FC-CLIP-卷积永存:开放词汇分割与单一冻结卷积CLIP
论文链接:https://arxiv.org/abs/2308.02487
Github:GitHub - bytedance/fc-clip: This repo contains the code for our paper Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP
机构:约翰霍普金斯
摘要
开放词汇分割是一项具有挑战性的任务,需要在不同的环境中从开放的类别集中分割和识别对象。解决这一挑战的一种方法是利用多模态模型(如CLIP)在共享嵌入空间中提供图像和文本特征,这有效地弥合了封闭词汇表和开放词汇表识别之间的差距。
因此,现有方法通常采用两阶段框架来解决问题,其中输入首先通过掩码生成器,然后通过CLIP模型以及预测的掩码。这个过程涉及多次从原始图像中提取特征,这可能是无效和低效的。相比之下,我们建议使用共享的冷冻卷积CLIP骨干将所有内容构建到单级框架中,这不仅大大简化了当前的两级管道,而且还显著地产生了更好的准确性-成本权衡。由此产生的单级系统,称为FC-CLIP,受益于以下观察结果:冻结的CLIP主干保持了开放词汇表分类的能力,也可以作为强掩码生成器,卷积CLIP可以很好地推广到比对比图像-文本预训练期间使用的更大的输入分辨率。令人惊讶的是,FC-CLIP在各种基准测试中取得了最先进的结果,同时运行速度几乎很快。具体而言,当仅对COCO全景数据进行训练并以零射击方式进行测试时,FC-CLIP在ADE20K上实现26.8 PQ、16.8 AP和3410万ou,在Mapillary远景上实现18.2 PQ、27.9万ou,在cityscape上实现44.0 PQ、26.8 AP、56.2万ou,在相同设置下分别优于现有技术在ADE20K上实现+4.2 PQ、+2.4 AP、+4.2 mIoU,在Mapillary远景上实现+4.0 PQ,在cityscape上实现+20.1 PQ。此外,FC-CLIP的训练和测试时间比同类现有技术显著快7.5倍和6.6倍,同时使用的总模型参数减少5.9倍。同时,FC-CLIP还在各种开放词汇语义分割数据集上设置了新的最先进的性能。
背景
挑战
全视分割(Panoptic segmentation)[42]是一项复杂的计算机视觉任务,旨在预测一组不重叠的掩模,每个掩模都有相应的类标签。它结合了语义分割[35]和实例分割[32]的任务,使其成为一个具有挑战性的问题。目前研究在全光质量(panoptic quality)(PQ)方面取得了重大进展。
然而,注释这种细粒度数据集的成本很高。为了克服封闭式词汇分词的局限性,人们提出了开放式词汇分词[46,85,28,24]。为了确保提供有意义的嵌入,通常使用预训练的文本编码[22,67,55,66]。该编码器可以有效地捕获词和短语的语义,这对开放词汇分词至关重要。
SimBaseline[85]和OVSeg[50]是最近使用两阶段框架使CLIP适应开放词汇分词的两种方法。在这些方法中,首先通过heavy mask generater 对图像进行处理[34,19],获得掩模建议,然后生成每个掩模图像裁剪,并将其馈送到冻结的CLIP模型中进行分类。MaskCLIP[24]将这种方法扩展到开放词汇全视分割,但另外利用CLIP主干中的掩码提议作为注意掩码,以有效地避免masked crops的多次转发过程。最近,ODISE[84]采用stable diffusion UNet[69,68]作为mask generater的冷冻骨干,显著提高了最先进的性能。然而,尽管取得了这些进步,它们仍然依赖于两阶段框架,其中mask generater 和CLIP分类器分别从原始图像中提取特征,导致效率低下和无效。
