智能计算: 最新进展、挑战和未来(Intelligent Computing: The Latest Advances, Challenges and Future)
Intelligent Computing: The Latest Advances, Challenges and Future
Abstract
计算是人类文明发展的一个重要推动力。近年来,我们见证了智能计算的出现,在大数据、人工智能和物联网时代,智能计算作为一种新的计算范式,正在重塑传统计算,以新的计算理论、架构、方法、系统和应用推动数字革命。智能计算极大地拓宽了计算的范围,使其从传统的数据计算扩展到日益多样化的计算范式,如感知智能(perceptual intelligence)、认知智能(cognitive intelligence)、自主智能(autonomous intelligence)和人机融合智能(humancomputer fusion intelligence)。长期以来,智能和计算经历了不同的演化和发展路径,但近年来却日益交织在一起:智能计算不仅以智能为导向,也以智能为驱动。这种交叉融合促使了智能计算的出现和快速发展。智能计算仍处于起步阶段,预计很快就会在智能计算的理论、系统和应用方面出现大量的创新。我们首次对智能计算的文献进行全面调查,涵盖其理论基础、智能与计算的技术融合、重要应用、挑战和未来展望。我们相信,这项调查非常及时,将为学术界和工业界的研究人员和从业人员提供一个全面的参考,并为智能计算投下宝贵的洞察力。
Keywords: 数据计算(Data intelligence), 自主智能(Autonomous Intelligence), 大型计算系统(large computing systems), 计算架构和范式(computing architectures and paradigms), 科学计算(computing for science)
1. Introduction
人类社会正从一个信息社会迎来一个智能社会,其中计算已经成为制定和推动社会发展的关键因素。在万物互联的数字文明新时代,传统的数据计算远远不能满足人类对更高智能水平的日益增长的努力。人们对智能计算越来越感兴趣,加上计算科学的发展,对物理世界的智能感知,以及对人类意识认知机制的理解,共同提升了计算的智能水平,加速了知识的发现和创造。
近年来,计算和信息技术迅速发展,得益于深度学习的空前普及和成功,人工智能(AI)已被确立为人类探索机器智能的前沿领域。在此基础上,产生了一系列突破性的研究成果,包括Yann LeCun提出的卷积神经网络(CNN)和Yoshua Bengio在深度学习的因果推理领域的贡献[1, 2]。Georey Hinton,人工智能的先驱之一,在2006年提出了深度信仰网络模型和反向传播优化算法[3]。Jurgen Schmidhuber,另一位重要的人工智能研究者,提出了最广泛使用的递归神经网络(RNN),长短期记忆(LSTM)[4]。它已被成功应用于许多领域,用于处理整个数据序列,如语音、视频和时间序列数据。2016年3月,DeepMind推出的人工智能围棋程序AlphaGo与世界顶级人类围棋高手李世石展开对战,引起了全世界空前的关注。这场划时代的人机大战以人工智能的压倒性胜利告终,并成为将人工智能浪潮推向一个全新高度的催化剂。
人工智能的另一个重要推动者是大型预训练模型的出现,这些模型已经开始广泛用于自然语言和图像处理,在迁移学习的协助下处理各种各样的应用。例如,GPT-3已经证明,一个具有高度结构复杂性和大量参数的大模型可以提高深度学习的性能。在GPT-3的启发下,出现了一大批大规模的深度学习模型[5][7]。
计算能力是支撑智能计算的重要因素之一。鉴于信息社会中天文数字般的数据源、异构的硬件集群和不断变化的计算需求,智能计算主要通过垂直和水平架构满足智能任务的计算能力要求。垂直架构的特点是同质化的计算基础设施,主要通过应用智能方法提高资源利用效率来提升计算能力。相比之下,水平架构协调和安排异构和广域计算资源,以最大限度地提高协作计算的效率。例如,2020年4月,针对全球COVID-19研究的计算需求,Folding@home在三周内结合40万名计算志愿者实现了2.5 Exaflops的计算量,超过了世界上任何超级计算机[8]。实现如此巨大的计算能力,是横向计算协作的成功。
尽管在智能和计算方面已经取得了巨大的成功,但我们仍然在以下两个各自的领域面临着一些重大挑战:
智能方面的挑战。使用深度学习的人工智能目前在可解释性、通用性、可进化性和自主性方面面临重大挑战。与人类智能相比,目前的大多数人工智能技术只能发挥微弱的作用,而且只在特定的领域或任务中发挥良好的作用。实现强大而普遍的人工智能仍有很长的路要走。最后,从基于数据的智能升级到更多样化的智能形式,包括感知智能(perceptual intelligence)、认知智能(cognitive intelligence)、自主智能(autonomous intelligence)和人机融合智能(human-machine fusion intelligence)等等,也存在着重大的理论和技术挑战。
计算方面的挑战。数字化浪潮带来了应用、连接、终端和用户的空前增长,以及产生的数据量,都需要巨大的计算能力。例如,人工智能所需的计算能力每100天翻一番,预计在未来5年内将增加100多万倍。随着摩尔定律的放缓,要跟上如此快速增长的计算能力要求变得很有挑战性。此外,智能社会中的巨大任务依赖于各种特殊计算资源的有效组合。此外,传统的硬件模式不能很好地支持智能算法,这限制了软件的发展。
到目前为止,还没有普遍接受的智能计算的定义。一些研究者认为智能计算是人工智能和计算技术的结合[9][11]。根据人工智能的发展,它标志着智能计算系统的三个不同的里程碑。这种观点将智能计算的定义限制在人工智能的范围内,同时忽略了人工智能的固有局限性以及人、机器和事物之间的三元互动的重要作用。另一个学派将智能计算视为计算智能。这一领域模仿人类或生物智能来实现解决特定问题的最优算法[12],并将智能计算主要视为一种算法创新。然而,它没有考虑到计算架构和物联网(IoT)在智能计算中发挥的重要作用。
我们从解决复杂的科学和社会问题的角度提出了智能计算的新定义,考虑到世界的三个基本空间,即人类社会空间、物理空间和信息空间之间日益紧密的融合。
定义1(智能计算)智能计算是指在支持全世界互联的数字文明时代,包含了新的计算理论方法、架构体系和技术能力的领域。智能计算根据具体的实际需求,以最小的成本完成计算任务,匹配足够的计算能力,调用巢穴算法,获得最优结果。
针对人类社会、物理世界和信息空间三者融合的快速增长的计算需求,提出了智能计算的新定义。智能计算以人为本,追求高计算能力、能源效率、智能化和安全性。它的目标是提供普遍、高效、安全、自主、可靠和透明的计算服务,以支持大规模和复杂的计算任务。图1显示了智能计算的整体理论框架,它体现了支持人类-物理-信息整合的各种计算范式。
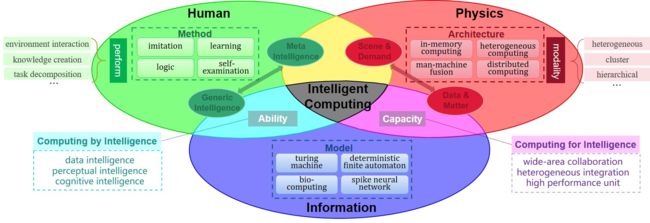
首先,智能计算既不是对现有超级计算、云计算、边缘计算以及神经形态计算、光电计算、量子计算等其他计算技术的替代和简单整合。相反,它是一种通过根据任务要求系统地、整体地优化现有计算方法和资源来解决实际问题的计算形式。相比之下,现有的主要计算学科,如超级计算、云计算和边缘计算,属于不同的领域。超级计算旨在实现高计算能力[13],云计算强调跨平台/设备的便利[14],而边缘计算则追求服务质量和传输效率。智能计算动态地协调边缘计算、云计算和超级计算领域之间的数据存储、通信和计算。它构建了各种跨域的智能计算系统,以支持端到端的云协作、云间协作和超级计算的互联。智能计算应充分利用现有的计算技术,更重要的是促进新的智能计算理论、架构、算法和系统的形成。
二是提出智能计算,解决未来人类-物理-信息空间一体化发展中的问题。随着大数据时代信息技术应用的发展,物理空间、数字空间和人类社会之间的界限变得越来越模糊。人类世界已经演变成一个以人、机器、物紧密融合为特征的新空间。我们的社会系统、信息系统和物理环境构成了一个动态耦合的大系统,人、机、物在其中以高度复杂的方式整合和互动,这促进了未来新计算技术和应用场景的发展和创新。
我们提出了智能计算文献中的第一个全面调查,涵盖其理论基础、智能与计算的技术融合、重要应用、挑战和未来前景。据我们所知,这是第一篇正式提出智能计算的定义及其统一理论框架的评论文章。我们希望这篇评论能够为学术界和工业界的研究人员和从业人员提供一个全面的参考,并对智能计算提出宝贵的见解。
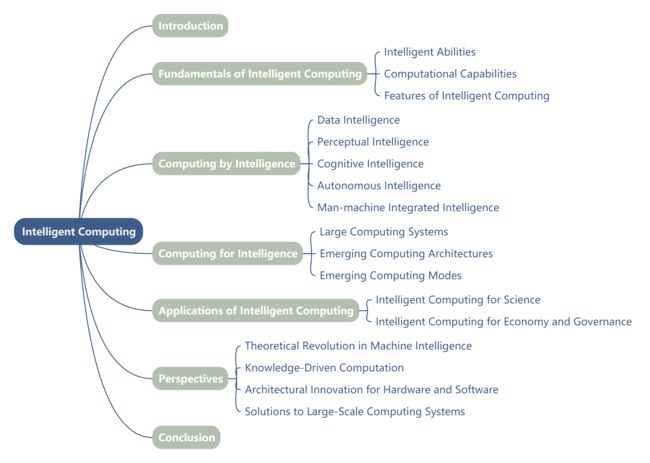
本文的其余部分组织如下。第2节介绍了智能计算的基本原理。第3节总结了由各种智能方面赋予的计算方法,以提高计算性能。第4节描述了大型计算系统、新兴计算架构和模式,以满足对智能模型计算能力的迫切需求。第5节展示了智能计算在科学和社会领域的几个重要应用。第6节提出了对智能计算未来发展的展望。最后,第7节是本文的结论。图2显示了本文的主要结构。
2. Fundamentals of Intelligent Computing
智能计算是数字文明时代支持万物互联的新计算理论方法、架构系统和技术能力的总称。它探索了许多经典和前沿研究领域的创新,以解决复杂的科学和社会问题。智能计算的基本要素包括人类智慧、机器能力和由万物组成的物理世界。在本节中,我们介绍了智能计算所期望的智能能力和计算能力。我们还描述了智能计算的特点,以及如何在人类-物理-信息世界中结合智能与计算。
2.1 智能能力(Intelligent Abilities)
在该理论框架中,人是智能计算的核心,是智慧的源泉,代表着原始和固有的智能,被称为元智能。元智能包括人类的高级能力,如理解、表达、抽象、推理、创造和感受,其中包含了人类所积累的知识[15][21]。
所有智能系统都是由人类设计和建造的。因此,在智能计算的理论体系中,人类的智慧是智能的源泉,而计算机是由人类的智能赋予的。我们把计算机的智能称为通用智能。通用智能代表了计算机解决复杂问题的能力,具有广泛的扩展性,包括自然语言处理[22]、图像识别[23]、语音识别[24]、目标检测和跟踪[25]等。元智能和通用智能之间的关系如图3所示,并在以下部分详细介绍。

2.1.1 元智能(Meta Intelligence)
元智能,也叫自然智能,以碳基生命为载体,由生物体个体和群体经过数百万年的进化产生。它包括生物体现智能、大脑智能(尤其是人脑)和蜂群智能。其中,生物体现智能是由生物体广泛获得的。它们可以接受环境的输入,完成适合其物理形态的特殊任务,并感知环境的变化,做出最有利的智能行为。此外,生物体还可以使用工具并改变其环境,以获得更好的生存机会。自然界中智力水平最高的是人类,他们不仅有坚实的生存能力,而且有感受和应对复杂环境的能力,例如,感知和识别物体,表达和获得知识,以及复杂的推理和判断。人类个体的智力是一种综合能力。
更确切地说:
- 他们执行高度复杂的认知任务。
- 他们可以完成困难的学习,理解抽象概念,进行逻辑推理,并提取有意义的模式。
- 他们可以最大限度地利用和改造自然环境,并可以构建一个数百万人数量级的合作社。
- 他们具有自我意识
第二,它是大脑智能。人脑是一个由大量神经元组成的复杂而动态的巨型神经网络系统。它的神秘面纱还没有完全揭开,这导致人们对智能的理解模糊不清。但就整体功能而言,人脑的智能表现是可以区分的。学习、发现和创造等能力是智力的明显表现。进一步分析发现,人脑的智能及其发生在其心理层面上是可见的,通过一些心理活动和思维过程表现出来[26]。因此,智力可以在宏观的心理学层面上被否认和研究。我们把人类智力表现的宏观心理层面称为大脑智力。我们大脑中负责不同感知或思维功能的不同区域作为一个统一的整体进行合作。
第三,它是蜂群智能。蜂群智能是一种高级智能,低级智能昆虫或动物通常通过聚集、协调、适应和其他简单行为产生。Gerardo和Wang首次提出了蜂群智能的定义[27]。蜂群智能优化算法模拟了自然界生物的迁移、觅食和进化过程中的分裂和合作。它将搜索空间中的点作为自然界的个体,将搜索和优化过程作为个体的觅食或进化过程。搜索和优化群集智能算法具有生成和验证的特点,它用更好的方案反复替换不太可行的方案,其灵感来自于适者生存(survival of the fittest)。
2.1.2 通用智能(Generic Intelligence)
通用智能,也叫机器智能,以硅基设施为载体,由个人和群体的计算设备产生。生物智能可以在以下四个层面移植到计算机上:数据智能(data intelligence)、感知智能(perceptual intelligence)、认知智能(cognitive intelligence)和自主智能(autonomous intelligence)。数据智能包括计算机对数据进行形式化、表达、计算、记忆和快速存储的能力。感知智能是指通过各种传感器和I/O设备获取信息,如语音、图像和视频。认知智能是指理解、思考、推理和解释的能力。自主智能代表了机器获得自我驱动和意识的能力。这四种类型的智能通常在进行复杂任务时进行合作。
数据智能强调通过计算方法实现生物内部智能行为,对自然规律进行编程[28]。它主要以计算理论为指导,依托计算机硬件的基本存储和计算能力,实现数据的原始智能[29]。数据智能采用了五种领先的互补技术的组合:用于基本数学功能的符号和数值计算,使计算机能够模仿人类的语言推理的模糊逻辑;基于大数据和统计规律的概率方法;通过具有大量参数的模型学习经验数据的人工神经网络构建;从自然界获得灵感的进化计算用于搜索和优化。将数据智能整合到这些相对成熟的分支中,形成了各种科学的方法。
感知智能表示具有视觉、听觉和触觉等感知能力的机器可以接触到外部世界。来自物理世界的信号通过麦克风、照相机和其他传感器,利用语音和图像识别映射到数字世界中。机器通过结构化的多模态现实世界数据与人类进行类似的交流和互动[30, 31]。感知智能完成了大规模数据的收集和图像、视频、音频和其他数据类型的特征提取,完成结构化处理。计算机为用户连接的硬件和软件更舒适地呈现数据。例如,自动驾驶利用光探测和测距方法(激光雷达)、其他传感设备和人工智能算法进行驾驶信息计算。人脸支付是一种通过感知人脸数据进行身份确认的设备。
认知智能表示机器具有类似人类的逻辑思维和认知能力,尤其是主动学习、思考、理解、总结、解释、计划和应用知识[32]。认知智能的发展由三个层次组成。第一个层次是学习和理解,如文本解析、自动标记、问题理解等。第二个层次是分析和推理,如逻辑连接和内涵抽象。第三层次是思考和创造。
自主智能意味着机器可以像人一样行动,具有自我驱动的自我、情感和意识。它将机器从严重的数据依赖中解放出来,并使它们能够根据环境的变化来学习学习技巧和更新其解决问题的能力。自主智能的最终目标是实现自我学习、有目的的推理和自然的互动,几乎不需要甚至不需要事先进行人类编程。
智能计算面临着大场景、大数据、大问题和无处不在的要求的挑战。算法模型越来越复杂,需要超级计算能力来支持越来越大的模型训练。目前,计算资源已经成为提高计算机智能研究水平的一个障碍。随着智能算法的发展,拥有丰富计算资源的机构可能形成系统的技术垄断。经典的超级计算机不适合人工智能对计算能力的需求。虽然算法优化可以在一定程度上减少对计算能力的需求,但不能从根本上解决这个问题。需要从架构、加速模块、集成模式、软件栈等多个维度进行全面优化。
最直观和有效的广域协作方法是通过垂直提升和水平扩展加强基础计算能力。首先,垂直提升是指利用技术迭代、材料创新、架构设计等手段提升计算部件的单位性能,提高单个芯片在单位时间内所能处理的指令数量上限。在传统的冯-诺依曼架构下,通过技术手段突破性能极限,满足图形渲染和深度学习训练任务的计算性能要求。这些芯片有足够的能力来支持先进的深度学习算法和当今主流计算机的即插即用。
