【AI测试】已落地-python文字图像识别PaddleOCR
python文字图像识别PaddleOCR
PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
国产之光,百度开源的paddle ocr
开源地址:https://github.com/PaddlePaddle/PaddleOCR
官方电子书:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/ocr_book.md
下载安装
文档:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/quickstart.md
说明: 本文主要介绍PaddleOCR wheel包对PP-OCR系列模型的快速使用
安装PaddlePaddle
-
您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple -
您的机器是CPU,请运行以下命令安装
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
更多的版本需求,请参照https://www.paddlepaddle.org.cn/install/quick中的说明进行操作。
安装PaddleOCR whl包
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本
- 对于Windows环境用户:直接通过pip安装的shapely库可能出现
[winRrror 126] 找不到指定模块的问题。建议从https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely下载shapely安装包完成安装。
我的安装
我是win11,电脑显卡不是NVIDIA,所以只能用CPU加速,建议使用GPU,速度更快。
pip install paddleoc
pip install paddlepaddle
我直接这样下载的,用后面的简单使用代码可以直接跑起来。
简单使用
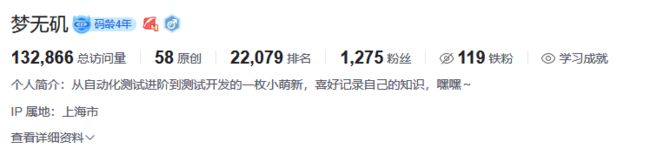
同样我们使用上次用到的图片进行识别。
# -*- coding: utf-8 -*-
'''
@Time : 2023/6/21 11:29
@Email : [email protected]
@公众号 : 梦无矶的测试开发之路
@File : python_paddleocr文字识别_demo01.py
'''
__author__ = "梦无矶小仔"
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False) # 使用CPU预加载,不用GPU
img_path = 'imgs\\csdn_homepage.png'
text_list = ocr.ocr(img_path, cls=True) # 打开图片文件
# print(text_list)
# 打印所有文本信息
for t in text_list[0]:
print(t[1][0])

这是输出结果,是不是完爆上次那个pytesseract的中文识别准确度?(paddleOCR在这张图上的中文识别准确率为100%)
相关参数
打印上文中的text_list进行分析。
[[
[[[10.0, 16.0], [158.0, 16.0], [158.0, 39.0], [10.0, 39.0]], ('梦无矶码龄4年', 0.9589648246765137)],
[[[12.0, 58.0], [146.0, 58.0], [146.0, 75.0], [12.0, 75.0]], ('132.866总访问量', 0.9609718322753906)],
[[[178.0, 58.0], [234.0, 58.0], [234.0, 76.0], [178.0, 76.0]], ('58原创', 0.9998252987861633)],
[[[265.0, 58.0], [361.0, 58.0], [361.0, 75.0], [265.0, 75.0]], ('22,079排名', 0.9822025299072266)],
[[[391.0, 58.0], [475.0, 58.0], [475.0, 75.0], [391.0, 75.0]], ('1,275粉丝', 0.9867120981216431)],
[[[505.0, 57.0], [591.0, 57.0], [591.0, 75.0], [505.0, 75.0]], ('119铁粉', 0.9969574213027954)],
[[[622.0, 59.0], [701.0, 59.0], [701.0, 76.0], [622.0, 76.0]], ('学习成就', 0.9997559785842896)],
[[[12.0, 91.0], [541.0, 91.0], [541.0, 105.0], [12.0, 105.0]], ('个人简介:从自动化测试进阶到测试开发的一枚小萌新,喜好记录自己的知识,嘿嘿~', 0.9711272716522217)],
[[[10.0, 120.0], [115.0, 120.0], [115.0, 137.0], [10.0, 137.0]], ('IP属地:上海市', 0.9775674939155579)],
[[[11.0, 150.0], [110.0, 150.0], [110.0, 167.0], [11.0, 167.0]], ('查看详细资料√', 0.9277077913284302)]
]]
结果是一个list,每个item包含了文本框,文字和识别置信度。
paddleocr默认使用PP-OCRv4模型(--ocr_version PP-OCRv4),如需使用其他版本可通过设置参数--ocr_version,具体版本说明如下:
| 版本名称 | 版本说明 |
|---|---|
| PP-OCRv4 | 支持中、英文检测和识别,方向分类器,支持多语种识别 |
| PP-OCRv3 | 支持中、英文检测和识别,方向分类器,支持多语种识别 |
| PP-OCRv2 | 支持中英文的检测和识别,方向分类器,多语言暂未更新 |
| PP-OCR | 支持中、英文检测和识别,方向分类器,支持多语种识别 |
ocr = PaddleOCR(**kwargs)
常用参数解析
更多命令行参数请阅读官方文档:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/whl.md
| 参数 | 含义 |
|---|---|
| use_angle_cls | bool,设置是否使用方向分类器识别180度旋转文字 |
| use_gpu | bool,设置是否使用GPU |
| page_num | int,支持输入pdf文件,指定推理前面几页,默认为0,表示推理所有页 |
| lang | str,指定语言模型 |
| rec | bool,设置为false表示单独使用检测 |
| det | bool,设置为false表示单独使用识别 |
# result = ocr.ocr(img_path, det=False) 只执行识别
# result = ocr.ocr(img_path, rec=False) 只执行检测
常用的多语言简写包括
| 语种 | 缩写 | 语种 | 缩写 | 语种 | 缩写 | ||
|---|---|---|---|---|---|---|---|
| 中文 | ch | 法文 | fr | 日文 | japan | ||
| 英文 | en | 德文 | german | 韩文 | korean | ||
| 繁体中文 | chinese_cht | 意大利文 | it | 俄罗斯文 | ru |
全部语种及其对应的缩写列表可查看多语言模型教程:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/multi_languages.md
官方python脚本使用
相关代码我略有改动。
中英文与多语言使用
通过Python脚本使用PaddleOCR whl包,whl包会自动下载ppocr轻量级模型作为默认模型。
- 检测+方向分类器+识别全流程
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # 只需要运行一次,会自动帮你把模型进行下载。
img_path = 'imgs\\csdn_homepage.png'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores)
im_show = Image.fromarray(im_show)
im_show.save('imgs\\result01.jpg')
打印展示:
结果是一个list,每个item包含了文本框,文字和识别置信度

效果展示:
结果可视化

落地实践
1、基于以上这些简单的demo,目前已经将其落地在公司的自动化项目中,取得的效果也非常显著,相较于之前的图像识别技术,现在有文字识别加持,提高了UI自动化的准确性,目前非UI本身发生大架构变化,均可无障碍运行。建议使用GPU,目前落地方案采取的是GPU运算。
2、根据文本框的xy轴值,我们可以取中间值进行点击,个别需要偏离中心轴位置的元素进行通用封装(参考airtest的点击偏移)
3、从结果返回值中我们可以看到,拿出的文字是一块一块的,所以在识别的时候,我们可以根据需要,进行区分开精准识别,模糊识别,全部识别等方式进行业务封装。
4、基于游戏自动化,需要训练自己的艺术字体,也可以将字体进行打包丢进去跑。
5、各项封装及二次开发,模型训练在持续进行…
6、再次感谢百度飞浆,致敬!