CVPR 2023 | iTPNs: 谁说 Linear probing 不适用 MIM 任务?

Title: Integrally Pre-Trained Transformer Pyramid Networks
Paper: https://arxiv.org/pdf/2211.12735.pdf
Code: https://github.com/sunsmarterjie/iTPN
导读
自 ViT 提出以后,Transformer 在计算机视觉领域逐渐衍生出两个重要分支,一个分支是以 Vision Transformer 为代表的给为 Transformer 主干网络,而另一个分支便是以 MAE 和 BEiT 为代表的 掩码图像重建(Masked Image Modelling, MIM)技术。通过结合这两项技术,极大的促进了包括分类、检测和分割等下游任务的发展。
今天为大家介绍的是一篇与 MIM 和 Vision Transformer 相关的一篇工作,其旨在解决上游预训练和下游微调之间的迁移差距。以代表性工作 MAE 和 BEiT 为例,其使用的主干网络均为朴素的 ViT 模型。尽管 SimMIM、ConvMAE以及GreenMIM 等模型应用了分层结构,但本质上仅会作用到 Backbone 上,而不会影响到 Neck,即特征金字塔。这会导致一个问题,仅当我们直接应用于下游任务时,如果你是采用 Linear probing 的方式,虽然不会破坏预训练的特征提取器,但由于整个优化过程从随机初始化的 Neck 层开始,作者认为这并不能确保冻结的 Backbone 与 Neck 能够很好的“搭配合作”。
因此,本文设计了一种简洁有效的预训练框架来缓解这种现象。考虑到部分读者可能对这方面不太熟悉,本篇文章将会先引入相关的概念和必要的背景基础知识,最后再详细介绍此项工作。
背景
定义
