C语言中 . -> & * ** typedef符号或操作符的用法
1. 结论
大家在看数据结构清华版书时,经常会被里面的 * . -> typedef c语言 c++的切换看的云里雾里,运行里面伪代码经常很困扰,网上也大多把c语言和c++看成一起混合编译处理,导致大家单纯想理解c语言造成很多困扰,下面这篇文章仅针对于c语言详细说明上面几个符号的用法,帮助大家理解纯c代码。
先说结论,在C语言中,对于一个结构体类型变量a
a.next
(&a)->next上面两种写法是等价的
2. 变量名、地址和多级指针
int a = 1;对于上面这段代码
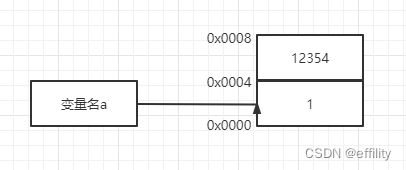
可以看成在操作系统内部做了上图的操作,首先,创建了一块内存大小为4个字节,首地址0x0000,结束地址为0x0004,对于编译器来说,该内存与变量名a绑定,通过变量名a,编译器能够知道变量类型为int,为什么叫对于编译器来说呢?因为在程序实际运行的过程中,a对于该程序的运行是没有任何意义的,里面可能存储的是 (0x0000)=4类似的语句,变量名a只是为了方便给人看的。
c语言是允许读取和操作地址的,就有以下语句
int* ptr_a = &a;对于上面这段代码
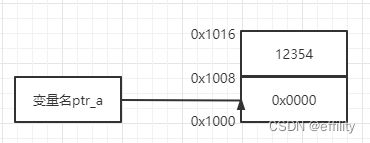
用到了两个操作符* 和 &
&符的含义就是拿到一个变量的地址位置,上面这段代码中 &a 的意思就是拿到a的地址
int*的意思就是申请一个int类型变量的指针,该指针可以存储int类型变量的地址,可以把int*看成一个整体,类似于基本变量int float等,整段代码的意义就是
通过int* 申请一个int类型的指针变量ptr_a来存储a变量的地址
ptr_a变量里面存储的是变量a的地址0x0000
*操作:拿到对应地址的值
当通过*(addr)操作时,能够得到内存地址里面的值
*ptr_a == 1;如上,当*操作ptr_a里面的值时,就能拿到ptr_a地址里面的值
*(0x0000) = 1,就是拿0x0000地址里面的1
不难显出,ptr_a也是一个变量,也具有地址
int** ptr_ptr_a = &ptr;上述代码中,可以把int**看成一个整体,来声明一个int**类型的指针,里面存储int*类型的地址(type类型的指针变量是type* type*类型的指针变量是type** 可以这么简单的认为)
对于ptr_ptr_a,有一级访值(*)和二级访值操作(*)
*操作:
得到ptr_ptr_a地址的值
*ptr_ptr_a
也就是
*(0x1000) = 0x0000
**操作
**ptr_ptr_a
可以看作是*(*ptr_ptr_a)),
就是*(*(0x1000)) = *(0x0000) = 1
这就是二级指针的作用,多级指针的使用方式类推。毕竟,一生二,二生万物
3. ->和. 箭头操作符和点操作符的区别
在讨论->和.操作符的区别之前,我们先简单回顾以下结构体的定义
// 节点结构体定义
struct LNode{
Elemtype data;//数据域,存储数据
struct LNode *next;//指针域,存储指针,存放后继节点信息
};
// 一般结构体定义模板
struct structName{
.....
};通过操作符struct来定义结构体,需要注意的是struct和LNode是一个整体,并不像变量声明
int a = 1;这种int和a是分开的
struct LNode类似于int,struct LNode共同决定这个结构体类型
当然,声明结构体类型变量就可以使用以下方式
struct LNode l1;上述声明了一个struct LNode类型的变量l1
使用 LNode l1;这种方式声明是错误的,因为变量类型是struct LNode
这样通过两个操作符来声明变量的方式很麻烦,能不能值使用一个操作符来声明呢,当然可以,c语言中有typedef操作符来进行类型的替换,格式为
typedef 源格式 目标格式
typedef struct LNode LNode1;此时LNode1就等价于Struct LNode
struct LNode l1;
LNode1 l2;上述两个变量的声明就有了相同的意义,当然,也可以在结构体定义的时候直接使用typedef
typedef struct LNode{
Elemtype data;//数据域,存储数据
struct LNode *next;//指针域,存储指针,存放后继节点信息
}LNode1;结构体也是变量,也就具有指针,结构体指针的定义也相同
struct Node* ptr_l1;上述声明了一个struct Node类型的指针ptr_l1,该指针指向结构体的地址
也可使用typedef简化声明过程
typedef struct LNode* LNodePtr;结构体指针变量就可声明为
LNodePtr l1;访问结构体中的成员,有两种操作方式 分别是 .和 ->
这两种方式的作用是等价的,只是操作的对象不同
struct LNode ll1;
struct LNode* ll2 = (struct LNode*)malloc(sizeof(struct LNode));
ll1.next = NULL;
ll2->next = NULL;如上,.操作的对象是变量本身,->操作是变量对应的指针,也就是说.操作对应的是变量名,->操作对应的是变量名对应的地址,操作的数据都是相同的,
当然,也可以有以下无意义的操作
struct LNode ll1;
struct LNode* ll2 = (struct LNode*)malloc(sizeof(struct LNode));
ll1.next = NULL;
ll2->next = NULL;
(*ll2).next = NULL;
(&ll1)->next = NULL;其中
*ll2就是得到ll2地址对应的变量名,也就是得到了变量,就可以使用.操作
&ll1是得到ll1的地址,就可以对地址使用->操作
当然,.操作在编译是会被转换为->操作,操作内存才是效率最高的行为
至于为啥会有.和->两种操作,可以参考文章
C 语言中,「.」与「->」有什么区别? - 知乎
4. 总结
对于c语言,变量名是方便人和编译器进行操作的载体,编译后都是对地址(指针)进行操作