,并且该接口不符合函数式接口的定义(即拥有多于一个的抽象方法),编译器会报错,提醒你该接口不是函数式接口。所以,从某种意义上来说,只要你保证你的接口中只有一个抽象方法,你可以不加这个注解。加上就会自动进行检测的。
Lambda表达式与函数式接口:
Lambda表达式是一种轻量级的匿名函数,它可以用于表示一个可传递的代码块。Lambda表达式与函数式接口密切相关,因为 Lambda表达式可以隐式地实现函数式接口中的抽象方法。
假设有如下的函数式接口定义:
@FunctionalInterface
interface MyFunctionalInterface {
void doSomething();
}我们可以使用Lambda表达式来实现它:
public class Main {
public static void main(String[] args) {
MyFunctionalInterface myLambda = () -> {
System.out.println("Doing something...");
};
myLambda.doSomething(); // 输出: Doing something...
}
}这里的Lambda表达式实际上是对函数式接口 MyFunctionalInterface 的实现。
综上:函数式接口是 Java 8 引入的一个概念,它是一种特殊类型的接口,其中只包含一个抽象方法。函数式接口的引入主要是为了支持 Lambda表达式,Lambda表达式是一种简洁的表示可传递匿名函数的方法。函数式接口和 Lambda表达式的结合,使得在Java中可以更方便地以函数式编程的方式来处理代码。使代码变得更加简洁、易读和易维护。
Lambda表达式的基本使用
首先,我们实现准备好几个接口:
import java.util.Comparator;
import java.util.PriorityQueue;
//无返回值无参数
//加上如下语句,可以帮我们校验当前接口是否有问题
@FunctionalInterface
interface NoParameterNoReturn {
void test();
}
//无返回值一个参数
@FunctionalInterface
interface OneParameterNoReturn {
void test(int a);
}
//无返回值多个参数
@FunctionalInterface
interface MoreParameterNoReturn {
void test(int a,int b);
}
//有返回值无参数
@FunctionalInterface
interface NoParameterReturn {
int test();
}
//有返回值一个参数
@FunctionalInterface
interface OneParameterReturn {
int test(int a);
}
//有返回值多参数
@FunctionalInterface
interface MoreParameterReturn {
int test(int a,int b);
}我们在上面提到过,Lambda可以理解为匿名内部类的简化,实际上是创建了一个类,实现了接 口,重写了接口的方法 。
这里我们不得不先给出 Lambda表达式的语法精简 :
您提到的这些是Lambda表达式的简化写法规则,它们使得Lambda表达式更加简洁和易读。下面我会一一解释这些规则:
1. 参数类型可以省略,如果需要省略,每个参数的类型都要省略。
Lambda表达式的语法允许我们省略参数的类型,编译器会根据上下文来自动推断参数的类型。但是,如果要省略参数类型,那么所有参数的类型都需要省略,不能只省略部分参数的类型。
// 完整写法
(int a, int b) -> System.out.println(a + b);
// 参数类型省略写法
(a, b) -> System.out.println(a + b);
2. 参数的小括号里面只有一个参数,那么小括号可以省略。
当Lambda表达式只有一个参数时,可以省略参数的小括号。但是,如果没有参数或者有多个参数,就不能省略小括号。
// 完整写法
(int a) -> System.out.println(a);
// 参数小括号省略写法
a -> System.out.println(a);
3. 如果方法体当中只有一句代码,那么大括号可以省略。
当Lambda表达式的方法体只有一句代码时,可以省略大括号。如果方法体有多于一句的代码,就不能省略大括号。
// 完整写法
(a, b) -> {
int sum = a + b;
System.out.println(sum);
}
// 大括号省略写法
(a, b) -> System.out.println(a + b);
4. 如果方法体中只有一条语句,且是return语句,那么大括号可以省略,且去掉return关键字。
