LeetCode刷题笔记
1、在二分法中,遇到了寻找mid时的小问题,要用
mid = left + (right - left) / 2;
代替
mid = (left + right) / 2;
为什么呢?在测试的数据中会有left + right超越int边界的情况采用上面的写法就可以避免很多;
二分法的约束条件
...
int left = 0, right = nums.length - 1;
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target) return mid;
else if(nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
...
为什么while循环的条件是 <= , 而不是
答:初始化的right的赋值是nums.length - 1, 即最后的一个元素的索引,此时的<=相当于两端区间是闭区间[left, right]。如果条件为left < right,则区间相当于[left, right),需要配合初始值right = nums.length,因为索引nums.length在数组nums[]中是越界的。
2、下一个排列
对于长度为n的数组,找到其下一个更大的排序,若无更大排序则变为最小排序。例:[1, 2, 3]下一个排序为[1, 3 ,2];
直接上算法:
- 从后向前找到满足a[i] < a[i+1]的较小数a[i],此时[i+1,n)必然是下降序列;
- 如果找到顺序对,那么在[i+1,n)从后向前找第一个a[i] < a[j],a[j]为较大数;
- 交换a[i]与a[j],此时[i+1,n)必为降序,再反转区间[i+1,n),使其变为升序,则可得到下一个稍大的排序了;
算法大概书写:
public Solution{
public void nextPermutation(int[] nums) {
int firstIndex = -1;
for(int i = nums.length - 2; i >= 0; i--) {
if(nums[i] < nums[i + 1]) {
firstIndex = i;
break;
}
}
if(firstIndex == -1) {
reverse(nums, 0, nums.length - 1);
return;
}
int secondIndex = -1;
for(int i = nums.length - 1; i >= firstIndex; i--) {
if(nums[i] > nums[firstIndex]){
secondIndex = i;
break;
}
}
swap(nums, firstIndex, secondIndex);
reverse(nums, firstIndex + 1, nums.length - 1);
}
//交换数组中两元素
public void swap(int[] nums, int i, int j){...}
//通过swap,逆置数组区间
public void reverse(int[] nums, int i, int j){
while(i < j){
swap(nums, i++, j--);
}
}
}
3、排序链表
时间复杂度O(n * log n) 的排序算法有归并排序、堆排序、快速排序(最差时间复杂度为O(n^2)),其中最合适链表的是归并排序。
归并排序基于分治算法,最容易想到的实现方法是自顶向下,考虑到递归调用栈的空间,空间复杂度为O(log n )。如果要达到O(1)的空间复杂度,需要使用自底向上的实现方法。
方法一:自顶向下归(真头假尾) :
1.找到链表中点(通过快慢指针),拆分为两个子链表,再分别进行排序;
2. 将拆分的子链表进行两两合并,得到完整排序后的链表;
Class Solution {
//主函数, dummyTail传入空;
public ListNode sortList(ListNode head) {
return sortList(head, null);
}
//head为含有元素的链表头节点,dummyTail为空尾指针
public ListNode sortList(ListNode head, ListNode dummyTail) {
if(head == null) {
return head;
}
//为了甩掉空尾指针,当传入两个节点的情况,分离节点为单独节点
if(head.next == dummyTail) {
head.next = null;
return head;
}
//快慢指针寻找链表中点,通过快指针fast、fast.next判断边界;
ListNode slow = head, fast = head;
while(fast != dummyTail && fast.next != dummyTail) {
slow = slow.next;
fast = fast.next.next;
}
ListNode mid = slow;
ListNode list1 = sortList(head, mid);
ListNode list2 = sortList(mid, dummyTail);
ListNode sorted = merge(list1, list2);
return sorted;
}
//merge即为经典的两有序链表排序融合为同一链表
public ListNode merge(ListNode head1, ListNode head2) {
ListNode dummyHead = new ListNode(0);
ListNode tmp = dummyHead, tmp1 = head1, tmp2 = head2;
while(tmp1 != null && tmp2 != null) {
if(tmp1.val <= tmp2.val) {
tmp.next = tmp1;
tmp1 = tmp1.next;
} else {
tmp.next = tmp2;
tmp2 = tmp2.next;
}
tmp = tmp.next;
}
if(tmp1 != null) {
tmp.next = tmp1;
}
if(tmp2 != null) {
tmp.next = tmp2;
}
return dummyHead.next;
}
}
4. 删除排序链表中的重复元素
给定有序链表, 链表中重复元素的出现位置是连续的,删除重复的元素包括元素本身. 例:1, 2, 3, 3 -> 1, 2;
//一次遍历
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if(head == null) {
return null;
}
//这里使用了假头部节点,为了方便删除头部节点后返回结果dummyHead.next;
ListNode dummyHead = new ListNode(0, head);
ListNode cur = dummyHead;
//当前节点从假头节点开始遍历,循环的判定是cur的后续两节点是否不为空,当有一个为空时便不用进行去重操作;
while(cur.next != null && cur.next.next != null){
if(cur.next.val == cur.next.next.val) {
int tmp = cur.next.val;
while(cur.next != null && cur.next.val == tmp) {
cur.next = cur.next.next;
}
} else {
cur = cur.next;
}
}
return dummyHead.next;
}
}
5.最小覆盖字串
给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 “” 。
注意:
对于 t 中重复字符,我们寻找的子字符串中该字符数量必须不少于 t 中该字符数量。
如果 s 中存在这样的子串,我们保证它是唯一的答案。