随着摩尔定律的放缓,传统的冯-诺伊曼计算模型将很快面临性能上限。Dennard 缩放定律的结束将导致功耗和散热问题成为处理器频率增长的障碍。传统的存储设备无法同时获得高速度和高密度。现有的以计算为中心的冯-诺依曼架构依靠由内存和存储组成的分层存储结构来维持计算性能和存储容量之间的平衡。该结构需要频繁地在处理器和存储器之间传递数据,因此计算效率下降,带宽受到限制,造成了 "存储墙 "问题。在这种情况下,内存计算成为突破冯-诺依曼系统瓶颈的有效措施,提高了整体的计算效率。
为了突破传统芯片结构的限制,智能计算需要通过横向扩展探索新的芯片。鉴于传统电子计算方法所面临的挑战,建立在材料科学、光子学和电子学等多学科领域的集成光子学的出现令人振奋。量子计算以量子力学原理为基础,利用量子叠加、纠缠和量子相干实现了量子并行计算,从根本上改变了传统的计算概念。生物计算是基于生物系统固有的信息处理机制而发展起来的。与传统计算系统相比,它的结构一般是并行的和分布式的。
由于数据中心的计算能力多样化已经成为一种趋势,通用化和专业化的计算芯片将并行发展。以CPU和其他通用计算芯片为核心的传统技术要满足大规模数据处理的要求是相当具有挑战性的。通用技术与专用技术的融合已成为一种有前途的方法。
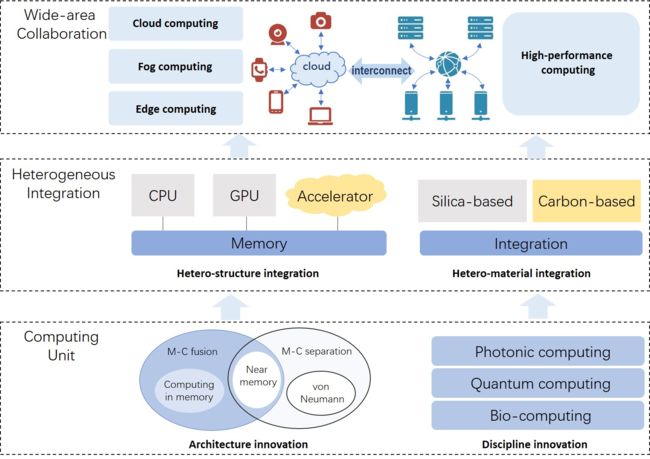
2.2.2 系统的异质整合(Heterogeneous Integration of Systems)
异质集成包括异质结构集成(hetero-structure integration)和异质材料集成(hetero-material integration)。异质结构集成主要是指将由多个加工节点制造的芯片封装在一起,以提高功能和性能。它可以封装由不同工艺、功能和制造商制造的部件。半导体技术的发展已经达到了物理极限,电路也变得更加复杂。传统的方式,即通过提高CPU的时钟频率和核心数量来提高计算能力,已经遇到了散热和能源消耗的瓶颈。异构集成可以解决这个问题。通过异构集成,不同的计算单元采用混合计算架构。每个计算单元执行其适当的任务,有效地提高计算性能。异质结构集成可分为芯片级和系统级。芯片级异构集成是一种整合不同芯片以提高整体芯片效率的方法。目前,主流的异质结构集成技术主要包括 2D/3D 封装、芯片等。系统级异构集成提供了单机多处理器和多机形式的各种计算类型,包括单机多计算、单机混合计算、同构异构多机和异构多机。
异质材料集成是指不同材料的半导体元件的集成,以实现小尺寸、良好的经济性、高灵活性和更好的系统性能。通过硅和碳的整合,将生物元件用于信息处理和计算,被认为是一种创新的探索。作为生物结构和功能的基本单位,单细胞是一个独立而有序的系统,能够对外界刺激和环境变化作出反馈和自我调节。其运行机制经历了长期的进化,因此能够满足其代谢的需要。作为遗传信息的天然储存载体,细胞中的DNA具有高储存能力和密度的特点。在数亿年的进化过程中,生物细胞也对其生化过程进行了优化,以尽量减少代谢过程的能量消耗。生物组件显示了存储容量、计算并行性和超低计算能力消耗的潜力。碳基和传统硅基芯片的有效整合有望在计算能力、存储密度和能源效率方面达到新的高度。
2.2.3 广域资源整合(Wide-Area Collaboration of Resources)
广域协作的人机物一体化(human-machine-thing integration)场景下的数据具有地域分布广、场景覆盖全、集体价值大等特点。从时间维度看,实时采集、感知、处理和智能数据分析需要分布式并行计算能力的支持,在任何地方都可以使用。因此,广域协作是非常必要的。广域协作计算将高性能计算(HPC)、云计算、雾计算(fog computing)和边缘计算(edge computing)等计算资源低成本地连接起来。它实现了供应方资源的自动横向扩展。需求方的多样化任务需要一个跨管理领域的新的计算基础设施,并以低成本、高效率和高度信任的方式按需协作。在支持万物互联的智能计算场景的引领下,广域协作计算以自主和点对点的方式支持资源的纵向和横向融合。在建立安全可靠的智能计算的新基础设施中,存在着跨领域的资源和任务的智能匹配、调度和协作的重大挑战。
提高广域协作的计算能力主要集中在两个科学问题上:广域协作模型的机制和广域协作系统的实现。广域协作模型主要强调资源抽象、解耦和封装,并建立一个软件化的可编程实体抽象方法来屏蔽设备、计算和数据资源的异质性。它构建了一个基于互联和互操作性的软件化可编程协作模型、规则和流程,以支持形成跨独立利益相关者的计算、数据和设备的交互秩序。广域协作系统主要关注需求方的任务分解和多样化作业的调度;计算和数据资源的跨域融合和管理;开放环境下的数据隐私保护、身份信任和安全保护;多维度的智能运维监控,破解资源分配、使用和业务执行的隐患。
2.3 智能计算的特点(Features of Intelligent Computing)
在本小节中,我们首先介绍智能计算发展的主要特征,然后揭示获得这些关键特征的创新路径。
2.3.1 面向对象的智能计算(Objective-Oriented Intelligent Computing)
如图5所示,智能计算具有以下特点:理论技术上的自学习和可进化性,架构上的高计算能力和高能源效率,系统方法上的安全性和可靠性,运行机制上的自动化和精确性,以及服务性上的协作性和普遍性。

如图 5 所示,智能计算具有以下特点:理论技术上的自学习(self-learning)和可进化性(evolvability),架构上的高计算能力(high computing capability)和高能源效率(high energy eciency),系统方法上的安全性(security)和可靠性(reliability),运行机制上的自动化(automation)和精确性(precision),以及服务性上的协作性(collaboration)和普遍性(ubiquity)。
自学习和可进化性(Self-learning and evolvability)。在脑神经科学的启发下,智能计算发展了几种新型技术,如神经形态计算和生物计算,以实现对冯-诺伊曼计算机结构原理和模型的突破。自学是指通过从海量数据中挖掘规则和知识,获得经验,并以可用的结果优化计算路径。同时,可进化性代表一种启发式的自我优化能力,模拟自然界中生物的进化过程,机器从环境中学习,随后进行自我调整以适应环境。
高计算能力和高能源效率(High computing capability and high energy eficiency)。为了超越传统的冯-诺依曼架构,智能计算发展到有关内存处理、异构集成和广域协作的新计算架构。高计算能力是指满足智能社会需求的计算能力,并作为水和电等基础设施。此外,高能效旨在最大限度地提高计算能效,尽可能地降低能耗,以确保对具有大规模特征、结构复杂、价值稀少的大数据进行有效处理。
安全性和可靠性(Security and reliability)。智能计算支持大规模泛在互连计算系统的跨域信任和安全保护。它建立了独立、可控的可信安全技术和支持系统,实现了数据的融合、共享和开放。高信任是指通过可信的硬件、操作系统、软件、网络和私有计算,实现身份、数据、计算过程和计算环境的信任。特别是,高安全性是指通过整合各种隐私保护技术,保证计算系统的网络安全、存储安全、内容安全和流通安全。
自动化和精确性(Automation and precision)。智能计算是以任务为导向的;它匹配计算资源,实现自动需求计算和精确的系统重建。系统结构根据任务执行情况不断调整。在软件和硬件层面上进行定向耦合重构。计算过程的自动化包括资源的自动管理和调度,服务的自动创建和提供,以及任务生命周期的自动管理,这是评价智能计算的友好性、可用性和服务的关键。计算结果的精确性是计算服务的基础;此外,它还解决了一些困难,包括计算任务的快速处理和计算资源的及时匹配。
协作和泛在性(Collaboration and ubiquity)。智能计算整合现有技术,利用异质元素的各种感知能力、互补的计算资源、计算节点功能的协作与竞争,促进物理、信息、社会空间的渗透与融合。人与机器之间的合作提高了智能任务的智能水平,而泛在性通过结合智能计算的理论方法、架构系统和技术方法,使计算能够在任何地方进行。
2.3.2 智能和计算的融合(Fusion of Intelligence and Computation)
智能计算包括两个基本方面:智能和计算,两者相辅相成。智能促进了计算技术的发展,而计算是智能的基础。提高计算系统的性能和效率的高级智能技术的范式是 “利用智能计算”(computing by intelligence)。支持计算机智能发展的高效和强大的计算技术的范式是 “为智能而计算”(computing for intelligence)。这两个基本范式从多个方面进行了创新,以提高计算能力、能源效率、数据使用、知识表达和算法能力,实现泛在、透明、可靠、实时和自动服务。
按智能计算的范式。复杂模型的计算能力需求已经超过了一般计算机的一到两个数量级。此外,传统计算机的底层计算机制与智能模型的计算模式之间存在着相当大的差距,导致计算效率低。智能计算模式包括新的模型、支持、范式、机制和协同作用,利用智能方法来提高计算能力和效率。
目前,由于智能系统缺乏常识、直觉和想象力,只能在封闭的环境中处理特定的任务。对神经形态计算(neuromorphic computing)、图计算(graph computing)、生物计算(biological computing)和其他新的计算模型进行研究,分析人脑、生物和知识计算机制。这些新模型可以有效地提高认知理解和推理学习能力,适应性,以及智能算法的泛化效果。
由于计算系统结构的限制和端(end-to-end)到端计算能力的不足,目前计算系统的计算和响应速度需要进一步提高。智能计算可以通过利用新的计算支持技术,如内存中处理、边缘计算和在线学习,提高计算系统的实时性能。此外,新的技术,如感知与计算的融合、处理定位等,也成为有前景的研究热点。
三元空间的深度融合导致了计算任务的多样性,因此计算场景和数据更加非结构化,任务的解决方案也更加复杂和具有挑战性。因此,新的计算范式能够对非结构化场景进行分析和建模,并对非结构化数据进行自适应处理。它通过一个自动和智能的过程实现了透明计算,该过程结束了任务的理解、分解、解决和资源分配。
智能计算探索新的计算机制,如硬件和软件重构和合作进化,以处理不同类型的任务。在智能进程的执行过程中,新机制通过组织具有不同颗粒度和功能的计算资源对硬件进行管理。新机制将形成一个具有自主学习和进化迭代的自动计算系统,应用智能技术,包括软件和硬件的弹性设计,算法和模型的灵活合作,以及数据和资源的自适应分配。
新的协同计算架构,如人机交互、蜂群智能和人在环(human-in-loop)中,将人类的感知和认知能力与计算机的操作和存储能力相结合。而这样的新架构对提高计算机的感知和推理能力是有效的。机器可以有超高的计算速度和精度,也可以通过各种传感器巧妙地从物理环境中获取信息。然而,它们不能独立地分析这些信息和执行复杂的任务。值得注意的是,人类可以在更高的层次上研究物理环境,认识物理世界的规律,并在人机互动中把知识传递给机器。
智能计算的范式(The paradigm of computing for intelligence)。硬件架构的异质性和复杂性阻碍了计算能力的整合和服务质量的提高。智能计算范式设计了新的框架、方法、集成、架构和系统,以提高智能水平,并提供无处不在、透明、自动、实时和安全的计算服务。
鉴于智能设备的多样性、计算资源的离散性和网络连接的复杂性,整合硬件和有效地提高智能计算能力变得更加困难。计算框架的创新采用了非冯-诺依曼结构,其中包含了内存处理、异质集成和广域协作。此外,还设计了专用的硬件构建块。为了满足对高计算能力的需求,芯片的计算结构和系统感觉、时间表和计算资源管理都被优化。
提高有限的能源效率的一个新方法是应用新的计算方法,如生物计算和神经形态计算,来研究生命体的低功耗特性。由于功耗只有20W,人脑的学习程序比任何人工智能都要有效得多。通过学习生物和人脑的计算方法,设计新的计算硬件和软件,智能计算可能会极大地提高计算效率,减少计算过程中的能源消耗。
智能计算通过提高机器的智能、感知能力和对紧急情况的反应来促进有效的协调和发展人机一体化。通过人、机、物的全面连接,智能计算创造了一种深度整合的计算模式。人-机-物的共生融合、合作互补,为人类提供更加全面、周到、准确的智能服务。
传统的以集群为中心的计算架构无法为边缘终端节点和用户提供及时的服务。采用端到端云和广域协作等新的分布式计算架构,有效地整合超级计算、云计算、边缘计算和终端计算资源。通过智能任务分解解决了集中计算的问题,实现了高效、泛在的计算服务。
在人-物-信息一体化的计算环境中,更多的恶意攻击面可以被利用,使系统更加脆弱。同时,海量的多异质信息也带来了数据安全和隐私问题。通过构建内生的安全方法和可信的计算机制,建立了一个新的安全可信的智能计算系统来解决这些问题。它确保了计算过程、身份、数据和结果的安全和信任。
3. 利用智能计算(Computing by Intelligence)
在本节中,我们描述了计算机的四种智能能力和综合智能的模式。对于每一种智能,我们介绍了在典型研究领域的显著进展。
3.1 数据智能(Data Intelligence)
提高计算的普遍性对智能计算至关重要。现实世界场景中的问题,如模拟、图形等,需要各种计算。智能计算的另一个关键点是如何提高计算的智力水平。从经验上看,我们都需要向自然界中的智能生物学习,计算也不例外,比如三种经典的智能方法:人工神经网络、模糊系统和进化计算。智能计算的理论包括但不限于上述类型的计算,以实现高水平的泛在性和智能。
3.1.1 模拟计算(Analog Computing)
模拟计算模型的复杂程度范围很广,其中滑尺(slide rule)和提名图(nomogram)是最简单的类型。相比之下,舰炮控制计算和大规模的数字/模拟混合计算则更为复杂[33, 34]过程控制和保护继电器系统使用模拟计算来控制和保护。根据不同的计算方法和应用领域,模拟计算有多种类型[35-39]。
与普通的数字计算相比,模拟计算既有优势也有劣势。它在计算和分析方面都实现了实时操作,可以同时操作多个数值。它的硬件设计简单,没有传感器要求将输入/输出转换为数字电子形式,带宽消耗较少。尽管如此,模拟计算的可运输性较差。模拟计算机只能解决一个预设的问题类型。由于计算受到环境因素的影响,要获得精确的解决方案通常是很困难的。
3.1.2 图计算(Graph Computing)
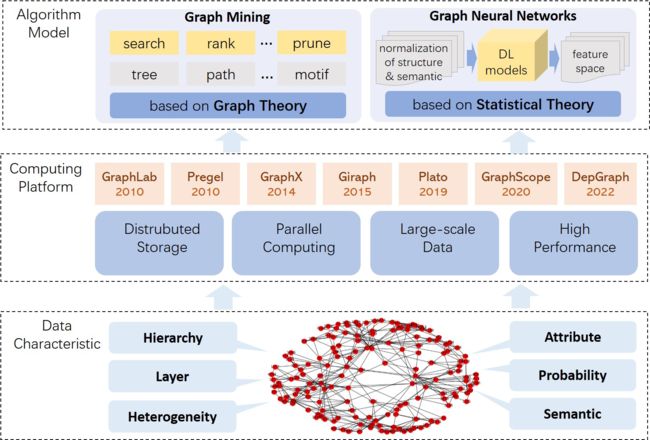
在数学上,图论是对图的研究,它是用来模拟对象之间成对关系的数学结构。图对于代数、几何、群论和拓扑学等数学理论至关重要。图处理使用图作为数据模型来表达和解决问题,它可以完全描绘出事物之间的关系。图计算架构在数学和相关领域,如动态系统和复杂性计算中也显示出很好的应用价值。近年来,图处理专注于大规模图数据领域,旨在实现大规模图的数据存储、管理和高效计算。
传统的图处理是基于图论的。它基于图结构的基本属性研究各种问题,包括搜索、挖掘、统计、分析、转换等问题。这些问题往往以节点或边的查询、遍历、排序、集合操作为基本运算符,计算出目标结果的精确或最佳近似解。
随着图数据规模的增大,主流研究方向是将图处理与大数据相关技术相结合,如分布式计算、并行计算、流计算、增量计算等。一些基于批处理消息的以节点为中心的并行图处理引擎被设计用来专门处理并行图处理任务,如Pregel[40]、Giraph[41]、Graphx[42]、GraphScope[43]、DepGraph[44]等。除了数据量的扩展,一些研究还扩展了图的数据模型。引入了属性、标签、概率、层次和其他特征,以解决更复杂的应用需求和建模挑战。随着数据库技术的发展,图数据库以其全面的应用场景和灵活的模型表达而强势崛起。它们已经成为新兴的NoSQL数据家族中的四个核心成员之一。图模型的扩展体现在存储和管理图数据等任务中。另一方面,模型的内涵扩展为各种图处理的算法演变带来了算法复杂性的增量。此外,它使计算问题的结果更适合在自然场景中应用。
