通过pdfBox读取pdf内容
引入依赖:
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>jempbox</artifactId>
<version>1.8.11</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>preflight</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-tools</artifactId>
<version>2.0.0</version>
</dependency>
2、通过引用处理文档,代码示例如下:
import org.apache.pdfbox.multipdf.PDFMergerUtility;
import org.apache.pdfbox.multipdf.Splitter;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageContentStream;
import org.apache.pdfbox.pdmodel.PDPageTree;
import org.apache.pdfbox.pdmodel.common.PDRectangle;
import org.apache.pdfbox.pdmodel.font.PDFont;
import org.apache.pdfbox.pdmodel.font.PDType0Font;
import org.apache.pdfbox.pdmodel.graphics.image.PDImageXObject;
import org.apache.pdfbox.text.PDFTextStripper;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class PdfBoxUtil {
/**
* 读取pdf中文字信息(全部)
*
* @param inputFile
* @return
*/
public static String readPdf(String inputFile) {
//创建文档对象
PDDocument doc = null;
String content = "";
try {
//加载一个pdf对象
doc = PDDocument.load(new File(inputFile));
//获取一个PDFTextStripper文本剥离对象
PDFTextStripper textStripper = new PDFTextStripper();
content = textStripper.getText(doc);
// System.out.println("内容:" + content);
// System.out.println("全部页数" + doc.getNumberOfPages());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//关闭文档
if (doc != null) {
doc.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return content;
}
/**
* 插入文字到pdf中
*
* @param inputFilePath
* @param outputFilePath
* @param pageNum
* @param message
* @throws Exception
*/
public static void insertWordContent(String inputFilePath, String outputFilePath, Integer pageNum, String message) throws Exception {
File inputPDFFile = new File(inputFilePath);
File outputPDFFile = new File(outputFilePath);
PDDocument doc = null;
try {
doc = PDDocument.load(inputPDFFile);
PDPageTree allPages = doc.getDocumentCatalog().getPages();
// PDFont font = PDType1Font.HELVETICA_BOLD;
PDFont font = PDType0Font.load(doc, new File("C:\\Users\\DELL\\Desktop\\FZLTHJW.TTF"));
// 字体大小
float fontSize = 36.0f;
PDPage page = (PDPage) allPages.get(pageNum - 1);
PDRectangle pageSize = page.getMediaBox();
float stringWidth = font.getStringWidth(message) * fontSize / 1000f;
// 计算页面的中心位置
int rotation = page.getRotation();
boolean rotate = rotation == 90 || rotation == 270;
float pageWidth = rotate ? pageSize.getHeight() : pageSize.getWidth();
float pageHeight = rotate ? pageSize.getWidth() : pageSize.getHeight();
double centeredXPosition = rotate ? pageHeight / 2f : (pageWidth - stringWidth) / 2f;
double centeredYPosition = rotate ? (pageWidth - stringWidth) / 2f : pageHeight / 2f;
// append the content to the existing stream
PDPageContentStream contentStream = new PDPageContentStream(doc, page, true, true, true);
contentStream.beginText();
// 设置字体和字体大小
contentStream.setFont(font, fontSize);
// 设置字体颜色(如下为红色)
contentStream.setNonStrokingColor(255, 0, 0);
if (rotate) {
// rotate the text according to the page rotation
contentStream.setTextRotation(Math.PI / 2, centeredXPosition, centeredYPosition);
} else {
contentStream.setTextTranslation(centeredXPosition, centeredYPosition);
}
// 写入文字
contentStream.drawString(message);
contentStream.endText();
contentStream.close();
// 保存到新文档中
doc.save(outputPDFFile);
System.out.println("成功向pdf插入文字");
} finally {
if (doc != null) {
doc.close();
}
}
}
/**
* 在pdf中插入图片
*
* @param inputFilePath
* @param imagePath
* @param outputFilePath
* @param pageNum
* @throws Exception
*/
public static void insertImageContent(String inputFilePath, String imagePath, String outputFilePath, Integer pageNum) throws Exception {
File inputPDFFile = new File(inputFilePath);
File outputPDFFile = new File(outputFilePath);
try {
PDDocument doc = PDDocument.load(inputPDFFile);
PDImageXObject pdImage = PDImageXObject.createFromFile(imagePath, doc);
PDPage page = doc.getPage(0);
//注释的这行代码会覆盖原内容,没注释的那行不会覆盖
// PDPageContentStream contentStream = new PDPageContentStream(doc, page);
PDPageContentStream contentStream = new PDPageContentStream(doc, page, true, true, true);
contentStream.drawImage(pdImage, 70, 250);
contentStream.close();
doc.save(outputPDFFile);
doc.close();
System.out.println("成功插入图片");
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 合并pdf文件
*
* @param pathList
* @param targetPDFPath
* @throws Exception
*/
public static void mergePdf(List<String> pathList, String targetPDFPath) throws Exception {
List<InputStream> inputStreams = new ArrayList<>();
for (String path : pathList) {
inputStreams.add(new FileInputStream(new File(path)));
}
PDFMergerUtility mergePdf = new PDFMergerUtility();
File file = new File(targetPDFPath);
if (!file.exists()) {
file.delete();
}
mergePdf.addSources(inputStreams);
mergePdf.setDestinationFileName(targetPDFPath);
mergePdf.mergeDocuments();
for (InputStream in : inputStreams) {
if (in != null) {
in.close();
}
}
}
/**
* 将pdf文件分割成多个
*
* @param sourcePdfPath
* @param splitPath
* @param splitFileName
* @throws Exception
*/
public static void spiltPdf(String sourcePdfPath, String splitPath, String splitFileName) throws Exception {
File targetDir = new File(splitPath);
if (!targetDir.exists()) {
targetDir.mkdirs();
}
int j = 1;
String splitPdf = splitPath + File.separator + splitFileName + "_";
// Loading an existing PDF document
File file = new File(sourcePdfPath);
PDDocument document = PDDocument.load(file);
// Instantiating Splitter class
Splitter splitter = new Splitter();
splitter.setStartPage(1);
splitter.setSplitAtPage(1);
splitter.setEndPage(5);
// splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
// Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
// Saving each page as an individual document
while (iterator.hasNext()) {
PDDocument pd = iterator.next();
String pdfName = splitPdf + j++ + ".pdf";
pd.save(pdfName);
}
document.close();
}
public static void main(String args[]) throws IOException {
// 1、读取pdf文件
// String filePath = "F:\\image_test\\sample.pdf";
// String content = readPdf(filePath);
// System.out.println("读取内容:" + content);
// 2、pdf中插入文字
// String inFilePath = "F:\\image_test\\sample.pdf";
// String outFilePath = "F:\\image_test\\sample2.pdf";
// try {
// insertWordContent(inFilePath,outFilePath,1,"插入的小狗文字");
// } catch (Exception e) {
// e.printStackTrace();
// }
// 3、pdf文件插入图片
// String inFilePath = "F:\\image_test\\sample.pdf";
// String imagePath = "F:\\image_test\\sun1.jpg";
// String outFilePath = "F:\\image_test\\sample3.pdf";
// try {
// insertImageContent(inFilePath,imagePath,outFilePath,1);
// } catch (Exception e) {
// e.printStackTrace();
// }
// 4、合并pdf文件
// String filePath1 = "F:\\image_test\\sample.pdf";
// String filePath2 = "F:\\image_test\\sample2.pdf";
// String outFilePath = "F:\\image_test\\sample4.pdf";
// List filePathList = new ArrayList<>();
// filePathList.add(filePath1);
// filePathList.add(filePath2);
// try {
// mergePdf(filePathList, outFilePath);
// } catch (Exception e) {
// e.printStackTrace();
// }
// 5、拆分pdf文件
String inFilePath = "F:\\image_test\\sample4.pdf";
String targetPath = "F:\\image_test\\11";
String targetFileName = "aa";
try {
spiltPdf(inFilePath, targetPath, targetFileName);
} catch (Exception e) {
e.printStackTrace();
}
}
}
如上的示例代码,依次按照顺序执行main方法示例
(1)、执行1效果:

(2)执行2效果:创建新文件且插入文字。
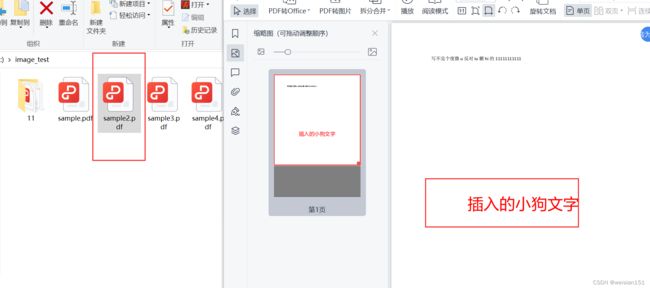
示例2需要我们自行下载字体,可以以下地址下载:
https://www.fontke.com/font/10279514/download/
在代码的如下位置引入该字体文件

(3)、3执行效果,插入图片成功

(4)、4执行效果,合并pdf会出现2页
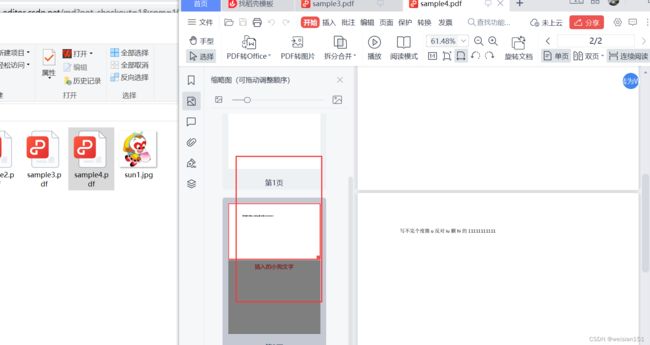
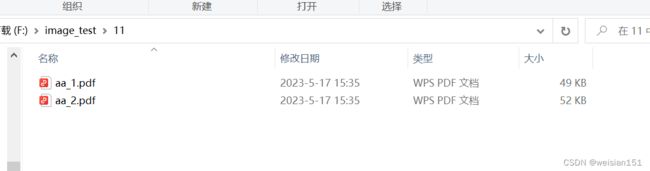
(5)、5执行效果,将多页的pdf文件进行一页一页分割
学海无涯苦作舟!!!