ENSO时间预测--构建预测ENSO的深度学习模型,预测未来1-24个月的Nino3.4指数
ENSO时间预测–构建预测ENSO的深度学习模型,预测未来1-24个月的Nino3.4指数
最近在看一篇关于ENSO预测的文章(Prediction of ENSO using multivariable deep learning),搜索相关材料时,发现在阿里云天池上有过相关的一个比赛(“AI Earth”人工智能创新挑战赛——AI助力精准气象和海洋预测),因此先学习了这个比赛的相关内容(包括代码的实现)
赛题简介
赛题背景
发生在热带太平洋上的厄尔尼诺-南方涛动(ENSO)现象是地球上最强、最显著的年际气候信号。通过大气或海洋遥相关过程,经常会引发洪涝、干旱、高温、雪灾等极端事件,对全球的天气、气候以及粮食产量具有重要的影响。准确预测ENSO,是提高东亚和全球气候预测水平和防灾减灾的关键。
本次赛题是一个时间序列预测问题。基于历史气候观测和模式模拟数据,利用T时刻过去12个月(包含T时刻)的时空序列(气象因子),构建预测ENSO的深度学习模型,预测未来1-24个月的Nino3.4指数,如下图所示:

数据描述
数据简介
本次比赛使用的数据包括CMIP5/6模式的历史模拟数据和美国SODA模式重建的近100多年历史观测同化数据。每个样本包含以下气象及时空变量:海表温度异常(SST),热含量异常(T300),纬向风异常(Ua),经向风异常(Va),数据维度为(year,month,lat,lon)。对于训练数据提供对应月份的Nino3.4 index标签数据。
训练数据说明
每个数据样本第一维度(year)表征数据所对应起始年份,对于CMIP数据共4645年,其中1-2265为CMIP6中15个模式提供的151年的历史模拟数据(总共:151年 15 个模式=2265);2266-4645为CMIP5中17个模式提供的140年的历史模拟数据(总共:140年 17 个模式=2380)。对于历史观测同化数据为美国提供的SODA数据。
其中每个样本第二维度(mouth)表征数据对应的月份,对于训练数据均为36,对应的从当前年份开始连续三年数据(从1月开始,共36月),比如:
SODA_train.nc中[0,0:36,:,:]为第1-第3年逐月的历史观测数据;
SODA_train.nc中[1,0:36,:,:]为第2-第4年逐月的历史观测数据; …, SODA_train.nc中[99,0:36,:,:]为第100-102年逐月的历史观测数据。
和 CMIP_train.nc中[0,0:36,:,:]为CMIP6第一个模式提供的第1-第3年逐月的历史模拟数据; …, CMIP_train.nc中[150,0:36,:,:]为CMIP6第一个模式提供的第151-第153年逐月的历史模拟数据;
CMIP_train.nc中[151,0:36,:,:]为CMIP6第二个模式提供的第1-第3年逐月的历史模拟数据; …, CMIP_train.nc中[2265,0:36,:,:]为CMIP5第一个模式提供的第1-第3年逐月的历史模拟数据; …, CMIP_train.nc中[2405,0:36,:,:]为CMIP5第二个模式提供的第1-第3年逐月的历史模拟数据; …, CMIP_train.nc中[4644,0:36,:,:]为CMIP5第17个模式提供的第140-第142年逐月的历史模拟数据。
其中每个样本第三、第四维度分别代表经纬度(南纬55度北纬60度,东经0360度),所有数据的经纬度范围相同。
训练数据标签说明
标签数据为Nino3.4 SST异常指数,数据维度为(year,month)。
CMIP(SODA)_train.nc对应的标签数据当前时刻Nino3.4 SST异常指数的三个月滑动平均值,因此数据维度与维度介绍同训练数据一致
注:三个月滑动平均值为当前月与未来两个月的平均值。
测试数据说明
测试用的初始场(输入)数据为国际多个海洋资料同化结果提供的随机抽取的n段12个时间序列,数据格式采用NPY格式保存,维度为(12,lat,lon, 4),12为t时刻及过去11个时刻,4为预测因子,并按照SST,T300,Ua,Va的顺序存放。
测试集文件序列的命名规则:test_编号起始月份_终止月份.npy,如test_00001_01_12.npy。
评估指标
评分细则说明: 根据所提供的n个测试数据,对模型进行测试,得到n组未来1-24个月的序列选取对应预测时效的n个数据与标签值进行计算相关系数和均方根误差,如下图所示。并计算得分。

其中:
![]()

数据转化工具
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
import matplotlib.pyplot as plt
import scipy
from netCDF4 import Dataset
import netCDF4 as nc
import gc
%matplotlib inline
数据读取
SODA_label处理
1.标签含义
- 标签数据为Nino3.4 SST异常指数,数据维度为(year,month)。
- CMIP(SODA)_train.nc对应的标签数据当前时刻Nino3.4 SST异常指数的三个月滑动平均值,因此数据维度与维度介绍同训练数据一致
注:三个月滑动平均值为当前月与未来两个月的平均值。
2.将标签转化为我们熟悉的pandas形式
label_path = 'D:/data/enso_data/SODA_label.nc'
label_trans_path = 'D:/data/enso_data/'
