"Deep Facial Expression Recognition: A Survey"论文笔记
introduction
- FER systems can be divided into two main categories according to the feature representations: static image FER and dynamic sequence FER. (时空信息)
- The majority of the traditional methods have used handcrafted features or shallow learning (e.g., local binary patterns (LBP) [12], LBP on three orthogonal planes (LBP-TOP) [15], non-negative matrix factorization (NMF) [19] and sparse learning [20]) for FER.
However, many competitions have collected relatively sufficient training data from challenging real-world scenarios,in
the meanwhile, due to the dramatically increased chip processing abilities (e.g., GPU units) and well-designed network architecture, studies in various fields have begun to transfer to deep learning methods.
database

deep facial expression recognition
1.pre-processing
-
face alignment(detector and to coordinate localized landmarks)

- Kim et al. [76] considered different inputs (original image and histogram equalized image) and different face detection models (V&J [72] and MoT [56]), and the landmark set with the highest confidence provided by the Intraface [73] was selected.
-
data augmentation(enlarge database)
- Data augmentation techniques can be divided into two groups: on-the-fly data augmentation and offline data
augmentation. - Usually, the on-the-fly data augmentation is embedded in deep learning toolkits to alleviate overfitting. During the training step, the input samples are randomly cropped from the four corners and center of the image and then flipped horizontally.
- Besides the elementary on-the-fly data augmentation, various offline data augmentation operations have been designed to further expand data on both size and diversity. The most frequently used operations include random perturbations and transforms, e.g., rotation, shifting, skew, scaling, noise, contrast and color jittering. Furthermore, deep learning based technology can be applied for data augmentation. For example,CNN or GAN(generatie adversatial network).
-
face normalization(to ameliorate illumination and head pose)
- illumination normalization
a.sevearal algorithms:isotropic diffusion (IS)-based normalization, discrete cosine transform (DCT)-based normalization [85] and difference of Gaussian (DoG)
b.homomorphic filtering based normalization & histogram equalization combined with illumination normalization etc.
c.weighted summation approach to combine histogram equalization and linear mapping ( to solve overemphasizing local contrast problem)
d.global equalization(GCN), local normalization and histogram equalization.
- pose normalization
a.Specifically, after localizing facial landmarks, a 3D texture reference model generic to all faces is generated to efficiently estimate visible facial components. Then, the initial frontalized face is synthesized by back-projecting each input face image to the reference coordinate system.
b.Alternatively, Sagonas et al. [93] proposed an effective statistical model to simultaneously localize landmarks and convert facial poses using only frontal faces.
c.Very recently, a series of GAN-based deep models were proposed for frontal view synthesis (e.g., FF-GAN [94], TP-GAN [95]) and DR-GAN [96]) and report promising performances.
2.deep networks for feature learning
Deep learning attempts to capture high-level abstractions through hierarchical architectures of multiple nonlinear transformations and representations.

-
convolutional neural network(CNN)
CNN is robust to face location changes and scale variations and behaves better than the multilayer perceptron (MLP) in the case of previously unseen face pose variations.

-
deep belief network(DBN)
The training of a DBN contains two phases: pre-training and fine-tuning [115]. First, an efficient layerby-layer greedy learning strategy [116] is used to initialize the deep network in an unsupervised manner, which can prevent poor local optimal results to some extent without the requirement of a large amount of labeled data. During this procedure, contrastive divergence [117] is used to train RBMs in the DBN to estimate the approximation gradient of the log-likelihood. Then, the parameters of the network and the desired output are fine-tuned with a simple gradient descent under supervision.
-
deep autoencoder(DAE)
In contrast to the previously mentioned networks, which are trained to predict target values, the DAE is optimized to reconstruct its inputs by minimizing the reconstruction error.
-
recurrent neural network(RNN)
RNN is a connectionist model that captures temporal information and is more suitable for sequential data prediction with arbitrary lengths.
-
generative adversial network(GAN)
GAN trains models through a minimax tow-player game between a generator G(z) and a discriminator D(x).
3.facial expression classification
Unlike the traditional methods, where the feature extraction step and the feature classification step are independent, deep
networks can perform FER in an end-to-end way. Specifically, a loss layer is added to the end of the network to regulate the back-propagation error; then, the prediction probability of each sample can be directly output by the network.
Besides the end-to-end learning way, another alternative is to employ the deep neural network (particularly a CNN) as a feature extraction tool and then apply additional independent classifiers,such as support vector machine or random forest, to the extracted representations [133], [134].
the start of the art
In this section, we review the existing novel deep neural networks designed for FER and the related training strategies proposed to address expression-specific problems.
-
Deep FER networks for static images
1.pre-training and fine-tuning
To mitigate this problem,which direct training of deep networks on relatively small facial expression datasets is prone to overfitting many studies used additional task-oriented data to pre-train their self-built networks from scratch or fine-tuned
on well-known pre-trained models.Kaya et al. [153] suggested that VGG-Face which was trained for FR overwhelmed ImageNet which was developed for objected recognition.
To eliminate this effect, which may weaken the networks ability to represent expressions, a two-stage training algorithm FaceNet2ExpNet [111] was proposed (see Fig. 4). The fine-tuned face net serves as a good initialization for the expression net and is used to guide the learning of the convolutional layers only. And the fully connected layers are trained from scratch with expression information to regularize the training of the target FER net.


