博客系统项目
文章目录
-
- 数据库的增删改查
- 草稿箱
- 草稿箱自动保存
- 分页查询
-
- 后端
- 前端
- 评论区
-
- 后端
- 前端
- md5加盐加密
md5加盐对用户密码进行加密;
全服用户博客列表页,实现分页查询;
用户博客列表页;
写博客,发博客,改博客;
博客草稿箱,自动保存,定时发布;
博客访问量,博客评论区,博客点赞;
数据库的增删改查
提示:这里可以添加技术整体架构
这个项目的功能几乎就是数据库的增删改查,但是在具体的实现细节上有一些需要注意的地方.
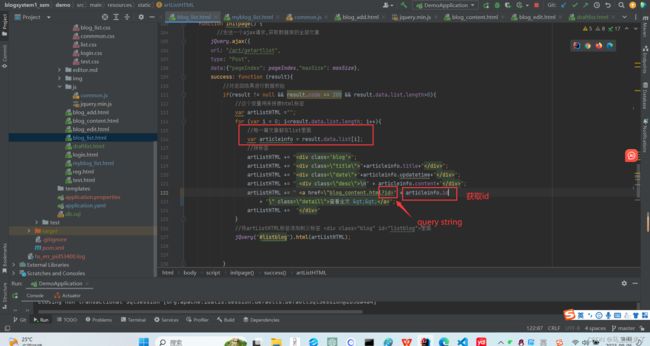
全服用户博客列表页会发送一个ajax异步请求直接查询到articleinfo表里已经发布的文章.
注意我这里使用state字段来定义文章的状态,state=1表示文章已经成功发布 ,state=0表示文章保存在草稿箱里.
为了能够更加便捷的从数据库里查询到文章,在url的query string里拼接上每篇文章的唯一标识id,这样点击标签跳转页面时时,可以直接给服务器发送一个get请求直接从数据库里根据id查询到文章并返回给前端,修改博客,查看博客详情,删除博客都要用到这个id.
在全服用户博客列表页上,将服务器传来的数据动态的拼接到html标签上:
function initpage() {
//发送一个ajax请求,获取数据库的全部文章
jQuery.ajax({
url: "/art/getartlist",
type: "Post",
data:{"pageIndex": pageIndex,"maxSize": maxSize},
success: function (result){
//对返回结果进行数据校验
if(result != null && result.code == 200 && result.data.list.length>0){
//这个变量用来拼接html标签
var artListHTML ="";
for (var i = 0; i<result.data.list.length; i++){
//每一篇文章都在list里面
var articleinfo = result.data.list[i];
//拼标签
artListHTML += "";
artListHTML += ""+articleinfo.title+"";
artListHTML += ""+articleinfo.updatetime+"";
artListHTML += " \n" + articleinfo.content+"";
artListHTML += " + articleinfo.id
+ "\" class=\"detail\">查看全文 >>";
artListHTML += ""
}
//将artListHTML标签添加到父标签 里面
jQuery("#listblog").html(artListHTML);
}
//获取最大页数
maxPage = result.data.finalMaxPage;
}
})
}
initpage();
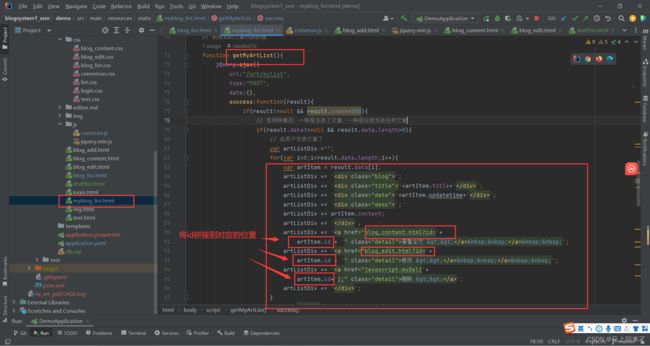
个人列表页同样也是如此:
“查看全文”,“修改”,"删除"都是点击之后跳转url对应的页面,然后发送ajax请求给后端,通过文章id来在数据库里查询/删除id唯一指向的文章
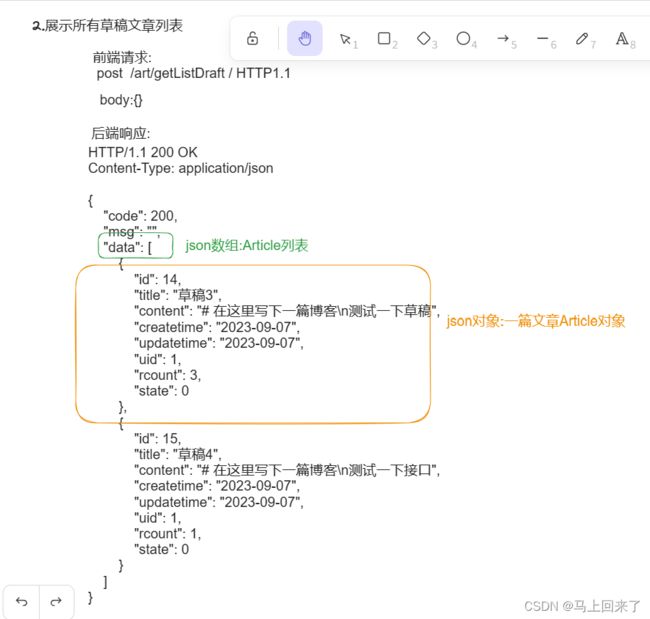
草稿箱

草稿箱里的文章state=0,正式发布的文章state=1

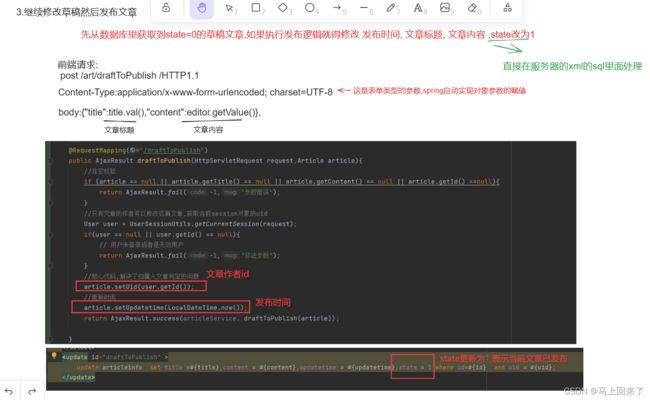
响应:
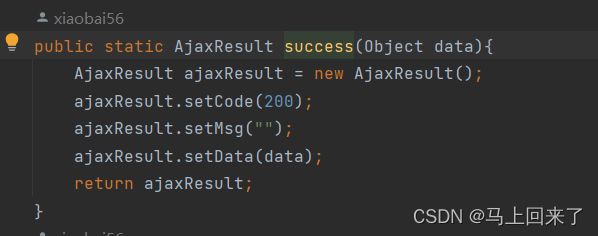
草稿箱自动保存
自动保存功能主要逻辑集中在前端,我开发这个功能的初心是用户在对于草稿箱里内容可能会忘记保存然后退出去了,这次的修改就作废了。
自动保存本质也只是在页面关闭时,给服务发送ajax请求,修改数据库里id对应的标题和内容,id依然从url里面获取.
思路:
1、我先获取到前端页面的标题输入框和文本输入框,页面加载完成后先将标题输入框和文本输入框的内容存储到浏览器的 localStorage里面;
2、然后添加一个定时器和监听事件,每3s就监听一下标题输和文入框的内容是否和 localStorage里的不同,如果修改了,就又将最新的标题和内容存到 localStorage里,这样 localStorage里会保存最新的内容;
