记一次Android概率性定屏问题分析解决路程
记一次Android概率性定屏问题分析解决路程
前言
最经一个同事遇到了概率性定屏的问题,询问我有没有解决过类似的问题,这不得让我想起了前同事解决概率行定屏问题留下来的宝贵文档,下面我就把前同事的文档关键的内容整理奉上,希望对概率性定屏问题有帮助。
一.问题描述
客户的机器在交易过程中出现定屏,出现过如下三种现象:
定屏1:按虚拟键有背景色,无法响应任何触摸事件,音量键无作用,power键有作用,ADB能连;
定屏2:按虚拟键无背景色,power键有作用,ADB能连;
定屏3:power键都无作用,ADB能连;
根据描述可见,如上三个现象,严重程度递增;
二.原因分析
- 1.复现并初步总结现场log,缩小可疑范围
根据现场抓取到的logcat信息可以判断,客户的launcher应用经常性出现native crash,这说明客户launcher应用是有问题的;由表面现象显示,根据严重程度看有多种情况,不排除仅仅只是应用界面卡死,故需要加大测试力度,增加复现概率,抓取log,分类总结各根因;拿了多台机器跑monkey测试,忽略native crash:
adb shell monkey -p com.ums.tss.mastercontrol -s 500 --ignore-crashes --ignore-timeouts --ignore-native-crashes -v 500000000 &
至少5台机器一起测试,基本一两天能复现出一台机器;
其中一种情况,杀掉master应用可以恢复,通过am命令可以跳转到别的界面,进一步说明客户应用存在缺陷,由于不是系统问题,此问题不重点关注;但是,另外那种情况,应用不应该引起系统定住,出现这种现象只能拔电池,这个用户体验非常差,再说第三方应用也无法保证质量,crash几次也难免,所以这是个非常严重的问题,需要进一步查找系统缺陷的根因
在monkey测试复现的机器上,做如下实验,进一步缩小问题范围:
getevent 触摸事件有值,说明触摸上报无问题
开发者选项中打开触摸调试,现象分为两种:触摸屏幕能出现背景圆球,以及不出现背景圆球
通过adb shell,敲命令stop,start,只重启zygote而不重启kernel,问题消失;
通过adb shell,执行/system/bin/bootanimation开机动画动作,虽然无法正常动画,但界面可变化
执行 am start -n com.android.launcher/com.android.launcher2.Launcher
跳转,命令卡死,AMS等关键服务、InputReader、InputDispatcher都是 system_server 启动的核心子线程,重点关注system_server,需要进一步根据log判断情况
从log看,system_server出现ANR,WindowManager: Input event dispatching timed out;
起初怀疑 从 InputReader到InputDispatcher再到响应显示链路出现问题,但从常规logcat中得不到任何线索,看来input timeout只是问题的结果和现象,而不是根因;
怀疑system_server各子线程出现死锁,关注anr的关键log:traces.txt;搜索held by/ waiting/locked等关键字,现场log有限,并无明显死锁的异常;
但其中一份 现场bugreport,引起了注意,system_server有明显死锁,ActivityManagerService的锁在执行 sendDeathNotice 时被拿住了,很多线程都在等它
而其余情况下有些bugreport抓取log失效;log现象都是Input event dispatching timed out,monkey是否跟客户遇到的问题一致?还不得而知
仍然需要自力更生,加大自测复现概率和抓取更多有用信息;而大量的看起来有点疑问实际却无效的log,扰乱了分析思路,遮蔽了真实根因
由于复现时常常出现在输入法界面,怀疑第三方输入法调用系统api引起了一些兼容性问题,删掉输入法,确实概率变低,但是即使不是客户环境,monkey测试仍然出现过此问题,看来还需进一步分析
由于情况复杂,总结搜集了如下一些重要log及调试手段,需要根据出现问题的时间点,仔细分析大量的log细节:
adb shell "ps | grep ' Z '" > 201706211748/ps_Z.txt
adb shell "ps | grep ' t '" > 201706211748/ps_T1.txt