题解:滑动窗口
通过两个数组have[128],need[128]记录窗口内的字符出现频数和需要的字符串t的每个字符频数,因为ASCII码一共有128位,所以数组的大小设定为128,且可以通过have[(char)asc2]形式存储频数;
窗口的边界采用左闭右开[left, right), 方便记录窗口长度right - left;
当右边界不超出字符串时循环:
首先移动右窗口right,判断新收纳进窗口的字符s.charAt(right)在need[]数组中的频数need[s.charAt(right)]是否为0,如果为0则continue,继续扩展right;如果不为0,说明是需要的字符,用count记录窗口内有需要字符的总频数,当且仅当已有字符串目标字符出现的次数小于目标字符串字符的出现次数时,count才会+1,以此保证count不是被同一字符多余的频次给加满的;
之后循环判断此时的count是否已经满足需要的字符总频次,满足的时候记录此时的字串长度,若为当前最短则记录。之后开始移动左窗口,当左边界字符不为需要的字符时移动左窗口;若左边界字符为需要的字符时,总频次减一、已有字符频次减一,之后移动左边界;
最后返回字串。
class Solution {
public String minWindow(String s, String t) {
if (s == null || s == "" || t == null || t == "" || s.length() < t.length()) {
return "";
}
//维护两个数组,记录已有字符串指定字符的出现次数,和目标字符串指定字符的出现次数
//ASCII表总长128
int[] need = new int[128];
int[] have = new int[128];
//将目标字符串指定字符的出现次数记录
for (int i = 0; i < t.length(); i++) {
need[t.charAt(i)]++;
}
//分别为左指针,右指针,最小长度(初始值为一定不可达到的长度)
//已有字符串中目标字符串指定字符的出现总频次以及最小覆盖子串在原字符串中的起始位置
int left = 0, right = 0, min = s.length() + 1, count = 0, start = 0;
while (right < s.length()) {
char r = s.charAt(right);
//说明该字符不被目标字符串需要,此时有两种情况
// 1.循环刚开始,那么直接移动右指针即可,不需要做多余判断
// 2.循环已经开始一段时间,此处又有两种情况
// 2.1 上一次条件不满足,已有字符串指定字符出现次数不满足目标字符串指定字符出现次数,那么此时
// 如果该字符还不被目标字符串需要,就不需要进行多余判断,右指针移动即可
// 2.2 左指针已经移动完毕,那么此时就相当于循环刚开始,同理直接移动右指针
if (need[r] == 0) {
right++;
continue;
}
//当且仅当已有字符串目标字符出现的次数小于目标字符串字符的出现次数时,count才会+1
//是为了后续能直接判断已有字符串是否已经包含了目标字符串的所有字符,不需要挨个比对字符出现的次数
if (have[r] < need[r]) {
count++;
}
//已有字符串中目标字符出现的次数+1
have[r]++;
//移动右指针
right++;
//当且仅当已有字符串已经包含了所有目标字符串的字符,且出现频次一定大于或等于指定频次
while (count == t.length()) {
//挡窗口的长度比已有的最短值小时,更改最小值,并记录起始位置
if (right - left < min) {
min = right - left;
start = left;
}
char l = s.charAt(left);
//如果左边即将要去掉的字符不被目标字符串需要,那么不需要多余判断,直接可以移动左指针
if (need[l] == 0) {
left++;
continue;
}
//如果左边即将要去掉的字符被目标字符串需要,且出现的频次正好等于指定频次,那么如果去掉了这个字符,
//就不满足覆盖子串的条件,此时要破坏循环条件跳出循环,即控制目标字符串指定字符的出现总频次(count)-1
if (have[l] == need[l]) {
count--;
}
//已有字符串中目标字符出现的次数-1
have[l]--;
//移动左指针
left++;
}
}
//如果最小长度还为初始值,说明没有符合条件的子串
if (min == s.length() + 1) {
return "";
}
//返回的为以记录的起始位置为起点,记录的最短长度为距离的指定字符串中截取的子串
return s.substring(start, start + min);
}
}
6. 从前序与中序遍历序列构造二叉树
给定一棵树的前序遍历 preorder 与中序遍历 inorder。请构造二叉树并返回其根节点。(preorder 和 inorder 均无重复元素)
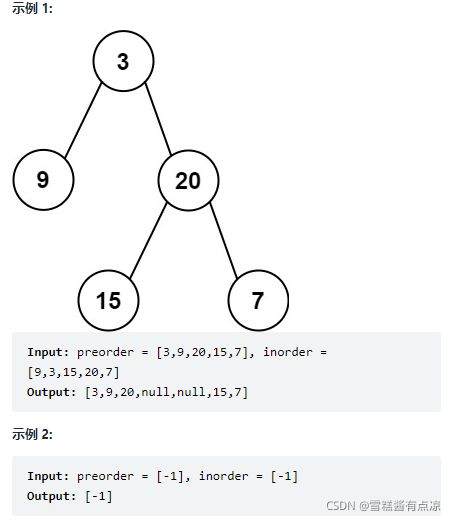
题解:
- 递归
通过前序遍历的头元素得到树的根节点,再根据中序遍历头节点的位置,将头节点左右的元素划分为左右子树。之后再分别从前序遍历中继续寻找左右子树的头节点,递归往复…
public TreeNode buildTree(int[] preorder, int[] inorder) {
return buildTreeHelper(preorder, 0, preorder.length, inorder, 0, inorder.length);
}
private TreeNode buildTreeHelper(int[] preorder, int p_start, int p_end, int[] inorder, int i_start, int i_end) {
// preorder 为空,直接返回 null
if (p_start == p_end) {
return null;
}
int root_val = preorder[p_start];
TreeNode root = new TreeNode(root_val);
//在中序遍历中找到根节点的位置,这里可以通过Hash表改进
//可改进//
int i_root_index = 0;
for (int i = i_start; i < i_end; i++) {
if (root_val == inorder[i]) {
i_root_index = i;
break;
}
}
//
int leftNum = i_root_index - i_start;
//递归的构造左子树
root.left = buildTreeHelper(preorder, p_start + 1, p_start + leftNum + 1, inorder, i_start, i_root_index);
//递归的构造右子树
root.right = buildTreeHelper(preorder, p_start + leftNum + 1, p_end, inorder, i_root_index + 1, i_end);
return root;
}
上述代码,每一次在中序遍历中寻找根节点都需要一次遍历,这里可以通过Hash表改进,因为题中规定树各元素的值是唯一的,所以可以通过值直接获取元素在中序遍历中的位置。
//通过HashMap改进的代码
public TreeNode buildTree(int[] preorder, int[] inorder) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < inorder.length; i++) {
map.put(inorder[i], i);
}
return buildTreeHelper(preorder, 0, preorder.length, inorder, 0, inorder.length, map);
}
private TreeNode buildTreeHelper(int[] preorder, int p_start, int p_end, int[] inorder, int i_start, int i_end,
HashMap<Integer, Integer> map) {
if (p_start == p_end) {
return null;
}
int root_val = preorder[p_start];
TreeNode root = new TreeNode(root_val);
int i_root_index = map.get(root_val);
int leftNum = i_root_index - i_start;
root.left = buildTreeHelper(preorder, p_start + 1, p_start + leftNum + 1, inorder, i_start, i_root_index, map);
root.right = buildTreeHelper(preorder, p_start + leftNum + 1, p_end, inorder, i_root_index + 1, i_end, map);
return root;
}
7.寻找两个正序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。

题解1:归并
将两数组归并为同一数组后取中位数。
题解2:二分法
寻找上下两数组的相对中位线,使得线左侧全部元素小于线右侧全部元素。
两数组总数分别为m、n,当我们用中线将其分隔(中位数紧邻线左侧,中线下标为中线右侧元素,即 i 为中线位下标,中线左侧元素为i - 1,右侧元素为 i ),无论奇偶线左侧元素总数应为(m + n + 1)/ 2(向上取整)。
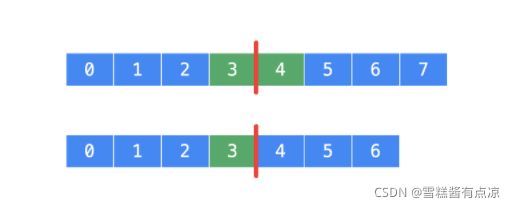
这里我们定位初始值left = 0, right = m,区间为左闭右开[left, right),循环判断边界left < right,我们先通过二分法,快速锁定第一行数组中线,根据中线左侧元素总数totalLeft固定,便得知第二数组中线的位置。之后进行判定,第一行数组中线左侧第一个元素 nums1[i - 1]是否小于第二行中线右侧第一个元素nums2[j]。若不小于则不满足中线的定义要求,需要向左二分,将第一行数组右区间赋值中线左侧位置right = i - 1,下一步寻找[left, i - 1);若小于则说明满足,但需要继续向右二分,为了寻找是否还有比当前中线左侧数值更大并满足要求的中线,将第一行数组左区间赋值中线右一元素i,left = i;