nc_label = nc.Dataset(label_path,'r')
#nc_label.variables.keys()
#nc_label.variables['month'][:]
years = np.array(nc_label['year'][:])
months = np.array(nc_label['month'][:])
year_month_index = []
vs = []
for i,year in enumerate(years):
for j,month in enumerate(months):
year_month_index.append('year_{}_month_{}'.format(year,month))
vs.append(np.array(nc_label['nino'][i,j]))#vs存储的是各个年月所对应的‘nino’标签值
year_month_index,vs
# np.array(nc_label['nino'][1,1])
df_SODA_label = pd.DataFrame({'year_month':year_month_index})
df_SODA_label['year_month'] = year_month_index
df_SODA_label['label'] = vs
df_SODA_label.to_csv(label_trans_path + 'df_SODA_label.csv',index = None)
df_SODA_label
转化
SODA_train处理
SODA_train.nc中[0,0:36,:,:]为第1-第3年逐月的历史观测数据;
SODA_train.nc中[1,0:36,:,:]为第2-第4年逐月的历史观测数据;
…,
SODA_train.nc中[99,0:36,:,:]为第100-102年逐月的历史观测数据。
SODA_path = 'D:/data/enso_data/SODA_train.nc'
nc_SODA = Dataset(SODA_path,'r')
#自定义抽取对应数据&转化为df的形式;index为年月; columns为lat和lon的组合
def trans_df(df, vals, lats, lons, years, months):
'''
(100, 36, 24, 72) -- year, month,lat,lon --数据维度(年,月,经度,维度)
'''
for j,lat_ in enumerate(lats):
for i,lon_ in enumerate(lons):
c = 'lat_lon_{}_{}'.format(int(lat_),int(lon_))
v = []
for y in range(len(years)):
for m in range(len(months)):
v.append(vals[y,m,j,i])
df[c] = v
return df
year_month_index = []
years = np.array(nc_SODA['year'][:])
months = np.array(nc_SODA['month'][:])
lats = np.array(nc_SODA['lat'][:])
lons = np.array(nc_SODA['lon'][:])
for year in years:
for month in months:
year_month_index.append('year_{}_month_{}'.format(year,month))
year_month_index
df_sst = pd.DataFrame({'year_month':year_month_index})
df_t300 = pd.DataFrame({'year_month':year_month_index})
df_ua = pd.DataFrame({'year_month':year_month_index})
df_va = pd.DataFrame({'year_month':year_month_index})
%%time
df_sst = trans_df(df = df_sst, vals = np.array(nc_SODA['sst'][:]), lats = lats, lons = lons, years = years, months = months)
df_t300 = trans_df(df = df_t300, vals = np.array(nc_SODA['t300'][:]), lats = lats, lons = lons, years = years, months = months)
df_ua = trans_df(df = df_ua, vals = np.array(nc_SODA['ua'][:]), lats = lats, lons = lons, years = years, months = months)
df_va = trans_df(df = df_va, vals = np.array(nc_SODA['va'][:]), lats = lats, lons = lons, years = years, months = months)
其中%%time是计算整个单元格运行所花费的时间
label_trans_path = 'D:/data/enso_data/'