因此,一个自然的问题出现了,即是否有可能将掩码生成器和CLIP分类器统一到一个开放词汇分词的单阶段框架中。在它们之间共享特征提取器是一个简单的解决方案,但它带来了两个挑战。
首先,微调CLIP主干可能会破坏图像和文本特征之间的对齐,从而导致在词汇表外类别上的性能差得多。现有方法[85,50,24,84]依赖于另一个独立的主干作为掩模生成器,增加了模型尺寸和计算成本。
其次,CLIP模型通常在相对较低分辨率的输入上进行预训练,而密集预测任务需要更高的分辨率才能获得最佳性能。
为了缓解这两个挑战,我们建议在共享的冷冻卷积CLIP主干上构建掩码生成器和CLIP分类器,从而形成单级框架FC-CLIP。冻结的CLIP主干确保了预训练的图像-文本特征对齐是完整的,允许超出词汇表的分类。它还可以通过附加轻量级像素解码器和掩码解码器作为强掩码生成器[19,89]。当输入大小增大时,基于卷积神经网络(CNN)的卷积CLIP[45]经验显示,与基于vit的CLIP[25]相比,卷积CLIP具有更好的泛化能力。这与全卷积网络在密集预测任务中的成功[58]相呼应。在图1中,我们通过k-means聚类将基于vit和基于cnn的CLIP的学习视觉表示可视化[57]。如图所示,基于cnn的CLIP学习到的特征在不同的输入大小上都更加鲁棒↓
令人惊讶的是,采用单个冻结卷积CLIP作为共享特征提取器的结果是非常简单而有效的设计。具体来说,单阶段FC-CLIP由建立在共享冻结卷积CLIP主干上的三个模块组成: 一个类别无关的掩码生成器,一个词汇内分类器和一个词汇外分类器(参见图2管道之间的比较)。该方法不仅设计简单,而且训练和测试成本都很低。相比之下,我们的模型只有238M的冻结参数和21M的可训练参数。此外,我们的模型训练只需要25.6个V100 GPU天。在推理过程中,我们的模型运行速度也提高了6.6倍。尽管FC-CLIP具有简单的设计,但它在多个数据集上的性能仍然优于以前的方法。仅在COCO全景数据集上训练,FC-CLIP以zero-shot的方式显著超过了先前最先进的ODISE[84]。具体来说,FC-CLIP在ADE20K、Mapillary远景和cityscape上分别达到26.8 PQ(+3.4)、18.2 PQ(+4.0)和44.0 PQ(+20.1)。
相关工作
视觉语言模型 Vision-language models
CLIP [66] 和 ALIGN
封闭词汇分割 Closed-vocabulary segmentation
FCN
实例语义分割 Instance segmentation
Mask R-CNN
DETR
我们提出的方法建立在Mask2Former[19]的像素解码器和掩码解码器的基础上,另外利用了CLIP[66]的开放词汇识别能力。
开放词汇分割 Open-vocabulary segmentation
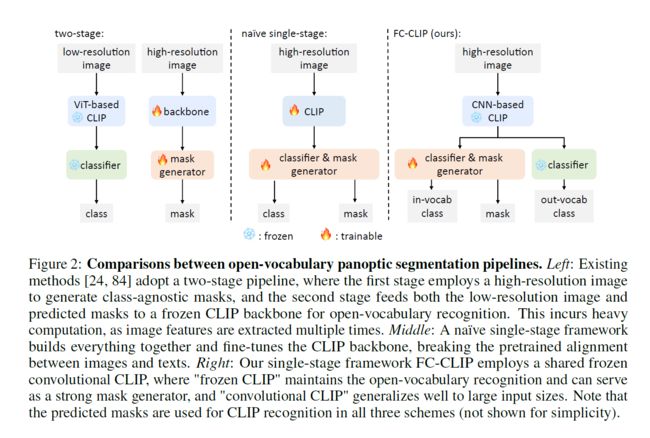
最近,MaskCLIP[24]提出了一种两阶段的管道,它由一个类别无关的掩码生成器和一个用于跨模态校准的冻结CLIP[66]编码器组成,从而将CLIP模型的范围扩展到开放词汇的全视分割
ODISE[84]挖掘了预训练文本-图像扩散模型[68]在表示空间中呈现开放概念以执行强开放词汇全视分割的能力方面的内在潜力。
FreeSeg[65]将多粒度概念编码为紧凑的纹理抽象,使其能够推广到任意文本描述。
我们通过利用单个冻结卷积CLIP骨干提出了单阶段框架,从而产生比现有作品更简单,更快,更强大的模型。
方法