当Lambda表达式的方法体只有一条语句且是return语句时,可以省略大括号,并且去掉return关键字。这是因为Lambda表达式会自动返回该语句的结果。
// 完整写法
(a, b) -> {
return a + b;
}
// 大括号和return关键字省略写法
(a, b) -> a + b;需要注意的是,Lambda表达式的简化写法并不是必须的,而是为了让代码更加简洁和易读。在使用Lambda表达式时,可以根据实际情况选择是否使用这些简化写法,以提高代码的可读性和可维护性。
首先来看一下无参数无返回值的情况:
public static void main(String[] args) {
//代表有一个类实现了这个接口,并重写了里面的方法——匿名内部类
NoParameterNoReturn noParameterNoReturn = new NoParameterNoReturn() {
@Override
public void test() {
System.out.println("test.....");
}
};
noParameterNoReturn.test();
}这一部分用Lambda表达式表示就变成:
public static void main(String[] args) {
NoParameterNoReturn noParameterNoReturn2 = ()->System.out.println("test.....");
noParameterNoReturn2.test();
}无参数有返回值:
public static void main3(String[] args) {
OneParameterNoReturn oneParameterNoReturn = (x) -> {
System.out.println(x);
};
oneParameterNoReturn.test(10);
}简化一下变成:
public static void main3(String[] args) {
OneParameterNoReturn oneParameterNoReturn = x -> System.out.println(x);
oneParameterNoReturn.test(10);
}无返回值有多个参数:
public static void main3(String[] args) {
MoreParameterNoReturn moreParameterNoReturn = (int x,int y) -> {
System.out.println(x+y);
};
moreParameterNoReturn.test(10,20);
}简化一下:
public static void main3(String[] args) {
MoreParameterNoReturn moreParameterNoReturn = (x,y) -> System.out.println(x+y);
moreParameterNoReturn.test(10,20);
}有返回值无参数:
public static void main(String[] args) {
NoParameterReturn noParameterReturn = ()->{return 10;};
System.out.println(noParameterReturn.test());
}简化一下:
public static void main(String[] args) {
NoParameterReturn noParameterReturn = ()-> 10;
System.out.println(noParameterReturn.test());
}有一个参数有返回值:
public static void main(String[] args) {
OneParameterReturn oneParameterReturn = a -> a;
System.out.println(oneParameterReturn.test(10));
}有多个参数有返回值:
public static void main(String[] args) {
MoreParameterReturn moreParameterReturn = (x,y)->{ return x+y };
System.out.println(moreParameterReturn.test(10, 20));
}变量捕获
Lambda 表达式中存在变量捕获 ,了解了变量捕获之后,我们才能更好的理解Lambda 表达式的作用域 。
Java当中的匿名类中,会存在变量捕获。
匿名内部类的变量捕获
匿名内部类就是没有名字的内部类 。我们这里只是为了说明变量捕获,所以,你只要会使用匿名内部类就好。
匿名内部类详解可以参考如下链接:匿名内部类详解 - SQP51312 - 博客园 (cnblogs.com)
那么,匿名内部类的变量捕获是什么呢?