df_sst.to_csv(label_trans_path + 'df_sst_SODA.csv',index = None)
df_t300.to_csv(label_trans_path + 'df_t300_SODA.csv',index = None)
df_ua.to_csv(label_trans_path + 'df_ua_SODA.csv',index = None)
df_va.to_csv(label_trans_path + 'df_va_SODA.csv',index = None)
CMIP_label处理
label_path = 'D:/data/enso_data/CMIP_label.nc'
label_trans_path = 'D:/data/enso_data/'
nc_label = Dataset(label_path,'r')
years = np.array(nc_label['year'][:])
months = np.array(nc_label['month'][:])
year_month_index = []
vs = []
for i,year in enumerate(years):
for j,month in enumerate(months):
year_month_index.append('year_{}_month_{}'.format(year,month))
vs.append(np.array(nc_label['nino'][i,j]))
df_CMIP_label = pd.DataFrame({'year_month':year_month_index})
df_CMIP_label['year_month'] = year_month_index
df_CMIP_label['label'] = vs
df_CMIP_label.to_csv(label_trans_path + 'df_CMIP_label.csv',index = None)#转化为csv格式并存储
df_CMIP_label的结果如下:
CMIP_train处理
CMIP_train.nc中[0,0:36,:,:]为CMIP6第一个模式提供的第1-第3年逐月的历史模拟数据;
…,
CMIP_train.nc中[150,0:36,:,:]为CMIP6第一个模式提供的第151-第153年逐月的历史模拟数据;
CMIP_train.nc中[151,0:36,:,:]为CMIP6第二个模式提供的第1-第3年逐月的历史模拟数据;
…,
CMIP_train.nc中[2265,0:36,:,:]为CMIP5第一个模式提供的第1-第3年逐月的历史模拟数据;
…,
CMIP_train.nc中[2405,0:36,:,:]为CMIP5第二个模式提供的第1-第3年逐月的历史模拟数据;
…,
CMIP_train.nc中[4644,0:36,:,:]为CMIP5第17个模式提供的第140-第142年逐月的历史模拟数据。
其中每个样本第三、第四维度分别代表经纬度(南纬55度北纬60度,东经0360度),所有数据的经纬度范围相同。
CMIP_path = 'D:/data/enso_data/CMIP_train.nc'
CMIP_trans_path = 'D:/data/enso_data/'
nc_CMIP = Dataset(CMIP_path,'r')
nc_CMIP[‘ua’][:].shape为(4645, 36, 24, 72)
year_month_index = []
years = np.array(nc_CMIP['year'][:])
months = np.array(nc_CMIP['month'][:])
lats = np.array(nc_CMIP['lat'][:])
lons = np.array(nc_CMIP['lon'][:])
last_thre_years = 1000
for year in years:
'''
数据的原因,我们
'''
if year >= 4645 - last_thre_years:
for month in months:
year_month_index.append('year_{}_month_{}'.format(year,month))
df_CMIP_sst = pd.DataFrame({'year_month':year_month_index})
df_CMIP_t300 = pd.DataFrame({'year_month':year_month_index})
df_CMIP_ua = pd.DataFrame({'year_month':year_month_index})
df_CMIP_va = pd.DataFrame({'year_month':year_month_index})
df_CMIP_sst的结果:
def trans_thre_df(df, vals, lats, lons, years, months, last_thre_years = 1000):
'''
(4645, 36, 24, 72) -- year, month,lat,lon
'''
for j,lat_ in (enumerate(lats)):
# print(j)
for i,lon_ in enumerate(lons):
c = 'lat_lon_{}_{}'.format(int(lat_),int(lon_))
v = []
for y_,y in enumerate(years):
'''
数据太大
'''