掩码图像重建是一种利用图像掩码去执行计算机视觉任务的技术。相比于基于对比学习等方法,基于 MIM 的方法能提供更有竞争力的结果。说到这,那就让我们先简单回顾下对比学习的知识吧。
对比学习
对比学习(Contrastive Learning)是一种通过在相同数据的扭曲视图(distorted views)上提取不变特征来学习实例级判别表示。例如凯明的MoCo和Hinton的SimCLR便是早期的两项代表性工作,它们采用不同的机制引入负样本与正样本进行对比:
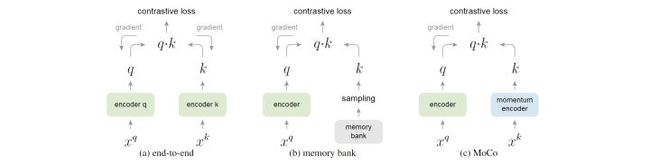
笔者之前写过的关于 MoCo 的论文+源码解读,感兴趣的可以去看看:https://mp.weixin.qq.com/s/U86RW5BAjWO5gpw-qXEzoA
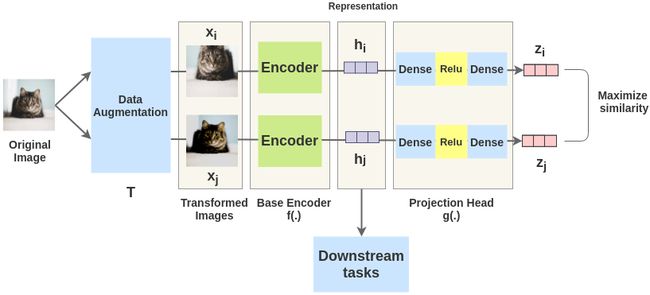
随后,DeepMind 团队提出了 BYOL 进一步解决了对负样本的依赖(避免表示崩溃)。当然,同期也有不少其他类似的工作,如凯明的SimSiam便探索了孪生神经网络表征学习的崩溃解。
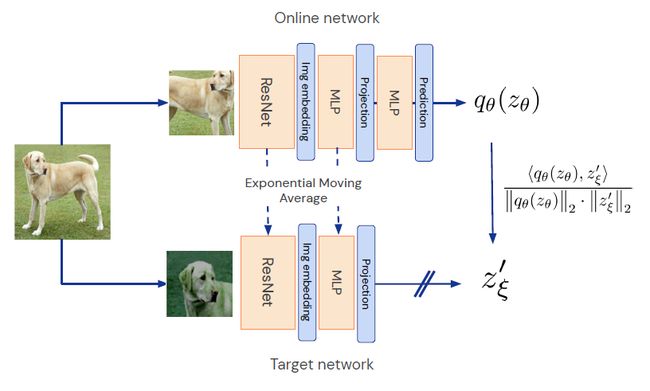
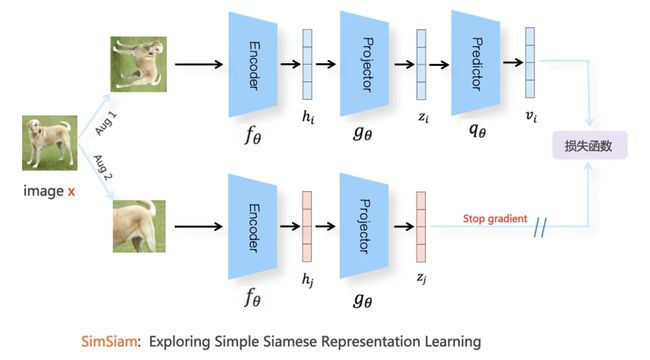

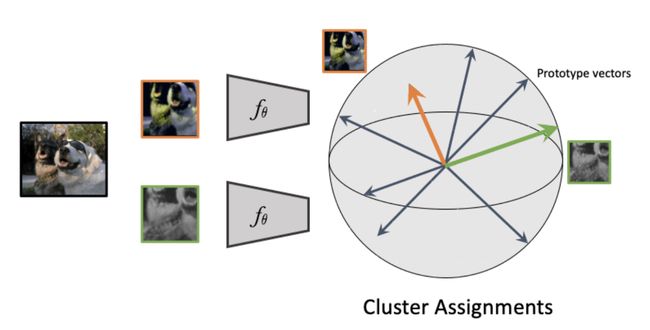
除了这种组成一对对的表征学习方式外,SwAV提倡对数据进行在线聚类,同时加强同一图像的多重增强视图之间的一致性:
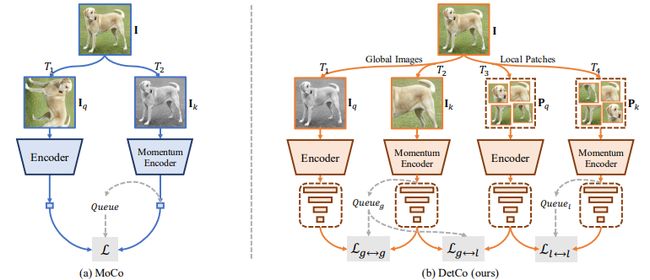
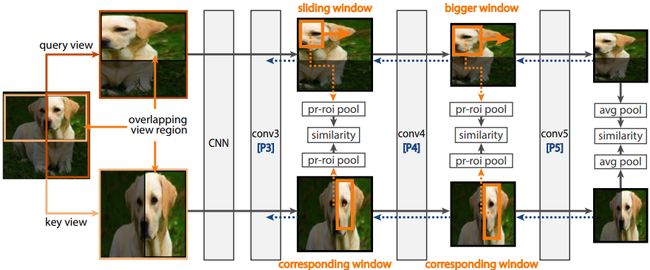
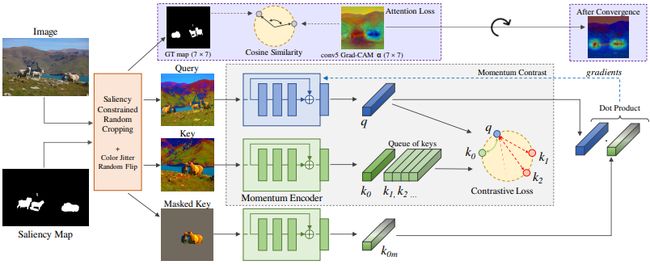