最后要判断一下极端情况,第一行数组中线左侧无值
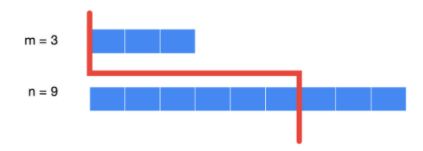
要设定第一行数组左侧最大元素为极小值;
第一行数组中线右侧无值
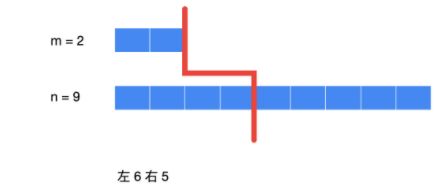
要设定第一行数组中线右侧最小值为极大值;
第二数组中线左侧无值
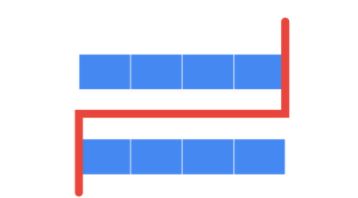
要设定第二行数组中线左侧数值为极小值;
第二行数组中线右侧无值
要设定第二行数组中线右侧数值为极大值;
最后根据奇偶,有两种返回情况;上下数组中线两侧都有可能是中位数,当总数为奇数时,选上下数组中线左侧最大的元素即为中位数;当总数为偶数时,(选中线左侧最大 + 中线右侧最小) / 2 即为中位数;
public class Solution {
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
if (nums1.length > nums2.length) {
int[] temp = nums1;
nums1 = nums2;
nums2 = temp;
}
int m = nums1.length;
int n = nums2.length;
// 分割线左边的所有元素需要满足的个数 m + (n - m + 1) / 2;
int totalLeft = (m + n + 1) / 2;
// 在 nums1 的区间 [0, m] 里查找恰当的分割线,
// 使得 nums1[i - 1] <= nums2[j] && nums2[j - 1] <= nums1[i]
int left = 0;
int right = m;
while (left < right) {
int i = left + (right - left + 1) / 2;
int j = totalLeft - i;
if (nums1[i - 1] > nums2[j]) {
// 下一轮搜索的区间 [left, i - 1]
right = i - 1;
} else {
// 下一轮搜索的区间 [i, right]
left = i;
}
}
int i = left;
int j = totalLeft - i;
int nums1LeftMax = i == 0 ? Integer.MIN_VALUE : nums1[i - 1];
int nums1RightMin = i == m ? Integer.MAX_VALUE : nums1[i];
int nums2LeftMax = j == 0 ? Integer.MIN_VALUE : nums2[j - 1];
int nums2RightMin = j == n ? Integer.MAX_VALUE : nums2[j];
if (((m + n) % 2) == 1) {
return Math.max(nums1LeftMax, nums2LeftMax);
} else {
return (double) ((Math.max(nums1LeftMax, nums2LeftMax) + Math.min(nums1RightMin, nums2RightMin))) / 2;
}
}
}
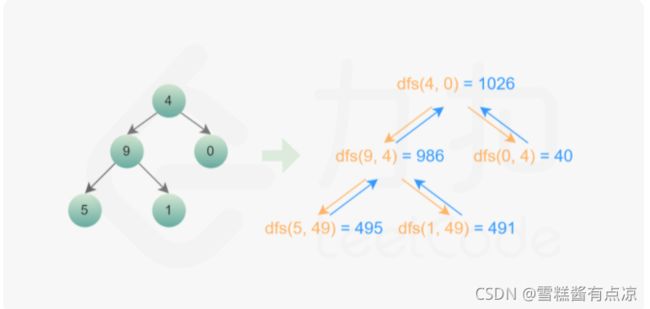
8.求根节点到叶节点数字之和
给你一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。
每条从根节点到叶节点的路径都代表一个数字:
例如,从根节点到叶节点的路径 1 -> 2 -> 3 表示数字 123 。
计算从根节点到叶节点生成的 所有数字之和 。
叶节点 是指没有子节点的节点。

题解:
1、深度优先遍历
从根节点向下依次判断,如果为叶子节点则直接加到数字之和,如果不是,则计算子节点对应的数字;
class Solution {
public int sumNumbers(TreeNode root) {
//初始总和传入0
return helper(root, 0);
}
public int helper(TreeNode root, int prevSum) {
//访问为空节点返回0值
if(root == null) {
return 0;
}
//计算当前总和
int sum = prevSum * 10 + root.val;
//若当前访问的为叶子节点直接将当前总和返回
if(root.left == null && root.right == null) {
return sum;
}
//如不为叶子节点返回遍历左右子树的总和
return helper(root.left, sum) + helper(root.right, sum);
}
}
9.复原IP地址

回溯法(深度优先遍历):
- 目的是在字符串中插入三个点,并使每一段都在【0,255】之间
- 终止条件:当插入点的为3个,并且最后一段在【0,255】之间
- 先寻找第一段合理的字符串,找到后插入点并递归开始寻找第二段…
//深度优先遍历函数,传参开始,结束,记录标点的个数
public void dfs(String s, int start, int end, int count) {
//先判断结束条件,是否满足标点已为三个,若满足判断第四段字符串是否在[0.255]之间
if(count == 3 && isValid(s.substring(start, end + 1))) {
res.add(path.append(s.substring(start, end + 1)).toString());
return;
}
//从strart开始遍历
for(int i = start + 1; i <= end; i++) {
//i点是用来遍历当前这一段的选取
if(isValid(s.substring(start, i))) {
//若当前遍历段符合条件,则记录并以此开始后续段的遍历
path.append(s.substring(start, i));
path.append(".");
//标点记录
count++;
//遍历后续段,i为上一段后第一个元素,以此开始继续遍历
dfs(s, i, end, count);
//遍历后,回溯到当前状态,要将此次定格的记录段归位。减少一位标点,并将路径恢复
count--;
path.delete(start + count, path.length());//路径消除的是本次循环中之前加入进去的部分,比如第一段就是start(0) + count(0)~ path.length();
}
}
}
//判断一段字符串是否在[0,255]之间
public boolean isValid(String s){
if (s.length() == 0) return false;
char[] cs = s.toCharArray();
if (cs[0] == '0' && cs.length != 1) return false;
int res = 0;
for (int i = 0; i < cs.length; i++){
res = res * 10 + cs[i] - '0';
}
if (res >= 0 && res <= 255){
return true;
}
return false;
}
//主函数
List<String> res = new ArrayList<>();
StringBuffer path = new StringBuffer();
public List<String> restoreIpAddresses(String s) {
//特殊情况,不满足ip字段范围的基本条件,直接返回
if (s.length() < 4 || s.length() > 12) return res;
//开始回溯遍历
dfs(s, 0, s.length() - 1, 0);
return res;
}
10.最长公共子序列

题解:典型的二维动态规划问题,双重循环遍历所有的可能组合,用二维数字记录每种情况下的最长公共子序列长度。
公共子序列:字符顺位一样,不要求连续
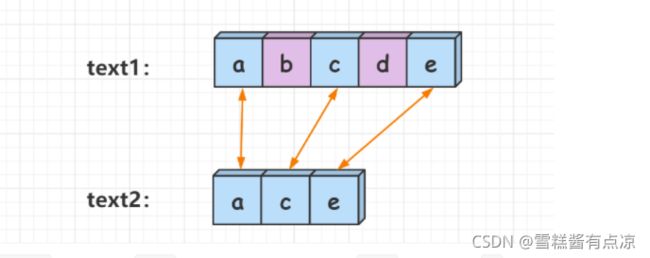
状态表示:定义f[i][j]记录字符串text1在[1, i]区间与字符串text2在[1, j]区间的最长公共子串长度(下标从一开始),字符串text1长度为n,text2长度为m,1<= i <= n, 1 <= j <= m。
初始值:f[0, i] = f[j, 0] = 0, 当一方没有遍历到字符时,此时最长公共子序列长度为0;
状态计算:根据text1[i], text2[j]情况,分为两纵决策:
-
若
text1[i] == text2[j],即当前遍历到的字符相同,则这个字符可以作为最长公共子序列的一部分,问题转化为了text1在[1, i - 1]与text2在[1, j - 1]区间的最大公共子序列长度 + 1,即f[i][j] = f[i-1][j-1] + 1;
-
若
text1[i] != text2[j],即当前遍历到的字符不相等,无延长最长公共子序列,此前的状态有两种可能f[i-1][j],f[i][j-1],此时的记录f[i][j]取f[i-1][j]与f[i][j-1]的最大值,即f[i][j] = max(f[i - 1][j],f[i][j - 1]);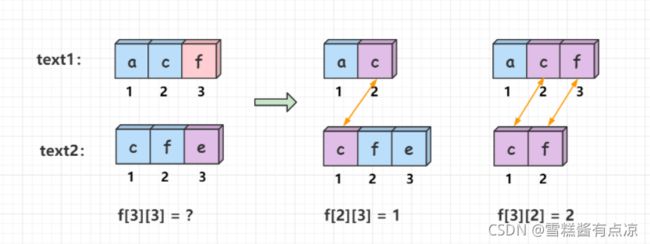
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int n = text1.length(), m = text2.length();
//初值默认为0
int[][] f = new int[n + 1][m + 1];
for (int i = 1; i <= n; ++i) {
for (int j = 1; j <= m; ++j) {
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
f[i][j] = f[i - 1][j - 1] + 1;
} else {
f[i][j] = Math.max(f[i - 1][j], f[i][j - 1]);
}
}
}
return f[n][m];
}
}
11.rand7实现rand10