问题定义
开放词汇分割的目的是将图像I∈RH×W×3分割成一组带有相关语义标签的掩码:

K个ground truth masks mi∈{0,1}H×W 包含相应的ground truth class标号ci。在训练过程中,使用一组固定的类标签Ctrain,而在推理过程中,使用另一组类别Ctest。在开放词汇设置中,Ctest可能包含训练中未见的新类别,即Ctrain ≠ Ctest。我们遵循先前的工作[24,84],并假设在测试期间Ctest的类别名称(以自然语言表示)是可用的。
两阶段开放词汇分词
现有作品[85,50,24,84]采用两阶段管道进行开放词汇分词。第一阶段包含一个与类别无关的掩码生成器m,参数为θM,给定输入图像i,它生成一组N个掩码建议{ ^mi}N i=1∈RN×H×W:

在第二阶段,CLIP适配器P接受图像I和掩码提案{{^mi}Ni =1作为输入,其中后者的输入用于引导冻结的CLIP模型CLIP∗(∗表示冻结)。适配器通过forwarding过程进行掩码分类,要么采用masked crop[85,50],要么采用masked attention[24,84]:

其中{{^ci}Ni =1∈rnx |C|表示N个预测掩码的预测类概率,C∈{Ctrain,Ctest}取决于训练或测试阶段,|C|为类别大小。
它有两个局限性。首先,提取两次图像特征,一次用于生成掩码,另一次用于掩码分类。双特征提取会产生大量的计算量,使得主干参数的扩展成本很高。
其次,掩模生成器通常需要高分辨率输入(例如1024×1024),而CLIP模型通常使用低分辨率图像(例如224×224)进行预训练。因此,两阶段管道需要将高分辨率图像馈送到掩模生成器中,并将低分辨率图像馈送到CLIP分类器中,这使得模型效率低下。
这个地方要说明的东西和background 里面一模一样....
简单单阶段开放词汇分割
为了避免增加模型大小和重复特征提取的计算成本,可以naïvely将所有内容一起制定为单阶段框架F,其中掩码生成器和掩码分类器共享相同的CLIP-预训练的骨干CLIP(未冻结),用于从输入图像I中提取特征

FC-CLIP
所提出的FC-CLIP利用冻结的基于cnn的CLIP骨干网的语义特征来生成掩码和进行CLIP分类。与之前的工作[85,50,24,84]不同,之前的工作经常训练一个单独的掩码生成器,忽略了CLIP语义特征的潜在重用,我们将基于cnn的CLIP主干纳入了最先进的分割方法Mask2Former[19]。我们注意到FC-CLIP是一个通用的元架构,可以建立在几种现代分割方法之上[19,89]。我们的方法有几个优点。通过冻结和共享骨干特征,我们的模型在训练和测试期间都显着提高了效率(即避免了特征重复)。基于cnn的CLIP主干不仅可以很好地传输到不同的输入分辨率(从其预训练的图像大小),而且可以生成多尺度特征图,与现代分割方法无缝兼容[19,89]。
在高层次上,FC-CLIP由三个组件组成:与类无关的掩码生成器、词汇内分类器和词汇外分类器。我们将在下面详细介绍每个组件。
Class-Agnostic Mask Generator
继Mask2Former[19]之后,我们使用了一种增强了多尺度可变形注意力的像素解码器[98]来改进从冻结的基于cnn的CLIP主干中提取的特征。增强的像素特征,连同一组对象查询[7,78],然后通过一系列掩码解码器,其中每个掩码解码器由掩码交叉注意[19],自注意[76]和前馈网络组成。通过在对象查询和像素特征之间执行矩阵乘法获得分割logits。通过匈牙利匹配[43],以一对一的方式将预测的掩码与ground-truth掩码匹配,并相应地进行监督。此外,由于对象查询的数量通常大于标记掩码的数量,因此通过此匹配过程只优化了预测掩码的子集。我们不会对剩余的不匹配的提案进行处罚,从而确保获得更多的掩码提案。
In-Vocabulary Classifier
一旦掩码提案被预测,它们将以对比的方式与类别文本嵌入进行分类,其中每个掩码的类嵌入和类别文本嵌入被投影到一个共同的嵌入空间中。也就是说,用词汇内分类器预测的类概率定义如下:∀i = 1,…N