2.diverse network input
Traditional practices commonly use the whole aligned face of RGB images as the input of the network to learn features for
FER. However, these raw data lack important information, such as homogeneous or regular textures and invariance in terms of image scaling, rotation, occlusion and illumination, which may represent confounding factors for FER. Some methods have employed diverse handcrafted features and their extensions as the network input to alleviate this problem.
Low-level representations encode features from small regions in the given RGB image, then cluster and pool these features with local histograms, which are robust to illumination variations and small registration errors.
Part-based representations extract features according to the target task, which remove noncritical parts from the whole image
and exploit key parts that are sensitive to the task.
3.auxiliary blocks & layers
Based on the foundation architecture of CNN, several studies have proposed the addition of well-designed auxiliary blocks or
layers to enhance the expression-related representation capability of learned features.
4.network ensemble
Two key factors should be considered when implementing network ensembles: (1) sufficient diversity of the networks to ensure complementarity, and (2) an appropriate ensemble method that can effectively aggregate the committee networks.
5.multitask network
in the real world, FER is intertwined with various latent factors, such as head pose, illumination, and subject identity (facial morphology). To solve this problem, multitask leaning is introduced to transfer knowledge from other relevant tasks and to disentangle nuisance factors.
Multitask networks jointly train multiple networks with consideration of interactions between the target FER task and other secondary tasks, such as facial landmark localization, facial AU recognition and face verification, thus the expression-unrelated factors including identity bias can be well disentangled.
6.cascaded networks
Most commonly, different networks or learning methods are combined sequentially and individually, and each of them contributes differently and hierarchically. In general, this method can alleviate the overfitting problem, and in the meanwhile, progressively disentangling factors that are irrelevant to facial expression.
7.generative adversarial networks(GANs)
Recently, GAN-based methods have been successfully used in image synthesis to generate impressively realistic faces, numbers, and a variety of other image types, which are beneficial to training data augmentation and the corresponding recognition tasks. Several works have proposed novel GAN-based models for poseinvariant FER and identity-invariant FER.

-
Deep FER networks for dynamic image sequences
We first introduce the existing frame aggregation techniques that strategically combine deep features learned from static-based FER networks. Then, considering that in a videostream people usually display the same expression with different intensities, we further review methods that use images in different expression intensity states for intensity-invariant FER. Finally, we introduce deep FER networks that consider spatio-temporal motion patterns in video frames and learned features derived from the temporal structure.
1.frame aggregation
Various methods have been proposed to aggregate the network output for frames in each sequence to improve the performance. We divide these methods into two groups: decision-level frame aggregation and feature-level frame aggregation.
For decision-level frame aggregation, n-class probability vectors of each frame in a sequence are integrated. The most convenient way is to directly concatenate the output of these frames.
For feature-level frame aggregation, the learned features of frames in the sequence are aggregate. Many statistical-based
encoding modules can be applied in this scheme. Alternatively, matrix-based models such as eigenvector, covariance matrix and multi-dimensional Gaussian distribution can also be employed for aggregation [186], [192]. Besides, multi-instance learning has been explored for video-level representation [193], where the cluster centers are computed from auxiliary image data and then bag-of-words representation is obtained for each bag of video frames.
2.expression intensity network
In this section, we introduced expression intensity-invariant networks that take training samples with different intensities as input to exploit the intrinsic correlations among expressions from a sequence that vary in intensity.
3.deep spatio-temporal FER network
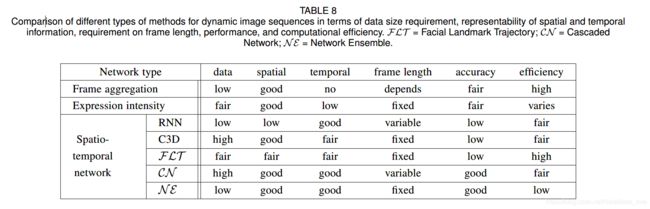
4.discussion
frame aggregation:Frame aggregation is employed to combine the learned feature or prediction probability of each frame for a sequence-level result. The output of each frame can be simply concatenated (fixed-length frames is required in each sequence) or statistically aggregated to obtain video-level representation (variable-length frames processible). This method is computationally simple and can achieve moderate performance if the temporal variations of the target dataset is not complicated.
However, frame aggregation handles frames without consideration of temporal information and subtle appearance changes, and expression intensity-invariant networks require prior knowledge of expression intensity which is unavailable in real-world scenarios.
Deep spatiotemporal networks:are designed to encode temporal dependencies in consecutive frames and have been shown to benefit from learning spatial features in conjunction with temporal features. RNN and its variations (e.g., LSTM, IRNN and BRNN) and C3D are foundational networks for learning spatio-temporal features.
However, the performance of these networks is barely satisfactory.RNN is incapable of capturing the powerful convolutional
features. And 3D filers in C3D are applied over very short video clips ignoring long-range dynamics. Also, training such a huge network is computationally a problem, especially for dynamic FER where video data is insufficient.
facial landmark trajectory methods extract shape features based on the physical structures of facial morphological variations to capture dynamic facial component activities, and then apply deep networks for classification. This method is computationally simple and can get rid of the issue on illumination variations.
However, it is sensitive to registration errors and requires accurate facial landmark detection, which is difficult to access in unconstrained conditions.
Network ensemble : is utilized to train multiple networks for both spatial and temporal information and then to fuse the network outputs in the final stage.
However most related researches randomly selected fixedlength video frames as input, leading to the loss of useful temporal information.
Additional related issues
-
Occlusion and non-frontal head pose
-
FER on infrared data
-
FER on 3D static and dynamic data
-
visualization techniques
CHALLENGES AND OPPORTUNITIES
-
Facial expression datasets
-
Incorporating other affective models
-
Dataset bias and imbalanced distribution
-
Multimodal affect recognition