3、用户忘记点保存草稿关掉页面时,在检测到页面要关闭的时候,直接从 localStorage里读取到最新的内容通过ajax发送给服务器保存到数据库里面
4、设置了一个开关,let isManualSave = 0,当用户点击“保存草稿”时,isManualSave++,自动保存在触发前会先判断一下isManualSave的值,如果isManualSave = 0说明用户没有手动点击保存,触发自动保存功能,如果isManualSave !=0说明用户已经手动保存了,不用触发手动保存了;
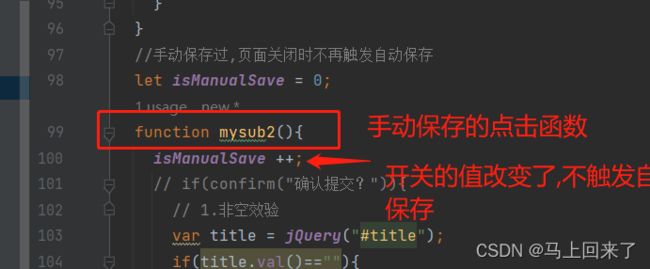
自动保存的代码:
<script>
// 博客数据对象,包括标题和内容
var blogData = {
title: "",
content: ""
};
// 获取标题输入框和内容输入框的 DOM 元素
var titleInput = document.getElementById("title");
var contentInput = document.getElementById("editor-markdown");
// 监听标题输入框的输入事件
titleInput.addEventListener("input", function() {
autoSave();
});
// 监听内容输入框的输入事件
contentInput.addEventListener("input", function() {
autoSave();
});
// 每隔3秒检查标题和内容是否改变,改变了就自动保存
setInterval(function() {
var latestTitle = titleInput.value;
var latestContent = contentInput.value;
if (latestTitle !== blogData.title || latestContent !== blogData.content) {
blogData.title = latestTitle;
blogData.content = latestContent;
autoSave();
}
console.log("调用了3s检测")
}, 3000);
// 自动保存函数
function autoSave() {
// 将博客数据保存到浏览器的本地存储
localStorage.setItem("draftBlog", JSON.stringify(blogData));
console.log("保存到本地了")
}
// 在用户离开页面前,将博客数据发送给服务器
window.addEventListener("beforeunload", function(event) {
console.log("页面关闭了")
var latestData = localStorage.getItem("draftBlog");
if (latestData) {
blogData = JSON.parse(latestData);
}
var lastTitle = blogData.title
var lastContent = blogData.content;
console.log(lastTitle);
console.log(lastContent)
draftid = getUrlValue("id");
if(isManualSave == 0){
// 2.进行修改操作
jQuery.ajax({
url:"/art/update",
type:"POST",
data:{"title":lastTitle,"content":lastContent,"id":draftid},
success:function(result){
console.log("Ajax request success:", result);
if(result!=null && result.code==200 && result.data==1){
// alert("恭喜:修改成功!");
// location.href = "myblog_list.html";
}else{
// alert("抱歉:操作失败,请重试!");
}
}
});
}
});
分页查询
后端
后端的话就是使用查询条数limit和偏移量offset来查询数据库,后端得根据前端传来的页码pageIndex和每页最大查询数maxSize来计算出偏移量:
当pageIndex是1的时候,分析可得此时的偏移量offset应该为0,这次查询时查出表里最开头的maxSize条数据;
当pageIndex是2的时候,分析可得此时的偏移量offset是在pageIndex=1查询了maxSize条数据之后的位置,也就是从offset=maxSize处往后在查maxSize条;
当pageIndex是3的时候,offset就得是从maxSize*2处完后查了
所以可以得offset是和maxSize有关系的
使用下面这个公式就可以计算出偏移量
int offset = (pageIndex-1)*maxSize;
后端查询出每页的数据之后,在计算一下每页查maxSize最多可以查多少页maxPage返回给前端
//先查询出数据库里面全部的文章数
int total = articleService.getCount();
//根据每页的最大展示数,计算出最大页数,没有整除就进一
double maxPage = total/(maxSize*1.0);
//向上取整
int finalMaxPage = (int)Math.ceil(maxPage);
后端将每页的maxSize文章数和最大页面数maxPage通过map结构返回给前端:
@RequestMapping("/getartlist")
public AjaxResult paging(Integer pageIndex,Integer maxSize){
//0.非空校验
if (pageIndex == null || maxSize== null){
return AjaxResult.fail(-1,"非法参数");
}
//根据pageIndex和maxSize计算出偏移量offset
int offset = (pageIndex-1)*maxSize;
//根据maxSize和offset可以查询出当前页面的数据
List<Article> list = articleService.paging(maxSize,offset);
/**
* 尾页处理
*/
//先查询出数据库里面全部的文章数
int total = articleService.getCount();
//根据每页的最大展示数,计算出最大页数,没有整除就进一
double maxPage = total/(maxSize*1.0);
//向上取整
int finalMaxPage = (int)Math.ceil(maxPage);
//使用map键值对,将每页的文章和最大页数返回给前端
Map<Object,Object> result = new HashMap<>();
result.put("list",list);
result.put("finalMaxPage",finalMaxPage);
return AjaxResult.success(200,result);
}
前端
前端定义三个变量:
//当前页的页码,以querystring的形式拼到url里面
var pageIndex =1;
//每页展示的数据条数
var maxSize = 2;
//最大页数
var maxPage = 1;
页码pageInex在点击下一页和上一页按钮时拼接到url里上
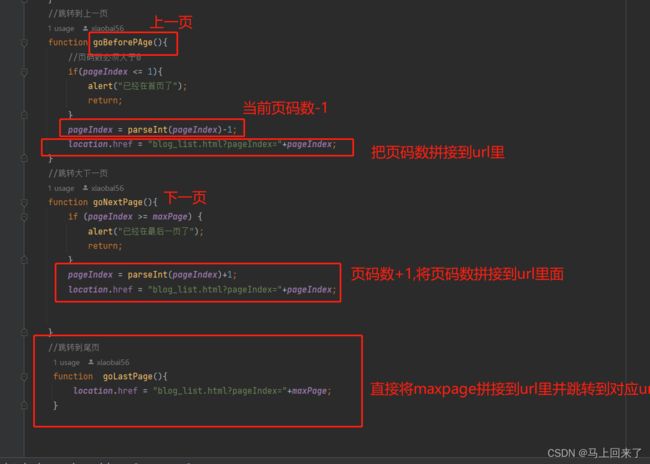
initpage()函数根据pageIndex和maxSize直接给服务器发送ajax请求,前端接收每页文章数maxSize和最大页码数maxPage
//当前页的页码,以querystring的形式拼到url里面
var pageIndex =1;
//每页展示的数据条数
var maxSize = 2;
//最大页数
var maxPage = 1;
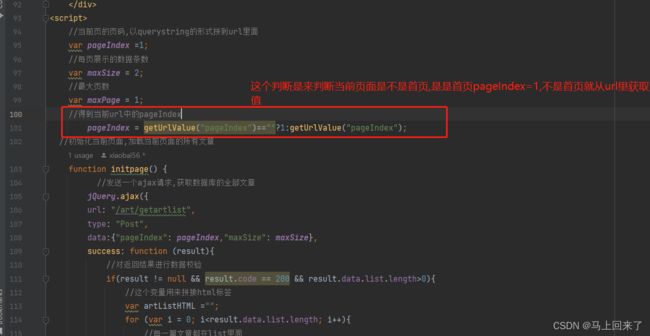
//得到当前url中的pageIndex
pageIndex = getUrlValue("pageIndex")==""?1:getUrlValue("pageIndex");
function initpage() {
//发送一个ajax请求,获取数据库的全部文章
jQuery.ajax({
url: "/art/getartlist",
type: "Post",
data:{"pageIndex": pageIndex,"maxSize": maxSize},