公式1:
rand_XY() = ( rand_X() - 1 )* Y + rand_Y()
可通过rand_X()和rand_Y()(产生1~X和 1 ~ Y的随机数)生成[1, X*Y] 的随机数;
公式2:
N可被X整除,N % X = 0;
rand_X() = rand_N() % X + 1;
拒绝采样:
当我们用公式生成的随机数可能不是正好满足需要的,这时候可以通过拒绝采样达成需求。比如只有rand7(),我们通过公式1生成,rand7*7= rand49 = ( rand7() - 1 ) * 7 + rand7(),如果生成的是[1, 40]直接返回,[41, 49]是我们不需要的范围,如果生成数在这里拒绝采样再次生成直到满足条件;
class Solution extends SolBase {
public int rand10() {
while(true) {
int num = (rand7() - 1) * 7 + rand7();
if(num <= 40) return num % 10 + 1;
}
}
}
12.二叉树的直径(简单)

题解:深度优先遍历(后序遍历,魔改求树的深度)
这道题看上去可以通过计算根节点的左子树深度 + 右子树深度获得结果,但是题目有要求直径可以不穿过根节点,也就是说有可能在子节点中可能存在直径更大的情况;我们在求树的深度基础上,增加每一时刻的最大直径,即左右子树深度之和leftDepth + rightDepth,记录最大的直径即可;
Class Solution {
//记录最大直径
int max = Integer.MIN_VALUE;
//辅助函数求树的深度
int depth(TreeNode root) {
if(root == null) {
return 0;
}
//计算左右子树深度
int leftDepth = depth(root.left);
int rightDepth = depth(root.right);
//计算此时的直径,并保留最大直径,其余部分与计算树的深度完全一致;
max = Math.max(leftDepth + rightDepth, max);
//返回深度,左右子树最大深度加上传参节点本身的深度;
return Math.max(leftDepth, rightDepth) + 1;
}
//主函数
public int diameterOfBinaryTree(TreeNode root) {
//战术性调用深度函数,但是我们并需要求深度而是需要这个过程记录最大直径,返回记录max;
depth(root);
return max;
}
}
12.最长重复子数组(中等)

题解:
- 最开始想到的就是试一下暴力法,但是就连暴力法都想复杂了;暴力法实际上是三重循环,暴力枚举,第三层循环是辅助第二层循环,负责在字符相同情况下继续往下比对;
// 暴力法
public int findLength(int[] nums1, int[] nums2) {
int ans = 0;
for(int i = 0; i < nums1.length; i++) {
for(int j = 0; j < nums2.length; j++) {
int k = 0;
//第三层循环,负责字符相等的情况下继续往下比对
while(i+k < nums1.length && j+k < nums2.length && nums1[i + k] == nums2[j + k]) {
k++;
}
ans = Math.max(k, ans);
}
}
return ans;
}
- 动态规划 结尾对齐比较!
动态规划数组dp[i][j]记录两个数组A[]从头截取至 i 元素,与B[]从头截取至 j 元素即前缀数组的最大公共长度(这里记录的是A[i]与B[j]对齐时比对的情况); 这里的前缀数组是指,我们在记录时比对的是末位项,不要求知道子数组是从哪里开始(虽然形成了dp表可以获知);
这里的前缀数组是指,我们在记录时比对的是末位项,不要求知道子数组是从哪里开始(虽然形成了dp表可以获知);
状态转移方程:
- 当遍历到的A[i]元素与B[j]元素相等时,此时便拥有了一位公共元素,此时再加上A[0 ~ i - 1],B[0 ~ j - 1]的公共元素长度,即dp[i][j] = dp[ i - 1][ j - 1 ] + 1;
- 当遍历到的A[i]元素与B[j]元素不相等时,重点这里要求当末尾项不相同时,以他俩为末尾项形成的子数组,公共子数组长度一定为0,即dp[i][j] = 0,原理见上;

动态规划,代码简单,但是原理有思维陷阱;
public int findLength(int[] nums1, int[] nums2) {
int m = nums1.length, n = nums2.length;
int[][] dp = new int[m+1][n+1];
int ans = 0;
for(int i = 1; i <= m; i++) {
for(int j = 1; j <= n; j++) {
if(nums1[i-1] == nums2[j-1]) {
dp[i][j] = dp[i-1][j-1] + 1;
ans = Math.max(ans, dp[i][j]);
}
}
}
return ans;
}
13.回文链表(简单)
题解:为了达到时间复杂度O(n),空间复杂度O(1),我们可以将后一半链表逆置,之后双指针将链表分为两段进行比较即可;这里涉及到两个函数:
- 寻找链表中点;
- 链表逆置;
因为我们对原链表部分进行了逆置操作,修改了原表结构,最后需要还原还要调用一次链表逆置,而且在并发环境下,函数运行时需要锁定其他线程或进程对链表的访问,因为在函数执行过程中链表会被修改;
//逆置链表
ListNode reverseList(ListNode head) {
ListNode pre = null, cur = head;
while(cur != null) {
ListNode nex = cur.next;
cur.next = pre;
pre = cur;
cur = nex;
}
return pre;
}
寻找链表中点是通过快慢指针实现的
//寻找链表中点
ListNode findMiddleNode(ListNode head) {
ListNode fast = head, slow = head;
//寻找到的节点奇数个节点为中点,偶数个为前段链表的未点;
while(fast.next != null && fast.next.next != null) {
fast = fast.next.next;
slow = slow.next;
}
return slow;
}
主函数
public boolean isPalindrome(ListNode head) {
if(head == null) {
return false;
}
ListNode middle = findMiddleNode(head);
ListNode afterReverseHead = reverseList(middle.next);
ListNode p1 = head, p2 = afterReverseHead;
boolean result = true;
while(p2 != null && result) {
if(p1.val != p2.val) {
result = false;
}
p1 = p1.next;
p2 = p2.next;
}
middle.next = reverseList(afterReverseHead);
return result;
}
41.缺失的第一个正数(困难)(原地哈希)

