Java并发包源码学习系列:基于CAS非阻塞并发队列ConcurrentLinkedQueue源码解析
文章目录
-
- 非阻塞并发队列ConcurrentLinkedQueue概述
- 结构组成
-
- 基本不变式
- head的不变式与可变式
- tail的不变式与可变式
- offer操作
-
- 源码解析
- 图解offer操作
- JDK1.6 hops设计意图
- poll操作
-
- 源码解析
- 图解poll操作
- 总结
- 参考阅读
非阻塞并发队列ConcurrentLinkedQueue概述
我们之前花了很多时间了解学习BlockingQueue阻塞队列接口下的各种实现,也大概对阻塞队列的实现机制有了一定的了解:阻塞 + 队列嘛。
而且其中绝大部分是完全基于独占锁ReentrantLock和条件机制condition实现的并发同步,但基于独占锁的实现较重量级,可能会引起上下文切换和线程调度,性能上有一定欠缺。比如:ArrayBlockingQueue、LinkedBlockingQueue等等。
- Java并发包源码学习系列:阻塞队列实现之ArrayBlockingQueue源码解析
- Java并发包源码学习系列:阻塞队列实现之LinkedBlockingQueue源码解析
- Java并发包源码学习系列:阻塞队列实现之PriorityBlockingQueue源码解析
- Java并发包源码学习系列:阻塞队列实现之DelayQueue源码解析
在我们印象中,有几个具有transfer特性的队列为了性能,会优先考虑自旋,采用CAS非阻塞算法,自旋到一定程度呢,才采取阻塞,比如:SynchronousQueue、LinkedTransferQueue等等,原理上是基于CAS原子指令提供的轻量级多线程同步机制。
- Java并发包源码学习系列:阻塞队列实现之SynchronousQueue源码解析
- Java并发包源码学习系列:阻塞队列实现之LinkedTransferQueue源码解析
而我们今天要学习的这个ConcurrentLinkedQueue并没有实现BlockingQueue接口,是一个完完全全使用CAS操作实现线程安全的、无界的非阻塞队列。

结构组成
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E>
implements Queue<E>, java.io.Serializable {
private static final long serialVersionUID = 196745693267521676L;
/**
* The fundamental invariants are:
* - There is exactly one (last) Node with a null next reference,
* which is CASed when enqueueing. This last Node can be
* reached in O(1) time from tail, but tail is merely an
* optimization - it can always be reached in O(N) time from
* head as well.
* - The elements contained in the queue are the non-null items in
* Nodes that are reachable from head. CASing the item
* reference of a Node to null atomically removes it from the
* queue. Reachability of all elements from head must remain
* true even in the case of concurrent modifications that cause
* head to advance. A dequeued Node may remain in use
* indefinitely due to creation of an Iterator or simply a
* poll() that has lost its time slice.
*/
private static class Node<E> {
volatile E item; // 值
volatile Node<E> next; // next域
Node(E item) {
// 构造节点,保证线程安全
UNSAFE.putObject(this, itemOffset, item);
}
/* ----- 内部使用UNSafe工具类提供的CAS算法 ----- */
// 如果item为cmp, 改为val
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
// 将next设置为val
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
// 如果next为cmp, 将next改为val
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
/**
* A node from which the first live (non-deleted) node (if any)
* can be reached in O(1) time.
* Invariants:
* - all live nodes are reachable from head via succ()
* - head != null
* - (tmp = head).next != tmp || tmp != head
* Non-invariants:
* - head.item may or may not be null.
* - it is permitted for tail to lag behind head, that is, for tail
* to not be reachable from head!
*/
private transient volatile Node<E> head;
/**
* A node from which the last node on list (that is, the unique
* node with node.next == null) can be reached in O(1) time.
* Invariants:
* - the last node is always reachable from tail via succ()
* - tail != null
* Non-invariants:
* - tail.item may or may not be null.
* - it is permitted for tail to lag behind head, that is, for tail
* to not be reachable from head!
* - tail.next may or may not be self-pointing to tail.