近年来,随着深度学习技术的发展,图数据被作为神经网络模型的输入,并衍生出各种类型的图神经网络模型和计算方法。图神经网络,如图卷积网络[45]、递归神经网络[46]、图注意网络[47]、图残差网络[48],都是从深度学习的技术框架中发展起来的。他们从结构性数据移植到半结构性数据,保留了模型的结构和功能的特点。同时,针对图数据结构改进核心数学模型,在分类、预测、异常检测等问题上取得良好的计算效果。
3.1.3 人工神经网络(Artificial Neural Network)
自20世纪80年代以来,工程技术被用来模拟人脑神经系统的结构和功能,构建人工神经网络。人工神经网络通过许多非线性处理器模仿大脑神经元的连接。它模拟了突触之间的信号传输行为与计算节点之间的输入和输出。心理学的W.S. McCulloch和数理逻辑的W. Pitts在1943年开发了被称为MP模型的神经网络和数学模型[49]。他们建议使用MP模型作为严格的数学描述和神经元的网络结构的基础。人工神经网络研究是建立在他们发现单个神经元可以进行逻辑运算的基础上。BP算法是由Rumelhart、Hinton和Williams在1986年创立的[50]。损失的反向传播和信号的前向传播构成了BP算法。因为多层前馈网络通常是由反向传播算法训练的,所以多层前馈网络通常被称为BP网络。

经过几十年的发展,已经提出了近40种人工神经网络模型,包括反向传播网络、感知器、自组织地图、Hopeld网络、玻尔兹曼机等。近年来,许多经典模型,如CNNs[51]、RNNs[52]和LSTMs[53],已被广泛用于图像、语音、文本、图形等领域的各种分类和预测任务。人工神经网络模型的训练在很大程度上取决于数据量。随着数据量的爆炸和模型复杂性的加深,人们开始将模型的训练和应用分开。模型基于大型海洋数据集进行预训练,保存起来,然后利用迁移学习技术应用于问题,以获得快速解决方案。谷歌人工智能研究所提出的BERT和OpenAI开发的GPT-3是两个最著名的预训练模型[54, 55]。它们在自然语言处理方面取得了巨大的成功[56]。
人工神经网络是深度学习(DL)系统的关键构建块,包括深度强化学习(DRL)系统。DRL系统使用多层神经网络来解决马尔科夫决策问题(MDPs)[57]。单人和多人的DRL模型都被越来越多地用于智能解决各种计算问题(如决策/控制和预测问题),否则以实时方式解决这些问题是不可行的。
3.1.4 模糊系统(Fuzzy Systems)
Lot Zadeh最初在1965年提出了模糊逻辑的概念[58]。模糊系统是一种基于 "真假程度 "的模糊逻辑的计算技术,而不是当代计算机所依据的典型的 “真假”(1或0)布尔逻辑。0和1的绝对值不能为自然语言提供一个很好的类比,也不能充分地描述生活或宇宙中的大多数其他活动。模糊逻辑可能被视为思维的真正运作方式,而二进制或布尔逻辑是一个子集。
"系统 "一词指的是一组相互依存的部分相互作用,并具有明确的结构[59]。系统可以从外部环境中被识别为一个复杂的整体。输入和输出是一个系统与周围环境互动的渠道。模糊系统(Fuzzy systems)是当使用传统的集合理论和二进制逻辑不切实际或难以实现时,使用模糊方法建立的信息处理架构[60]。它们的主要特征是将符号信息表示为模糊的条件(if-then)规则。
四个功能构件,即模糊器(fuzzier)、模糊推理引擎(fuzzy inference engine)、知识库(knowledge base)和去模糊器(defuzzier),构成了模糊系统的常规结构[60]。模糊系统可以把清脆的数据和语言值作为输入。如果你正在处理干脆数据,你应该把重点放在模糊化阶段,而不是推理阶段,这时相应的模糊集被分配给非模糊输入。适当的近似推理方法被用来将输入值转化为输出变量的语言值。模糊条件规则被用来反映专家的知识。当模糊系统需要数字输出信息时,利用去模糊化方法将适当的数据集与产生的模糊集匹配。
当缺乏全面的数学描述或使用精确(非模糊)模型的成本很高或很难时,模糊系统就有了实际应用。模糊系统是处理不完整数据的好工具,例如,用于信号和图像处理[61, 62]、系统识别[63, 64]、决策支持[65, 66]和控制过程[67, 68]。
3.1.5 进化计算
进化计算(Evolutionary computation)是一种独特的计算类型,它以自然进化的过程为线索。一些计算机科学家从自然进化中寻找灵感,这并不奇怪,因为构成我们星球的众多生物体都是被专门设计来在它们的利基环境中茁壮成长的,这显示了自然界中进化的力量。进化计算的一个关键点是将这种强大的自然发展与一种被称为 “试错”(也被称为 “生成-测试”)的特殊问题解决方法进行比较。潜在解决方案的价值,或者说它们如何有效地解决这个问题,决定了它们被保留并作为开发其他潜在解决方案的构建块的可能性。随后,我们将对遗传学和进化论的相关部分进行描述。
在20世纪40年代,早在计算机发明之前,就已经有了利用达尔文原则来自动解决问题的想法[69]。1948年,图灵创造了 "genetic or evolutionary search"这一短语,到1962年,Bremermann对 "optimization by evolution and recombination"进行了计算机测试。在整个60年代,出现了核心思想的三种不同的实现方式。Holland将他的方法命名为遗传算法(genetic algorithms)[70],而Fogel、Owens和Walsh在美国提出了进化编程(evolutionary programming)[71, 72]。德国的Rechenberg和Schwefel同时创造了优化的进化策略(evolution strategies for optimization)[73]。这些领域独立发展了大约15年。自20世纪90年代初,它们被认为是不同的技术方言,后来被称为进化计算(evolutionary computing)[74]。20世纪90年代初,第四个流向,即遗传编程,由Koza[75]按照主要概念推广。根据目前的术语,进化计算指的是整个领域,所涉及的算法被称为进化算法(evolutionary algorithms),而进化编程(evolutionary programming)、进化策略(evolution strategies)、遗传算法(genetic programming)和遗传编程(genetic programming)被认为是属于相应算法变体的子领域。
3.2 感知智能(Perceptual Intelligence)
一个智能系统在开始工作之前,首先开始智能感知。因此,感知智能在所有智能系统中起着至关重要的作用。感知智能的重点是多模态感知、数据融合、智能信号提取和处理。典型的例子包括智能城市管理,自动潜水系统,智能防御系统,和自主机器人。对感知智能最一致的热情是类似人类的素感能力,包括视觉、听觉、嗅觉、味觉和触觉。此外,智能传感还包括温度、压力、湿度、高度、速度、重力等,只要在计算或数据训练方面做出显著的努力,就可以推进其性能。
在过去的几十年里,机器视觉出现了巨大的进步,强调创造出能够独立看到和理解其周围环境的设备。由于状态的约束范围和明确否认的情况,对工业过程的观察在制造背景下不再是一个挑战[77]。然而,从工业过程到现实世界中的自由环境感知,这种情况成为一个显著的挑战。因为有无限多的情况和意外事件可能随时发生,由一个完全自主的机器人来处理这些情况仍然是一个挑战。相反,即使是一个蹒跚学步的孩子也能毫不费力地观察这个世界。我们的大脑拥有最有效的电路和处理系统,使我们能够处理来自数百万个感官感受器的感官数据。如果这些电路和过程能够被理解并在技术上实现,机器智能无疑将经历一场革命。应用包括公共和私人建筑中的安全和保安监控,以及在养老院和医院中观察老年人或身体或心理受损的人的行为和健康[78]。此外,它还可以使老年人在家中停留更长时间[79]。像这样的模型对于必须穿越周围环境和控制周围事物的自主机器人通过感知用户需求使用户更加舒适的情景下,会有很大用处[80]。
随着模式识别和深度学习技术的完全使用,近年来机器的感知智能已经超过了人类,在语音、视觉和触摸识别方面取得了显著的进步。由于智能传感器的重要性和许多可能的应用,它们受到了广泛的关注。由于计算机和物联网在制造业中的整合,普通的传感器已经变得智能,允许它们用收集的数据进行复杂的计算[81]。智能传感器在能力、尺寸和灵活性方面都得到了扩展,将笨重的机械转化为高科技的智能。智能传感器已经发展成为具有检测和自我意识能力的物体,因为它们带有信号调节、嵌入式算法和数字接口[82]。这些传感器被设计成物联网组件,将实时数据转化为可以发送到网关的数字数据[83]。过程控制和质量评估只是这些设备所提供的众多功能中的两个。由于基于云的分析工具和人工智能,智能传感器数据也可用于通过流程优化和预测性维护来最大限度地降低制造成本。从供应管理到全球资源协调,传感器数据一旦在线传输,就可以以多种方式使用。智能传感器有各种形状和尺寸,以满足不同应用的需要,如图8所示,而且新的和更好的模型一直在开发中。最普遍的传感器类型之一是测量光强度和色温的光传感器。从像TE Connectivity这样的大型组合公司到像Aceinna这样的更专业的供应商,几乎任何种类的过程或环境情况都有一种传感器类型。
智能传感器还可以预见、监测和立即响应补救情况。智能传感器的主要任务包括原始数据收集、灵敏度、过滤调整、运动检测、分析和通信[84]。例如,智能传感器的一种用途是无线传感器网络,其节点与一个或多个额外的传感器和传感器中心耦合在一起,形成一些通信技术。此外,来自几个传感器的数据可用于对已经存在的问题进行推断;例如,温度和压力传感器数据可用于预测机械故障的开始。

3.3 认知智能(Cognitive Intelligence)
认知智能是指机器具有像人类一样的逻辑理解和认知能力,尤其是思考、理解、总结和积极应用知识的能力。它描述了在现实环境中处理复杂事实和情况的能力和技巧,如解释和规划。数据识别是感知智能的核心功能,需要对图像、视频、声音和其他类型的数据进行大规模的数据收集和特征提取,完成结构化处理。相比之下,认知智能需要理解数据元素之间的关系,分析结构化数据中的逻辑,并根据提炼的知识做出反应。认知智能计算主要研究机器的自然语言处理、因果推理和知识推理等课题。通过对人脑的神经生物学过程和认知机制的启发式研究,机器可以提高其认知水平,以协助、理解、决策、获得洞察力和发现。
3.3.1 自然语言处理(Natural Language Processing)
自然语言处理将人类语言转换为机器语言,使机器能够理解和计算。这项研究有一个非常漫长的任务环节,从上游的信息提取、数据清洗、数据检索和预训练[54, 55],到下游的文本分类、问题回答系统和自动摘要等。自然语言处理集中在两个主要任务上:自然语言理解(NLU)和自然语言生成(NLG)。NLU理解文本的意义,其程度是必须把握住单词和结构。其具体步骤包括词汇分析、句法分析和语义分析。
词汇分析在中文自然语言处理的词条分割模块中起着关键作用[85]。词汇分析的关键部分包括词的分割、语篇标签、命名实体识别和词义消歧。语音部分和语义标签是词法分析的主要功能。词义消歧主要解决的是不同语境下的词义问题,因为一个词根据不同的语境可能有众多的含义,有必要为眼前的任务语境选择最合适的词义。命名实体识别的主要目标是定位和注释上下文中具有特定含义的词,如人名或地名。词汇分析的基础是由规则、统计和机器学习构成的[86]。
确定一个句子的每个组成部分(或其句法结构)之间的关系是句法分析的主要目标。乔姆斯基的语法层次(Chomsky’s hierarchy of grammar)是目前流行的无语境句法模型。它通过一套完整的分析方法获得一个句子的句法树。
关于NLU的研究大多集中在语义分析上。它涵盖了自然语言理解的每个阶段。语义分析指的是在几个粒度级别上的三个主要任务:单词级别的意义辨析,句子级别的语义角色标注,以及话语级别的核心推理消化。作为语义分析的辅助手段,语用分析和效果分析也得到了广泛的研究。语用分析主要研究文本与环境的关系,包括说话者、接受者、语境等。情感分析可以获得用户的偏好、情绪和讲话的潜在倾向。早期的研究通过建立情感字典做出了贡献[87, 88]。近年来,基于机器学习和深度学习的方法已经开始通过构建学习模型来分析文本的情感特征[89, 90]。
NLG从原始文本、数据和图像中生成新的文本信息。主要应用是机器翻译(machine translation)[91]、问答系统(question and answer system)[92]、自动摘要(automatic abstract)[93]和跨模式文本生成(cross-modal text generation)[94]。NLG的经典方法分三个阶段。首先,确定应该建立什么目标,并决定文本中应该包括什么。其次,通过评估场景和可用的交际资源来规划如何实现目标,如文本结构化、句子聚合、词汇化和指代表达生成。最后,按照计划生成文本。近年来,随着神经网络的发展和任务的复杂性和特殊性的增加,端到端方法引起了更多的关注[95]。端到端方法直接从输入到输出构建模型,根据训练任务数据的反馈迭代增强模型,形成全闭环计算的程序[96]。
3.3.2 因果推理(Causal Inference)
目前的机器学习在很大程度上依赖于关联模型,导致人工智能的可解释性差。机器很难区分数据中真实或虚假的因果关联。解决这个问题的关键是使用因果推理而不是关联推理,这样机器就可以使用适当的因果结构来为推理世界建模。Pearl使用三个层次结构来对因果推理进行分类[97]。第一层是关联,涉及数据化的统计关联。第二层是干预,这涉及到什么是可见的,以及额外的干预或行动会产生什么。第三层是反事实,这是对过去事件的反思和追溯。它回答了这样一个问题:“如果我们在过去采取了不同的行动,会有什么不同”?反事实层是最强大的层次。如果一个模型可以回答反事实的问题,它也可以回答关于干预和观察的问题。
Hume提供了一个字面的阐述,最初建议使用反事实框架来讨论因果关系[98]。Lewis根据Hume的研究,将可能世界的语义与反事实相结合,对反事实框架进行了符号化的表达,以描述因果关系[99]。Verma等人从实际数据中学习,预测反事实的结果[100]。Besserve等人提出了一个非统计学框架。他们通过反事实推理揭示了网络的模块化结构,该结构由纠结的内部变量组成[101]。Kaushik等人为文件的反事实操作设计了一个人在环形系统。他们建议利用循环中的反馈来消除误导性的关联[102]。
潜在结果框架(potential outcomes framework)是因果推断中最重要的理论模型之一。该模型由哈佛大学著名统计学家Rubin提出[103],也被称为Rubin因果模型。潜在结果模型的核心是比较有无干预对同一主体的影响。一个目标的结果出现与否,主要取决于分配机制。我们只能看到一个结果,并不意味着另一个结果不存在。因此,描述有关潜在结果的事件更为合理。除了潜在结果模型外,结构性因果模型(structural causal model)是因果推理中使用最广泛的模型之一。结构性因果模型(structural causal model)可以描述多个变量的因果关系。Pearl开发了一种基于外部干预的因果关系的正式表达方法,创造了一种从数据中探索因果关系和数据生成机制的方法[97]。Causal Network通过收集因果术语来确定因果关系,从大型文本语料库中挖掘出因果模式[104]。数据驱动的方法,如概念网络,通过人工收集信息将因果事件编码为常识,从文本中推导出因果关系[105, 106]。因果推理(causal reasoning)和自然语言处理(natural language processing)可以结合起来,从大型文本语料中提取术语或短语之间的因果关系,捕捉和理解事件和行动之间的因果关系。Luo等人使用数据驱动的方法来解决短文之间常识性的因果推理问题。他们提出了一个框架,从一个广泛的网络语料库中自动收集因果关系,可以正确模拟项目之间的因果关系强度[104]。Dasgupta等人用无模型强化学习训练了一个递归网络(recursive network),以克服因果关系问题[107]。因果表征学习的最新进展是在没有事先了解人工分区的情况下检索出真实世界的模型[108]。
