【自学开发之旅】Flask-数据查询-数据序列化-数据库关系(四)
db.session
ProductInfo.query
filter() 灵活查询
filter_by()
limit() 限制输出条目
offset() 偏移量
order_by() 排序
group_by() 分组聚合
<模型类>.query.<过滤方法>
过滤方法

查询方法
“牛”字开头且(“,”默认)价格大于5的
>>> ProductInfo.query.filter(ProductInfo.product_name.startswith('牛'), ProductInfo.product_price > 5).all()
[<ProductInfo 3>, <ProductInfo 5>]
>>> result = ProductInfo.query.filter(ProductInfo.product_name.startswith('牛'), ProductInfo.product_price > 5).al
l()
>>> [pro.product_name for pro in result]
['牛肌肉', '牛肉']
用“或”的话需要:导入or_()
>>> from sqlalchemy import or_
>>> ProductInfo.query.filter(or_(ProductInfo.product_name.startswith('牛'), ProductInfo.product_price > 5)).all()
[<ProductInfo 1>, <ProductInfo 3>, <ProductInfo 5>]
>>> result = ProductInfo.query.filter(or_(ProductInfo.product_name.startswith('牛'), ProductInfo.product_price > 5
)).all()
>>> [pro.product_name for pro in result]
['apple', '牛肌肉', '牛肉']
in_的用法:在某个范围
>>> ProductInfo.query.filter(ProductInfo.product_address.in_(['湖南','山东','集美'])).all()
[<ProductInfo 1>, <ProductInfo 2>, <ProductInfo 3>, <ProductInfo 5>, <ProductInfo 6>, <ProductInfo 7>]
>>> result = ProductInfo.query.filter(ProductInfo.product_address.in_(['湖南','山东','集美'])).all()
>>> [pro.product_name for pro in result]
['apple', 'orange', '牛肌肉', '牛肉', '鸡肉', '鸡胸肉']
分页
类.query.filter.(类.属性==“”).offset(3)limit(3).all()
limit限制每页多少条,offset限制多少第多少页
查询product_price > 5的所有记录
两种方法
>>> result = ProductInfo.query.filter(ProductInfo.product_price > 5).all()
>>> ProductInfo.query.filter(ProductInfo.product_price > 5).all()
[<ProductInfo 1>, <ProductInfo 3>, <ProductInfo 5>]
>>> [pro.product_name for pro in result]
['apple', '牛肌肉', '牛肉']
>>> db.session.query(ProductInfo.product_name).filter(ProductInfo.product_price > 5).all()
[('apple',), ('牛肌肉',), ('牛肉',)]
因为查出来还是元组,还需要继续处理
original_list = [('apple',), ('牛肌肉',), ('牛肉',)]
new_list = [item[0] for item in original_list]
print(new_list)
分组聚合
用db.session.query(查询列,聚合列)
.filter(条件) #分组前数据筛选条件
.group_by(“分组列名”) #按什么来分组
.having(条件) #分组之后过滤条件
group by常常和func一起使用
fun,sum()
avg()
max()
min()
count()
查询每个省份的价格平均值
>>> from models.product import ProductInfo
>>> from models import db
>>> from sqlalchemy import func
>>> db.session.query(ProductInfo.product_address, func.avg(ProductInfo.product_price)).group_by("product_address").all()
[('山东', 10.0), ('深圳', 3.0), ('湖南', 11.25), ('集美', 2.5)]
对该结果再减小范围,结果大于5的,用having
>>> db.session.query(ProductInfo.product_address,func.avg(ProductInfo.product_price)).group_by("product_address").having(func.avg(ProductInfo.product_price>5)).all()
[('山东', 10.0)]
>>>
db.session.query(ProductInfo.product_address, ProductInfo.product_name, func.max(ProductInfo.product_price)).group_by("product_address").all()
报错:

解决:
问题是关于SQLAlchemy和MySQL的一个特定问题,具有一定的代码相关性。
这个错误是因为你的SQL查询中有一个在GROUP BY子句中未被聚合的列,这是MySQL的’only_full_group_by’模式所不允许的。由于product_name未包含在GROUP BY子句中,也未在聚合函数(如MAX、MIN、AVG等)中使用,所以MySQL抛出了这个错误。
移除此模式:MySQL的’only_full_group_by’模式是可以更改的。这个模式是在MySQL 5.7.5版本以后引入的,用于限制GROUP BY查询的行为。它要求SELECT列表中的所有非聚合列都必须在GROUP BY子句中出现,否则就会抛出错误。
SET GLOBAL sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
这将从全局的SQL模式中移除’ONLY_FULL_GROUP_BY’选项。
4.运行以下命令来检查当前的SQL模式:
SELECT @@sql_mode;
练习:
查询记录添加时间在1天以前所有记录
>>> ProductInfo.query.filter(ProductInfo.add_time<=(datetime.datetime.now() - datetime.timedelta(days=1))).all()
[<ProductInfo 5>]
查询种类为fruits的前十条记录
ProductInfo.query.filter(ProductInfo.product_kind==1).limit(10).all()
[<ProductInfo 1>, <ProductInfo 2>, <ProductInfo 8>]
查询产地为湖南的第一条记录
ProductInfo.query.filter(ProductInfo.product_address == "湖南").first()
<ProductInfo 2>
查询价格大于10的所有记录,并且倒序(降序desc)排序(order_by)
>>> ProductInfo.query.filter(ProductInfo.product_price>10).order_by(ProductInfo.product_price.desc()).all()
[<ProductInfo 5>, <ProductInfo 3>]
数据序列化
让对象可以跨平台存储,或者进行网络传输
orm实现查询功能
router/product_view/product.py
@product_bp.route("/product/get")
def product_get():
# 通过url携带的参数来传递id
id = request.args.get("id")
if id is None:
result = ProductInfo.query.all()
else:
result = ProductInfo.query.get(id)#result是个对象(结构体)每个平台都不一样,底层实现不一样,不能来传输和返回
#result = ProductInfo.query.filter(ProductInfo.product_id == id).all
#数据序列化:json、pickle库
if result:
#对象 - 字典 - json
#方法一:自定义实现
#tmp_dict = {}
#tmp_dict["product_name"] = result.product_name
#方法二:通过dict函数将对象变成字典。对象要实现keys和__getitem__的方法
# return generate_response(msg="get success!", data=result)
if isinstance(result, list):
result2 = [dict(pro) for pro in result]
else:
result2 = dict(result)
return generate_response(msg='get success!', data=result2)
else:
return generate_response(msg='data empty!', code=6)
使用方法二:
去models/prudct.py去实现那两种方法
# dict函数转化字典的时候,自动调用对象中的keys方法,自定字典中的key,然后依照字典的取值方式(__getitem__去获取对应的key值)
def keys(self):
return ('product_name','product_kind','product_price','product_address')
def __getitem__(self, item):
return getattr(self,item)

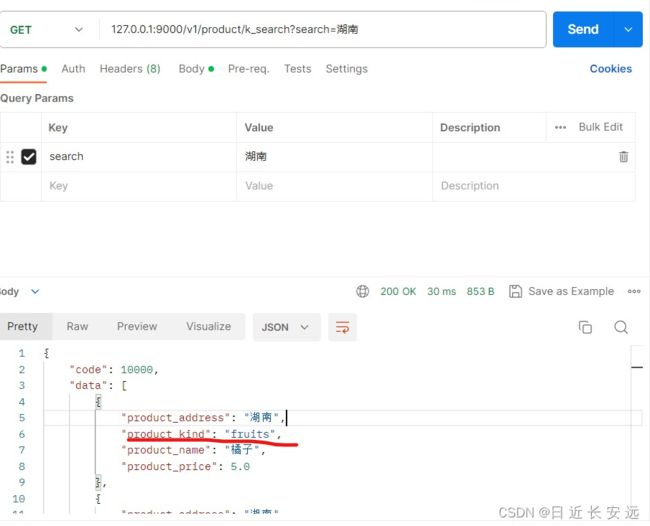
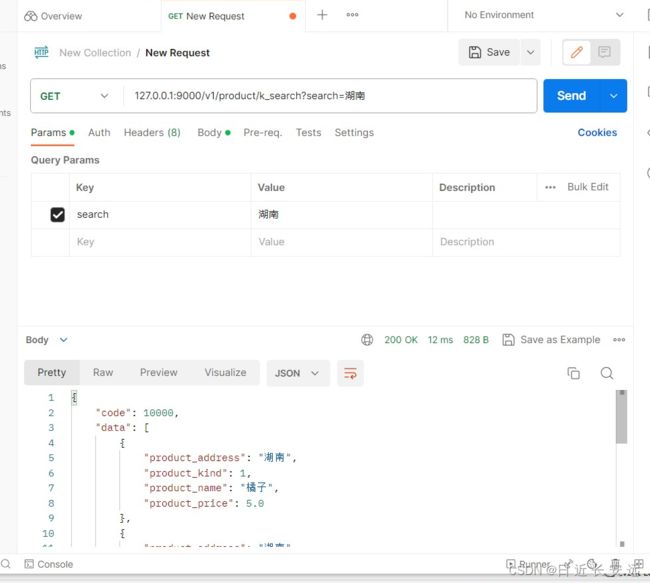
关键字搜索功能接口实现:
@product_bp.route("/product/k_search", methods=["GET"])
def k_search():
pro_search = request.args.get("search")
if pro_search is None:
result = ProductInfo.query.all()
else:
result = ProductInfo.query.filter(or_(ProductInfo.product_address.like(f'%{pro_search}%'), ProductInfo.product_name.like(f'%{pro_search}%')))
result2 = [dict(pro) for pro in result]
return generate_response(code=10000, msg="get product info success", data=result2)
数据库关系:
创建一个种类表,用来查询的时候kind1–fruits
在models/product.py添加
class ProKind(db.Model):
__tablename__ = "pro_kind"
kind_id = db.Column(db.Integer, primary_key=True, autoincrement=True)
kind_name = db.Column(db.String(256))
外键创造联系—relationship
一对一、一对多、多对多
在ProductInfo类中添加(把kind那里改下)
# 建立外键关联
kind_forkey = db.Column(db.ForeignKey('pro_kind.kind_id'))
在ProKind类中添加
# 建立relationship
pro_info = db.relationship("ProductInfo", backref="kind")
“backref”是反向查询字段:
对于ProKind类的对象可以通过pro_info属性查询到关联的ProductInfo,同时它为ProductInfo对象建立了kind属性,ProductInfo对象可以通过kind属性查询响应的ProKind信息
>>> p1 = ProductInfo.query.get(1)
>>> dir(p1)
['__abstract__', '__annotations__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__fsa__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '_
_init_subclass__', '__le__', '__lt__', '__mapper__', '__module__', '__ne__', '__new__', '__reduce__', '__re
duce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__table__', '__tablena
me__', '__weakref__', '_sa_class_manager', '_sa_instance_state', '_sa_registry', 'add_time', 'keys', **'kind'**
, 'metadata', 'product_address', 'product_id', 'product_kind', 'product_name', 'product_price', 'query', 'q
uery_class', 'registry']
>>> p1.kind
<ProKind 1>
>>> p1.kind.kind_name
'fruits'
>>>
上面这个是一对多的联系,如果一对一:
# 建立relationship
pro_info = db.relationship("ProductInfo", backref="kind", userlist=False)
注意都在orm层,不用连表,我们关联到另一个表是指属性字段而已pro_info,数据库中不用创建外键。
>>> k1 = ProKind.query.get(1)
>>> k1
<ProKind 1>
>>> dir(k1)
['__abstract__', '__annotations__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__',
'__format__', '__fsa__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass_
_', '__le__', '__lt__', '__mapper__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__
repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__table__', '__tablename__', '__weakr
ef__', '_sa_class_manager', '_sa_instance_state', '_sa_registry', 'kind_id', 'kind_name', 'metadata', **'pro_
info'**, 'query', 'query_class', 'registry']
>>> k1.pro_info
那接下来怎么查:
将获取属性的时候稍微变一变
models/product.py
def __getitem__(self, item):
if item == 'product_kind':
return self.kind.kind_name
else:
return getattr(self,item)