*/
private transient volatile Node<E> tail;
// 无参构造,初始化将head和tail指向item为null的哨兵节点
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
// 指定初始容量
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
for (E e : c) {
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
t.lazySetNext(newNode);
t = newNode;
}
}
if (h == null)
h = t = new Node<E>(null);
head = h;
tail = t;
}
}
在ConcurrentLinkedQueue非阻塞算法实现中,head/tail并不是总是指向头/尾节点,也就是说允许队列处于不一致状态,优点是:把入队/出队原本需要一起原子化执行的两个步骤分离,从而缩小入队/出队时需要原子化更新值的范围到唯一变量,这是非阻塞算法得以实现的关键。
由于队列有时会处于不一致的状态,为此ConcurrentLinkedQueue 提供了3个不变式来维护非阻塞算法的正确性,分别是:基本不变式、head的不变式和tail的不变式。
不变式是指: 并发对象的各个方法之间必须遵守的”契约”,每个方法在调用前和调用后都必须保持不变式。采用不变式,就可以隔离的分析每个方法,而不用考虑它们之间所有可能的交互。
基本不变式
- 当入队插入新节点之后,队列中有一个next域为null的(最后)节点。
- 从head开始遍历队列,可以访问所有item域不为null的节点。
head的不变式与可变式
不变式
- 所有存活的节点,都能从head通过调用succ()方法遍历可达。
- head不能为null。
- head节点的next域不能引用到自身。
可变式
- head节点的item值可能为null,也可能不为null。
- 允许tail之后与head,也就是说:从head开始遍历队列,不一定能达到tail。
tail的不变式与可变式
不变式
- 通过tail调用succ()方法,最后节点总是可达的。
- tail不能为null。
可变式
- tail节点的item域可能为null,也可能不为null。
- 允许tail滞后于head,也就是说:从head开始遍历队列,不一定能到达tail。
- tail节点的next域可以引用到自身。
offer操作
源码解析
offer操作将会将元素e【非null】加入到队尾,由于无界队列的特性,这个操作将永远不会返回false。
public boolean offer(E e) {
// 检查元素是否为null,为null就抛空指针
checkNotNull(e);
// 构造新节点
final Node<E> newNode = new Node<E>(e);
// 【1】for循环从tail开始迭代
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
// 【2】q == null 说明是p是尾节点
if (q == null) {
// 【3】
// cas将p的next设置为newNode,返回true
// 如果设置失败,说明有其他线程修改了p.next
// 那就再次进入循环
if (p.casNext(null, newNode)) {
// 【4】
// 这里tail指针并不是每次插入节点都要更改的,从head开始第奇数个节点会是tail
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
//【5】
else if (p == q)
// 并发情况下,移除head的时候【比如poll】,将会head.next = head
// 也就满足p == q 的分支条件, 需要重新找到新的head
p = (t != (t = tail)) ? t : head;
//【6】
else
// 表明tail指向的已经不是最后一个节点了,更新p的位置
// 这里其实就是找到最后一个节点的位置
p = (p != t && t != (t = tail)) ? t : q;
}
}
图解offer操作

上面是模拟的单线程情况下的offer一个元素的操作,可以看到:
- 初始化head、tail都指向了item为null的哨兵节点,他们的next指向null。
- 单线程情况下,我们暂时认为CAS操作都是执行成功的,此时q为null,将会走第一个分支【2】,将p的next指向newNode,此时p==t,因此不会执行【4】casTail操作,直接返回true。
多线程情况下,事情就不是这么简单了:
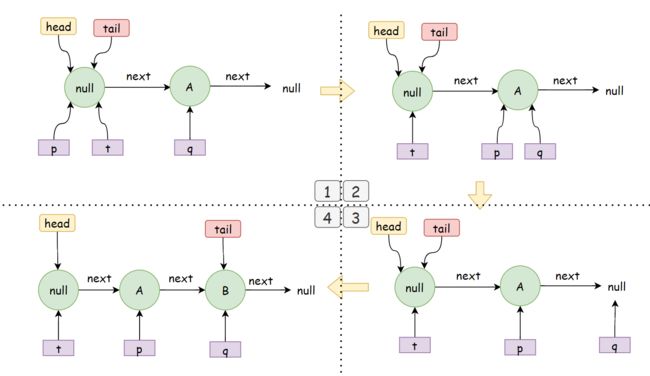
- 加入线程A希望在队尾插入数据A,线程B希望在队尾插入数据B,他们同时到了【3】
p.casNext(null, newNode)这一步,由于casNext是原子性的,假设A此时设置成功,且p == t,如图1。 - A成功,自然B线程cas设置next失败,那么将会再次进行for循环,此时
q != null && p != q,走到【6】,将p移动到q的位置,也就是A的位置,如图2。 - 再次循环,此时
q==null,再次进行【3】的设置next操作,此时假设B成功了,如图3。 - 此时你会发现,tail需要重新设置了,因为
p != t条件满足【4】,将会执行casTail(t, newNode),将tail指针指向插入的B。
相信一通图解 + 源码分析下来,你会慢慢对整个流程熟悉起来,稍微总结一下:
offer操作其实就是通过原子CAS操作控制某一时刻只有一个线程能成功在队尾追加元素,CAS失败的线程将会通过循环再次尝试CAS操作,直到成功。
非阻塞算法就是这样,通过循环CAS的方式利用CPU资源来替代阻塞线程的资源消耗。
并且,tail指针并不是每次都是指向最后一个节点,由于自身的机制,最后一个节点要么是tail指向的位置,要么就是它的next。因此定位的时候,这里使用p指针定位最后一个节点的位置。
对了,你会发现,在整个过程中,【5】操作一直没有涉及到,其实【5】的情况会在poll操作的时候可能会发生,这里先举个例子吧:

图一是poll操作可能会导致的情况的一种,以他为例子:此时tail节点指向弃用的节点,此时向队列中offer一个元素。
- 此时,执行到【2】处,各个指针的指向如图1。
- 接着由于q不为null,且p == q,顺利进入【5】,这时p被赋值为head,如图2。
- 再次循环,q指向p.next,此时为null,如图3。
- q为null,进入【2】,和之前一样,【3】设置next,此时【4】
p != t,设置新节点为新的tail,如图4。
JDK1.6 hops设计意图
在看源码注释的时候,我发现很多处都对hop这个玩意进行了注释,原来JDK1.6的源码中确实有它的存在:聊聊并发(六)ConcurrentLinkedQueue的实现原理分析,并且设计的理念还是一样的,用hops控制tail节点的更新频率,提高入队的效率。
引用《Java并发编程的艺术》方腾飞 :
减少CAS更新tail节点的次数,就能提高入队的效率,所以doug lea使用hops变量来控制并减少tail节点的更新频率,并不是每次节点入队后都将 tail节点更新成尾节点,而是当 tail节点和尾节点的距离大于等于常量HOPS的值(默认等于1)时才更新tail节点,tail和尾节点的距离越长使用CAS更新tail节点的次数就会越少,但是距离越长带来的负面效果就是每次入队时定位尾节点的时间就越长,因为循环体需要多循环一次来定位出尾节点,但是这样仍然能提高入队的效率,因为从本质上来看它通过增加对volatile变量的读操作来减少了对volatile变量的写操作,而对volatile变量的写操作开销要远远大于读操作,所以入队效率会有所提升。
private static final int HOPS = 1;
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
Node<E> n = new Node<E>(e);
retry:
for (;;) {
Node<E> t = tail;
Node<E> p = t;
for (int hops = 0; ; hops++) {
Node<E> next = succ(p); // 1.获取p的后继节点。(如果p的next指向自身,返回head节点)
if (next != null) { // 2.如果next不为null
if (hops > HOPS && t != tail)
continue retry; // 3.如果自旋次数大于HOPS,且t不是尾节点,跳出2层循环重试。
p = next; // 4.如果自旋字数小于HOPS或者t是尾节点,将p指向next。
} else if (p.casNext(null, n)) { // 5.如果next为null,尝试将p的next节点设置为n,然后自旋。
if (hops >= HOPS)
casTail(t, n); // 6.如果设置成功且自旋次数大于HOPS,尝试将n设置为尾节点,失败也没关系。
return true; // 7.添加成功。
} else {
p = succ(p); // 8。如果第5步尝试将p的next节点设置为n失败,那么将p指向p的后继节点,然后自旋。
}
}
}
final Node<E> succ(Node<E> p) {
Node<E> next = p.getNext();