if y >= 4645 - last_thre_years:
for m_,m in enumerate(months):
v.append(vals[y_,m_,j,i])
df[c] = v
return df
%%time
df_CMIP_sst = trans_thre_df(df = df_CMIP_sst, vals = np.array(nc_CMIP['sst'][:]), lats = lats, lons = lons, years = years, months = months)
df_CMIP_sst.to_csv(CMIP_trans_path + 'df_CMIP_sst.csv',index = None)
del df_CMIP_sst
gc.collect()#强制对代码进行垃圾回收
df_CMIP_t300 = trans_thre_df(df = df_CMIP_t300, vals = np.array(nc_CMIP['t300'][:]), lats = lats, lons = lons, years = years, months = months)
df_CMIP_t300.to_csv(CMIP_trans_path + 'df_CMIP_t300.csv',index = None)
del df_CMIP_t300
gc.collect()
df_CMIP_ua = trans_thre_df(df = df_CMIP_ua, vals = np.array(nc_CMIP['ua'][:]), lats = lats, lons = lons, years = years, months = months)
df_CMIP_ua.to_csv(CMIP_trans_path + 'df_CMIP_ua.csv',index = None)
del df_CMIP_ua
gc.collect()
df_CMIP_va = trans_thre_df(df = df_CMIP_va, vals = np.array(nc_CMIP['va'][:]), lats = lats, lons = lons, years = years, months = months)
df_CMIP_va.to_csv(CMIP_trans_path + 'df_CMIP_va.csv',index = None)
del df_CMIP_va
gc.collect()
数据建模
工具包导入&数据处理
工具包导入
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.optimizers import Adam
import joblib
from netCDF4 import Dataset
import netCDF4 as nc
import gc
from sklearn.metrics import mean_squared_error
import numpy as np
from tensorflow.keras.callbacks import LearningRateScheduler, Callback
import tensorflow.keras.backend as K
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from tensorflow.keras.optimizers import *
from tensorflow.keras.callbacks import *
from tensorflow.keras.layers import Input
%matplotlib inline
数据读取
SODA_label处理
前面已经叙述过就不多做阐述,将转化成csv格式的数据读取进去:
df_SODA_label = pd.read_csv('D:/data/enso_data/df_SODA_label.csv')
df_CMIP_label = pd.read_csv('D:/data/enso_data/df_CMIP_label.csv')
训练集验证集构建
df_SODA_label['year'] = df_SODA_label['year_month'].apply(lambda x: x[:x.find('m') - 1])
df_SODA_label['month'] = df_SODA_label['year_month'].apply(lambda x: x[x.find('m') :])
df_train = pd.pivot_table(data = df_SODA_label, values = 'label',index = 'year', columns = 'month')#做成一个交互表
year_new_index = ['year_{}'.format(i+1) for i in range(df_train.shape[0])]
month_new_columns = ['month_{}'.format(i+1) for i in range(df_train.shape[1])]
df_train = df_train[month_new_columns].loc[year_new_index]
df_train结果为:
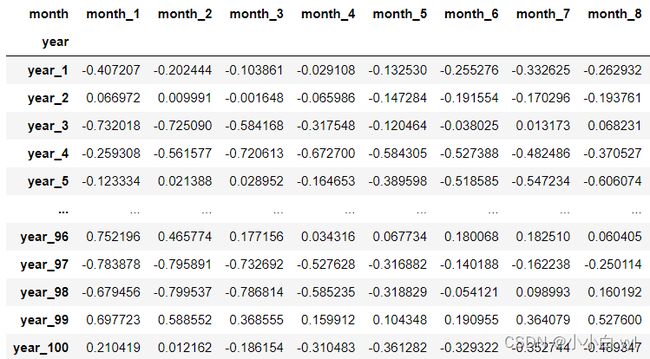
100 rows × 36 columns
模型构建
MLP框架
def RMSE(y_true, y_pred):