最后便是一些致力于将对比学习应用于提升特定下有任务的方法,如同时发表在 CVPR & ICCV 2021 上的三篇代表性文章:Detco、ReSim以及CAST:
< ,
, ,
, >
>
自凯明的 MIM 提出以后,此类对比学习方法的热度也逐渐下降了,后面也就一些结合 Transformer 去做的工作如 DINO 和 MoCov3。
掩码图像重建
掩码图像重建是自监督任务的一种形式,它能够很好的解决对数据的依赖。相比于 CV 领域,NLP 领域一直都处于领先地位,无论是基于 GPT 中的自回归语言建模或者 BERT 中的掩码自编码方案,本质上都是基于删除-预测的机制,这些方法很容易推广到 LLM 上。
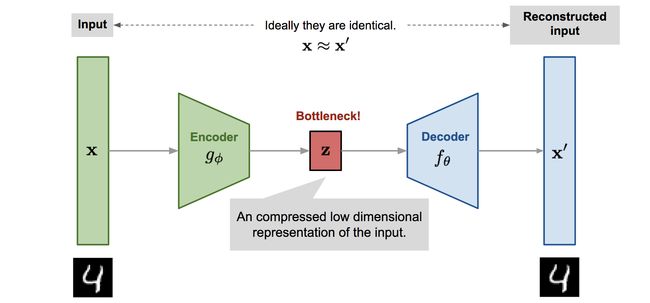
然而,正如凯明在 MAE 论文中指出,掩码自编码器的概念是一种更通用的去噪自编码器(Denoising Auto Encoder, DAE),它是自然的,也适用于计算机视觉。DAE 可以算是介于 AE 与 VAE 之间的产物。众所周知,自编码器(Auto-Encoder)是一种非常典型的网络架构,它允许在没有标注的情况下进行表征学习,由 Hinton 等人于 1993 年提出。随后过了十几年,人们便提出了将噪声“强制”引入到学习的表征上,其通过对潜在特征叠加高斯噪声从而形成“损坏”的信号以作为网络的输入来重建未校正的输入信号,这便是变分自编码器(Variational auto-encoder, VAE)。
关于 VAE 笔者此前写过一篇全面的推导和解析,这里强烈推荐大家看看,感受下数学之美!
BERT 的提出带火了 NLP 领域。而对于 CV 领域而言,笔者早期接触的自监督学习主要有图像修复、图像着色、图像拼图等形式,强烈推荐大家去看下 Amit Chaudhary 的自监督学习笔记:https://amitness.com/2020/02/illustrated-self-supervised-learning/。随着 ViT 的引入,便涌现出了许多基于掩码预测的自监督学习方法,下面带大家快速过一遍:

iGPT较早提出在给定一系列像素作为输入的情况下预测后续像素值。
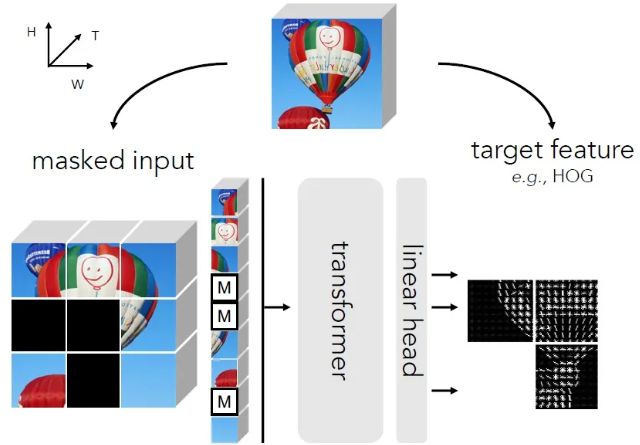
MaskFeat应用 HOG 作为预测目标,而非 RGB 像素值。
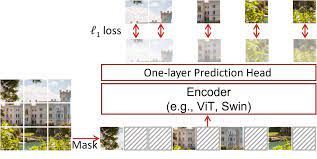
SimMIM中采用线性层作为解码器
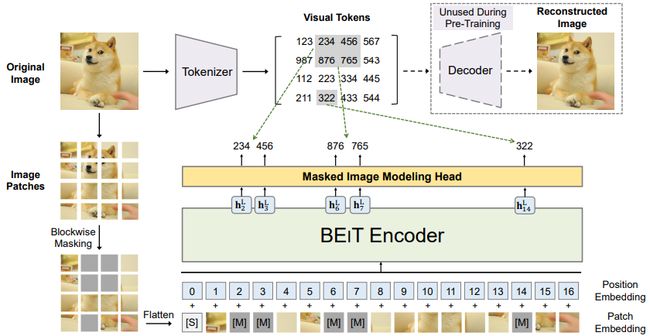
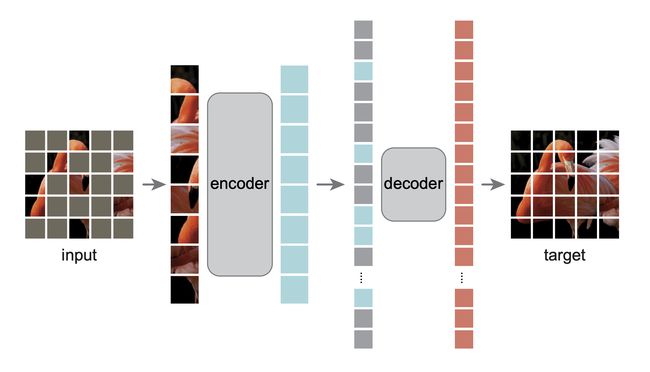
BEiT和MAE算是两个同期的工作,其一个亮点便是基于 ViT 模型重建缺失块。
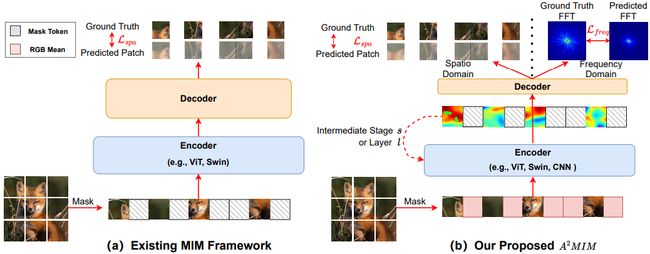
A 2 M I M A^{2}MIM A2MIM 则是提出了一种与架构无关的 MIM 框架,将 Transformer 和 CNN 兼容起来。
方法
Framework
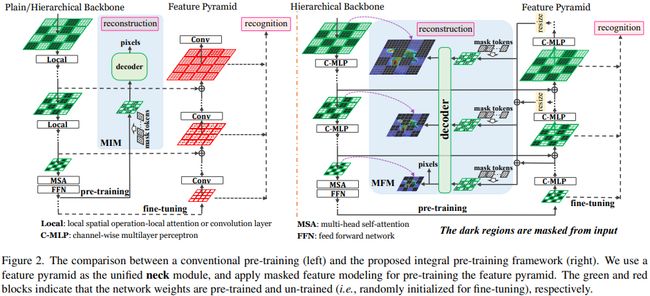
整体的框架图如上所示。首先,让我们先看下图中左侧内容,其显示了传统的预训练范式。需要注意的是,这里我们先不区分具体的微调任务(如分类、检测和分割),假设它们都共享相同的 Backbone,而无需 Neck 和 Head (参考MAE和BEiT等)。那么,问题来了,这种架构容易引起两个问题:
- 骨干网络的参数并未针对多级特征提取进行专门的优化,即缺乏一种合理的机制来高效的提取和融合多尺度特征;
- 微调阶段的优化若从随机初始化的 Neck 和 Head 开始,那么这会显著减慢训练过程且不容易获得更优的效果。