adb shell "ps -t | grep ' D '" > 201706211748/ps_t_D.txt
adb pull /sdcard/HiLogcat 201706211748/HiLogcat
adb shell logcat -v threadtime -d *:v > 201706211748/logcat.txt
adb shell logcat -b events -v threadtime -d *:v > 201706211748/logcat_events.txt
adb shell dmesg > 201706211748/dmesg.txt
adb pull /data/anr ./201706211748/anr
adb pull /data/tombstones ./201706211748/tombstones
adb pull /data/system/dropbox ./201706211748/dropbox
adb shell ls -lsa /data/anr/" > ./201706211748/ll.txt
adb shell ls -lsa /data/tombstones/ >> ./201706211748/ll.txt
adb shell ls -lsa /data/system/dropbox/ >> ./201706211748/ll.txt
adb shell "debuggerd -b 829" > ./201706211748/debuggerd_sysserv.txt
adb shell "kill -3 829"
adb pull /data/anr ./201706211748/anr2
adb shell "echo t > /proc/sysrq-trigger"
adb shell "cat /proc/kmsg" > ./201706211748/kmsg_trigger.txt
adb shell dumpstate > ./201706211748/dumpstate.txt
adb shell dumpsys > ./201706211748/dumpsys.txt
adb pull /system/build.prop ./201706211748/build.prop
adb bugreport > ./201706211748/bugreport.txt其中 echo t > /proc/sysrq-trigger 能看到kernel的线程函数栈,针对死锁问题很有帮助;kill -3 pid可以得到关注应用空间调用栈,而debuggerd 也可以分析关注的进程栈
- 2.定位到debuggerd机制出了问题
分析monkey测试复现机器的log结果,重点关注分析 traces.txt、bugreport;而system_server、watchdog、ActivityManager等线程的锁的持有情况也是重点关注对象,出现了一些转机,发现 ActivityManagerService锁都被持有,执行am命令都无反应,只要执行am命令,再把traces.txt导出来,之前没有死锁的都会出现明显死锁;
而通过其中的debuggerd -b pid调试手段去看函数调用栈时出现了最大的疑点,debuggerd 无反应!这时候怀疑android的debug机制有bug,于是想办法证明是否如此,总结规律,发现问题都是出现在native crash的时候,且NativeCrash线程出现异常,NativeCrashListener: Exception dealing with report;而ps | grep D发现,有一台机器debuggerd一直D状态,而有台机器debuggerd也一直睡眠,睡在connect连接上,直觉认为,要解决此问题,需要详细了解debuggerd调试机制,山路十八弯,终于要峰回路转了,实验也确实有方向了
拿了两台出问题的机器,由于debuggerd只是调试使用,删掉system/bin/debuggerd进程,也不会影响正常行为,测试了三四天,都不再出现问题;只不过tombstone不再有了,影响debug crash,但这也不会影响实际出货的机器,这也不失为一种解决方案;
那debuggerd到底哪里出现了问题呢?删掉debuggerd总觉得不那么完美,毕竟还得使用debug手段看一些现场,根因还得继续查找
ps -t | grep " t "发现,客户应用,即“master”关键字的两个线程处于被调试状态,而出问题后,/data/tombstone/ 目录的内容不再变化,关注最后时间点的tombstone,它比前面正常的内容要少!最后时间节点的一份tombstone,master很多子线程tombstone信息都没得到输出;都是卡在最后一个t调试状态的master子线程上!