success: function (result){
//对返回结果进行数据校验
if(result != null && result.code == 200 && result.data.list.length>0){
//这个变量用来拼接html标签
var artListHTML ="";
for (var i = 0; i<result.data.list.length; i++){
//每一篇文章都在list里面
var articleinfo = result.data.list[i];
//拼标签
artListHTML += "";
artListHTML += ""+articleinfo.title+"";
artListHTML += ""+articleinfo.updatetime+"";
artListHTML += " \n" + articleinfo.content+"";
artListHTML += " + articleinfo.id
+ "\" class=\"detail\">查看全文 >>";
artListHTML += ""
}
//将artListHTML标签添加到父标签 里面
jQuery("#listblog").html(artListHTML);
}
//获取最大页数
maxPage = result.data.finalMaxPage;
}
})
}
initpage();
首页的url里面没有pageIndex
对于首页的处理
评论区
后端
评论区分有两点关键实现:
一、多级评论,一级和二级评论
二、回复评论
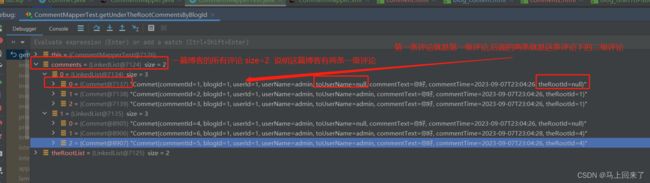
服务器这边的实现:创建一张表,表名为comments,字段看下面的图片。

其中我用toUserName和theRootId这个字段来控制一级评论和二级评论,一条一级评论的特点是没有toUserName为nul,theRootId也为null,前端标签里只需要获取到该条评论的userName、commentTime和commentText然后打印出来就行;二级评论需要知道toUserName该条评论回复谁,theRootId该条评论是哪条一级评论下的二级评论。

在数据库里查询所有评论时:
1、先将theRootId=null的所有一级评论查询出来放到一张链表里theRootList;
2、然后遍历这个链表,获取每个一级评论的commentId,然后使用where theRootId=commentId(一级评论的id)将所有的二级评论查询出来放到一个链表里list,然后使用头插法将一级评论插入到二级评论里;
3、list链表就包含了一级评论和一级评论下的所有二级评论,在将list链表添加到comments链表里面,comments是链表嵌套链表的结构,comments表示每篇博客的所有评论,comments每一个元素list就表示一条一级评论和所有的二级评论;
@Test
void getUnderTheRootCommentsByBlogId() {
//用来装一篇博客的所有评论
LinkedList<LinkedList<Commet>> comments = new LinkedList<>();
//获得所有的一级评论
LinkedList<Commet> theRootList = commentMapper.getTheRootCommentsByBlogId();
for (int i = 0; i < theRootList.size(); i++) {
//获得一级评论的commentId
int theRootId = theRootList.get(i).getCommentId();
//获得所有一级评论下的二级评论
LinkedList<Commet> list = commentMapper.getUnderTheRootCommentsByBlogId(theRootId);
/**
* 二级评论和一级评论合并
*/
//将一级评论放在头插在的第一个位置,二级评list为空,直接插入一级评论就不为空了
Commet commet = theRootList.get(i);
list.addFirst(commet);
comments.add(list);
}
System.out.println(comments);
}
前端
前端的实现,思路:

md5加盐加密