因此,iTPNs 提倡将重建和识别过程统一起来,以最大限度的减轻这种现象,如图中右半部分所示。
Unifying Reconstruction and Recognition
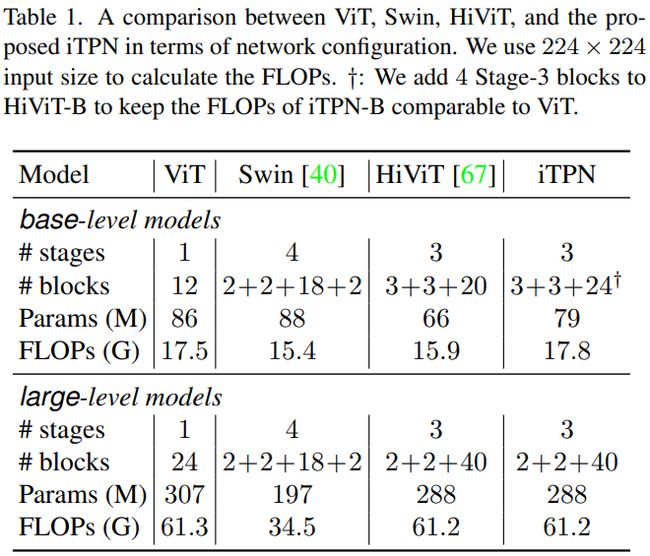
具体地,iTPNs 基于 HiViT 和 特征金字塔构建了一个全新的框架。其中,HiViT 通过以下方式完成进一步的简化:
- 采用通道多层感知器(
Channel-wise MultiLayer Perceptron,C-MLP)替换shiftedwindow attentions; - 将感受野为 7 × 7 7 \times 7 7×7 的 stage 剔除掉,而是直接在 14 × 14 14 \times 14 14×14 的 stage 直接计算全局注意力;
如此一来,该主干网络就不用像 SimMIM 方法一样需要输入全图才能跑,直接节省 30%–50 % 的计算成本。下表展示了具体的参数比对:
此外,为了更好的联合优化骨干网络(HiViT)和颈部(Feature Pyramid),iTPNs 采用了以下两个技术细节:
首先,作者通过将特征金字塔插入预训练阶段(用于重建)并在微调阶段复用训练好的权重(用于识别)以此来统一上游和下游颈部特征。
其次,为了更好地预训练特征金字塔,本文提出了一种新颖的掩码特征建模(Masked Feature Modeling, MFM)任务为特征金字塔提供多阶段监督,该任务通过将原始图像输入一个 moving-averaged backbone 计算出中间特征,同时使用特征金字塔的每一层输出来重建中间目标。
总的来说,MFM 可以理解为 MIM 的一种补充方法,其更好的提高了重建和识别的准确性。此外,MFM 还可以适应从预训练教师模型(本文应用了CLIP)“吸收知识”以获得最佳的性能。
实验
ImageNet-1K classification