这充分说明了,debug机制确实出现了问题,在输出native crash的dump内容时,系统卡死在一个进程调试状态了,那么就只能分析理顺一下debug的流程吧;
先理一下框架层的crash机制:
1、system_server启动AMS,AMS会创建一个子线程如“Thread-XX”,专门侦听crash,然后保存tombstone,让系统(AMS)做些善后处理,进而杀掉此进程的所有线程,调用流程是:
NativeCrashListener.run-->consumeNativeCrashData-->NativeCrashReporter-->handleApplicationCrashInner-->crashApplication-->killProcess
2、“Thread-XX”是通过什么方式知道发生crash的呢?原来它创建了一个 "/data/system/ndebugsocket" sock,它做为服务端,accept等待侦听 debuggerd进程连接与消息;
3、debuggerd是init进程启动的本地守护进程,它是“Thread-XX”的客户端,那它怎么知道发生了native crash呢?这个得从linux信号通信机制和android的调试机制说起,由于这里非常复杂,只简要说一下:android修改了boinic c/c++库函数的linker,在加载so的过程中,即设置了进程的android信号处理函数,拦截了SIGSEGV等信号进行处理,这个信号处理函数,通过一个名叫"android:debuggerd"的sock连接到debuggerd进程;原来,信号处理函数做为此sock的客户端,而debuggerd作为服务端;
4、综上所述,源头都是程序的段错误信号SIGSEGV,它的出现,使进程执行信号处理函数,连接debuggerd,而debuggerd一方面做为 "android:debuggerd" sock即信号处理函数的服务端,另一方面,它完成一次跟信号处理函数的连接后,又进一步作为“Thread-XX”的客户端,读取crash现场信息,传给“Thread-XX”做tombstone保存;debuggerd是把SIGSEGV信号通知给system_server的桥梁;
5、上述的过程涉及的主要源码在如下几个文件:
NativeCrashListener.java (frameworks\base\services\core\java\com\android\server\am)
Linker.cpp (bionic\linker)
Debuggerd.cpp (system\core\debuggerd)
Tombstone.cpp (system\core\debuggerd)
知道了上述的大致流程,再去总结到底哪里出了问题?
同时上网搜索debuggerd,发现也有人遇到过类似的问题:
http://blog.csdn.net/ffmpeg4976/article/details/48666265
框架的这个流程中,会出现一些异常情况是android没考虑到的:“Thread-XX”和debuggerd的sock连接,如果服务端异常情况,那么客户端有可能阻塞在connect上;那么在debuggerd的处理流程中,加上超时机制,使之出现问题时不要一直阻塞;而NativeCrashListener在异常时,删掉sock,debuggerd自然也不会阻塞;
- 3.继续查debuggerd阻塞的另一种情况:D状态
这样修改代码后,以为不会再出现,测试了好几台机器,三天下来,都没出现,但没想到持续测试,虽然降低了概率,却又出现了定屏,这时候,发现debuggerd 就一直D状态,本来就一直疑惑为什么debuggerd 时常是D状态,看来还得继续往下查这个D状态;
这只能深入到linux内核,详细摸清debuggerd 跟信号处理函数的sock连接,对照代码,总结出如下流程:
1、客户应用master 进程发生native crash,也就是段错误,这个会让内核产生 SIGSEGV 信号;
2、被 bionic 的 linker 设置的 信号处理函数拦截 SIGSEGV,信号处理函数会通过sock 连接 debuggerd 守护进程;让debuggerd 做crash动作;