3.3.3 知识推理
知识推理(Knowledge reasoning)一直是认知智能的一个重要组成部分。传统的推理包括演绎(deductive)推理和归纳(inductive)推理,它来自于经典的数学理论。演绎式推理从一般的前提开始,并引出具体的陈述或个别的结论[109]。归纳推理则是从个体到一般。它从具体的例子中得出一般性的原则和规则[110]。

知识推理使用图数据模型或拓扑结构来整合数据,建立知识库,如图9所示。它存储了具有自由形式的语义实体(对象、事件、情况或抽象概念)和它们的关系描述。该研究包含七个方面:知识获取(knowledge acquisition)、表示(representation)、存储(storage)、建模(modeling)、整合(integration)、理解(understanding)和管理(management)。
作为一种有效的知识表达方式,知识图谱(knowledge graph)通过丰富的语义关系将实体连接起来,并构建一个系统的、半结构化的知识库。知识图谱已被广泛用于垂直应用领域,如医疗、电子商务、金融、公共安全、交通和智能问答。典型的知识图谱包括YAGO [111], DBpedia [112], Freebase [113], Wikidata [114]等。这些知识图谱从许多数据资源中提取、组织和管理知识,然后以三元组的形式存储和表示知识。它们有助于理解搜索的语义并提供准确的搜索答案。
基于知识图谱的知识推理主要集中在关系上,即根据图谱中现有的事实或关系推断出未知的事实或关系,或者根据已有的知识和经验识别和纠正现有实体、关系和图谱结构中的错误。它包括基于规则、分布式表示、图和神经网络的推理。
基于逻辑规则的推理主要使用一阶谓词逻辑、描述逻辑和概率逻辑来推导新的实体关系。典型的方法包括ProPPR[115]、Tensor-Log[116]、SRL[117]等。
以路径排名算法(path ranking algorithm)[118]为代表的基于图结构(Graph-structure-based)的推理,将知识图的半结构化拓扑特征与统计标准相结合。这种方法考虑了实体之间的路径关系,在算法中引入了统计规则,并产生了强大的推理效果。
基于神经网络的推理使用深度学习模型来推断知识。神经张量网络(Neural tensor network, NTN)[119]构建了实体的词向量平均表示。R-CCN[120]通过卷积网络捕捉相邻实体的信息。IRN使用RNN作为控制单元来模拟多步骤推理的过程,并引入了注意力机制(attention mechanism)。Deep-Path[121]最初在知识推理模型中引入了强化学习框架。
基于分布式表征学习(distributed representation learning)的推理,通过表征模型学习知识图中的事实图元,获得知识图的低维向量表征。然后,推理预测被转换为基于表示模型的简单向量操作。其核心是将知识图谱映射到连续矢量空间,并通过计算每个元素的分布式表示法进行隐性推断。大多数表征学习方法,包括TransE[122]和RESCAL[123],基于不同的空间假设建立各种学习模型,并使用单步关系,或单一的三元组,作为其输入和学习目标。
3.4 自主智能(Autonomous Intelligence)
有两个关键因素推动机器从被动输出到主动创造:一个强概括的模型(strongly generalized model)和与外部环境的持续互动。自主智能(autonomous intelligence)的发展路径从学习单一任务开始,到通过从一个例子中得出推论来学习,逐渐达到通过与环境动态互动的主动学习,最后结束于自我进化的高级智能目标。本小节着重于发展技术领域,如迁移学习(transfer learning)、元学习(meta-learning)和自主学习(autonomous learning),以研究产生自主智能的可行路径。
3.4.1 迁移学习(Transfer Learning)
迁移学习(transfer learning)的基本思想是利用已解决的问题的策略来解决新的问题,即把已有的经验转移到过去。目前,作为机器学习的一个分支,大多数神经网络方法都是用来训练模型的。训练后的模型参数通常作为一组初始值,以减少模型训练的复杂性。转移学习主要是通过优化单一的整体任务作为转移源来训练样本空间中的基础模型。适当的模型被直接转移到目标领域,然后使用少量的标记样本对目标模型进行微调(fine-tuned)。迁移学习的初衷是为了节省人工标注的时间,使模型能够从现有的标注数据(源域数据(source domain data))转移到未标注的数据(目标域数据(target domain data))。它可以最大限度地利用获得的数据,减少机器学习的样本量要求。
在迁移学习中,数据被分为源数据(source data)和目标数据(target data)。源数据指的是与未解决的任务没有直接关系的其他数据,通常有大量的数据集。目标数据是与任务直接相关的,数量较少。迁移学习的目的是通过一些额外的数据或现有的模型建立从源域到目标域的映射关系。它将一般的知识应用于新的任务,以充分利用源数据来帮助模型在目标数据上的改进。转移学习也可以与其他模型相结合,如联合学习和强化学习[124, 125]。
根据学习风格,转移学习可以分为四类。基于实例(Instance-based)的迁移学习从源域选择实例来帮助训练目标域[126]。对实例分配不同的权重。实例越相似,权重越高。具有较高权重的实例具有较高的优先权。基于特征(Feature-based)的迁移学习将目标域和源域映射到同一空间,使两个域的分布之间的距离最小化[127]。对称空间方法将源域和目标域的特征空间转化为一个共同的子空间。非对称空间方法直接将源域特征空间转换为目标域特征空间(或者相反),以实现两个域的对齐。这种方法可以解决源域和目标域之间数据分布不一致的问题,彻底解决数据缺失的问题。基于模型的迁移学习重用在源域上训练的模型,并通过微调(fine-tuning)或固定特征提取器调整模型参数[128]。基于关系(Relationship-based)的迁移学习探索相似场景的关系,并利用源域和目标域之间关系中隐含的相关性[129]。
3.4.2 元学习(Meta-learning)
元学习的目的是帮助机器学习学习[130, 131],使机器能够快速学习真实环境中各种复杂的新任务。传统的机器学习方法是提前手动调整参数,直接在特定的任务下训练深度模型。而元学习将使机器学习所有需要人类提前设置和定义的参数变量,包括如何预处理数据、选择网络结构、设置超参数、定义损失函数等[132]。从学习历史中获得的经验给了机器元知识。因此,它可以快速处理只有少数数据样本的新任务。元学习主要应用于少次学习、零次学习、无监督学习以及其他可用数据很少的领域。元学习的提出是为了解决传统神经网络模型在少数样本情况下泛化性能不足和对新任务适应性差的问题。元学习的理念通过降低各种类似任务的模型设计成本,使机器学习过程更加自主。
由于元学习的目标是通过训练数据中的元知识快速获得学习新任务的能力,元学习将整个任务集视为训练实例。元学习在训练和验证数据集上获得具有强大泛化能力的初始网络参数。它在测试数据上进行一些梯度下降操作来学习新的任务。然后,它测试学习后模型的效果。元学习通过初步训练获得一个良好的模型初始值,然后在初始值的基础上用少量的训练数据更新特定任务的权重,以达到良好效果。元学习也可以看作是找到了一组高灵敏度(high-sensitivity)的参数。基于这些参数,只需要几次迭代就能在一个新任务上取得理想的结果。
迄今为止,最有影响力的元学习模型是模型无知元学习(MAML)[133]。MAML不是一个深度学习模型,而更像是一种训练技术。它的目标是为一组任务训练一组微调的参数,而不是为一个特定的任务训练一个模型。因此,MAML的输入是任务,而不是数据。MAML使用一组自适应权重,在经过几次梯度下降后可以很好地适应新任务。然后,找到这个权重就是训练目标。MAML迭代地训练一批任务。在每次迭代中,它首先训练该批任务中的每个任务,然后返回到原始状态,对这些任务的损失进行综合判断,然后选择一个适合该批任务的方向。
3.4.3 自主学习(Autonomous Learning)
元学习(Meta-learning)可以通过对类似任务集的学习来处理特定类型的任务的一般解决模型,并可以在任务之间转移学习。然而,这种学习能力只能在同质化的任务之间转移,甚至任务的支持和查询集大小都是严格一致的。自主学习(Autonomous learning)旨在从被动接受数据和训练转变为主动学习,提高学习效率,这也是图灵奖得主Yann LeCun[134]考虑的方向。除了更高层次的转移学习能力外,外部开放世界的模型也被纳入到自主智能架构的设计中。
人类和其他动物总是能够通过观察和少量的互动,以无监督的方式学习大量关于一切如何运作的背景知识。这些知识就是我们所说的常识,它是世界模型的基础。LeCun设计了一个学习框架,允许机器以自我监督的方式(即没有标记的数据)学习一个 “世界模型”。他用这个模型来进行预测、推理和行动。在这个模型中,他从各个学科中提取有价值的想法,并将这些想法结合起来,提出了一个由六个模块组成的自主智能框架(聚集模块(conguration module)、感知模块(perception module)、世界模型模块(world model module)、成本模块(cost module)、行动模块(action module)和短期记忆模块(short-term memory module))。每个模块都可以很容易地计算出目标函数,估计出相应的梯度,并将梯度信息传播给上游的模块。
这个自主智能的认知框架中的大多数模块都与动物的大脑有相似之处。感知模块对应的是处理视觉、听觉和其他感觉途径的皮层。世界模型对应于前额叶皮层的一些部分高级处理单元。本质成本模块与杏仁核相对应。而可训练的批评者成本模块则对应于前额叶皮层中负责奖励预测的部分。短期记忆模块可以对应于海马体。同时,congurator对应于前额叶皮层的中央控制和注意力调节机制。行为者模块对应于运动前皮层。通过这种高度类似于大脑的设计,不仅跨任务的学习能力转移看起来很有希望,而且它还以模块化的方式将常识和情感引入框架,使机器朝着 "有意识 "的推理和计划迈出了一大步。
3.5 人机一体化智能(Man-machine Integrated Intelligence)
尽管在四个层次的智能方面取得了显著的进展,但要想从极其复杂的场景中仅通过计算/统计模型获得关键的见解,还需要更多的努力。在这些场景中,人类应继续在解决问题和决策中发挥不可或缺的作用,探索人类认知处理中涉及的要素,并将其与机器智能相结合。下面将重点讨论人机交互(human-computer interaction)、人机融合(human-machine integration)和脑机接口(braincomputer interface)。
3.5.1 人机交互(Human-Computer Interaction)
计算机已经以各种形式出现在日常生活和工业操作中。为了提高计算机的可用性,人们设计了各种方法和产品。人机交互技术的发展进一步释放了计算机的潜力,提高了用户的工作效率。人机交互经历了人类通过手工作业、命令语言、图形用户界面(GUI)、网络用户界面等适应计算机的早期阶段。GUI通过减少打字操作,简单易学。需要帮助理解计算机的普通用户也可以熟练地使用它。它实现了实际的标准化,由于用户人群的扩大,给信息产业带来了前所未有的发展。
随着网络的普遍发展和无线通信技术的发展,人机交互领域正面临着巨大的挑战和机遇。用户要求在多媒体终端上有更方便的交互模式。同时,操作界面在美学和形式上也有创新。它已经达到了多模式、不精确的交互阶段,并不断向以人为中心的自然交互方向发展。在这个阶段,人机交互使用多种交流渠道。模态涵盖了用户表达意图、执行动作或感知反馈信息的各种交流方式。采取这种方式的计算机用户界面被称为多模式用户界面(MMI)。MMI使用各种人类感觉渠道和行动渠道(如语言、手写、姿势、视觉、表情、触觉、嗅觉、味觉和其他输入),以平行和不精确的方式与计算机环境互动。它将人们从传统交互方式的桎梏中解放出来,使人们进入一个自然和谐的人机交互时期[135, 136]。
3.5.2 人机融合(Human-Machine Integration)
人机融合智能理论关注的是通过人类、机器和环境之间的互动产生的一种新的智能形式。它是一种结合了物理和生物特征的全新一代智能科学系统。人机融合智能,有效地混合了硬件传感器收集的客观数据和人类感官感知的主观信息,整合了人的深刻认知方式和计算机的卓越计算能力[137, 138]。它利用人类先前的领域知识作为重要的学习线索来构建新的理解方法,并增强了基于计算机的决策。有了新的方法,计算机可以管理专业领域中人类和机器都无法单独处理的复杂问题。
人机结合,由人和机器指导综合学习过程,直到达成共识,以互动和协作的方式进行,而不是静态的。它要求两个组成部分之间通过互动平台进行直观的交流。机器智能可以被解释并直接发送给人类。专家可以很容易地以自然的形式提交反馈。此外,融合应该自动适应动态环境,以便综合智能能够随着人类知识的更新而不断发展。因此,自我进化的集成智能对于处理动态场景至关重要,以便任务和数据可以快速变化[139]。
为了有效地将计算机带入实时思考过程,人类和机器必须更紧密地结合起来。传统上,要在集成计算机中实现高实时性能并不容易。一种结合人和机器能力的先进模式是人机共生。人机共生系统应该在更好的互动和合作方面更好地理解人类的意图[140]。硬件,如传感器、手镯、可穿戴设备和其他计算机,像空气一样在隐形状态下被正式化。例如,可穿戴设备可以附着在衣服和鞋子上,实现人机共生[140]。在软件方面,元宇宙技术的发展将为人们提供一个完全沉浸式的人机共生体验[141, 142]。计算机技术在未来将继续为我们服务,交互界面和任务将变得更加自然和智能。云端的分布式交互和协作系统将建立在虚拟和现实的结合上。它将在信息感知、建模、模拟、推理、预测、决策、展示、互动和控制的循环中获得人类的功能。它将提供人机协作的持续学习能力。它将为重要的应用提供平台支持能力,如在未知环境中的远程探索和操作,复杂系统的协同指挥和操作,人机共驾环境,以及整合虚拟和现实的社会问题研究和治理。
3.5.3 脑-机接口(Brain-Computer Interface)
脑机接口(BCI)是通过分析人类(或动物)的脑电图(EEG)信号而建立的一种交互系统。它突破了传统神经反射弧结构的限制,使脑神经信号可以通过有线或无线方式直接与计算机通信,从而直接控制和沟通外部电子应用设备。根据信号获取方法,BCI分为三类:非侵入性、半侵入性和侵入性。非侵入性BCI利用信号源,包括表面EEG、脑磁图(MEG)、功能磁共振成像(fMRI)、功能近红外光谱(fNIRS)等。半侵入性BCI使用皮质电图(ECoG)。侵入性BCI利用皮层内EEG。由于设备购置简单、操作方便、安全、易于临床使用,EEG技术受到极大重视。EEG信号的明显优势是其可达到毫秒级的高时间分辨率,适合实时监测和在线传输[143]。
单模态脑机接口面临一些挑战,包括长期运行的鲁棒性差、受指令数量影响的分类准确性、人机适应性和系统稳定性有待提高。例如,单模BCI系统可实现的任务数量有限,这限制了外部输出设备完成复杂任务。随着功能指令数量的增加,分类精度下降,系统稳定性受到限制,在实际应用中很难获得良好的效果。鉴于单一模式的脑机接口存在上述问题,近年来有人提出了混合脑机接口(HBCI)的概念。HBCI也被称为多模态脑机接口(MBCI)。它指的是将单模态脑机接口与另一系统(BCI系统或非BCI系统)相结合的系统[144, 145]。HBCI可满足多自由度控制系统对多指令和实时性的需求,以突破单模BCI中指令有限、多分类和识别精度低的问题。它扩展了运动指令量,提高了人机交互的适用性和输出特性,完善了人机交互系统功能。它在航空远程操作和设备控制方面具有广阔的应用前景[146, 147]。