原地哈希
这道题目使用了原地哈希法,将数组元素 - 1当作下标值。nums = [3, 4, -1, 1],如nums[0] = 3,则3 - 1 = 2为下标值,需要将nums[0]放置在nums[2]上。
原理如上述,但是由于放置元素会导致原元素被覆盖,所以实际操作是交换两元素,nums[0] = 3,则交换nums[0]与nums[2 = nums[0] - 1]。交换后由于nums[0]被赋予新值,继续判断nums[0]的新位置…直到nums[0]不满足下标条件(nums[0] <= 0 && nums[0] >= nums.length)或者nums[0]已经位于了所应该在的下标上(nums[nums[0] - 1] == nums[0]),这里没有使用nums[nums[0] - 1] = i + 1,是因为这个条件只能判断当前元素是否摆在了他应该在的hash位上,如果有两个相同元素时,这个判断便有了冲突,有两个相同元素时且hash位置已经被占只能放弃。
最后再遍历检查一遍数组是否有元素不为下标+1,若有即为缺失的正数。
重点
在判断哈希位置是否摆放正确的判断nums[nums[i] - 1] != nums[i]这里有些难理解。这个判断实际实现了的作用,以[nums[i] - 1]为下标的元素是否摆放着nums[i]。
1.若摆放不为nums[i]:那么肯定需要交换元素。
2.若摆放为nums[i]值,有两种可能:
a. 摆放的是当前遍历到的nums[i],即已经摆放到正确位置了,nums[nums[i] - 1] = i + 1
b. 摆放的是相同的值但非此元素,此时无需交换,当前元素视为废弃元素,摆放在原地随意处置,nums[nums[i] - 1] != i + 1。
也就是说nums[nums[i] - 1] != i + 1没有判断重复值的情况。
class Solution {
// 原地Hash
public int firstMissingPositive(int[] nums) {
for(int i = 0; i < nums.length; i++) {
// 满足条件交换元素后,继续循环判断。
// 这里nums[i] >= 1, 不能写成nums[i] - 1 >= 0,这是因为Integer.MIN_VALUE = -2147483648 = MAX_VALUE + 1;
// MIN_VALUE - 1 = MAX_VALUE正好满足 >= 0,而MIN_VALUE <= nums.length,有漏洞!
while(nums[i] >= 1 && nums[i] <= nums.length && nums[nums[i] - 1] != nums[i]) {
System.out.println(nums[i] - 1);
swap(nums, nums[i] - 1, i);
}
}
for(int i = 0; i < nums.length; i++) {
if(nums[i] - 1 != i) {
return i + 1;
}
}
return nums.length + 1;
}
private void swap(int[] nums, int index1, int index2) {
int tmp = nums[index1];
nums[index1] = nums[index2];
nums[index2] = tmp;
}
}
5.最长回文子串
中心扩散法
从头到尾遍历,分别判断单个元素和两个元素的最长回文子串情况。
/**
* 中心扩散法
*/
public String longestPalindrome(String s) {
if(s == null || s.length() <= 1) {
return s;
}
char[] chs = s.toCharArray();
String max = "";
for(int i = 0; i < chs.length; i++) {
int len1 = expand(chs, i, i);
int len2 = expand(chs, i, i + 1);
int len = Math.max(len1, len2);
if(len > max.length()) {
int start = i - (len - 1) / 2;
int end = i + len / 2;
max = s.substring(start, end + 1);
}
}
return max;
}
// 中心扩散函数
private int expand(char[] chs, int left, int right) {
while(left >= 0 && right < chs.length && chs[left] == chs[right]) {
left--;
right++;
}
return right - left - 1;
}
动态规划
这里直接使用数组dp[i][j]表示 [i, j]是否为回文子串。
public String longestPalindrome(String s) {
int len = s.length();
int begin = 0, maxLen = 1;
// 1.dp[i][j]表示范围[i,j]是否是回文子串
boolean dp[][] = new boolean[len][len];
//初始化在循环中进行
// 4.循环嵌套顺序,根据递推公式可知dp[i][j]是由左下方的元素dp[i+1][j-1]得来,所以我们需要先遍历出左下方的元素,
// 而且根据题意,取子串的范围[i,j]可知,i <= j(上对角);
// 4.1 可以选择外循环 i 内循环 j ,i从大到小,j无限制(行遍历,j不受影响)
for(int i = len - 1; i >= 0; i--) {
for(int j = i; j < len; j++) {
// for(int j = len - 1; j >= i; j--) {
// 4.2 也可以选择外循环j 内循环i,j从小到大, i顺序无限制(按列遍历,i不受影响)
// for(int j = 0; j < len; j++) {
// for(int i = 0; i <= j; i++) {
// for(int i = j; i >= 0; i--) {
// 2,3.当s[i] != s[j]时,则[i,j]范围的子串直接不为回文子串(对初始化和递推条件都生效)
if(s.charAt(i) != s.charAt(j)) {
dp[i][j] = false;
} else {
// 3.初始化,当i == j(单个字符) 或 j - i == 1(两个字符)时,s[i] == s[j]可以直接判定为回文子串;
// 初始化的元素就是dp数组对角线及对角线上一层的次对角线;
if(i == j || j - i == 1) {
dp[i][j] = true;
} else {
// 2.当子串范围大于2时,若s[i]==s[j],要依靠范围缩小的子串[i+1,j-1]是否为回文子串进行判定;
dp[i][j] = dp[i + 1][j - 1];
}
}
// 当[i,j]为回文子串时,记录是否为最大子串,如果是更新起点begin与长度maxLen;
if(dp[i][j] == true) {
if(j - i + 1 > maxLen) {
begin = i;
maxLen = j - i + 1;
}
}
}
}
return s.substring(begin, begin + maxLen);
}
百度笔试 通关
小昱购买了两款游戏,第一款游戏有n个关卡,通过第i关需要花a[i]的时间;第二款游戏有m个关卡,通过第i关需要花b[i]的时间。两款游戏都不允许跳过关卡,即必须要通过第 i关,才能挑战第 i+1关。小昱想知道在游戏时长不超过t的情况下,最多可以通过多少关?
题解:计算前缀和,配合二分法查找
分别计算第一款游戏的前缀时间消耗presumeA,第二款游戏的前缀时间消耗presumeB。
遍历presumeA,计算剩余可用时间 t - presumeA[i],在presumeB中寻找元素,若没有匹配则返回偏小的一侧。
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int n = scan.nextInt();
int m = scan.nextInt();
int t = scan.nextInt();
int[] a = new int[n];
int[] b = new int[m];
int[] presumeA = new int[n];
int[] presumeB = new int[m];
// 计算前缀和
for(int i = 0; i < n; i++) {
a[i] = scan.nextInt();
if(i == 0) {
presumeA[i] = a[i];
} else {
presumeA[i] = presumeA[i - 1] + a[i];
}
}
// 计算前缀和
for(int i = 0; i < m; i++) {
b[i] = scan.nextInt();
if(i == 0) {
presumeB[i] = b[i];
} else {
presumeB[i] = presumeB[i - 1] + b[i];
}
}
// 遍历第一款游戏的前缀和
int res = 0;
for(int i = 0; i < n; i++) {
// 计算可用的剩余时间
int remain = t - presumeA[i];
// 若剩余时间 < 0则,无法达到次前缀及后续前缀,直接返回即可。
if(remain < 0) {
break;
} else {
// 在第二款游戏前缀和中寻找
int pass2 = find(presumeB, remain) + 1;
res = Math.max(pass2 + i + 1, res);
}
}
System.out.println(res);
}
private static int find(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target) {
return mid;
} else if(nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return right;
}
剑指36 二叉搜索树与双向链表
将一颗二叉搜索树转换成一个排序的(循环)双向链表。通过调整树节点指针来进行转换。