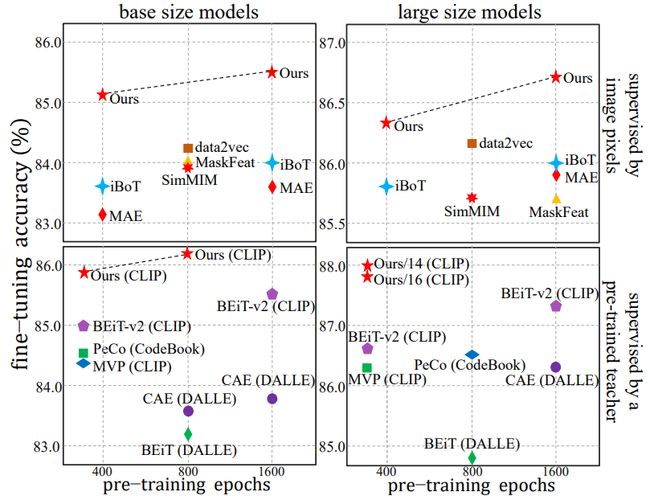
可以看出,iTPN 显示出优于现有方法的显着优势,无论是仅使用像素监督还是利用来自预训练教师的知识(括号中内容为教师模型的名称)。
ImageNet-1K classification
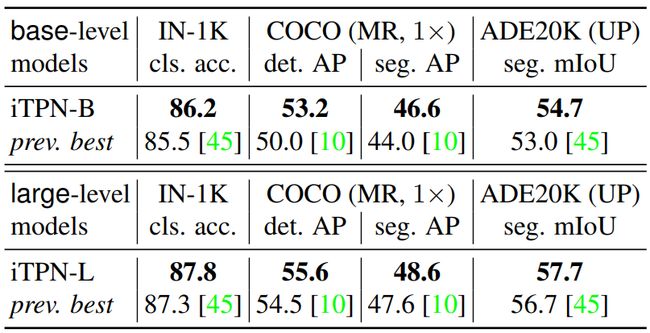
此外,iTPN 在几个重要基准测试中的识别准确率均超过了之前的 SOTA。
COCO and ADE20K
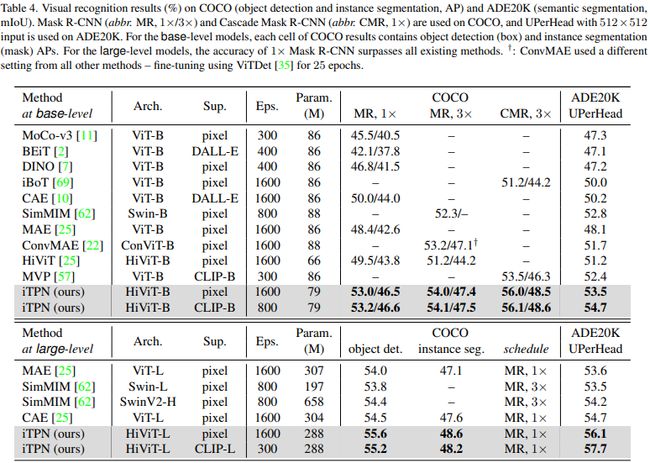
不仅在图像分类,在下游的目标检测和图像分割任务下表现也很不错。
Linear probing
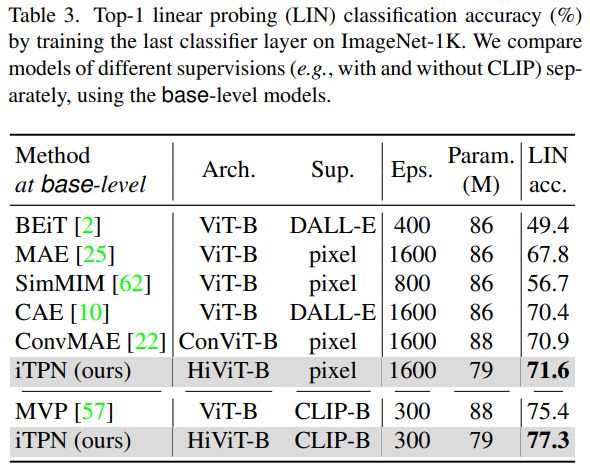
正如我们前面所提到的,传统 MIM 方法使用 Linear probing 微调时效果并不好,这在很多 MIM 相关的方法中也经常被提及。确实,与 Fine-tune 相比,这种方式对预训练骨干更加敏感。不过,从上表可以明显的看出,iTPN 仍然能获得不错的精度,例如在 CLIP 监督下,超越同等配置的 MVP 将近两个百分点。
总结
本文提出了一个用于预训练 HiViT 的完整框架,其核心贡献在于利用特征金字塔统一重建和识别任务,从而最大限度地减少预训练和微调任务之间的迁移差距。此外,为了更好的优化特征金字塔,本文提出了一种掩码特征建模任务,旨在补充掩码图像建模能力。最后,预训练的 iTPN 在一些主流的视觉识别任务中报告了卓越的识别能力。
写在最后
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!
同时欢迎添加小编微信: cv_huber,备注CSDN,加入官方学术|技术|招聘交流群,一起探讨更多有趣的话题!