单因素方差分析(R)
目录
目标
原理
假设前提和模型设定
离差平方和分解
检验统计量和拒绝域
未知参数的估计
例题
应用
目标
方差分析的基本思想:通过分析不同影响来源对总体的影响程度,确定可控因素对研究对象影响力是否显著。
单因素方差分析用来研究一个控制变量的不同水平是否对观测指标变量有显著影响。
原理
观测指标变量值的变动会受控制变量和其他随机变量两方面的影响,据此,把观测指标变量的总离差平方和(SST)分解为(受控制变量影响的)组间离差平方和(SSB)和(受其他随机变量影响的)组内离差平方和(SSW)两部分,即:SST=SSB+SSW。在观测指标变量的总离差平方和中,如果组间离差平方和所占比例较大,则说明观测指标变量的变动主要由控制变量引起的,控制变量给观测指标变量有显著影响;反之,控制变量对观测指标变量没有显著影响。
假设前提和模型设定
设单因素A有r个水平,分别记为![]() ,在每个水平
,在每个水平![]() 下的观测指标变量样本值看做一个总体,故有r个总体,基于假设前提:
下的观测指标变量样本值看做一个总体,故有r个总体,基于假设前提:
1.每个总体均服从正态分布,且方差相等,即![]()
2.每个总体中抽取的样本![]() 相互独立(
相互独立( 为
为 因素水平的实验数据个数)
因素水平的实验数据个数)
通过假设检验来探究期望控制变量对观测指标变量是否有显著影响,如果有,则意味着A因素不同水平对应的观测指标变量总体的均值有显著差异。可作出如下假设:
![]() ;
;
![]() 不完全相等
不完全相等
方差分析的任务:
任务一:检验r个总体的均值是否相等,即完成上述假设的检验;
任务二:作出未知参数![]() 的估计。
的估计。
由假设前提有![]() ,即有
,即有![]() ,故
,故![]() 可视为随机误差,且相互独立,由假设前提知,各个
可视为随机误差,且相互独立,由假设前提知,各个![]() 相互独立。从而得到模型:
相互独立。从而得到模型:
![]()
记数据总个数为
![]()
总平均值为
![]()
用因素水平下的总体均值与总平均值的差异来表示 因素水平对观测指标变量的效应:![]() 。效应间的关系为
。效应间的关系为
![]()
从而改写模型为:
![]()
可得,前述假设等价为:
![]()
![]() 不全为0
不全为0
这是因为当且仅当![]() 时,
时,![]() ,即
,即![]() (i=1,2,...,r)
(i=1,2,...,r)
离差平方和分解
记 因素水平下的样本均值为
![]() ,
,
A因素的所有水平的样本总均值为
![]()
组内离差平方和为:
![]()
组间离差平方和为:
总离差平方和为:
![]()
检验统计量和拒绝域
由![]() 和
和![]() 分布的可加性,可得:
分布的可加性,可得:
![]()
因此,
![]()
SSB可以看做r个变量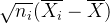 的平方和,它们之间仅有一个线性约束条件:
的平方和,它们之间仅有一个线性约束条件:
![]()
故知SSB的自由度是r-1。
并且,由SSW和SSB表达式可知二者独立,所以,
当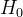 为真时,
为真时,
![]()
![]()
当 不为真时,
![]()
![]()
因此可得拒绝域为:
![]()
因SST的n个变量![]() 之间有一个约束条件
之间有一个约束条件![]() ,所以SSW的自由度为n-1。
,所以SSW的自由度为n-1。
据上述分析结果,可得方差分析表:
| 方差来源 | 平方和 | 自由度 | 均方 | F比 |
| 因素A | SSB | r-1 | ||
| 误差 | SSW | n-r | ||
| 总和 | SST | n-1 |
在实际中,可先计算SST和SSB,再由二者相减得到SSW,以简便计算。
未知参数的估计
由![]() 知,
知, 的无偏估计为:
的无偏估计为:![]()
由![]() 知,
知,![]() 的无偏估计为:
的无偏估计为:![]()
不管是否为真,![]() ,可知
,可知 的无偏估计为:
的无偏估计为:![]()
当拒绝时,效应![]() 不全为0,且
不全为0,且![]() ,可知,
,可知,![]() 的无偏估计为
的无偏估计为![]()
当拒绝时,常常需要作出两总体![]() 和
和![]() ,
,![]() 的均值差
的均值差![]() 的区间估计,由于
的区间估计,由于
![]()
![]()
并且![]() 与
与![]() 独立,于是,
独立,于是,
据此得均值差![]() 的置信水平为1-
的置信水平为1- 的置信区间为:
的置信区间为:
![]()
例题
设有三台机器,用来生产规格相同的铝合金薄板,并且假定除了机器这一因素之外,其他条件都相同。取样并测量薄板的厚度精确到千分之一厘米,得到结果(服从单因素方差分析假设前提):
machine1=c(0.236,0.238,0.248,0.245,0.243)
machine2=c(0.257,0.253,0.255,0.254,0.261)
machine3=c(0.258,0.264,0.259,0.267,0.262)
data1=cbind(machine1,machine2,machine3)