return tf.sqrt(tf.reduce_mean(tf.square(y_true - y_pred)))
def RMSE_fn(y_true, y_pred):
return np.sqrt(np.mean(np.power(np.array(y_true, float).reshape(-1, 1) - np.array(y_pred, float).reshape(-1, 1), 2)))
# .reshape(-1, 1) 表示任意行任意列
# np.power(x1,x2),表示x1的x2次方
def build_model(train_feat, test_feat): #allfeatures,
inp = Input(shape=(len(train_feat)))
x = Dense(1024, activation='relu')(inp) #全连接层
x = Dropout(0.25)(x) #随机删掉一定比例的神经元,让它们不发挥传递作用,使网络模型变得稀疏的一种模型方法。
x = Dense(512, activation='relu')(x)
x = Dropout(0.25)(x)
output = Dense(len(test_feat), activation='linear')(x)
model = Model(inputs=inp, outputs=output)
adam = tf.optimizers.Adam(lr=1e-3,beta_1=0.99,beta_2 = 0.99)
model.compile(optimizer=adam, loss=RMSE)
return model
模型训练
feature_cols = ['month_{}'.format(i+1) for i in range(12)]
label_cols = ['month_{}'.format(i+1) for i in range(12, df_train.shape[1])]
# df_train.shape[1]#列的维度
# feature_cols是month1-month12,label_cols是month13-month36
model_mlp = build_model(feature_cols, label_cols)
model_mlp.summary()
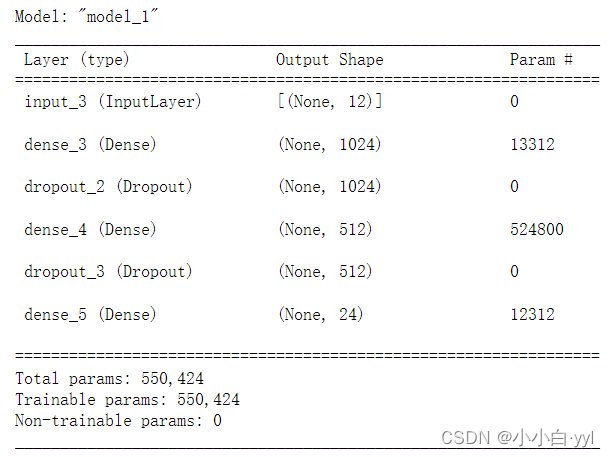
输出结果解释:
- 首先,输入层将外部长度传入进去,故没有参数,而传进去的Input(shape=(len(train_feat))) 维度为12,故此时数据通过该层后数据维度为(None,12)
- 框架中的第二层dense(Dense),输入维度为12,而经过了1024个神经元,因此参数个数为(12+1)*1024=13312;经过1024个神经元的作用输出维度即1024
- dropout (Dropout)是抑制过拟合的一种方法,原来维度保持不变,无参数。
- dense_1 (Dense),输入维度为1024,经过512个神经元,因此参数个数为(1024+1)*512=524800;经过512个神经元的作用输出维度即512
- dropout_1 (Dropout)同上
- dense_2 (Dense),输入维度为512,经过len(test_feat)=24个神经元,因此参数个数为(512+1)*24=12312;经过24个神经元的作用输出维度即24
tr_len = int(df_train.shape[0] * 0.8)# 100*0.8
tr_fea = df_train[feature_cols].iloc[:tr_len,:].copy()#取df_train中前80行12列
tr_label = df_train[label_cols].iloc[:tr_len,:].copy()
val_fea = df_train[feature_cols].iloc[tr_len:,:].copy()
val_label = df_train[label_cols].iloc[tr_len:,:].copy()
model_weights = 'D:/data/enso_data/model_mlp_baseline.h5'
checkpoint = ModelCheckpoint(model_weights, monitor='val_loss', verbose=0, save_best_only=True, mode='min',
save_weights_only=True)
"""
model_weights:保存模型文件的路径;monitor要监控指标的名称,使用 “loss” 或 “val_loss” 以监控模型的总损失;
verbose:当verbose=0时,简单说就是不输出日志信息 ,进度条、loss、acc这些都不输出;当verbose=1时,带进度条的输出日志信息
当verbose=2时,为每个epoch输出一行记录,和1的区别就是没有进度条
save_best_only=True 只在模型被认为是目前最好时保存;
model:如果 save_best_only=True,则根据监视指标的最大化或最小化来决定是否覆盖保存文件。对 val_acc 应为 max,
对 val_loss 应为 min。在 auto 模式,如果监控的指标为 acc 或以 ‘fmeasure’ 开头,则模式为 max,对余下的则为 min。
save_weights_only=True 表示只保存模型的权重.
"""
# ReduceLROnPlateau,回调函数,在训练过程中修改学习率来提升模型
plateau = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=5, verbose=1, min_delta=1e-4, mode='min')
early_stopping = EarlyStopping(monitor="val_loss", patience=20)#patience:能够容忍多少个epoch内都没有improvement
history = model_mlp.fit(tr_fea.values, tr_label.values,
validation_data=(val_fea.values, val_label.values),
batch_size=4096, epochs=200,
callbacks=[plateau, checkpoint, early_stopping],
verbose=2)
Metrics
def rmse(y_true, y_preds):
return np.sqrt(mean_squared_error(y_pred = y_preds, y_true = y_true))
def score(y_true, y_preds):
accskill_score = 0
rmse_score = 0
a = [1.5] * 4 + [2] * 7 + [3] * 7 + [4] * 6
y_true_mean = np.mean(y_true,axis=0)
y_pred_mean = np.mean(y_preds,axis=0)
for i in range(24):
fenzi = np.sum((y_true[:,i] - y_true_mean[i]) *(y_preds[:,i] - y_pred_mean[i]) )
fenmu = np.sqrt(np.sum((y_true[:,i] - y_true_mean[i])**2) * np.sum((y_preds[:,i] - y_pred_mean[i])**2) )
cor_i= fenzi / fenmu
accskill_score += a[i] * np.log(i+1) * cor_i
rmse_score += rmse(y_true[:,i], y_preds[:,i])
return 2 / 3.0 * accskill_score - rmse_score
y_val_preds = model_mlp.predict(val_fea.values, batch_size=1024)
print('score', score(y_true = val_label.values, y_preds = y_val_preds))
最终得到的分数为21.9333
模型预测
模型构建
在上面的部分,我们已经训练好了模型,接下来就是提交模型并在线上进行预测,这块可以分为三步:
- 导入模型;
- 读取测试数据并且进行预测;
- 生成提交所需的版本;
import tensorflow as tf
import tensorflow.keras.backend as K
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from tensorflow.keras.optimizers import *
from tensorflow.keras.callbacks import *
from tensorflow.keras.layers import Input
import numpy as np
import os
import zipfile
def RMSE(y_true, y_pred):
return tf.sqrt(tf.reduce_mean(tf.square(y_true - y_pred)))
def build_model(train_feat, test_feat): #allfeatures,
inp = Input(shape=(len(train_feat)))
x = Dense(1024, activation='relu')(inp)
x = Dropout(0.25)(x)
x = Dense(512, activation='relu')(x)
x = Dropout(0.25)(x)
output = Dense(len(test_feat), activation='linear')(x)
model = Model(inputs=inp, outputs=output)
adam = tf.optimizers.Adam(lr=1e-3,beta_1=0.99,beta_2 = 0.99)
model.compile(optimizer=adam, loss=RMSE)
return model
feature_cols = ['month_{}'.format(i+1) for i in range(12)]
label_cols = ['month_{}'.format(i+1) for i in range(12, 36)]
model = build_model(train_feat=feature_cols, test_feat=label_cols)
model.load_weights('D:/data/enso_data/model_mlp_baseline.h5')
模型预测
test_path = 'D:/data/enso_round1_test_20210201/'
### 0. 模拟线上的测试集合
# for i in range(10):
# x = np.random.random(12)
# np.save(test_path + "{}.npy".format(i+1),x)
### 1. 测试数据读取
files = os.listdir(test_path)
test_feas_dict = {}
for file in files:
test_feas_dict[file] = np.load(test_path + file)
### 2. 结果预测
test_predicts_dict = {}
for file_name,val in test_feas_dict.items():
test_predicts_dict[file_name] = model.predict(val.reshape([-1,12]))
# test_predicts_dict[file_name] = model.predict(val.reshape([-1,12])[0,:])
### 3.存储预测结果
for file_name,val in test_predicts_dict.items():
np.save('D:/data/result/' + file_name,val)
打包run.sh目录下方
#打包目录为zip文件
def make_zip(source_dir='./result/', output_filename = 'result.zip'):
zipf = zipfile.ZipFile(output_filename, 'w')
pre_len = len(os.path.dirname(source_dir))
source_dirs = os.walk(source_dir)
print(source_dirs)
for parent, dirnames, filenames in source_dirs:
print(parent, dirnames)
for filename in filenames:
if '.npy' not in filename:
continue
pathfile = os.path.join(parent, filename)
arcname = pathfile[pre_len:].strip(os.path.sep) #相对路径
zipf.write(pathfile, arcname)
zipf.close()
# make_zip()
该项目所用到的数据集
参考代码
比赛地址