匿名内部类的变量捕获是指在匿名内部类中访问外部类的局部变量或参数。当在匿名内部类中引用这些外部变量时,Java编译器会自动为其生成一个副本,这样匿名内部类就可以在其生命周期内持有这些变量的值。这种机制称为"捕获"。
让我们通过一个示例来详细了解匿名内部类的变量捕获:
你或许还记得,之前我们学习匿名内部类时发现无法修改原来已经给定了值的变量,否则会报错,不管是在匿名内部类中修改还是之后修改都不可以:
public class AnonymousInnerClassExample {
public void doSomething() {
int localVar = 42; // 局部变量
// 创建匿名内部类
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("Inside anonymous inner class: " + localVar);
}
};
// localVar = 100; // 修改局部变量的值,会报错
// 调用匿名内部类的run方法
runnable.run();
}
public static void main(String[] args) {
AnonymousInnerClassExample example = new AnonymousInnerClassExample();
example.doSomething();
}
}在上面的例子中,我们有一个外部类 AnonymousInnerClassExample ,它包含了一个方法 doSomething() ,在该方法中我们声明了一个局部变量 localVar 并赋值为42。然后,我们创建了一个匿名内部类,实现了 Runnable 接口,并在其中引用了外部类的局部变量 localVar 。
在匿名内部类中,我们访问了局部变量 localVar ,并在匿名内部类的 run() 方法中打印它的值。此时,Java编译器会自动为匿名内部类生成一个对 localVar 的副本。
运行这段代码,输出将会是:Inside anonymous inner class: 42
如果在匿名内部类后面修改局部变量的值,那么会有如下报错:

需要注意以下几点:
1. 匿名内部类可以访问外部类的局部变量,但是这些变量需要是 final 的,或者在实际上被隐式地标记为 final 。在 Java 8 之后,可以不显式地声明局部变量为 final ,但是一旦变量被赋值后就不能再修改它。
2. 一旦在匿名内部类中捕获了外部变量,匿名内部类就会持有该变量的一个副本。这意味着即使外部变量的值在匿名内部类创建后被修改,匿名内部类仍然保持着初始捕获时的值。
匿名内部类的变量捕获是一种方便的机制,允许我们在匿名内部类中使用外部类的局部变量,使得代码更加简洁和灵活。
class Test {
public void func(){
System.out.println("func()");
}
}
public class TestDemo {
public static void main(String[] args) {
int a = 100;
new Test(){
@Override
public void func() {
System.out.println("我是内部类,且重写了func这个方法!");
System.out.println("我捕获到变量 a == "+a
+" 我是一个常量,或者是一个没有改变过值的变量!");
}
};
}
}在上述代码当中的变量 a 就是捕获的变量。这个变量要么是被 final 修饰,如果不是被 final 修饰的 你要保证在使用之前,没有修改。如下代码就是错误的代码。
class Test {
public void func(){
System.out.println("func()");
}
}
public class TestDemo {
public static void main(String[] args) {
int a = 100;
new Test(){
@Override
public void func() {
a = 88;
System.out.println("我是内部类,且重写了func这个方法!");
System.out.println("我捕获到变量 a == "+a
+" 我是一个常量,或者是一个没有改变过值的变量!");
}
};
}
}Lambda的变量捕获
在Lambda当中也可以进行变量的捕获,因为它本身也是一个匿名内部类,具体我们看一下代码:
public static void main(String[] args) {
int a = 99;
MoreParameterReturn moreParameterReturn = (x,y)->{
//a = 9999;
System.out.println(a);