write.csv(data1,"D:/CSDN/方差分析/r/data1.csv",row.names = FALSE)
先假设检验三个总体的均值是否相等
做出假设:
![]()
![]() 不全相等
不全相等
由数据可知,r=3,![]() ,n=15,则,
,n=15,则,
![]()
![]()
SSW=SST-SSB
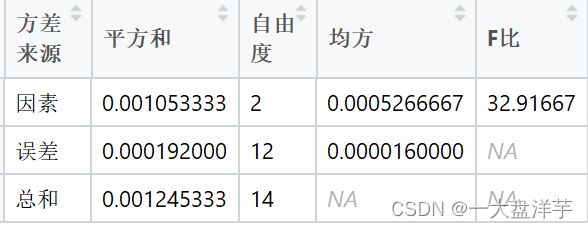
F比=32.91667>![]() =3.885294
=3.885294
故在0.05显著性水平下拒绝,认为各台机器生产的薄板厚度有显著的差异。
write.csv(data1,"D:/CSDN/方差分析/r/data1.csv",row.names = FALSE)
Data1=read.csv("D:/CSDN/方差分析/r/data1.csv")
n=15
r=3
n1=n2=n3=5
SST=sum(c(Data1$machine1**2,
Data1$machine2**2,
Data1$machine3**2))-(sum(Data1)**2)/n
SSB=sum(c((sum(Data1$machine1)**2)/n1,
(sum(Data1$machine2)**2)/n2,
(sum(Data1$machine3)**2)/n3))-(sum(Data1)**2)/n
SSW=SST-SSB
tab1=data.frame(matrix(nrow = 3,ncol = 5))
colnames(tab1)=c("方差来源","平方和","自由度","均方","F比")
tab1[1,1]="因素"
tab1[2,1]="误差"
tab1[3,1]="总和"
tab1[1,2]=SSB
tab1[2,2]=SSW
tab1[3,2]=SST
tab1[1,3]=r-1
tab1[2,3]=n-r
tab1[3,3]=n-1
tab1[1,4]=SSB/(r-1)
tab1[2,4]=SSW/(n-r)
tab1[1,5]=tab1[1,4]/tab1[2,4]
qf(1-0.05,r-1,n-r)接着对未知参数![]() 进行点估计及均值差的0.95置信区间
进行点估计及均值差的0.95置信区间
![]()
1.6e-05
![]()
0.2533333
![]()
![]()
![]()


hatsigma2=SSW/(n-r)
hatmu=mean(c(mean(Data1$machine1),
mean(Data1$machine2),
mean(Data1$machine3)))
tab2=data.frame(matrix(nrow = 2,ncol = 3))
colnames(tab2)=c("machine1","machine2","machine3")
rownames(tab2)=c("hatmu","hatdelta")
tab2[1,1]=mean(Data1$machine1)
tab2[1,2]=mean(Data1$machine2)
tab2[1,3]=mean(Data1$machine3)
tab2[2,1]=tab2[1,1]-hatmu
tab2[2,2]=tab2[1,2]-hatmu
tab2[2,3]=tab2[1,3]-hatmu
tab3=data.frame(matrix(nrow = 3,ncol = 2))
colnames(tab3)=c("lower","upper")
rownames(tab3)=c("interval12","interval13","interval23")
t=qt(1-0.025,n-r)
tab3[1,1]=mean(Data1$machine1)-mean(Data1$machine2)-
t*sqrt(SSW/(n-r)*(1/n1+1/n2))
tab3[1,2]=mean(Data1$machine1)-mean(Data1$machine2)+
t*sqrt(SSW/(n-r)*(1/n1+1/n2))
tab3[2,1]=mean(Data1$machine1)-mean(Data1$machine3)-
t*sqrt(SSW/(n-r)*(1/n1+1/n3))
tab3[2,2]=mean(Data1$machine1)-mean(Data1$machine3)+
t*sqrt(SSW/(n-r)*(1/n1+1/n3))
tab3[3,1]=mean(Data1$machine2)-mean(Data1$machine3)-
t*sqrt(SSW/(n-r)*(1/n2+1/n3))
tab3[3,2]=mean(Data1$machine2)-mean(Data1$machine3)+
t*sqrt(SSW/(n-r)*(1/n2+1/n3))应用
library(reshape2)
tData1=melt(Data1,
measure.vars=c("machine1","machine2","machine3"),
variable.name = "machine",
value.name = "thickness")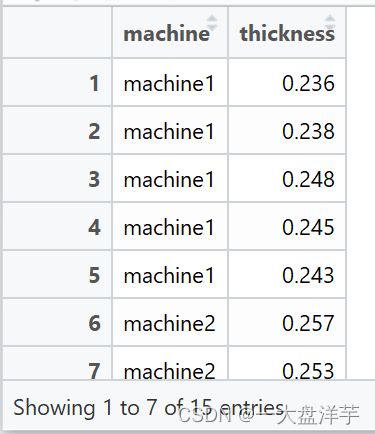
aov=aov(thickness~machine,data=tData1)
summary(aov)