其中,T为可学习的温度参数,初始化为0.07,用于控制分布的清晰度;cos为余弦距离测量值;vi为第i个预测掩码的类嵌入,该掩码是通过掩码池化对来自像素解码器的最终像素特征进行的,类似于[28]。tj是类j的类别名称的文本嵌入,它是通过将类别名称提供给clip预训练的文本编码器而获得的。注意,这些类别文本嵌入只需要生成一次。然后将它们保存在内存中作为文本分类器,因此在训练期间产生的额外成本可以忽略不计。这就形成了我们的词汇内分类器。
Out-of-Vocabulary Classifier
然而,在推理过程中,我们注意到单独使用词汇内分类器无法推广到完全新的未见过的类,因为模型仅在有限的类别集上训练,因此无法识别各种新概念。为了解决这一问题,我们引入了一个词汇外分类器,该分类器将掩码池化应用于冻结的CLIP主干特征,旨在借用CLIP预训练(完整)的开放词汇识别能力。与其他两阶段方法不同[85,50,24,84],其中需要一个或多个CLIP前向处理,所采用的词汇外分类器引入了边际额外成本,因为骨干特征已经被提取(并且只执行轻量级掩码池)。然后,用冻结的CLIP主干特征上的掩码池特征替换vi,以类似于Eq.(6)的方式获得词汇外分类器预测的类概率。该分类器严格保持原有的CLIP特征分布,使我们能够更好地识别全新的类别。注意,词汇表外分类器只在测试期间执行。
Combining In- and Out-of-Vocabulary Classifiers
根据之前的研究[30,28,44,84],我们使用几何集成来融合词汇内和词汇外分类器之间的分类分数。亦即∀j = 1,…, |C |
式中,ci(j)表示ci的第j个元素,下标in和out分别表示词汇内和词汇外分类器。α, β∈[0,1]平衡了词汇内分类器和词汇外分类器对已知类别和未知类别的预测。
实验
结构
我们使用来自OpenCLIP[36]1的ConvNeXt-Large CLIP[56,66]主干在LAION-2B[70]数据集上进行预训练。在CLIP主干之上,我们按照Mask2Former[19]构建掩码生成器。采用9个掩码解码器,以增强的像素特征和一组对象查询作为输入,生成与类别无关的掩码。对于词汇内分类,如下[28],类嵌入是通过掩码池化像素解码器最终输出的像素特征来获得的。然后,通过预测的类嵌入与类别文本嵌入之间的矩阵乘法得到分类逻辑(softmax之前)。
训练策略
我们遵循[19],采用相同的训练配方和损失,没有任何特殊的设计。
使用AdamW[39,59]优化器和权值衰减0.05对训练进行优化。
使用1024 × 1024的裁剪尺寸。
我们采用学习率1 × 10−4和multi-step decay schedule。训练批大小为16,模型在COCO panoptic训练集上训练50 epoch[52]。
推理策略
在推理过程中,输入图像的短边将被调整为800,同时确保长边不超过1333。对于城市景观和Mapillary远景,我们将短边尺寸增加到1024。我们采用掩码合并方案[19]进行掩码预测。词汇外分类器仅在对冻结的CLIP骨干特征进行掩码池化的推理期间执行。最终的分类结果然后通过几何集成词汇内和词汇外分类器[30,28,44,84]获得,如Eq.(7)所示,其中我们默认α = 0.4和β = 0.8。继现有技术之后,我们还采用了来自[28,84]的提示工程和来自[30,50]的提示模板。如果未指定,FC-CLIP仅在COCO panoptic数据集上训练[52]。根据之前的研究[28,84],我们在ADE20K[95]、cityscape[21]和Mapillary远景[62]上对该模型进行了零射击评估,用于开放词汇全视分割。我们还报告了在这些数据集以及PASCAL数据集上的开放词汇语义分割结果[26,61]。用panoptic quality (PQ)[42]、Average Precision (AP)和mean intersection-over-union (mIoU)来评价panoptic分割结果,用mIoU来评价semantic segmentation[26]。请注意,所有结果都是通过仅在COCO全景数据上训练的相同单个检查点获得的。
实验结果

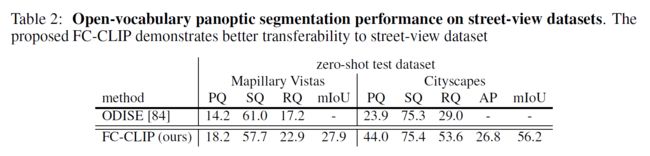
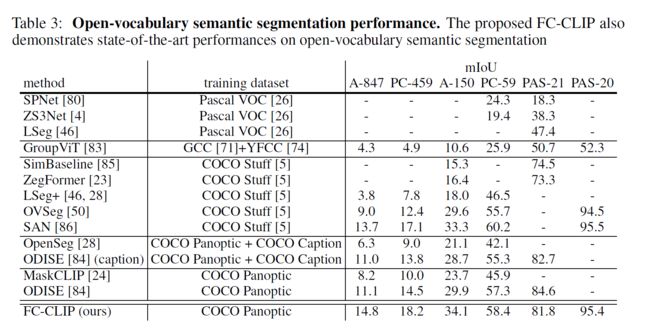



消融实验



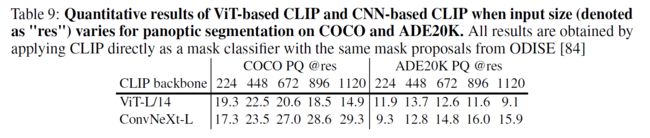
总结
限制
在不久的将来,有一些有趣的研究课题有待探索,例如更好地释放CLIP在掩码分割和分类方面的潜力,如何处理冲突或重叠的词汇表(例如,猫与猫头)等。
它依赖于在互联网数据上预先训练的CLIP模型,这可能有偏见,这需要未来的校准研究,以避免误用。