return x+y;
};
System.out.println(moreParameterReturn.test(10, 20));
}后期关于变量捕获问题,我们使用最多的地方是在线程。
Lambda在集合当中的使用
为了能够让Lambda和Java的集合类集更好的一起使用,集合当中,也新增了部分接口,以便与Lambda表达式对接。
为了能够让Lambda表达式和Java的集合类更好地配合使用,Java集合框架中引入了一些接口和方法。下面是新增的一些接口及其对应的方法:
1. Collection 接口:
- removeIf(Predicate filter): 根据给定的条件(Predicate)删除集合中满足条件的元素。
- spliterator(): 返回一个Spliterator,用于支持集合的并行遍历。
- stream(): 返回一个流(Stream),用于支持集合的函数式操作和Lambda表达式的使用。
- parallelStream(): 返回一个并行流(Parallel Stream),用于支持集合的并行处理。
- forEach(Consumer action): 对集合中的每个元素执行给定的操作(Consumer)
2. List 接口(继承自 Collection 接口):
- replaceAll(UnaryOperator
operator): 对集合中的每个元素应用给定的操作(UnaryOperator)进行替换。 - sort(Comparator c): 根据给定的比较器(Comparator)对集合进行排序。
3. Map 接口:
- getOrDefault(Object key, V defaultValue): 获取指定键的值,如果键不存在则返回默认值。
- forEach(BiConsumer action): 对Map中的每个键值对执行给定的操作(BiConsumer)。
- replaceAll(BiFunction function): 对Map中的每个键值对应用给定的操作(BiFunction)进行替换。
- putIfAbsent(K key, V value): 当键不存在时,将指定键值对存入Map。
- remove(Object key, Object value): 移除键值对,仅当键和值匹配时才移除。
- replace(K key, V value): 替换指定键的值。
- computeIfAbsent(K key, Function mappingFunction): 如果键不存在,则使用给定函数(Function)计算值并存入Map。
- computeIfPresent(K key, BiFunction remappingFunction): 如果键存在,则使用给定函数(BiFunction)计算新值并替换原来的值。
- compute(K key, BiFunction remappingFunction): 根据给定函数(BiFunction)计算新值并替换原来的值,或者在键不存在时存入Map。
- merge(K key, V value, BiFunction remappingFunction): 根据给定函数(BiFunction)合并新值和旧值,并存入Map。
这些接口和方法的引入使得集合类与Lambda表达式和函数式编程更加紧密结合,让我们能够更便捷地进行集合元素的筛选、处理和转换。
以上方法的作用你可以自己查看帮助手册。接下来我只会示例部分方法的使用。
注意:Collection的 forEach() 方法是从接口 java.lang.Iterable 拿过来的。
Collection接口:
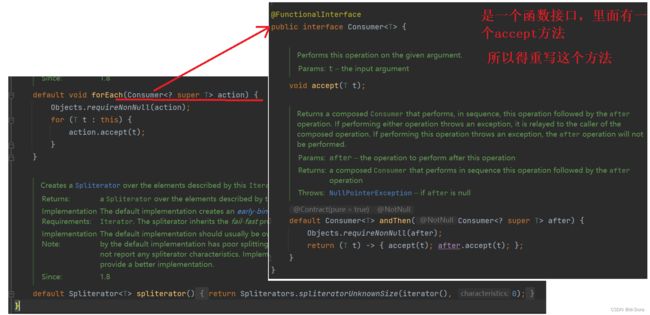
forEach() 方法演示:该方法表示:对容器中的每个元素执行action指定的动作 。forEach() 方法接受一个 Consumer 接口作为参数,它代表一个接收单个输入参数并且不返回结果的操作。在 forEach() 方法中,对集合中的每个元素都会调用一次 Consumer 的 accept() 方法,将该元素作为输入参数传递给 accept() 方法。
所以就得到:
public static void main1(String[] args) {
List list = new ArrayList<>();
list.add("hello");
list.add("abc");
list.add("zhangsan");
list.forEach(new Consumer() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
} 将如上代码直接改为Lambda表达式:
list.forEach(s -> System.out.println(s));List接口 :