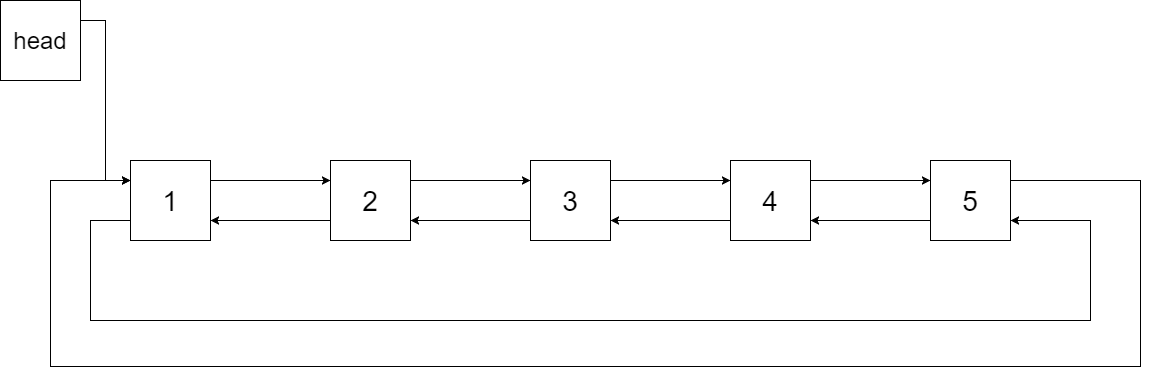
我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中的第一个节点的指针。
题解
根据二叉搜索树遍历的顺序可以看到是通过中序遍历进行地。所以转换的过程也是通过中序遍历完成的,我们建立两个成员属性pre,head分别记录当前节点的前置节点和链表的头节点。
class Solution {
Node pre, head;
public Node treeToDoublyList(Node root) {
if(root == null) {
return null;
}
dfs(root);
// 建立循环链表,将尾节点与头节点建立连接
head.left = pre;
pre.right = head;
return head;
}
// 中序遍历
public void dfs(Node root) {
if(root == null) {
return;
}
dfs(root.left);
if(pre == null) {
head = root;
} else {
pre.right = root;
root.left = pre;
}
// 记录前置节点
pre = root;
dfs(root.right);
}
}
15.三数之和(重新思考)

三数之和思想是双指针扩散,但在定义时由于题意是三元组,所以需要定义三个指针分别指向三个元素,一个指针进行遍历,每一次遍历中另外两个指针进行扩散。
双指针扩散思想
为了方便去重的判断,我们首先将元素按序排列。之后,使用三个指针left, middle, right分别从前向后指向三个元素。left为遍历的左边界,middle,right为扩散指针,每轮middle = left + 1, right = numsl.length - 1,三元组和为sum = nums[left] + nums[middle] + nums[right]。若当前sum < 0,middle++; 若当前sum > 0,right--;两个指针按照sum的值进行循环扩散,直到指针相撞left == right,且在这期间遇到sum == 0的情况,要记录nums[left], nums[middle], nums[right]的值。
这里强调三点:
1.每一轮遍历,两个扩散指针都要将边界范围内的值全部覆盖到,直到指针相撞,这是因为要记录所有可能的情况。
2.扩散指针去重:当sum == 0时,要考虑去重,即nums[middle] == nums[middle + 1],nums[right] == nums[right - 1],将sum == 0的结果保持唯一性。
3.左指针遍历去重:上一个去重是在左边界确定的情况下保证另外两个元组的唯一性,那么左边界值等于上一轮左边界值得情况即nums[left] == nums[left - 1],左边界值如果出现过,就无需再进行扩散了,因为这样是重复的扩散。
public List<List<Integer>> threeSum(int[] nums) {
// 遍历 + 双指针,left用来遍历和确立左边界,middle和right用来扩散
int left, middle, right;
List<List<Integer>> res = new ArrayList<>();
// 先排序
Arrays.sort(nums);
// 左边界遍历
for(left = 0; left < nums.length - 2; left++) {
// 左边界去重
if(left > 0 && nums[left] == nums[left - 1]) {
continue;
}
// 扩散
middle = left + 1;
right = nums.length - 1;
// 一定要扩散到两个指针碰撞,即边界内所有元素都判断到
while(middle < right) {
int sum = nums[left] + nums[middle] + nums[right];
if(sum < 0) {
middle++;
} else if(sum > 0) {
right--;
} else {
List<Integer> sub = new ArrayList<>();
sub.add(nums[left]);
sub.add(nums[middle]);
sub.add(nums[right]);
res.add(sub);
// sum == 0, 要进行扩散指针的去重
while(middle < right && nums[middle + 1] == nums[middle]) {
middle++;
}
while(middle < right && nums[right - 1] == nums[right]) {
right--;
}
// 重要:记录三元组后,要继续移动双指针,为了覆盖所有的边界元素!
// 经过扩散指针的去重操作后,扩散指针指向的元素不存在还有其他匹配的元素了,所以只需继续向内移动指针就好(只移动一个指针也可以,目的就是为了覆盖边界内全部元素).
middle++;
right--;
}
}
}
return res;
}
回溯篇
回溯

14.1 组合(中等)

class Solution {
//结果数组
List<List<Integer>> res = new ArrayList<>();
//遍历路径
List<Integer> path = new ArrayList<>();
//主函数
public List<List<Integer>> combine(int n, int k) {
backtracking(n, k, 1);
return res;
}
//按照回溯法模板函数
void backtracking(int n, int k, int startIndex) {
//终止条件
if(path.size() == k) {
res.add(new ArrayList(path));
return;
}
//单程搜索逻辑
for(int i = startIndex; i <= n; i++) {
//处理节点
path.add(i);
//递归函数
backtracking(n, k, i+1);
//回溯操作,撤销
path.remove(path.size() - 1);
}
}
}
14.2 子集(中等)

这个题目比较特殊,因为求的是子集,path结果需要的不是叶子节点而是每一个叶节点,所以回溯没有终止条件,替代的是直接将当前路由的path数组加入结果集里;
class Solution {
List<List<Integer>> res;
List<Integer> path;
//主函数
public List<List<Integer>> subsets(int[] nums) {
res = new ArrayList<>();
path = new ArrayList<>();
backtracking(nums, 0);
return res;
}
//回溯函数
private void backtracking(int[] nums, int startIndex) {
//没有终止条件,替代的是每一个叶节点都加入结果集
res.add(new ArrayList(path));
//单层搜索逻辑
for(int i = startIndex; i < nums.length; i++) {
//处理节点
path.add(nums[i]);
//递归函数
backtracking(nums, i + 1);
//回溯操作
path.remove(path.size() - 1);
}
}
}
14.3 子集II