MD5是一种信息摘要算法,是一种单向的哈希函数,将一串字符经过一系列的按位与,按位异或等运算生成固定长度128比特的散列值,这些运算的过程就造成了信息的缺失,因此不可逆。
如果直接只对明文进行md5运算得到散列值的话是不安全,任何一个密码串都对应唯一一个md5的值(工程上来说),如果密码长度是固定的,那么可以搞一个表.将密码所有组合的MD5的值全部列出,然后拿着表里的md5的值去和某个密码的MD5的值去比较,如果相等在就能找到MD5匹配的明文密码,这就是暴力破解的过程.有个彩虹表就可以做到这样的暴力破解。
加长密码的长度,可以有效的提高暴力破解的难度代价就越高,密码越长,彩虹表的量级就非常大,想象65位长度的密码的所有组合有多少种。
因此采用明文+盐方式将密码变长!!!
加密过程:
使用UUID.randomUUID()生成的唯一的随机值当做盐值salt,用明文和盐值salt拼接然后生成MD5散列值md5Password,然后拼接ciphertext = salt+$+md5Password存储到数据库里,如果你想暴力破解ciphertext那就代价很高了,这是65位的字符串,你单单破解唯一的32位salt你都得付出极大的代价.
解密过程:
由于md5不可逆,所以解密只能是拿着明文和盐值在进行一次相同加密操作,来看最后得到的ciphertext是否和数据库里存储的ciphertext一样,如果一样就说明密码正确,如果不一样就说明密码错误.
加密过程:
/**
* 对明文进行加密,产生盐值
* @param password
* @return存储到数据库里面
*/
public static String encrypt(String password){
//1.产生盐值
String salt = UUID.randomUUID().toString().replace("-","");
//2.明文和盐值进行md5加密
String md5Password = DigestUtils.md5DigestAsHex((password+salt).getBytes());
//3.拼接:盐值+$+密文
String ciphertext = salt+"$"+md5Password;
return ciphertext;
}
解密过程:
先获取到数据库里的ciphertext,然后把$前面的盐值拿出来进和密码进行加密
/**
*
* @param inputPassword 用户输入的密码
* @param finalPassword 数据库保存的最终密码
* @return
*/
public static Boolean check(String inputPassword,String finalPassword){
//0.非空校验
if(!StringUtils.hasLength(inputPassword) || !StringUtils.hasLength(finalPassword) || finalPassword.length()!=65){
return false;
}
//1.从数据库的密码里面获取盐值
String salt = finalPassword.split("\\$")[0];
//2.输入的明文密码和盐值进行md5加密
String ciphertext = encrypt(inputPassword,salt);
//3.判断是否相等
if(ciphertext.equals(finalPassword)){
return true;
}
return false;
}
/**
*不产生盐值, 用与校验密码
* @param password 前端传过来
* @param salt 从数据库里获取
* @return
*/
public static String encrypt(String password,String salt){
//0.非空检验
if(!StringUtils.hasLength(password) || !StringUtils.hasLength(salt)){
return null;
}
//1.加密
String md5Password = DigestUtils.md5DigestAsHex((password+salt).getBytes());
//2.盐值+$+密文 32位盐值+1位$+32位md5的值 =65位
String ciphertext = salt+"$"+md5Password;
return ciphertext;
}