3、debuggerd初始化时,先保证自身忽略所有信号,accept 等候 master 发来的 crash消息,这个当然等到了,之后通过系统调用 ptrace 的 PTRACE_ATTACH 操作进入内核,先建立与 master 进程的调试关系,(ptrace系统调用返回之后会关闭与信号处理函数之间的sock,之后进入后续处理循环);
4、在内核 PTRACE_ATTACH 期间,debuggerd 把自己设置为 master 的父进程;并调用 send_signal 发送强制终止信号给master,这个过程中,会调用 signal_wake_up 唤醒 master 进程,在ptrace系统调用返回时,可能进行调度;
5、debuggerd继续运行,进入D状态,调用 wait_on_bit 等待bit19/21标志位清零来唤醒自己;此时,整个过程,一个master进程的 SIGSEGV信号,引发了 debuggerd 进入D状态;等待 JOBCTL_TRAPPING 清零唤醒
6、在进行调度时,会进入到master的信号处理,在内核信号分发时使master进程修改为 stop 状态,以方便被跟踪调试;
7、在内核中master线程的上下文中,处理master的信号时,get_signal_to_deliver会依次调用 do_signal_stop do_jobctl_trap ptrace_signal ,都会调用到 ptrace_stop ,之后再退出函数循环;
如果不是被调试,则原本准备好信号处理函数的环境后,进入到用户空间信号处理函数,处理完再返回内核善后再进入用户空间,
但由于是被调试状态,ptrace_stop会让master暂停,并唤醒调试进程 debuggerd ,然后schedule出去;
8、debuggerd 从D唤醒得到运行,得到一些master进程的状态后,从ptrace系统调用返回到用户空间,通过 sock 写个ack给master 的 boinic 信号处理函数
9、debuggerd继续运行,也通过sock连接到AMS,保存master的tombstone信息,之后再次调用ptrace系统调用,通过PTRACE_DETACH 解除与master的调试关系,使之继续运行;
10、master 进程的boinic信号处理函数从sock读取到ack回复消息;之后设置信号的处理方式为默认处理方式;杀死自己;并且发送 SIGSTOP 信号给全组线程;然后退出了信号处理函数;
11、由于master的子线程都会收到信号,继续上面的处理循环,把子线程的tombstone信息都保存起来
这个流程非常复杂,需要深入到内核的信号机制、跟踪调试机制,详细了解kill & ptrace两个系统调用的处理流程,同时涉及一些CPU体系结构的细节,有兴趣的可以通过“LINUX内核源代码情景分析.PDF”详细了解,涉及的主要文件有:
Signal.c (kernel)
Ptrace.c (kernel)
Signal.c (arch\arm\kernel)
Ptrace.c (arch\arm\kernel)
为了便于分析问题,引入了手动crash内核,保存内存镜像,通过crash分析内存来调试内核的方法,这是分析内核的利器;
- 4.使用crash工具分析内核ptrace系统调用的阻塞情况
先介绍一下crash工具的常见命令:
启动crash工具:./crash DDRCS0.BIN@0x80000000 vmlinux
crash> help //帮助命令,显示出crash支持的命令
crash> log //打印dmesg
还有 bt whatis rd task struct list kmem dis p mach ps foreach 等命令,不一一介绍了,分析时都会有用到
上述第3节介绍了debuggerd睡在一个标志位上,即wait_on_bit(&task->jobctl, JOBCTL_TRAPPING_BIT ,ptrace_trapping_sleep_fn, TASK_UNINTERRUPTIBLE);
睡在这个JOBCTL_TRAPPING_BIT标志位上的线程,会通过如下代码唤醒:
void task_clear_jobctl_trapping(struct task_struct *task)
{
if (unlikely(task->jobctl & JOBCTL_TRAPPING)) {
task->jobctl &= ~JOBCTL_TRAPPING;
wake_up_bit(&task->jobctl, JOBCTL_TRAPPING_BIT);
}
}
它对应的ptrace系统调用睡眠的代码:
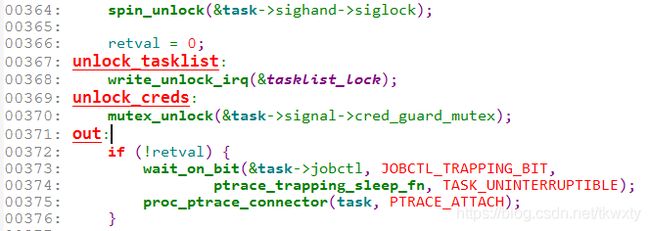
ptrace调用过程:

debuggerd调用ptrace,ptrace会通过信号机制,发送信号给要调试的线程master,master的信号处理过程,又会调用 ptrace_stop--> task_clear_jobctl_trapping,再唤醒debuggerd,大致流程就是这样;
通过crash也可以看出:
先找出处于调试态的线程,和处于D状态的debuggerd 线程号

![]()
打印debuggerd/30403的函数调用栈
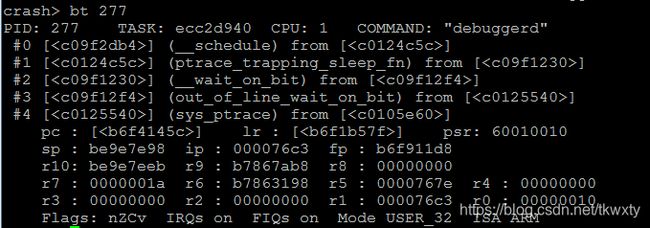

正常情况下,30403线程schedule出去时,会把debuggerd 从D状态唤醒,现在问题就是,为什么debuggerd没有被唤醒呢?
&task->jobctl变量会不会产生竞态呢?从代码可以看到,它都通过了spin_lock_irq(&sighand->siglock);锁的保护;
通过 task -x 30403 命令查看&task->jobctl等变量,状态都对:

是否还有种可能,ptrace系统调用在执行wait_on_bit时,刚好判断完这个标志,正准备schedule时就被调度出去了,然后master线程进入内核的信号处理流程,把这个变量&task->jobctl的JOBCTL_TRAPPING位修改了,调用了task_clear_jobctl_trapping-->wake_up_bit,却白操作了,因为这时候debuggerd还没睡;再回到debuggerd时,调用schedule睡眠;但master线程因为JOBCTL_TRAPPING位已经为0,就再也调不到wake_up_bit了!
也一度怀疑,是否jobctl变量的值缓存在寄存器中未刷新,导致没有调用到wake_up_bit
还是通过dis -l 反汇编命令看看这些函数的情况吧

上述r0是第一个参数,即struct task_struct *task;通过struct 命令,偏移0x270就是&task->jobctl,这样确实可以看到task 30403 的JOBCTL_TRAPPING 标志位用str指令清零了

通过ps可以看出,debuggerd在cpu1上,master及其子线程在cpu0上,那会不会是因为多cpu并发导致的呢?以及各cpu有硬件cache机制,且执行指令有流水线,这边cpu0写进去了,实际那边cpu1在wake_on_bit时取到的还是老值,这样分析,我觉得是有可能的;

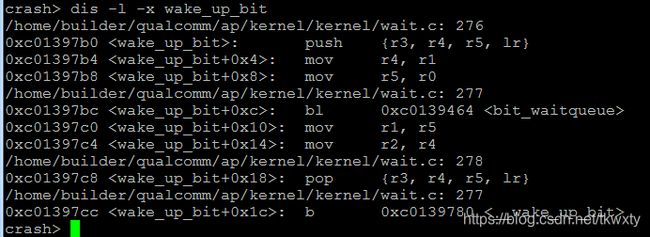
于是拿来了展讯的代码,signal.c看了下,发现展讯的代码在修改&task->jobctl后,调用了 smp_mb();内存屏障操作,再调用wake_up_bit,这样就能消除上面的竞态;代码修改如下:

这样修改之后,再行测试,debuggerd 不再长期处于D状态了;再也没出现过这种定屏问题了
同时,我也屏蔽了if判断,只要进到此函数,都调用wake_up_bit,再做测试,也没出现过定屏,如下:

因为此函数会进来多次,错过了一次,后面能“补刀”,防止再出现问题;
三.总结
此问题解决办法:
1、删掉debuggerd,即禁止掉android的native crash调试机制;这样缺点是native crash调试现场抓不到,不利于分析一些问题
2、修复android框架及kernel中的漏洞;
经验教训:
1、遇到低概率问题,想办法复现问题,则离解决问题就近了一半,比如此问题,发现了native crash时才会触发,那就想办法产生更多的native crash,发现装上豌豆荚,很容易出现native crash;营造复现环境;
2、丰富调试手段,比如bugreport,debuggerd,sysrq_trigger,crash
3、此问题涉及了android和linux的核心机制,必须理顺代码流程,将疑点追查到底,方可解决问题;
最后不得不佩服前同事个人技术能力的强悍,给点个赞。