题解:这道题目和上一道题目多了一个要求,就是元素中可以有重复元素,需要进行去重操作。还是使用回溯法公式,整体结构格式不变。
终止条件:因为需要将每一个叶节点加入结果集,所以没有结束条件判断,每一次回溯都要将当前的路径加入至结果集;
处理节点:处理节点这部分不太一样,因为我们要进行去重操作,在这里我们要排除重复出现的子集,我们需要新增一个boolean数组visited[n]记录数组中每一个元素是否被访问,而这里的判断和普通的判断还不一样(并不是前一个元素和后一个元素相同且前一个元素被访问过就是重复的),在的树形结构里使用过是有两个维度的,一个维度是同一树枝上使用过,一个维度是同一树层使用过;同一树枝使用过并不是重复,比如[1, 2, 2],而同一树层使用过才是重复,比如[1, 2], [1, 2];如何进行同一层的去重呢,当我们发现单层搜索逻辑中前一个元素等于后一个元素时,如果前一个元数没有访问过,那么就是重复的了。这里为什么是没有访问过呢,因为我们处理节点路径加入元素之后,会在visited[]中设定成true(访问过),递归后进行回溯操作时再将visited[]中设定为false(未访问过)复原;就是说单层搜索逻辑中,同树层前一个元素回溯完会处于为访问的状态,所以未访问过才是判断条件:i > 0 && nums[i] == nums[i-1] && !visited[i-1];
class Solution {
private List<List<Integer>> res;
private List<Integer> path;
private boolean[] visited;
public List<List<Integer>> subsetsWithDup(int[] nums) {
res = new ArrayList<>();
path = new ArrayList<>();
visited = new boolean[nums.length];
Arrays.sort(nums);
backtracking(nums, 0);
return res;
}
private void backtracking(int[] nums, int startIndex) {
//终止条件
res.add(new ArrayList(path));
//单层搜索逻辑
for(int i = startIndex; i < nums.length; i++) {
//处理节点
if(i > 0 && nums[i] == nums[i-1] && !visited[i-1]) {
continue;
}
path.add(nums[i]);
visited[i] = true;
//递归
backtracking(nums, i + 1);
//回溯
path.remove(path.size() - 1);
visited[i] = false;
}
}
}
// @lc code=end
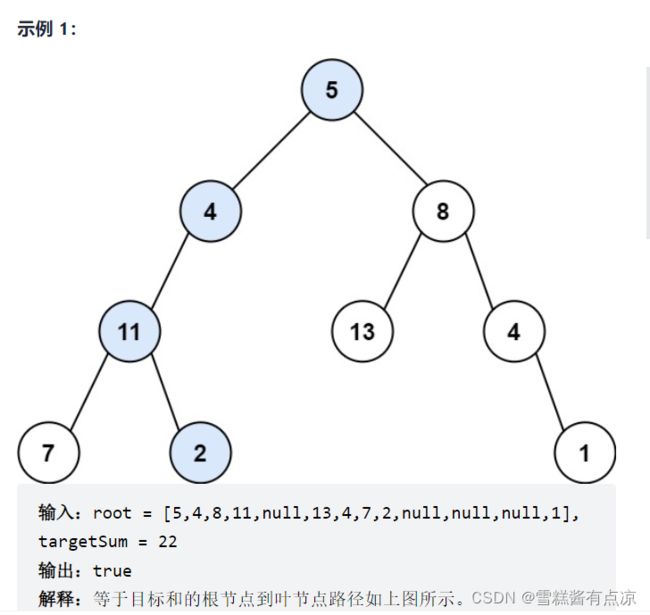
15.路径总和(简单)
摘自代码随想录:
很多同学会疑惑,递归函数什么时候要有返回值,什么时候没有返回值:
1.先确定递归函数的参数和返回类型
参数:需要二叉树的根节点,需要一个计数器计算是否有路径之和为目标和;
返回类型:
- 如果需要搜索整棵二叉树,且不用处理递归返回值,递归函数不需要返回值;
- 如果需要搜索整棵二叉树,且需要处理递归返回值,递归函数就需要返回值;
- 如果要搜索其中一条符合条件的路径,遇到符合条件的路径就及时返回,那么递归一定需要返回值;
本题是第三种情况:
- 未看题解时,想到了一种方法,通过一次先序遍历完整的遍历一次,如果有满足的路径就将结果
res置为true。但是这种方法有一点劣势,就是要遍历整颗二叉树,而题目的要求实际上可以遇到满足的路径就直接返回true。
class Solution {
boolean res = false;
public boolean hasPathSum(TreeNode root, int targetSum) {
preorder(root, targetSum, 0);
return res;
}
void preorder(TreeNode root , int targetSum, int curSum) {
if(root == null) {
return;
}
curSum += root.val;
if(root.left == null && root.right == null && curSum == targetSum) {
res = true;
}
preorder(root.left, targetSum, curSum);
preorder(root.right, targetSum, curSum);
}
}
- 第二种方法就是搜索到满足条件的路径就理解返回结果:
public boolean hasPathSum(TreeNode root, int targetSum) {
//这个是为了排除传入二叉树为空的情况和有单侧子树的节点的情况
if(root == null) {
return false;
}
//遇到叶子节点进行判断当前路径是否满足条件,
if(root.left == null && root.right == null) {
return root.val == targetSum;
}
//这里的递归传参,为了更加方便,传入的目标和为总和减去当前遍历到的节点值;当检测到满足条件的路径后直接就返回true
//若左子树有满足条件的路径返回true
if(hasPathSum(root.left, targetSum - root.val)) return true;
//若右子树有满足条件的路径返回true
if(hasPathSum(root.right, targetSum - root.val)) return true;
//若没有满足条件,返回false
return false;
}
这里回溯条件是自然完成的,遍历到当前节点的和,在传入递归中时才进行处理,递归结束返回到当前节点还是目前需要的节点的和;
这里最后的递归和触底返回false可以再精简一下:
public boolean hasPathSum(TreeNode root, int targetSum) {
if(root == null) {
return false;
}
if(root.left == null && root.right == null) {
return root.val == targetSum;
}
return hasPathSum(root.left, targetSum - root.val) || hasPathSum(root.right, targetSum - root.val);
}
动态规划篇
动态规划五部曲:
- dp数组以及其下标的含义;
- 递推公式
- dp数组如何初始化
- 遍历顺序
- 打印dp数组(检查)
01背包(二位数组)
有N件物品和一个最多能承重为bagSize的背包。第i件物品的重量是weight[i],得到的价值是value[i]。每件物品只能用一次,求解讲哪些物品装入背包价值总和最大。
1.dp数组以及其下标含义
我们传参int[] weight数组记录物品的重量,int[] value记录物品的价值,bagSize为背包最大承重;
这里使用的是二位dp数组,dp[i][j]这里表示的含义是:从下标为[0-i]的物品里任意取,放进容量为j的背包,价值总和最大为多少。
2.递推公式
我们想要得到dp[i][j](从[0-i]的物品里任意取(每件物品只能用一次),放进容量为j的背包,价值总和最大是多少),有两种方向:
- 不放物品