//如果p节点的next节点指向自身,那么返回head节点;否则返回p的next节点。
return (p == next) ? head : next;
poll操作
poll操作将在队头出队一个元素,并返回,如果队列为空,则返回null。
源码解析
public E poll() {
// 【1】continue xxx;会回到这
restartFromHead:
// 【2】死循环
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// 【3】如果当前 有值, 就cas操作置null
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
// 【4】
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// 【item == null】 或 【item != null 但是 cas失败了】
// 【5】队列为空, 返回null
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
// 【6】
else if (p == q)
continue restartFromHead;
// 【7】
else
p = q;
}
}
}
final void updateHead(Node<E> h, Node<E> p) {
// h == p 其实就不需要更新了,否则更新head为p,更新成功了,将h.next指向h本身
if (h != p && casHead(h, p))
h.lazySetNext(h);
}
图解poll操作
先来看看最简单的情况:
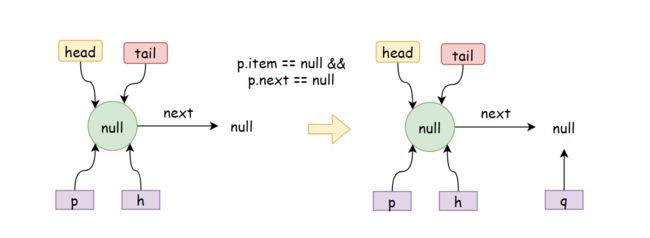
初始情况下,head和tail指向item为null的哨兵节点,此时假设某个线程执行poll操作,从head开始迭代:此时,p.item == null && p.next == null,将走到【5】这一分支,进行updateHead,此时p!=h,也就是直接返回null了。
如果此时走到【5】分支时,正好有另一个线程向队列中添加了元素,这时情况如下:

- 指针q将指向新插入元素的位置,此时【5】位置
q != null,接着走【6】发现p != q,【6】也走不进去。 - 最后走到【7】,将p指向q节点位置。
- 再次进入循环,走到分支【3】,此时item不为null,尝试cas设置item为null,假设设置成功后,此时条件【4】成立,
p != h,设置p为head,使h指向自身,最后返回p的值。
你会发现,最终得结果,就是我们之前在分析offer操作时出现的一种情况,也就是offer的时候,发现tail.next = tail。
接着,我们可以看到,在poll中,也同样存在类似的判断,也就是【6】的代码,判断p == q,同理也是类似的,下面有紫色表示线程A,蓝色表示线程B。

- 假设线程A执行poll操作时,当前队列状态如图1。
- 如图2,此时p通过cas操作将A设置为null。
- 此时p != h,将会执行updateHead操作,在此之前,如果正好线程B开始poll,如图3。
- B线程就会进走到【6】,跳到restartFromHead,寻找当前队列的head,如图4。
poll一个元素的时候,将会使用CAS操作将当前节点的item值设置为null,并CAS设置head,将移除的节点指向自己,使得被垃圾回收。
整个循环过程中,不断检测并发情况,如果发现头节点被修改,将会跳出循环,重新获取新的head。
总结
ConcurrentLinkedQueue是一个使用CAS操作实现线程安全的、无界的非阻塞队列,基于链表。
链表的头尾节点为volatile修饰,保证在多线程环境下的出队入队操作的安全性,volatile自身保证可见性,原子性由CAS操作保证。
设计上,非阻塞算法允许队列处于不一致状态,比如tail指针并不是每次都指向最后一个节点,最后一个节点可能是tail,也可能是tail.next,这个特性分离了入队/出队操作中包含的两个需要一起原子执行的步骤,从而有效地缩小了入队/出队时的原子化范围的唯一变量。针对不一致,使用三个不变式来维护非阻塞算法的正确性。
对volatile变量的写操作开销要远远大于读操作,因此,额外增加了遍历队列、寻找头/尾节点的开销【增加volatile读的开销】,但是因为不需要每次操作都CAS更新head/tail【减少volatile写的开销】,提升入队效率。
参考阅读
-
《Java并发编程之美》
-
《Java并发编程的艺术》
-
非阻塞算法在并发容器中的实现
-
聊聊并发(六)ConcurrentLinkedQueue的实现原理分析
-
Jdk1.6 JUC源码解析(24)-ConcurrentLinkedQueue