sort()方法的演示:该方法根据c指定的比较规则对容器元素进行排序。
sort(Comparator c) 方法是 List 接口中的一个默认方法(default method),用于对列表中的元素进行排序。它接受一个比较器(Comparator)作为参数,用于指定排序规则。排序规则由比较器中的 compare() 方法定义。
比较器是一个函数式接口,它有一个抽象方法 int compare(T o1, T o2),用于比较两个对象 o1 和 o2 的顺序。根据比较结果,返回负整数表示 o1 小于 o2,返回正整数表示 o1 大于 o2,返回零表示 o1 等于 o2。
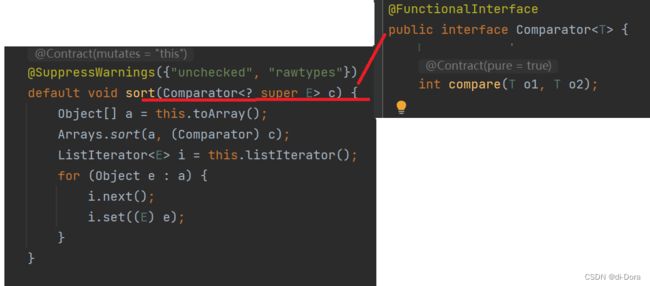
public static void main1(String[] args) {
list.sort(new Comparator() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
} 将如上代码直接改为Lambda表达式:
list.sort((o1, o2) -> o1.compareTo(o2));Map接口 :
HashMap 的 forEach(BiConsumer action) 方法是 Map 接口中的一个默认方法(default method),它用于对 Map 中的每个映射执行action指定的操作(BiConsumer)。
BiConsumer 是一个函数式接口,它有一个抽象方法 void accept(T t, U u),用于接受两个输入参数 t 和 u,并执行操作。
forEach() 方法的参数是一个 BiConsumer,它接受两个输入参数,分别为 Map 的键和值,我们在 lambda 表达式中定义了输出操作来打印键值对。通过该方法,我们可以方便地遍历 Map 并对每个键值对进行特定的操作。
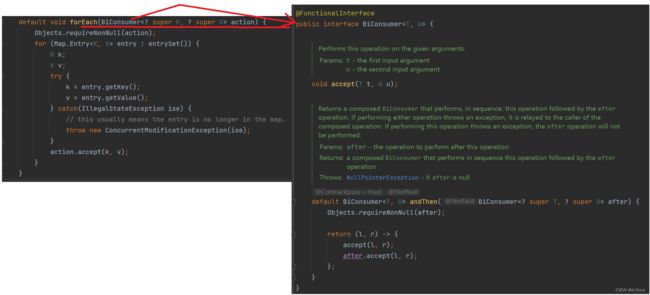
public static void main3(String[] args) {
Map map = new HashMap<>();
map.put("hello",13);
map.put("abc",3);
map.put("zhangsan",31);
map.forEach(new BiConsumer() {
@Override
public void accept(String s, Integer integer) {
System.out.println("key: "+s +" val: "+integer);
}
});
} 将如上代码直接改为Lambda表达式:
map.forEach((s, integer) -> System.out.println("key: "+s +" val: "+integer));Lambda表达式的优缺点
优点很明显,在代码层次上来说,使代码变得非常的简洁。缺点也很明显,代码不易读。
**优点**:
1. 代码简洁,开发迅速:Lambda表达式可以大幅减少冗余代码,使代码更加简洁,从而提高开发效率。它使得我们能够以更紧凑的方式编写匿名函数,无需显式地定义类和方法。
2. 方便函数式编程:Lambda表达式支持函数式编程范式,使Java可以像函数式编程语言一样处理函数作为一等公民。这样,我们可以将函数作为参数传递给方法,或者将函数作为方法的返回值。
3. 非常容易进行并行计算:Lambda表达式的函数式特性使得在并行计算上更为简单。它使得并行处理集合数据变得更容易,可以通过使用Stream API来自动进行并行处理,从而提高计算性能。
4. Java引入Lambda,改善了集合操作:Java集合框架引入了许多与 Lambda表达式一起使用的新方法,如 forEach() , removeIf() , stream() 等,使集合的操作更加便捷和灵活。
**缺点**:
1. 代码可读性变差:Lambda表达式的语法相对较新,如果滥用或过度使用,可能导致代码可读性变差。复杂的 Lambda表达式可能会难以理解,尤其对于不熟悉 Lambda的开发人员来说。
2. 在非并行计算中,很多计算未必有传统的for循环性能高:虽然Lambda表达式在并行计算中可以带来性能提升,但对于一些简单的循环计算,使用Lambda可能并不比传统的 for 循环性能更高。
3. 不容易进行调试:由于 Lambda表达式是匿名函数,当出现问题需要进行调试时,可能不太容易定位问题所在,特别是在复杂的 Lambda表达式中。
综上所述,Lambda表达式的优点在于代码简洁、方便函数式编程和并行计算等,可以提高开发效率和性能。然而,需要谨慎使用,以避免过度使用导致代码难以理解和调试困难的问题。在代码设计中,需要权衡使用Lambda表达式的场景,保持代码的可读性和维护性。