HBCI系统有两个基本特征:信息融合(information fusion)和控制策略(control strategy)。信息融合包括数据级融合、特征级融合和根据信息表示水平的决策级融合。数据级融合直接融合由不同传感器获得的信号数据。特征级融合结合了从每个传感器获得的数据中提取的特征向量。决策级融合根据投票或分类决策的权重计算输出整个系统的决策结果,这些决策是由每个传感器单独处理的。根据控制策略,HBCI系统通过采用同步模式[148, 149]或顺序模式[150, 151]。
有人提出了一种协作式BCI(CBCI),它可应用于团体协作,通过增加用户维度来提高系统性能[152]。CBCI的优势不仅在于有效地整合群体EEG特征,提高解码的准确性和稳健性。它还可以提高人机混合智能在前沿任务中的决策信心。CBCI通常有精确的应用场景。通过设计高效的群脑信息融合算法,它可以实现比单脑信息更准确、更快速的目标控制[153]。CBCI的应用价值在于提高多用户脑机协作系统对特定任务的信息处理能力。它包括加强系统基于人类视觉信息的决策能力和基于人类运动感觉信息的控制能力[154, 155]。
CBCI的结构分为两种类型:集中式和分布式。集中式CBCI结构是针对一个或多个特征进行多人EEG联合特征提取[156]。分布式CBCI结构的设计思想是小组决策。该小组在同一时间执行相同的任务。根据每个用户的任务表现为其分配不同的决策权重,以避免个人EEG差异。权重的设置是决策融合的关键问题[157]。通过联合任务的设计、大脑激活特征的探索和多人合作的因果关系分析,传统的单人与环境/任务之间的互动研究逐渐转变为多人与环境/任务之间的群体互动研究。这标志着BCI技术突破了工程应用的限制。CBCI中的群脑协作联合操作更符合未来人机交互的社会化,将得到空前的发展和广泛的应用。
4. 计算促进智能(Computing for Intelligence)
人工智能的发现正在定期涌现,这主要是由于不断提高的计算能力[158]。与最初普及深度学习的2012年的突破性模型相比,2020年揭示的最大模型需要600万倍的计算能力。在强调这一趋势并试图量化其在2018年的上升速度后,OpenAI的研究人员得出结论,这种快速的上升不可能永远保持下去。事实上,迫在眉睫的减速可能已经开始了。
从历史上看,人工智能的快速变化步伐是由新的想法或革命性的理论推动的。通常情况下,最新的最先进的(state-of-the-art)模型只依靠比以前用于努力实现相同目标的更大的神经网络和更强大的处理系统。2018年,OpenAI的研究人员做了一项研究,跟踪基于计算能力的最大模型的增长[159]。利用在人工智能研究历史上训练一些最突出的人工智能模型所需的计算量,他们发现了计算资源快速增长的两个趋势。
他们的研究表明,开发一个突破性模型所需的计算能力的增长速度与摩尔定律大致相同,摩尔定律是一个长期的观察,即在 2012 年之前,单个微芯片的计算能力往往每两年翻一番。尽管深度学习技术一直是过去十年中大多数人工智能发展的驱动力,但 AlexNet,一个图像识别系统,在2012年发布时吸引了人们对它的新兴趣。如图10所示,AlexNet的推出刺激了顶级模型的计算需求急剧增加,在2012年和2018年之间,每 3.4 个月翻一番。
对图片分类的研究提供了第一个证据,表明在深度学习的最初几年,不断增长的计算能力持续改善了性能。然而,当图像识别算法开始通过增加计算资源在某些任务上超过人类时[160],人们的注意力转向了其他领域。2010年代中期,强化学习技术被用于巨大的人工智能模型,以玩像Atari或Go这样的游戏[161]。后来,出现了一种叫 transformer 的新架构,重新把重点放在语言任务上[55]。OpenAI的GPT-3[162],一个文本生成器,已经成为近年来最受欢迎的人工智能模型之一。
尽管算法和架构的进步使得更多的学习可以通过更少的计算来完成,但即使在这些进步之后,处理需求仍然很高。AlexNet到GPT-3需要同样的3.4个月的计算需求翻倍期。因此,计算能力正在成为智能计算的一个瓶颈。同时,AI/ML平台的能源效率将变得越来越重要,以降低计算成本[164]。
分布式机器学习(DML)方法正在被开发出来,以通过减少单个服务器上的计算负荷使计算具有可扩展性[165]。有一类DML,被称为联邦学习(FL),对分布式学习特别有希望,同时在服务器上保留了数据隐私[166]。它还避免了将大量的数据从分布式地点传输到中央服务器的开销。毕竟,在未来的智能计算系统中,不同的DML范式将是至关重要的。
4.1 大型计算系统(Large Computing Systems)
当摩尔定律失去效力时,超大型计算能力主要取决于平行堆积大量计算、内存和存储资源。例如,"高性能计算 "一词被用来描述将大量计算机快速联网成一个 "集群 "以进行密集计算的做法。由于云计算的出现,企业现在可以选择增加其高性能计算项目的容量。
4.1.1 高性能计算(High-Performance Computing)
当摩尔定律失去效力时,超大型计算能力主要取决于平行堆积大量计算、内存和存储资源。例如,"高性能计算 "一词被用来描述将大量计算机快速联网成一个 "集群 "以进行密集计算的做法。由于云计算的出现,企业现在可以选择增加其高性能计算项目的容量。
传统的HPC架构是为基于仿真的方法而开发的,如计算流体力学。相反,应用程序的开发是为了使用程序员可以使用的基础技术。现代HPC系统包括各种各样的硬件组件(例如,处理、内存、通信和存储)。这种异质性的一个衡量标准可以从与机器学习等技术集成的应用程序的不同特点中看出。HPC和人工智能的融合导致了对旧问题的新方法的开发和新应用的制定。
人工智能平台,通过人工智能提高科学发现的有效性,为开发和计算提供了一个集成的工作空间。由于人工智能平台的存在,研究人员可以避免繁琐的环境设置和计算机资源管理[169]。尽管研究人员希望将人工智能工作负载直接提交给HPC集群,但由于需要大量的管理和调度程序,这样做是不现实的。为了封装异构的基础设施并为研究人员创造一个一致的环境,基于HPC的人工智能平台正变得越来越流行。未来,研究人员将越来越多地使用跨学科的方法,利用各种资源(包括数据、HPC和物理世界)来解决各种问题[170-172]。
最近,越来越多的技术公司开始关注使用类似人工智能技术的平台。由于架构的发展和处理能力的不断扩大,已经为各种研究学科建立了众多的人工智能平台[173]。
-
腾讯公司的IDrug[174]提供了一个整合了最新算法、数据库以及硬件优势的药物开发平台。通过利用强大的计算资源(如NVIDIA GPU),计算机辅助药物搜索迭代(computer-aided drug search iteration)的操作时间明显减少。IDrug促进了新鲜数据的创建和汇总,同时整合了当前的几个数据库。IDrug提供与临床前药物开发有关的服务,包括蛋白质结构预测、可视化、合成路线和分子设计。
-
EasyDL[175]以百度大脑的无门槛深度学习平台为特色,利用英伟达Tesla系列的P4和P40 GPU来完成大部分的机器学习工作负载。对于基本任务,PaddlePaddle框架和AI workow引擎相结合[176]。通常情况下,接受过人工智能开发培训的商业研究人员应该使用EasyDL。
-
亚马逊人工智能[177](AWS)通过云计算利用了亚马逊网络服务。亚马逊人工智能的主要特点是灵活性、可拥护性和安装的简单性。AWS提供了全方位的资源,包括各种流行的Python工具和库,此外还有安全功能。
-
VenusAI[173]是一种基于超级计算机的方法,扩展了初级硬件的虚拟化和容器化。VenusAI提供了一个聚合和分配不同资源的技术机制。VenusAI在应用服务层也有一个统一的资源接口。
上述平台包括从商业云部署到需要与科学调查复杂整合的特定行业平台。这就需要建立一个具有强大处理能力的人工智能平台,用于科学研究。
4.1.2 边缘、雾和云计算(Edge, Fog, and Cloud Computing)
自2006年以来,云计算已经作为一种成熟的范式存在[178]。它通过抽象化底层计算、存储和网络基础设施来实现应用部署和可扩展性。在云计算数据中心中,许多同质的、高能力的计算机被一个高度可靠的、冗余的网络连接在一起[179]。
由于近年来处理器、存储器和通信技术的进步,计算能力的广泛增加塑造了物联网时代[180]。智能手表、智能城市电网和监测生理数据的智能建筑设备都是这一新兴领域的例子。鉴于移动计算的进步和对这些设备共同运作的广泛渴望,出现了一种情况,即许多不同类型的设备都参与提供相同的服务或程序(例如,健康监测应用程序)。这些新的计算需求是以本地计算范式的要求为特征的,由于云计算的上述特点,它不能充分满足这一要求[181]。
雾计算是一种分布式云计算,其中数据、计算、存储和应用等资源不是位于集中的数据中心,而是位于整个云及其基础数据源的其他节点。它是一种控制许多分散的网络的方法,其中一些网络可能是虚拟化的,所有这些网络在传感器和云存储设施之间提供数据处理和传输设施[182]。
边缘计算使远程设备能够在网络的 "边缘 "自行处理数据,或在附近服务器的帮助下处理数据。此外,只有最关键的数据才会被传送到中央数据中心进行处理,大大降低了延迟[183]。在边缘计算场景中,终端设备可以与附近的基站通信,以加载处理密集型工作。在完成一项工作后,边缘服务器会将结果发送给终端设备。虽然这种作业处理的最终结果与云计算的结果相当,但边缘服务器而不是集中的云服务器负责向终端设备提供所需服务。通过将分布式服务移到事件的物理位置附近,边缘计算可以潜在地大大减少终端用户设备的服务延迟。
图11说明了云、雾和边缘计算的表示方法。在某些情况下,"边缘 "和 "雾 "被当作同义词使用[184]。与流行的看法相反,雾计算并不仅仅依赖于边缘计算。相反,雾计算可能通过边缘计算来使用。此外,当云不在边缘时,它也包括在雾中。相应地,雾必须存在于边缘设备和云之间的某个中间位置。它作为网络和边缘设备之间的中介,支持本地计算进行分析。
在大多数情况下,在计算方面,边缘服务器无法与云服务器的功率和灵活性竞争。随着端点数量的不断增加,对边缘服务器的需求可能会变得无法处理。而且,由于边缘计算是一种分布式计算范式,边缘服务器只能利用其所在节点的本地信息,而不是整个数据集。根据这些结果,边缘计算不是全球决策的最佳选择。然而,由于云计算的集中性,它不仅有可能提供大量的计算能力,而且有可能为国际决策提供服务。基于这些结论,研究人员提出了边缘-云计算(edge-cloud computing)的概念,它汇集了边缘和云计算的优势[183]。但要注意的是,在边缘计算系统中,多个服务器可以相互安全合作(例如,利用区块链平台),为终端设备服务,从而提高边缘服务器的利用率[186, 187]。然而,服务器之间的协调将涉及一些开销。
使用分层和协作的边缘-雾-云架构有几个优点,例如,能够在给定的限制范围内(如延迟和能源之间的权衡),传播智能和计算以找到最佳解决方案[188]。要实现边缘、雾和云计算的可持续整合,就必须克服设计、实施、部署和评估方面的若干问题,因为这种模式具有分层、跨层和分散的结构。
4.2 新兴的计算架构(Emerging Computing Architectures)
架构创新促进数字计算的目标包括更有效的能源管理,降低功耗,更便宜的总芯片成本,以及更快的错误检测和纠正。当涉及到某些无法在CPU上执行的人工智能操作时,人工智能加速器可能会大幅削减训练和执行时间。内存计算是一个极为有利的选择,因为它有利于内存单元进行原始的逻辑操作,因此它们可以在不需要与处理器互动的情况下进行计算,这是内存和处理器之间速度差距扩大的主要原因。
4.2.1 加速器(Accelerators)
在短期内,使用各种加速器的架构专业化将是保持计算能力增长的最佳方式。因为在实验室中建造的晶体管原型通常需要十年左右的时间才能被整合到一般的制造过程中。然而,到目前为止还没有展出可行的替代品。因此,找到一个实用的post-CMOS解决方案来解决这个问题的期限几乎已经过了十年。在没有可行的替代方案的情况下,架构专业化是未来十年硬件唯一可行的选择。在不断发展的通用计算环境中,硬件的专业化很难跟上。由于交货时间长,开发成本高,专业化不是一个合适的解决方案。虽然如Thompson和Spanuth[189]所论证的那样,摩尔定律的放缓使得架构专业化成为全面通用计算的实用且可承受的替代方案,但它将对算法设计和编程环境产生深远的影响[190]。
如图12所示。峰值功率(x轴)和每秒千兆运算的峰值(y轴)以对数尺度显示。请注意右边的标题,它解释了用于对计算精度、形式因素和推理/训练进行分类的众多特征。用来表示计算精度的几何图形可能有许多不同的形式,包括analog、int1、int32、fp16和fp64。当用不同的颜色来表示形式因素时,更容易看到计算元件中被塞进了多少计算能力。这项研究只包括具有单个主板和一个物理内存插槽的设置。最后,实心的几何图形代表了为训练和推理而建造的加速器的性能,而空心的几何物体代表了仅有推理功能的加速器的性能。
阿里巴巴和Groq等公司的一些最新和最新的芯片,以及英伟达和英特尔最近的产品,其峰值功耗远远超过100W,并且在开发时考虑到了推论。过去几年的趋势也随之改变。这两种加速器都是为无人驾驶汽车和数据中心设计的,表明这些技术的功率预算已经增加到100W以上。此前,其他数字精度是集成设备、自动驾驶汽车和数据中心的标准;然而,int8后来取代了它们。一些加速器不仅支持int8推理,还支持fp16 and/or bf16。最后,代表数据中心系统的椭圆显示了高端训练节点的竞争日益激烈。NVIDIA和Cerebras的节点是性能最好的,Graphcore和Groq也有明显的贡献。虽然谷歌TPU和SambaNova也是竞争对手,但他们只报告了多节点的基准测试结果,而不是其系统在单个节点上的峰值能力。
因此,加速器是确保所有科学计算用户预期的持续性能提升的最有效工具;然而,加速器应该由一个明确的使用案例来驱动。因此,各研究领域特别需要强调数据科学的某些特征,以达到分析和模拟的目的。IT领域的一些大人物一直在讨论下一代HPC系统如何变得更加多样化。由于这些硬件设计的长期改进,未来要保持HPC系统的生态性和性能提升并不容易。
4.2.2 内存计算(In-Memory Computing)
很明显,计算机的使用方式正在迅速发展。根据冯-诺依曼的计算模型,计算机从一个被称为存储器的中央存储库中检索它执行指令所需的数据和代码。尽管如此,尽管内存设备有所改进,但内存和处理器之间的性能差距正在扩大。像深度学习和物联网这样的突破,在这个问题上的情况尤为严重。由于处理如此大规模的数据集超过了冯-诺依曼架构的能力,此类应用提供了显著的困难。
当存储单元被赋予执行基本逻辑操作的能力时,内存中计算(computing-inmemory,CIM)就成为一种可行的选择,因为它可以独立于中央处理器单元进行计算[192-195]。已经提出了几种基于CIM的、打破冯-诺依曼范式的替代计算机架构。这类设计通常使用最先进的技术,并将久经考验的技术和新技术周到地结合起来,以提高计算性能。提高这类系统的性能需要相当大的综合能力,这给应用转化带来了巨大的障碍。同样关键的是验证这种CIM框架的问题。
针对未来计算需求的适当的CIM设计需要仔细平衡技术和架构选择。一种已经影响到计算机行业的现代技术就是记忆体(memristor)。科学家们正在研究记忆体的实现,原因很多,包括其低温制造技术、非易失性电阻开关以及与CMOS的兼容性。由于其作为一种相对较新的技术的地位,记忆体有一些限制,如设备性能的地理和时间变化以及缺乏可靠的模拟。
静态随机存取存储器(static random access memory,SRAM)[196, 197]或非易失性存储器(nonvolatile memory)[198, 199]都可以用来实现CIM,即SRAM-CIM或nvCIM[200]。静态随机存取存储器(SRAM)可用于构建CIM。SRAM-CIM或非易失性存储器(nvCIM)。nvCIM允许在系统不活动时也能存储权重数据,因此没有必要在开机时从处理器中调取数据。由于其耐用性低,写入能量高,nvCIM只能用于有足够内存的系统,以保留特定应用所需的所有数据。相比之下,SRAM-CIM很适合于低到中等容量的系统。由于其更快的写入速度、更便宜的写入能量和明显更好的(几乎是无限的)耐久性,它可以被安排与各种神经网络一起运作。最新的逻辑技术也可以与SRAM-CIM一起使用,以减少延迟并提高功率效率。
根据[200],在计算结构方面。在传统的冯-诺依曼设计中,内存宏(Memory macro)和数字处理元件(digital processing elements)被设置为两个不同的块[201-203]。另一方面,CIM宏(CIM macros)在整个单一内存窗口中同时进行信息交换和计算。如图13所示,CIM被分为近内存阵列计算(near-memory array computing,NMAC)和内存内阵列计算(in-memory array computing,IMAC)。
-
NMAC: 数据使用 NMAC 结构的存储单元进行存储,就像传统存储设备的存储单元一样[204-206]。存储器宏有一个单独的接口,用于连接模拟人或电子电路与存储单元。NMAC 电路被用来计算数字或模拟 MAC,使用输出权重和来自电路外部的输入。Digital MAC 程序将 NMAC 的输出存储在输出寄存器中。
-
IMAC: 各种输入技术被用来输入数据并使用存储单元阵列执行模拟计算[207-209]。在MAC计算过程中,每个SRAM单元对一个二进制权重和一个输入进行一次相乘。位线上的模拟计算结果随后被转换为数字输出。例如,考虑[208]中的二进制全连接网络-使用MAC计算方法。由于MAC运算,某一列的所有IMC数据被加在一起,得到可访问的位线的模拟电压。然后,一个ADC电路将该可访问位线的电压转化为数字输出。
4.3 新兴的计算模式(Emerging Computing Modes)
复杂性的存在经常被指责为传统计算机的失败。如果一台超级计算机陷入困境,很可能是因为向大型经典机器提出了一个特别困难的任务。此外,今天高度复杂的人工智能模型(如, DNNs)在边缘设备中的普遍使用仍然难以实现。其原因是,操作这些模型的高级GPU和加速器存在功率和带宽紧缺的缺陷,导致处理时间长,架构设计繁琐[210]。鉴于这些事实,研究人员被刺激去创造新的计算模式,如神经形态和光子计算(neuromorphic and photonic computing)、生物计算(biocomputing)和令人难以置信的颠覆性量子计算(quantum computing)。
进入大数据时代后,对数据处理速度的要求也越来越高。与此同时,经典计算机的计算能力也逐渐达到极限。而量子计算可以克服这一限制,因为它具有纠缠或其他非经典关联带来的量子优势,在许多复杂的计算问题上实现指数级的速度。量子计算的这一优势可以为在短时间内处理大量信息带来巨大的潜力,并成为下一代计算技术的一个有希望的候选者。
4.3.1 量子计算(Quantum Computing)
20世纪90年代初,Elizabeth Behrman 开始将量子物理学与人工智能相结合。大多数科学家认为这两个学科就像油和水一样,不可能结合。但现在,当化学家和生物学家开始学习量子力学时,计算机科学和量子力学的结合显得非常自然。此外,计算机的发展也受到了量子信息技术的极大影响。与计算机科学所考虑的经典比特0和1相比,量子物理学开始考虑这种经典比特是否可以被量子比特取代进行操作。由于其叠加状态,这种量子比特可以代表0或1,这取决于上下文。叠加存在于许多量子系统中,包括光子的两个正交偏振方向,电子在磁场中的自旋方向,以及核自旋的两个自旋方向,所有这些都在量子计算中得到应用。量子系统的叠加使量子计算具有并行计算的优势,使其速度得到明显的提高。与经典计算机相比,量子计算机的计算能力可以呈指数级提高[211, 212]。此外,如果我们从量子计算的角度研究人工智能,我们可能不需要一个非常先进的通用量子计算机。大多数时候,一个特殊功能的量子处理器可以满足人工智能的算法,并表现出量子的优势[213-218],这可以很快实现。
图14:显示复杂度等级之间的关系的图,以及识别和评估可能的量子优势的流程图[214]。 a)说明了增加更多的数据可能在几个方面增加复杂性。人们认为,量子计算可以巧妙地解决传统ML算法的数据不能解决的问题。因为能够从数据中学习的经典算法属于一个复杂性类别,可以处理超出经典计算的问题。 b) 流程图是开发的分析量子预测优势的可行性的方法。带有相关内核的量子和经典程序,以及使用编码和函数电路 U e n c U_{enc} Uenc 和 U Q N N U_{QNN} UQNN 的具有潜在无限深度的 Q N N QNN QNN 的 N N N 个数据样本,被作为输入提供。在考虑要学习的函数之前,可以评估一个称为 g C Q g_{CQ} gCQ 的几何量,以确定正量子或经典预测分离的可能性,从而强调数据对潜在预测优势的重要性。如果测试成功,我们将演示如何建立一个有效地达到这个极限的对抗性函数;否则,无论数据函数如何,传统技术都能保证提供相同的性能水平。在确定了模型复杂度 s C s_C sC 和 s Q s_Q sQ 之后,可以进行标签/函数特定的测试来评估实际提供的服务。红色虚线显示了量子核(QK)方法是否能确定一个简单的经典函数是否可以代表任何给定的数据编码。
近年来,人工智能和量子计算持续升温,逐渐成为两大研究热点。量子人工智能是结合这两大热点的跨学科前沿课题。目前,人们认为只要有一个数据或算法是量子的,就可以归纳为量子人工智能的范畴。在这个新兴的学科中存在两个重要的问题。一个是使用先进的经典机器学习算法来分析或优化量子系统,解决与量子力学有关的问题。另一个是建立基于量子硬件的量子学习算法,利用量子计算的并行性来提高机器学习算法的速度。最后,还有一种情况:算法是量子化的,数据也是量子化的,但在这个长进行没有实质性的进展。
量子人工智能具有广阔的应用前景[219]。例如,量子人工智能已经被应用于药物的合成[220]和各种化学反应的处理[221]。尽管量子人工智能发展迅速,但它仍处于初始阶段。许多应用仍然受限于量子比特的数量和由环境噪声引起的特异功能量子计算机的误码率。因此,现在我们从量子角度研究量子人工智能。我们都在考虑如何建立一个可扩展的系统,并确保量子比特在计算过程中收到最少的噪音。我们相信,经过几年甚至几十年的发展,量子人工智能将给世界带来第五次浪潮。
就目前而言,我们每天都必须处理大量的数据。这些数据之间存在着关联。图谱算法可以从这些数据之间的关系中获得许多有用的或隐藏的信息。图计算作为下一代人工智能的核心技术,已经被广泛应用于医疗、教育、军事、金融等众多领域。然而,当图的规模很大时,对计算资源的要求将大大增加。例如,发现最大的全连接子图的问题是一个 NP-hard 问题。现在,我们思考是否可以利用量子计算来提高图计算的速度。高斯玻色子采样已被多次证明具有量子优势,同时,我们发现图可以被编码成高斯玻色子采样机[222, 223]。也就是说,我们可以利用抽样结果快速发现完全连接的子图(cliques)的最大数量[220]。
4.3.2 神经形态计算(神经形态计算)
Carver Mead在20世纪80年代首次提出了神经形态这一术语[224, 225],当时它主要涉及模拟-数字混合形式的脑启发计算。然而,由于脑启发计算机系统的发展和重要资金的出现,现在有相当多的硬件被认为属于神经形态计算的范畴。
非冯-诺伊曼计算机(Non-von Neumann computers)是那些类似于神经元和突触的计算机。它们的构造和操作受到了大脑中神经元和突触的启发。或者说,神经形态计算机(neuromorphic computer)有控制处理和记忆的神经元和突触。与冯-诺依曼计算机相比,神经形态计算机(neuromorphic computer)利用参数和神经网络的拓扑结构而不是预先设定的指令来构建其程序。神经形态方法的一个子类依赖于生成和操纵模拟神经网络中的 “尖峰”。尖峰出现的频率、它们的大小和它们的形状可以被用来在神经形态计算机中存储数字数据,而冯-诺伊曼计算机则将信息编码为二进制值。将二进制值转换为尖峰,反之亦然,这仍然是神经形态计算的研究课题[226]。
图15:传统计算系统和脑启发式计算系统的结构[227]。该图说明,基于传统计算系统的三层结构(右),提出了一个由软件(在顶部)、编译器(在中间)和硬件(在底部)组成的脑启发计算系统(左)。应用程序和图灵完备的编程语言(如JAVA和Python)构成了传统计算机系统架构的软件层。中间的软件表示,如抽象语法树,在整个编译过程中被转化为硬件表示,如指令。指令由遵守冯-诺依曼架构的CPU或GPU在硬件层面上执行。ALU、CPU、ROM、RAM和I/O都是冯-诺伊曼架构的组成部分。图灵完备性保证了所有堆栈的完全平等。神经形态的应用及其开发框架构成了由人脑启发的计算机系统的软件层(如Nengo和PyTorch)。POG代表这个阶段的软件,而EPG代表这个阶段的硬件(CFG,控制-运算图)。在使用编译工具将其转换为EPG之前,POG已经呈现。为了抽象神经形态的硬件,提出了一个称为ANA的硬件层,它由调度单元(SU)、处理器单元(PU)、内存和一个互连网络(TrueNorth、SpiNNaker、Tianjic和Loihi)组成。另一方面,神经形态完备性不仅提供了精确的等价性,还提供了近似的等价性,以说明大脑启发式计算的近似特征。
这两种设计由于其不同的特征而以不同的方式运作[228]。
- 高度并行性(High parallelism): 由于所有的神经元和突触都有并发功能的能力,神经形态计算机就其本质而言是并行的。与冯-诺依曼系统相比,神经元和突触进行的是相对简单的计算。
- 共用处理和内存(Co-located processing and memory): 在神经形态硬件中,处理和记忆是不分开的。在许多情况下,突触和神经元进行处理和存储的价值,尽管神经元通常被视为处理单元,突触被视为内存单元。将处理器和存储单元结合起来可以缓解关于处理器或存储器划分的冯-诺依曼限制,从而使最大性能更慢。此外,co-location 可以减少从主存储器访问数据的时间,这种做法在传统计算中很常见,与计算相比,消耗了大量的能量。
- 本质上的可扩展性: 由于添加更多的神经形态芯片需要添加更多的神经元和突触,神经形态计算机自然是可扩展的。人们可以把许多物理神经形态芯片的组合看作是一个巨大的神经形态系统,以操作越来越大的网络。许多大规模的神经形态硬件系统已经被有效地投入使用,如SpiNNaker[229, 230]和Loihi[231]。
- 事件驱动的计算(Event-driven computation)。由于事件驱动的计算,神经形态计算机能够进行极其有效的计算[232, 233]。在网络的执行过程中,神经元和突触只在尖峰出现时进行计算,而尖峰是相对稀疏的。
- 随机性(Stochasticity): 神经形态的计算机可以纳入随机性。
神经形态计算机在出版物中被广泛描述和引用,作为采用的动机[234, 235]。神经形态计算机非常适合于计算,因为其能源效率高:它们通常以传统计算机的一小部分功率运行。它们消耗的能量非常少,因为它们是事件驱动和高度并行化的,这意味着只有系统的一部分同时工作。鉴于计算的能源消耗不断增加和能源受限程序的出现(即边缘计算),能源效率是探索神经形态计算机实施的充分动力。此外,神经形态计算机非常适合现代人工智能和ML应用,因为它们本身就可以进行类似神经网络的操作。此外,神经形态计算机具有处理多种计算的潜力[236]。
4.3.3 光子计算(Photonic Computing)
架构的专业化带来了更多的数据中心需求,如机器学习工作负载的加速器技术,机架分解方法也给当前的互连技术带来了压力。即使最新的高吞吐量处理器芯片具有多个CPU/GPU内核,可以进行极其困难的计算,但它们缺乏充分利用其资源所需的片外带宽。应对这一挑战需要克服封装限制,这与当前电气封装的有限带宽密度直接相关[190]。
a) 深度神经网络的典型块状结构包括一个输入层、多个隐藏层以及一个输出层,该层产生用于分类或回归的输出。 b) 在这个网络设计中,采用了一个传统的N输入神经元。它的输出是通过非线性激活函数处理其输入的线性加权和而形成的。 c) 按照PDN芯片的结构,通过重叠而彼此分开,输入图片在一个ve上被6个像素阵列分割成四个小的图像。构成图像的一部分的像素被送到初级层的神经元中。第二层和第三层与下面各层之间的联系是显而易见的。该网络有两种结果是可以想象的。 d) 现实世界中N个输入的光子神经元的结构,其中光学PIN衰减器被用来改变N个光学输入信号的权重,然后平行PD的输出之和被用来进行光检测。一个TIA被用来放大和电压转换光电流 i s u m i_{sum} isum。调整供给光使得产生神经元的光输出成为可能。
光神经网络(ONNs)比电神经网络有很多优点,包括超高的带宽、快速的计算速度和高并行性,所有这些都是通过使用光子硬件加速来计算复杂的矩阵-向量乘法实现的[210, 238, 239]。为了跟上不断增加的数据处理技术的复杂性和数据集的数量,我们需要深度集成和可扩展的ONN系统,其尺寸紧凑,能耗降低。光的叠加和相干特性允许ONN神经元在不同的背景下通过干涉[240]或diraction[241]自然耦合,而广泛的非线性光学效应[242]可用于物理地实现神经元的激活功能。由于这些工具,其他类型的神经网络拓扑结构,如全连接[240, 241, 243]、卷积[244-246]和递归[247, 248],现在可以用光学方法实现。利用当今最先进的光学技术,ONNs可以每秒进行十万亿次操作[244],这与电学对应物相当,其能耗可能与每次操作的光子相当,甚至低于光子[249],这比数字计算要低几个数量级[250]。硅光子集成电路(PIC)由于其体积小、集成密度高、功耗低,正在成为构建光智能计算机所需的大规模、紧凑型处理单元的一个有吸引力的选择[245, 251-253]。
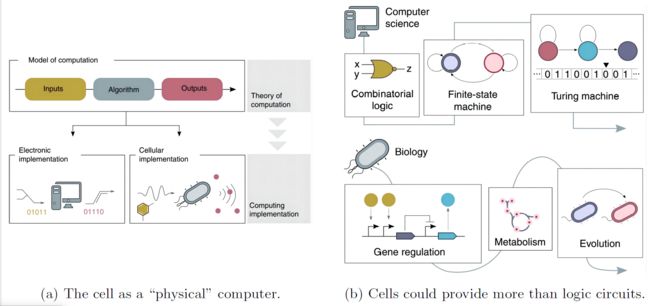
a)输入和输出以及算法对输入的处理在技术上是指计算模型。尽管同一理论计算模型有各种物理实现方式,但无论何种具体实现方式,计算的本质是一致的。电气数据也构成了电子实现的输入和输出。尽管如此,细胞也可以检测和传输广泛的物理、化学和生物数据流。数据可以用各种技术编码成输入。温度编码系统的例子。 b) 计算机科学中已经建立了比组合逻辑更复杂的计算模型。图灵机和氮态机就是这方面的例子。这些模型优于组合逻辑,因为它们能够以更广泛的方式将更广泛的输入处理成更广泛的输出。生命系统的细胞可以处理信息,因为各种计算机制已经在整个时间段内进化。一个简单的模型作为在细胞中创建组合逻辑电路的基础,代表了分子生物学的基本原则。然而,该模型没有考虑到像新陈代谢这样的基本生物系统或像进化这样的过程,而这些可能为开发更复杂的、尚不为人知的模型铺平道路。
与电学对应物相当,其能耗可能与每次操作的一个光子相当,甚至低于一个光子[249],这比数字计算低几个数量级[250]。硅光子集成电路(PIC)由于其体积小、集成密度高、功耗低,正在成为构建光智能计算机所需的大规模、紧凑型处理单元的一个有吸引力的选择[245, 251-253]。
4.3.4 生物计算(Biocomputing)
生物计算(Biological computing)是利用生物系统固有的信息处理机制开发的一种新的计算模式。简而言之,它是用来用生物方法解决计算问题的。生物计算主要集中在设备和系统方面。设备,又称分子设备,是在分子水平上进行信息检测、处理、传输和存储的基本单位;系统是指完全不同于传统计算架构的新计算系统的设计。一般来说,该系统是一个分布式系统。
生物学计算机(Biological computers)主要包括蛋白质计算机、RNA计算机和DNA计算机。蛋白质计算机以蛋白质的运动规律作为计算机运行的基本原型。雪城大学的研究人员用蛋白质作为计算机的核心器件,用激光来读取信息。其存储容量比电子计算机大300倍,开启了蛋白质计算机的时代。RNA和DNA计算机以核酸分子之间的特异性杂交为基本模式。由于RNA在区分分子结构和实验操作方面不如DNA,所以很少有人关注RNA计算机。DNA计算机以生物酶为基本材料,以生化反应为处理信息的过程,试图以人类处理信息的方式提高计算机处理信息的效率。阿德尔曼在1994年首次提出了DNA计算机。经过大量的研究和实践,尽管它仍处于起步阶段,但DNA所表现出的强大存储能力和并行性使DNA计算机具有巨大的潜力。
生物计算与传统计算相比具有独特的优势,可以概括为强大的并行和分布式计算能力以及低能耗。平行计算和分布式计算是传统计算机为解决大规模复杂计算问题而设计的模式。但生物计算自然具有并行和分布式计算无法比拟的优势。其次,生物计算中的生化连接过程需要分子能量,不需要额外的外部能量,整体能耗非常低。例如,1焦耳的能量可以完成1000多次的DNA计算,而传统的硅基计算机只能完成100多次的计算。这之间有一个数量级的差异。
在目前的技术能力范围内,生物计算不可避免地存在一些缺陷。受现有生物技术的限制,目前的生物计算机大多是纸上谈兵,没有合适的条件进行相关的实验验证,更谈不上建设。例如,在DNA计算机中,如何重复使用DNA或蛋白质,以满足计算过程中不断消耗DNA的要求;现有的DNA计算机都是专门针对某个特定的长项。在制作标准和通用的计算机部件方面也很复杂;DNA涉及生物隐私信息。保护公民的DNA信息不被犯罪分子侵犯和利用是一个重要的社会问题。
5 智能计算的应用(Applications of Intelligent Computing)
5.1 科学中的智能计算(Intelligent Computing for Science)
如果我们要跟上我们快速发展的环境中不断增加的问题,用同样的老方法发现创新的想法是不会停滞的。然而,由于目前正在进行的计算机革命的影响,科学发现的速度将得到前所未有的巨大推动。
5.1.1 计算材料科学(Computational Materials Science)
几十年来,计算材料(CM)已经成为研究材料特性和设计新材料的有力手段。然而,由于材料和材料行为的复杂性,包括缺乏许多原子、离子、原子和离子相互作用的力场和电位,分子动力学(MD)模拟中不同的热力学阶段,以及优化材料成分和工艺参数的巨大搜索空间,它们的应用面临许多挑战。人工智能与CM的整合被证明是对传统CM的革命,是一种新的研究范式[255]。智能CM是材料信息学的一个主要组成部分[256],并且正在变得越来越流行。在Web of Science上,相关出版物的数量已经达到5万篇。大约70%是在过去五年里发表的。
人工智能和CM的整合在多个长度和时间尺度以及多个物理场的耦合计算中表现出巨大的成功。最著名的电子和原子尺度计算方法是通过应用密度泛函理论(Density Functional Theory, DFT)进行第一原理计算。DFT计算的关键问题是,由于电子结构的薛定谔方程中存在多种粒子和非线性相互作用,对计算能力有巨大的要求。深度神经网络可能是加速电子薛定谔方程计算过程的一种有效方法[257, 258]。DFT中交换相关(XC)能量的近似限制了Kahn-Sham DFT计算的准确性。核脊回归和深度神经网络可以创建更准确的XC近似[259, 260]。基于ML的XC近似甚至可以应用于具有强关联性的系统。通过用经验势能代替耗时的电子结构计算,MD可以在不同的温度下模拟具有缺陷的更大系统。ML可以提供一种系统的方法,从第一原理的计算中推导出力场或势能。基于ML的力场被称为ML势。ML势由两部分组成: 数据和ML电位模型。在数据收集过程中,所研究系统的先验知识在设计候选结构时起着核心作用,这些结构应该用第一原理计算来计算。局部结构的描述符的设计是ML势模型的核心[261]。目前已经发表了几个有效的ML势软件包,包括Amp[262]、MLIP[263]、MLatom[264]和DeepMD[265]。Xu等人基于DeepMD[266]建立的模型,用分子动力学研究了锂硅合金。分析了各种晶体和非晶体Li-Si系统的结构和动态特征。他们的预测比相似精度的自发分子动力学模拟快20倍。这种方法也可以应用于液态水等绝缘材料。Grace等人引入了一个绝缘材料的模型,并将其应用于液态水[267]。它表明,可以计算出与经典的2纳秒轨迹在Xed温度下的拉曼光谱,并且低频拉曼光谱的分辨率得到了提高。Li等人在固态电解质Na3OBr上应用DeepMD[268]。得到了在固定温度下的Na+浸润系数,表明了温度对迁移屏障的影响。他们的工作也证明了DeepMD在研究固态电解质的传输特性方面的广阔前景。最近,He等人利用DeepMD研究了SrTiO3的结构相变[269]。通过使用DeepMD建立模型,研究了不同面内应变下的温度驱动的相变特征。
左边描述的是传统范式,中间用有机氧化还原电池来说明。右边是一个闭环系统的模型。逆向工程、智能软件、人工智能/机器学习、嵌入式系统和机器人技术都是闭环系统的必要组成部分。
相场模拟可以说明微观结构在连续热力学和动力学水平上随时间的演变。但它们需要巨大的计算能力。LSTM网络,作为一种著名的门控RNN算法,被成功地应用于训练一个模型,从很短的时间内的计算收集的数据中预测长时间的演变结果[271] 。在材料的有限元计算中,关键问题是为特定的材料在特定的服务环境中构建一个构成模型。许多ML模型能够从数据中构建一个构成模型,例如,高斯处理[272]、人工神经网络[273{278]和符号回归[279, 280]。
ML在计算材料中的另一个应用是训练ML代用模型,特别是一个简单的分析代用公式,用来替代原来的真实物理模型[281, 282]。从不同输入参数的物理模型的几次计算中收集数据,并应用于ML模型的训练。通常情况下,ML代用模型的评估速度远远快于原始物理模型,而两个模型的精度几乎相同。计算速度上的几级加速允许在设计和优化空间中进行全局搜索。可用于训练多模态代用模型的典型ML算法包括Kriging/高斯过程[283]、LSTM网络[271, 284]、物理信息神经网络[285]和CNN[286]。
对于没有可用的物理模型的情况,可以直接从实验数据中训练出一个代理模型,以替代尚不清楚的物理模型。这种情况在材料社会中是最常见的,该模型通常被称为材料微观结构-宏观性能关系。材料机器学习中的特征或描述符包括电子和原子参数、化学成分、微观结构参数、热力学和动力学参数、加工条件、服务环境条件、所有材料表征条件、光学和电子显微镜图像等。机器学习模型的输出可以是目标属性,也可以是势能表面[265]。根据所研究的问题,一些参数在一些问题中是特征,而在其他问题中成为响应。目标属性包括稳定性[287]、成型性、带隙[288]、居里温度、介电性能、外电[289]等。稳定性在预测新材料和形成能量方面起着势在必行的作用,这可以从第一原理计算中得到。Li等人[290]开发了一种转移学习方法来预测形成能。在筛选了21316个过氧化物后,他们发现了764个稳定的过氧化物,容忍系数小于4.8。其中98个已经被DFT计算证明是稳定的。最近,Park等人利用一系列机器学习模型研究了有机/无机混合化合物的稳定性,证明先进的电子结构理论和机器学习的结合促进了新材料的设计[291]。带隙是设计新型光伏设备的一个重要参数。太阳能电池需要一个符合可见光波长的带隙。2018年,Takahashi等人预测了过氧化物带隙,利用机器学习寻找太阳能电池的候选材料[287]。他们预测了9238种过氧化物材料具有所需的带隙,其中11种是未被发现的。
5.1.2 天文学的计算(Computing for Astronomy)
天文学作为最古老的观测科学之一,在历史上已经收集了大量的数据。由于产生数字输出的望远镜技术的突破,最近出现了巨大的数据爆炸。天文学和天体物理学的长处是有大量的数据和各种大口径的地基望远镜,例如,即将到来的大型同步测量望远镜和天基望远镜[292]。现在的数据收集更加有效,而且基本上是使用高分辨率的相机和相关工具自动进行。该系统每天将收集大约15TB的数据[293]。关于有效的决策,必须要有更有效的数据分析。因此,需要智能计算技术来解释和评估该数据集。
星系的形态学分类。经过多年的等待和期待,詹姆斯-韦伯太空望远镜拍摄的第一批图像终于在2022年7月12日发布。一个名为Morpheus的机器学习模型在像素层面上对天体来源进行形态学分类。Morpheus在加州大学圣克鲁斯分校的Lux超级计算机上进行训练,该计算机由28个GPU节点组成,每个节点有两个英伟达V100 Tensor Core GPU。机器学习模型迅速发展成为宇宙学和天体物理学中令人难以置信的有效工具。例如,CNN和生成对抗网络(generational adversarial networks, GANs)已被成功应用于促进基于恒星形成和形态特性的星系形态分类[294-297]。事实证明,这些ML算法可以达到90%以上的准确率,并且在时间预算少得多的情况下,表现同样出色,甚至优于传统方法。
无线电频率干扰检测。较新的研究表明,U-Net[298]及其变体为语义分割提供了强大的架构基础,这是基于深度学习的射频干扰(RFI)检测的一个重要组成部分。U-Net最初是为射电天文学中的RFI检测而实现的[299]。计算机生成的数据和Bleien天文台的信号天线捕获的观测数据的组合被用来训练和测试该网络[300]。在使用HERA天文台收集的合成和真实数据对U-Net的变体进行检测RFI的评估后[301],为了提高对其他表现形式的通用性,作者将规模和时间段分成模型中的独立元素。如[302, 303]所示,将错综复杂的能见度的比例和时间段的描述结合起来,只产生了微不足道的好处。迁移学习一直被认为在缺乏标记数据的情况下是有效的。例如,R-Net可以在模拟数据上进行训练,并采用一小部分专家标记的数据。它的领域可以从模拟数据调整为真实世界的数据[303]。GANs在[304]中已被证明对RFI检测有用。在[305]中提出了一种非常新颖的使用GANs的方法。作者提出了一种源分离策略,以区分天文信号和RFI,该策略基于使用两个独立的生成器。
5.1.3 药学研究的计算(Computing for Pharmaceutical Research)
人工智能对所有的药物设计阶段都有影响[306-308]。药物设计得益于人工智能,因为它可以帮助科学家建立蛋白质的三维结构,药物和蛋白质之间的化学关系,以及药物的有效性。在药理学方面,人工智能被用来创建靶向化合物和多靶点药物。人工智能还可以设计合成路线,预测反应产量,并了解化学合成背后的力学原理。人工智能使重新利用现有药物来治疗新的治疗目标变得更加简单。人工智能对于识别不良反应、生物活性和其他药物筛选结果至关重要。
因此,它们可以分为三类:a)基于配体的方法,b)基于结构的方法,以及c)基于关系的方法。
最近用于药物设计的人工智能工具和平台如下[310]。
- AlphaFold是一个开创性的计算模型,完全使用DeepMind和EMBL-EBI生成的蛋白质氨基酸序列来估计蛋白质的三维结构[311]。根据最新的CASP14分析,AlphaFold提供了最精确的三维蛋白质结构估计[311]。除了考虑与蛋白质结构相关的不同约束(进化、物理和几何),AlphaFold还实现了一个基于蛋白质数据库的神经网络架构。
- SwissDrugDesign[312]是瑞士生物信息学研究所的一个产品,是最广泛使用的药物设计人工智能平台之一。
- 默克公司的Synthia是Chematica的升级版,根据化合物信息建议潜在的合成路线。该人工智能应用可以通过调整搜索选项为目标分子提供多种合成路线。Chematica是由Klucznik等人开发的,用于生成八个常见化合物的合成程序,并随后对它们进行实验。与传统技术相比,每种化合物的生产率都有明显的提高,成本也有所降低[313]。
- Cyclica的Ligand Express确定了与某些大分子相关的潜在目标。与其筛选大量的大分子集合来定位与某些蛋白质结合的合适配体,一个建立在云端的先进平台对人类蛋白质组进行筛选,以发现最佳的匹配蛋白和蛋白质[314]。
- 阿斯利康的人工智能平台REINVENT被用来从头设计大分子。它可以产生符合用户输入的广泛偏好的大分子[315]。
网上有几个不同的人工智能平台和工具用于药物研究和发现,而且新的平台和工具在不断出现。目前的研究没有足够的空间来深入描述它们,但其他优秀的评价[306-308, 316-318]对它们进行了分析和比较。
通过庞大的化学文库检测活性化合物是药物开发过程中的初始阶段之一[319]。高通量筛选(HTS)现在是这个阶段的主宰[320]。通过 HTS 筛选大型化学库,使用与研究相关的检测方法。它不是在硅计算行为,而是提供了经验测试的好处。HTS还不是经常需要的。大型文库的实验筛选成本很高,因为它们只包含化学空间的一小部分。此外,并不是所有的检测都能在足够大的范围内进行;一般来说,必须在每个检测的实验数据的数量和质量之间进行协商,以获得尽可能好的结果。虚拟筛选(VS)是一种可用于补充或替代 HTS 的另一种方法[321, 322]。通过在 "硅 "(silico)中而不是在 "体 "中筛选化学品(vitro),"硅 "(silico)更容易负担,而且不受物理库的限制,VS旨在克服HTS的弊端。VS 通常会丰富活性物质,提高命中率,并降低后续测试的成本[323]。当有一个独特的设计假设,如验证过的目标,这一点尤其正确。然而,VS是不精确的,很容易产生不准确的预测,就像其他几种硅技术一样。一旦出现这种情况,不活跃的分子就可能被归类为假阳性,从而浪费了进一步研究的时间和重要资源。因此,提高VS的富集率仍然是必要的。
曼彻斯特大学的斯蒂芬-奥利弗和罗斯-金创造了两个机器人,即亚当和夏娃,它们是自动化和目前人工智能在药物创造中的应用的锦上添花[310]。亚当是为了做微生物实验,自行分析数据,提出假说,并创造实验来检验假说,直到建立一个正确的理论[324]。机器人Eve更加复杂;它每天实验筛选数百种化合物,确定某些命中率,构建特定的细胞系以测试命中率,然后修改命中率的结构以产生领先化合物[325]。
在制药业,使用先进的制造技术是一个普遍的趋势,特别强调像连续制造这样的互联和智能流程,适合个性化和按需制药的新技术(如3D打印),以及不断努力为管道中的问题化合物找到解决方案[326]。COVID疫情使我们重新评估了加快药物和疫苗研发过程的方法。数字化、困难的物质和快速的步伐给制药业带来了建模、预测方法和数字合作的趋势。诸如蛋白质的稳定和纯化等额外和独特的困难,是由管道中越来越多的生物大分子带来的。
5.1.4 计算机辅助育种(Computer-Aided Breeding)
粮食安全现在是一个世界性的问题,部分原因是人口快速膨胀,预计到2050年将达到90亿人[327]。组织培养诱变和转化等方法已被用于改善农作物。功能基因组学提高了我们对植物基因组的认识,并为修补基因组提供了新的机会。有希望的方法,如纳米技术、RNA干扰和下一代测序,已经被开发出来,以提高农业产量,应对未来的需求[328]。
作物育种近来在使用人工智能技术方面有所增长,这些技术支持服务的创建、模式的确定以及农业食品应用和供应链阶段的决策过程。人工智能在农业中的主要目标是准确预测结果,提高产量,同时尽量减少资源的使用[329]。因此,人工智能工具提供的算法可能会评估性能,预测不可预见的问题或发生,并发现趋势,如通过安装智能灌溉系统进行水消耗和灌溉过程管理,以处理农业问题[330]。
人工智能促进了整个农业价值链,从种植、收获到销售[331]。因此,人工智能的进步通过加强作物管理,帮助了农业企业的效率。天气预报、改进自动化设备以准确检测虫害或疾病,以及分析生病的作物以提高生产健康作物的能力,这些都是人工智能正在使用的常见领域。它为一些科技公司创造人工智能算法铺平了道路,帮助农业部门处理包括害虫和杂草侵扰以及全球变暖导致的产量下降等问题[332]。
为了最大限度地提高产量和抗灾能力,同时减少作物损失,农民应该采用技术来预测天气。人工智能赋予农民权力,通过分析他们收集的数据,获得更多的知识和理解,然后通过将帮助他们做出明智选择的过程落实到位来采取行动[334]。此外,利用农场的模式或用相机识别工具拍摄的照片,人工智能技术可以通过识别植物的病虫害以及营养物质的减少和潜在的土壤缺陷来监测土壤管理和健康[331]。通过降低农药的使用,人工智能技术在环境保护方面提供了巨大的功能优势。例如,农民可以使用人工智能方法,包括机器人技术、ML和计算机视觉,在有杂草的地方喷洒除草剂,更有效、更精确地控制杂草。这将减少覆盖整个田地所需的化学喷雾。
农业供应链的四个中心集群(产前、生产、加工和销售)与ML算法的关系越来越密切[335]。在生产前阶段,ML技术被用于预测土壤特征、作物产量和灌溉需求。在随后的阶段,ML可能被用来检测疾病和预测天气。为了实现高质量和安全的产品质量,在加工阶段的第三个集群中使用ML算法预测生产计划。最后,分销集群可能受益于ML算法,特别是在存储、客户分析和运输方面[331]。
5.2 智能计算促进经济和治理(Intelligent Computing for Economy and Governance)
智能计算加速了转型变化,导致了经济和社会秩序的转变。由于技术的进步,商品和劳动力的市场正在发生巨大的变化。人工智能的最新发展和相关的进步正在将数字革命的界限推向新的方向。
5.2.1 数字经济(Digital Economy)
人工智能系统的进步有几条潜在路线。一般来说,人工智能应该是数字经济中每个数据驱动战略的核心,包括工业4.0。例如,预测性维护可能会从人工智能中获益良多[336, 337]。预测性维护涉及一般机械或生产机械的维护,并通过使用来自生产或作业线的传感器数据来帮助降低运营成本或停机时间。
开发和应用基于人工智能的预测模型来改善维护计划是可能的。此外,物联网和CPS的应用应该受益于人工智能,因为这些技术是为了收集数据而不是分析。最后,人工智能可能有助于未来机器人和自动化的发展,用于工业、制造业和服务应用。对于这种独特的人工智能技术,深度强化学习现在正显示出有希望的结果[338, 339]。需要注意的一个更基本的事情是,一般的数据分析概念也必须为人工智能的使用而调整。跨行业的数据挖掘标准程序[340]是一个初级的标准,强调连续的分析过程之间的反馈。最近,这个标准被扩展到考虑行业特定的需求和领域特定的专业知识[341]。
关于人工智能在商业和经济中的应用,通常有三个主要问题被提出来。第一个问题是由于采用自动分析系统而导致的工作流失[342];第二个问题是难以理解通用的人工智能方法;第三个问题是富裕国家和发展中国家之间日益扩大的财富差距[343]。有趣的是,前两个论点与数字医学和卫生系统几乎相同。必须适当设计的人工智能治理,可以解决后一个问题。
5.2.2 城市治理
根据最近的研究,城市治理是为了开发新的战略和方法,使城市更加智能[344]。智能城市包括智能城市治理,其目的是利用最先进的信息技术来同步数据、程序、当局和物理结构,使当地人受益。[345]. Meijer和Bolvar[346]基于对文献的深入研究,建立了智能城市治理的四个示范性概念:智能决策、智能城市的治理、智能行政和智能城市合作。
另外,许多有希望的城市大脑研究的新途径已经被提出[347-349]。大数据已经使结合各种来源和不同观点的数据来提供城市居民的完整情况成为普遍做法。大城市的人口发展带来了管理更复杂的道路网络的额外挑战。正因为如此,痕迹管理也需要分析、预测和智能行动[350]。例如,城市一直在开发综合交通管理系统,以实时优化交通流量,如中国杭州的城市大脑。这些技术利用了由各种传感器捕获的大量城市监测数据。此外,模拟城市大脑系统的难度随着轨道交通网络的复杂性而增加。重要的考虑因素包括[351](1)通过并行异构计算加快巨大的同步异构网络众的计算速度;(2)直观地模拟城市环境,建立具有强大环境稳健性的可感知算法。在危机管理方面,未来的城市能够迅速进行搜索将是至关重要的。因此,通过对个体的特征和活动进行模拟分析,在监测数据中搜索和识别个体是至关重要的。城市规划和分析公共资源也是迷人的领域。城市大脑可以根据整个时间段的城市化规则积累事实。通过研究这些信息,可以优化公共设施的设计和政府资金的分配。

最近的研究呼吁更加重视 "智能治理 "的 "城市 "部分。城市问题,相关的专业知识被理解为通过与人的互动在社会上形成的,而不是过度重视技术上创造的中性信息[353]。例如,作为政府、商业部门和公民社会之间合作努力的产物,信息往往组织不力,或者最多只是半结构化的。当试图解决战略性和非常规性的问题时,就需要这种信息。在解决影响整个社区的问题时,我们必须获得促进对话、辩论和形成协议的技术工具[348]。民主体制、社会条件、种族和政治价值观以及物理世界都是可能促进或阻碍创造性和智能治理发展的背景因素的例子。它认为,在考虑现有 "智能 "政府的替代方案时,应考虑背景因素[346]。
6 观点(Perspectives)
前几节已经从理论和实验的角度回顾了智能计算的技术细节及其主要挑战。在本节中,将从新兴产业生态的角度阐述智能计算产业的主要挑战和未来发展。
6.1 机器智能的理论革命(Theoretical Revolution in Machine Intelligence)
与传统的计算理论相比,智能计算是对以语言和生物为动机的计算范式的应用和发展[354]。它意味着机器可以根据不同的场景来模仿人类思维的问题解决和决策能力。然而,硅基和碳基操作的基本逻辑存在根本差异,大脑智能的机制仍需进一步揭示。智能计算的下一步是通过在宏观层面上深入探索类人智能的基本要素及其交互机制[355],以及在微观层面上深入探索支撑不确定性产生的计算理论,来进行彻底的理论检修。
根据霍华德-加德纳(Howard Gardner)的多元智能理论,人类智能可以被区分为不同的智能模式[356]。根据不同机器智能的表现形式,它可以被分解成不同的基本能力组合。例如,逻辑-数学智能是学习能力、计算能力和记忆能力的组合。由于智能计算是指在机器中模拟和接近人类的智能,一个基本的范式,即对多元智能的定义和可否认和可计算属性进行标准化,有助于更好地实现类似人类的智能。有必要设计一个多元智能的公理系统,并证明它具有基本的数学属性,如可解性和完备性。对于多元计算智能,需要精确的分解和定量描述。此外,多变量智能的可计算性和可比较性也应该通过量化的数学表达和原子智能融合的测量标准来提供。科学家们可以通过不同理论之间的整合、碰撞和互动,开发出更好的类人机器智能[357-359]。
基于计算理论的图灵计算,是功能性的。建立在图灵计算基础上的经典计算产生确定性的结果。然而,智力的创造性是建立在不确定性之上的。接受相同的背景知识,不同的人对同一个问题会有不同的思考。即使面对同一个问题,同一个人在其他时间和环境下也会做出各种选择和判断。这种不确定性就是为什么人类智能可以不断产生新的数据、知识和工具。随机性和模糊性是主观和客观世界中不确定性的两种主要形式。目前,对机器智能的探索是建立在经典计算理论之上的,试图通过艺术化的预设符号系统和算法模型来抽象出自然世界,实现对随机性和模糊性的逼近。人脑的智能是从蛋白质、粒子通道、化学信号和电信号等化学现象的出现中生长出来的。为了研究从低级感知到高级逻辑推理的进化,有必要了解不确定的涌现是如何发生的,以及如何重现涌现的随机性和模糊性。神经形态网络模拟了大脑中神经元的结构和功能,但它不能模拟智能生成的过程。量子计算可能是最有希望的方向之一。量子力学揭示了构成世界的基本粒子的不确定性。这种不确定性可能会推动人类意识的出现和发展,也可以成为构建高级机器智能的理论基础。已有一些研究在经典计算机中模仿量子力学的概率行为[360]。为了进一步发展智能计算,我们首先需要构建一个能够支持不确定性的计算理论,以实现从理论计算空间到物理空间的完美映射。
6.2 知识驱动的计算(Knowledge-Driven Computation)
为了使计算机像人类一样学习,科学家们采取了两种方法: 由专家系统提出的符号人工智能(Symbolic AI),以及由深度神经网络指定的连接主义(Connectionism)[361, 362]。这两种方法在某种程度上可以很好地解决智能计算问题。问题的关键仍然需要事先的知识输入,如预先设定的物理符号系统、神经网络模型、行为规则等。数据驱动的智能在理论和方法论层面上主要依靠数学模型和大规模数据输入来计算结果。实质上,机器并不产生新的知识,它只是根据先前的知识进行一系列的数字计算,从而得出结果。换句话说,机器只是一个 “执行者”,而使知识的推导和计算成为可能的实际策略和逻辑仍然是由人类规定的。然而,在有大量数据的小任务中,数据化学习逐渐显示出局限性。由于泛化能力弱、解释能力差、知识表达困难、缺乏常识和灾难性遗忘等问题,这些模型离人类的理解还很远。在大多数情况下,人类更擅长从少数实践中总结,而不需要从大规模的训练数据中学习。根据他们的相关性[363],大脑可以将视觉转化为多种知识。然而,目前的深度学习框架只能在表面上模拟人类智能[364]。
将不同领域的知识与算法模型相结合,可以带来更好的问题解决,科学研究的第五范式的原型就是基于此[365]。因此,探索人类如何学习并将其应用于人工智能的研究非常重要。知识驱动的机器智能可以从人类活动中学习,模仿人类的决策能力,使机器能够像人类一样感知、识别、思考、学习和协作。探索多知识驱动的知识推理和持续学习的理论和关键技术,使智能系统具有类似人类的学习、感知、表述和决策能力,可以促进智能计算从数据驱动向知识驱动的发展[366]。将数据驱动的归纳抽象与知识驱动的演绎推理和物理定理的约束优化相结合,是提高机器智能的一个关键挑战。为了实现对抽象概念的总结和达到更高的智能水平,需要开发更多的可执行的系统架构来探索知识的创建、存储和检索方式。在理论层面上,知识数据模型需要改进,而模型对现实世界的描述能力也需要加强。引入类人思维模型,学习人类的环境感知、情感偏好、寻求优势和避免伤害的倾向,构建一个能够感知环境的自学系统的计算模型。
6.3 硬件和软件的架构创新(Architectural Innovation for Hardware and Software)
在硬件结构方面已经提出了各种创新。但是,硬件和软件之间的适应性面临着巨大的挑战,如精度损失、调用难度和协作不确定性。从理论上看,神经形态计算是一种有效的技术体系,在智能计算方面具有明显的优势[367, 368]。神经形态技术可以降低功耗,并将实时计算性能提高几个量级。此外,神经形态技术成本低,在许多应用中容易实现。然而,神经形态计算硬件(神经形态芯片、SNN、忆阻器等)的设计给构建算法和模型带来障碍。虽然传统的神经网络模型在建模领域问题上取得了准确的结果,但当把训练好的神经网络模型移植到SNN上时,结构上的不兼容会导致精度的损失。SNNs的应用取决于神经计算芯片的发展。由于其新的设计结构和计算模式,SNNs不能达到传统芯片的理论结果。
为了缩小神经形态计算硬件和软件之间的差距,在新的硬件环境下,软件和硬件的共同设计和协调发展对数据管理和分析是必要的。未来,必须突破冯-诺依曼架构下计算机的固定输入和处理范式,大力发展跨学科的智能计算和仿生学。在算法层面上进行设计,突破现有架构的限制,以更低的计算成本和硬件设计,尝试更可行的、类似人类的数据处理。同时要开发高性能、低能耗的新部件设计方案,提高软件和硬件的计算能力和效率,以满足智能计算需求和应用的快速增长。
6.4 大规模计算系统的解决方案(Solutions to Large-Scale Computing Systems)
智能计算的理论技术架构是一个复杂的系统,有多个子系统与其他学科互动。系统中的各种硬件需要更复杂的系统设计,更好的优化技术,以及系统调整中的许多成本。在高维计算的理论中缺乏复杂性是大规模计算系统的主要挑战。在大规模计算系统中,优化问题可以被简化为多个小任务,以降低系统的复杂性。然而,在这方面还没有坚实的理论基础。对于优化问题,主要目标是使目标函数最小化。然而,当存在多个不确定因素时,最小化目标函数不能捕捉这些不确定因素。不确定性会导致系统的显著变化,从而增加复杂性,这是很难分析的。例如,在计算社会科学问题中,需要建模的主要对象是人的群体。宏观现象的机制,如族群进化和文化传播,可以通过分析人与环境的互动来解释。然而,在操作这样一个大规模的系统时,捕捉所有的微观干扰因素是有问题的。同时,将社会科学的计算过程分解成多个独立的子系统也是一种挑战。
在为大规模应用寻找解决方案时,有必要在任务开始时从宏观角度确定全局参数。需要设计一种新的交互式任务指导方法,在任务理解过程中引入人类的作用。然后,有必要将复杂的计算问题分解成子问题,并根据其逻辑组织问题序列。最后,可以将多个子问题的结果合并为一个完整的解决方案。一般来说,解决大规模问题有三个方面的困难。首先,应探索新的抽象方法来建立微观-宏观联系的因果分析模型,而不是增加更多的参数和建立更复杂的子系统。对于没有直接联系的系统模块,可以通过维度转换揭示它们之间的隐含关系。大规模复杂系统的问题往往涉及多个学科,需要来自不同领域的先验知识和实验经验来解决其子问题的一般数学原理。其次,在大规模系统中,子系统的计算机制是高度非线性的,这可能导致不同子系统的计算资源竞争,甚至相互制约。多层次的子系统使得研究非线性影响的难度成倍增加。研究多级子系统的非线性可以有效地揭示大规模系统的内部机制。最后一个问题是系统的可解释性。一般来说,模型的复杂性会随着精度的提高而逐渐增加,更高的复杂性会导致模型的不可解释性。由于大规模系统经常与现实世界交换信息,各子系统之间复杂的相互作用导致了系统结构的演变。有必要从高阶角度建立一个新的理论来分析其可解释性[227]。
在为大规模应用寻找解决方案时,有必要在任务开始时从宏观角度确定全局参数。需要设计一种新的交互式任务指导方法,在任务理解过程中引入人类的作用。然后,有必要将复杂的计算问题分解成子问题,并根据其逻辑组织问题序列。最后,可以将多个子问题的结果合并为一个完整的解决方案。一般来说,解决大规模问题有三个方面的困难。首先,应探索新的抽象方法来建立微观-宏观联系的因果分析模型,而不是增加更多的参数和建立更复杂的子系统。对于没有直接联系的系统模块,可以通过维度转换揭示它们之间的隐含关系。大规模复杂系统的问题往往涉及多个学科,需要来自不同领域的先验知识和实验经验来解决其子问题的一般数学原理。其次,在大规模系统中,子系统的计算机制是高度非线性的,这可能导致不同子系统的计算资源竞争,甚至相互制约。多层次的子系统使得研究非线性影响的难度成倍增加。研究多级子系统的非线性可以有效地揭示大规模系统的内部机制。最后一个问题是系统的可解释性。一般来说,模型的复杂性会随着精度的提高而逐渐增加,更高的复杂性会导致模型的不可解释性。由于大规模系统经常与现实世界交换信息,各子系统之间复杂的相互作用导致了系统结构的演变。有必要从高阶角度建立一个新的理论来分析其可解释性[227]。
7 总结(Conclusion)
我们目前正迎来人类发展的第四次浪潮,正处于从信息社会向人类-物理-信息一体化的智能社会的关键转型期。在这一转型过程中,计算技术正经历着变革性的、甚至是颠覆性的变化。智能计算被认为是计算的未来方向,不仅是面向智能的计算(intelligenceoriented computing),而且是智能赋能的计算(intelligence-empowered computing)。它将提供普遍、高效、安全、自主、可靠和透明的计算服务,以支持当今智能社会的大规模和复杂的计算任务。本文对智能计算进行了全面的回顾,涵盖了其理论基础、智能与计算的技术融合、重要应用、挑战和未来方向。我们希望这篇综述能给研究人员和从业人员提供一个良好的参考,并促进未来智能计算的理论和技术创新。