i:当物品i的重量大于此时的承重量j时,无法将其放入。当我们不放物品i时,此时的dp[i][j]=dp[i-1][j],就是从[0-i-1]的物品里任取放进容量为j的背包最大价值和; - 放入物品
i:当物品i的重量小于等于此时的称重量j时,可以将其放入背包。此时的dp[i][j] = max(dp[i-1][j], dp[i-1][j-weight[i]]+value[i]),即为选取不放物品i时的最大价值 和 如果放入物品i时的最大价值(这里通过选取[0,i-1]物品放入承重j-weight[i]时的最大价值加上物品i的价值);
3.初始化
这里提供两种初始化的思路:
- 手动初始化
dp数组大小定为dp[weight.length][bagSize + 1],这里bagSize + 1是因为我们需要书包承重为0时的最大价值和,所以对于j多了一种状态;
因为dp[i][0]表示的是背包承重为0时装入的最大价值,所以设定值为0;
for (int j = 0 ; j < weight[0]; j++) {
// 当然这一步,如果把dp数组预先初始化为0了,这一步就可以省略,但很多同学应该没有想清楚这一点。
dp[0][j] = 0;
}
物品i此时从0开始计位,通过递归公式可以看出当前的价值是通过左上斜方获得的,所以我们需要给第一行进行初值赋值。此时的dp[0][j]表示的是选择0物品时,在承重为j的情况下最大价值和。当遍历到的承重量j大于等于物品0的重量时,它的最大价值和就是物品0的价值;
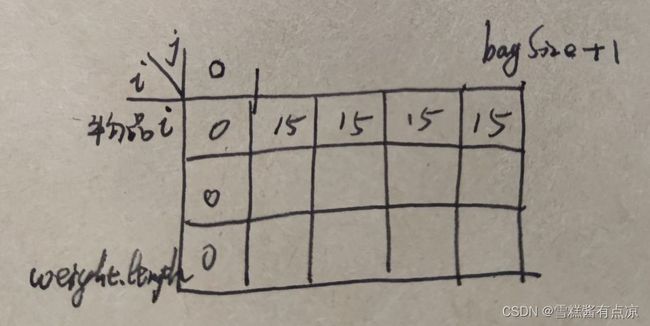
所以第一行的初始化从承重量j为物品0的重量开始遍历,直到背包最大承重量,最大价值都赋值为物品0的价值(因为此时只能装入一件物品0);承重量j小于物品0的时候都默认最大价值为0了;
for(int j = weight[0]; j <= bagSize; j++) {
dp[0][j] = value[0];
}
- 自动初始化,拓宽i,虚建物品0:
dp数组大小定为dp[weight.length + 1][bagSize + 1],这里行和列都多了一组数据,真正的物品下标是从1开始计位。dp[0][j]可以看成是不存入物品时背包的装入的最大价值,所以设定值为0(实际上我们是虚建了一个物品0,他的价值为0,所以即使装入背包价值总和也为0);dp[i][0]表示的是背包承重为0时装入的最大价值,所以设定值为0;
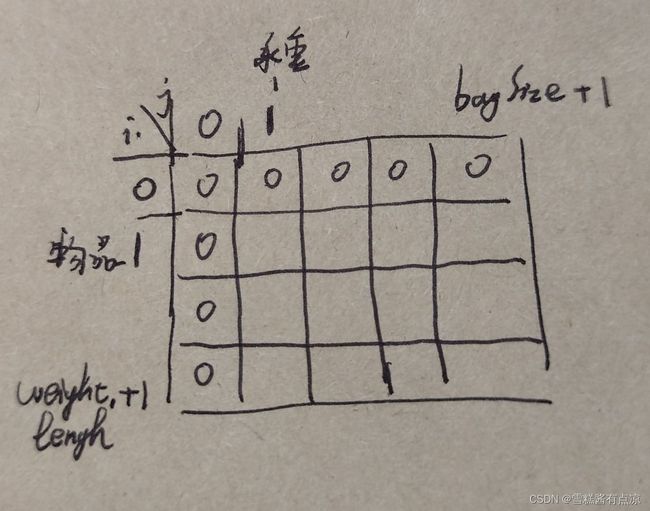
由于新建dp数组默认所有值为0,所以我们便不再需要进行其他的手动初始化;实际上这么做是简化了上一种初始化的工作,真正第一个物品这一行也就是dp[1][j]对应着上一种初始化方法的dp[0][j],而这一行的值直接由递推公式帮我们代办了;
4.遍历顺序
这道题是有两个遍历维度的:物品与背包承重量。
那么是先遍历物品还是先遍历背包承重量呢?
对于这道题是都可以的!那是因为什么呢?
理解递归的本质和递推的方向:
递归公式dp[i][j] = max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);可以看出dp[i][j]的得出是靠dp[i-1][j]和dp[i-1][j-wieght[i]]推导出来的,也就是左上方(包括正上方)。
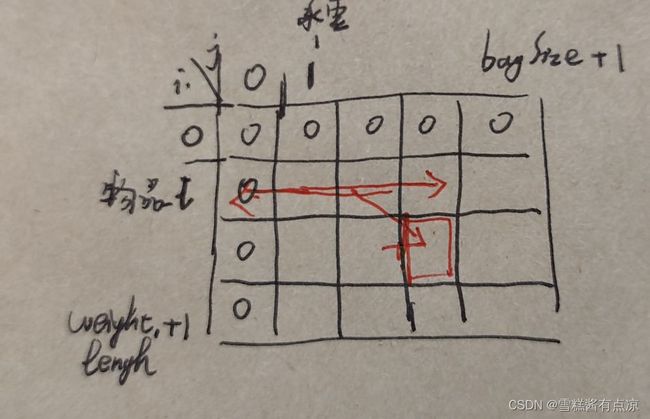
如果按照先遍历背包承重量j,再遍历物品i:
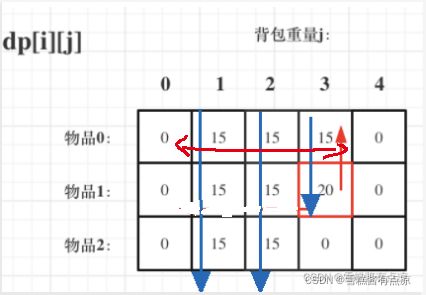
如果按照先遍历物品i,再遍历背包承重量j:
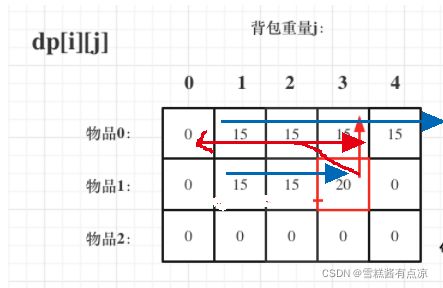
两个遍历次序虽然不同,但是dp[i][j]需要的就是左上角(包括正上方)的数据,遍历顺序并不影响公式的推导!
5.打印dp数组检查检查是否符合预期
完整代码:
- 第一种手动初始化方法:
public class Solaution01bag {
public static void testWeightBagProblem(int[] weight, int[] value, int bagSize) {
int wLen = weight.length;
int[][] dp = new int[wLen + 1][bagSize + 1];
//手动初始化
for(int j = weight[0]; j <= bagSize; j++) {
dp[0][j] = value[0];
}
//这两种初始化方法,i,j都是从1开始遍历(j=0已经初始化为0了,i=0手动初始化赋值了);i值的遍历范围两种方法是不同的;
for(int i = 1; i < wLen; i++) {
for (int j = 1; j < bagSize + 1; j++) {
if(weight[i] > j) {
dp[i][j] = dp[i - 1][j];
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weight[i]] + value[i]);
}
}
}
for(int i = 0; i < wLen; i++) {
for(int j = 0; j <= bagSize; j++) {
System.out.print(dp[i][j] + " ");
}
System.out.println('\n');
}
}
public static void main(String[] args) {
int[] weight = {1, 3, 4};
int[] value = {15, 20, 30};
int bagSize = 4;
testWeightBagProblem(weight, value, bagSize);
}
}
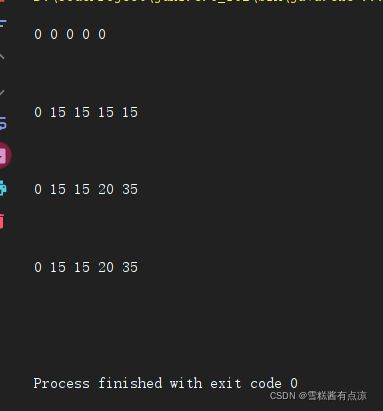
输出dp数组:

- 第二种自动初始化方法:
public class Solaution01bag {
public static void testWeightBagProblem(int[] weight, int[] value, int bagSize) {
int wLen = weight.length;
//物品+1,虚建价值为0的物品0,默认值0免去了初始化
int[][] dp = new int[wLen + 1][bagSize + 1];
//这两种初始化方法,i,j都是从1开始遍历(j=0已经初始化为0了,i=0也初始化为0了);i值的遍历范围两种方法是不同的;
for(int i = 1; i < wLen + 1; i++) {
for (int j = 1; j < bagSize + 1; j++) {
if(weight[i - 1] > j) {
dp[i][j] = dp[i - 1][j];
} else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - weight[i - 1]] + value[i - 1]);
}
}
}
for(int i = 0; i <= wLen; i++) {
for(int j = 0; j <= bagSize; j++) {
System.out.print(dp[i][j] + " ");
}
System.out.println('\n');
}
}
public static void main(String[] args) {
int[] weight = {1, 3, 4};
int[] value = {15, 20, 30};
int bagSize = 4;
testWeightBagProblem(weight, value, bagSize);
}
}
输出dp数组: