ClickHouse中MergeTree
ClickHouse中MergeTree
03-CK 引擎之ReplacingMergeTree 引擎
目标
ReplacingMergeTree 表引擎,解决MergeTree相同主键无法去重的问题。
结果:
合并后保存最后插入的记录
路径
- ReplacingMergeTree 引擎作用
- 如何创建表
- 案例演示
实施
为了解决MergeTree相同主键无法去重的问题,ClickHouse提供了ReplacingMergeTree引擎,用来对主键重复的数据进行去重。
删除重复数据可以使用
optimize命令手动执行,这个合并操作是在后台运行的,且无法预测具体的执行时间。
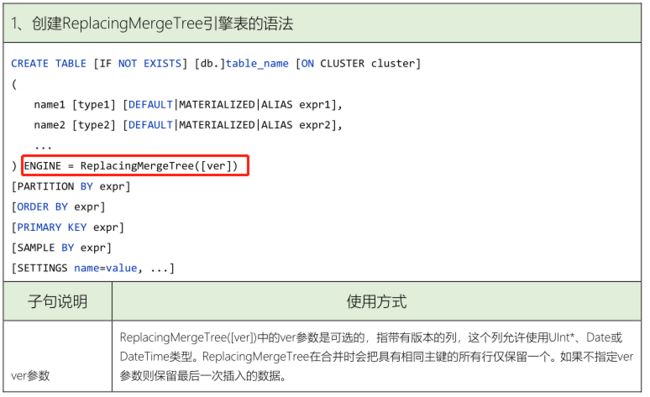
创建表,演示案例:
# 创建表
CREATE TABLE tbl_test_replacingmergetree_users
(
`id` UInt64,
`email` String,
`username` String,
`gender` UInt8,
`birthday` Date,
`mobile` FixedString(13),
`pwd` String,
`regDT` DateTime,
`lastLoginDT` DateTime,
`lastLoginIP` String
)
ENGINE = ReplacingMergeTree(id)
PARTITION BY toYYYYMMDD(regDT)
ORDER BY id
SETTINGS index_granularity = 8192 ;
# 插入数据
INSERT INTO tbl_test_replacingmergetree_users SELECT *
FROM tbl_test_mergetree_users
WHERE id <= 5 ;
# 查询数据
SELECT * FROM tbl_test_replacingmergetree_users ;
# 第二次、插入数据
INSERT INTO tbl_test_replacingmergetree_users (id, email, username, gender, birthday, mobile, pwd, regDT, lastLoginIP, lastLoginDT) SELECT
id,
email,
username,
gender,
birthday,
mobile,
pwd,
regDT,
lastLoginIP,
now() AS lastLoginDT
FROM tbl_test_mergetree_users
WHERE id <= 3 ;
# 第二次、查询数据
SELECT * FROM tbl_test_replacingmergetree_users ;
# 执行优化操作,使用Optimize关键字
OPTIMIZE TABLE tbl_test_replacingmergetree_users FINAL ;
# 第三次、查询数据
SELECT * FROM tbl_test_replacingmergetree_users
小结
为了解决MergeTree相同主键无法去重的问题,ClickHouse提供了ReplacingMergeTree引擎,用来对主键重复的数据进行去重。
ReplacingMergeTree引擎总结
- 使用ORDER BY排序键,作为判断数据是否重复的唯一键
- 只有在合并分区时,才会触发数据的去重逻辑
- 删除重复数据,是以数据分区为单位。同一个数据分区的重复数据才会被删除,不同数据分区的重复数据仍会保留
在进行数据去重时,由于已经基于ORDER BY排序,所以可以找到相邻的重复数据 - 数据去重策略为:
- 若指定了ver参数,则会保留重复数据中,ver字段最大的那一行
- 若未指定ver参数,则会保留重复数据中最末的那一行数据
04-CK 引擎之SummingMergeTree 引擎
目标
SummingMergeTree表引擎,用来支持对主键相同的列进行
预聚合。
结果:
最后数值性列保存的是sum函数求和的结果
路径
- SummingMergeTree 引擎作用
- 如何创建表
- 案例演示
实施
ClickHouse通过SummingMergeTree来支持对主键列进行预聚合。在后台合并时,会将主键相同的多行进行sum求和,然后使用一行数据取而代之,从而大幅度降低存储空间占用,提升聚合计算性能。
在预聚合时,ClickHouse会对主键列以外的其他所有列进行预聚合。
- 但这些列必须是
数值类型才会计算sum(当sum结果为0时会删除此行数据);- 如果是String等不可聚合的类型,则随机选择一个值。
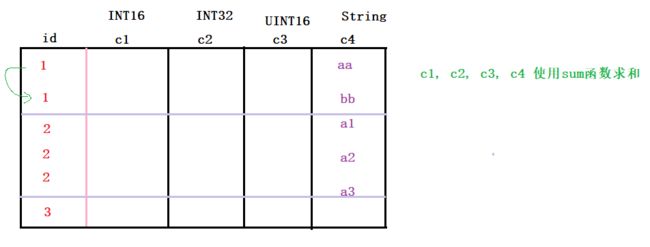
通常建议将SummingMergeTree与MergeTree配合使用,使用MergeTree来存储
明细数据,使用SummingMergeTree存储预聚合的数据来支撑加速查询。
演示案例如下所示
# 1. 创建表
CREATE TABLE tbl_test_summingmergetree
(
`key` UInt64,
`value` UInt64
)
ENGINE = SummingMergeTree()
ORDER BY key ;
# 2. 插入数据
INSERT INTO tbl_test_summingmergetree (key, value) VALUES (1,13);
# 3. 查询数据
SELECT * FROM tbl_test_summingmergetree ;
# 4. 第二次、插入数据
INSERT INTO tbl_test_summingmergetree (key, value) VALUES (1,13);
# 5. 第二次、查询数据
SELECT * FROM tbl_test_summingmergetree ;
# 6. 第三次、插入数据
INSERT INTO tbl_test_summingmergetree (key, value) VALUES (1,16);
# 7. 第四次、查询数据
SELECT * FROM tbl_test_summingmergetree ;
# 8. 第五次、查询数据
SELECT
key,
sum(value),
count(value)
FROM tbl_test_summingmergetree
GROUP BY key
# 9. 优化表
OPTIMIZE TABLE tbl_test_summingmergetree FINAL ;
# 10. 第六次、哈希数据
SELECT * FROM tbl_test_summingmergetree ;
小结
ClickHouse通过SummingMergeTree来支持对主键列进行预聚合,要求非主键列为数据类型。
ReplacingMergeTree引擎总结
- 使用ORDER BY排序键,作为判断数据是否重复的唯一键
- 只有在合并分区时,才会触发数据的去重逻辑
- 删除重复数据,是以数据分区为单位。同一个数据分区的重复数据才会被删除,不同数据分区的重复数据仍会保留
在进行数据去重时,由于已经基于ORDER BY排序,所以可以找到相邻的重复数据 - 数据去重策略为:
- 若指定了ver参数,则会保留重复数据中,ver字段最大的那一行
- 若未指定ver参数,则会保留重复数据中最末的那一行数据
05-CK 引擎之AggregatingMergeTree 引擎
目标
AggregatingMergeTree 引擎,用来做增量数据统计聚合,允许这对不同列指定不同的聚合函数。
路径
- AggregatingMergeTree 引擎作用
- 如何创建表
- 案例演示
实施
AggregatingMergeTree也是预聚合引擎的一种,是在MergeTree的基础上针对聚合函数计算结果进行增量计算用于提升聚合计算的性能。

- 插入数据时,语法:
xxx-State,其中xxx表示聚合函数名称- 查询数据时,语法:
xx-Merge,其中xxx表示聚合函数名称
使用AggregatingMergeTree引擎创建表语法:
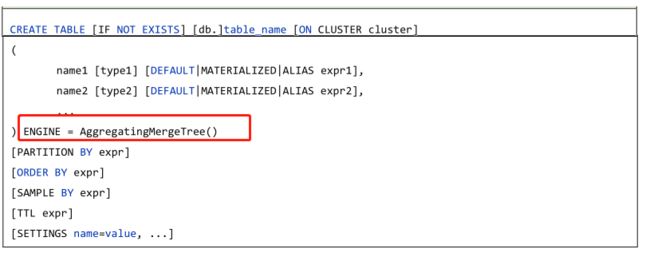
实例案例,如下所示:
# 1. 创建表
CREATE TABLE tbl_test_mergetree_logs
(
`guid` String,
`url` String,
`refUrl` String,
`cnt` UInt16,
`cdt` DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(cdt)
ORDER BY toYYYYMMDD(cdt) ;
# 2. 插入数据
INSERT INTO tbl_test_mergetree_logs (guid, url, refUrl, cnt, cdt) VALUES ('a','www.itheima.com','www.itcast.cn',1,'2019-12-17 12:12:12'),('a','www.itheima.com','www.itcast.cn',1,'2019-12-17 12:14:45'),('b','www.itheima.com','www.itcast.cn',1,'2019-12-17 13:13:13');
# 3. 查询数据
SELECT * FROM tbl_test_mergetree_logs ;
┌─guid─┬─url─────────────┬─refUrl────────┬─cnt─┬─────────────────cdt─┐
│ a │ www.itheima.com │ www.itcast.cn │ 1 │ 2019-12-17 12:12:12 │
│ a │ www.itheima.com │ www.itcast.cn │ 1 │ 2019-12-17 12:14:45 │
│ b │ www.itheima.com │ www.itcast.cn │ 1 │ 2019-12-17 13:13:13 │
└──────┴─────────────────┴───────────────┴─────┴─────────────────────┘
# 4. 创建表
CREATE TABLE tbl_test_aggregationmergetree_visitor
(
`guid` String,
`cnt` AggregateFunction(count, UInt16),
`cdt` Date
)
ENGINE = AggregatingMergeTree()
PARTITION BY cdt
ORDER BY cnt ;
# 5. 插入数据
INSERT INTO tbl_test_aggregationmergetree_visitor SELECT
guid,
countState(cnt),
toDate(cdt)
FROM tbl_test_mergetree_logs
GROUP BY
guid,
cnt,
cdt ;
# 6. 查询数据
SELECT
guid,
count(cnt)
FROM tbl_test_aggregationmergetree_visitor
GROUP BY
guid,
cnt ;
小结
AggregatingMergeTree也是预聚合引擎的一种,是在MergeTree的基础上针对聚合函数计算结果进行增量计算用于提升聚合计算的性能。通过预先定义的聚合函数计算数据并通过二进制的格式存入表内。
06-CK 引擎之CollapsingMergeTree 引擎(折叠树)
目标
CollapsingMergeTree 折叠树引擎,通过
以增代删的思路,支持行级数据修改和删除的表引擎。
结果
根据sign 对1 和-1进行计算和为0 优化时删除
路径
- CollapsingMergeTree 引擎(折叠树)作用
- 如何创建表
- 案例演示
实施
在ClickHouse中不支持对数据update和delete操作(不能使用标准的更新和删除语法操作CK),但在增量计算场景下,状态更新是一个常见的现象,此时update操作似乎更符合这种需求。
ClickHouse提供了一个CollapsingMergeTree表引擎,它继承于MergeTree引擎,是通过一种变通的方式来实现状态的更新。
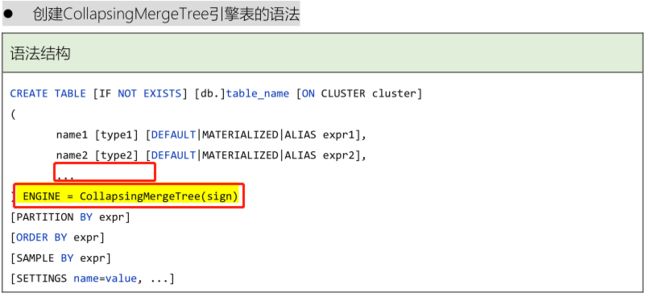
基本思路:创建表时,需要指定Sign列(必须是Int8类型,有2个值:1和-1)
指定Sign列(必须是Int8类型):
- 1表示为状态行,当需要
新增一个状态时,需要将insert语句中的Sign列值设为1;- -1表示为取消行,当需要
删除一个状态时,需要将insert语句中的Sign列值设为-1。
演示案例如下:
# 1. 创建表
CREATE TABLE tbl_test_collapsingmergetree_day_mall_sale
(
`mallId` UInt64,
`mallName` String,
`totalAmount` Decimal(32, 2),
`cdt` Date,
`sign` Int8
)
ENGINE = CollapsingMergeTree(sign)
PARTITION BY toYYYYMMDD(cdt)
ORDER BY mallId ;
# 2. 插入数据
INSERT INTO tbl_test_collapsingmergetree_day_mall_sale (mallId, mallName, totalAmount, cdt, sign) VALUES (1,'西单大悦城',17649135.64,'2019-12-24',1);
# 3. 插入数据
INSERT INTO tbl_test_collapsingmergetree_day_mall_sale (mallId, mallName, totalAmount, cdt, sign) VALUES (2,'朝阳大悦城',16341742.99,'2019-12-24',1);
# 4. 查询数据
SELECT * FROM tbl_test_collapsingmergetree_day_mall_sale
# 5. 插入数据
INSERT INTO tbl_test_collapsingmergetree_day_mall_sale (mallId, mallName, totalAmount, cdt, sign) VALUES (1,'西单大悦城',17649135.64,'2019-12-24',-1);
# 6. 插入数据
INSERT INTO tbl_test_collapsingmergetree_day_mall_sale (mallId, mallName, totalAmount, cdt, sign) VALUES (2,'朝阳大悦城',16341742.99,'2019-12-24',-1);
# 7. 优化数据
OPTIMIZE TABLE tbl_test_collapsingmergetree_day_mall_sale FINAL
# 8. 查询数据
SELECT * FROM tbl_test_collapsingmergetree_day_mall_sale
# 9. 插入数据
INSERT INTO tbl_test_collapsingmergetree_day_mall_sale (mallId, mallName, totalAmount, cdt, sign) VALUES (1,'西单大悦城',17649135.64,'2019-12-24',1);
INSERT INTO tbl_test_collapsingmergetree_day_mall_sale (mallId, mallName, totalAmount, cdt, sign) VALUES (2,'朝阳大悦城',16341742.99,'2019-12-24',1);
INSERT INTO tbl_test_collapsingmergetree_day_mall_sale (mallId, mallName, totalAmount, cdt, sign) VALUES (1,'西单大悦城',17649135.64,'2019-12-24',-1);
# 10. 查询数据
SELECT * FROM tbl_test_collapsingmergetree_day_mall_sale ;
# 11. 优化数据
OPTIMIZE TABLE tbl_test_collapsingmergetree_day_mall_sale FINAL ;
# 12. 查询数据
SELECT * FROM tbl_test_collapsingmergetree_day_mall_sale;
小结
CollapsingMergeTree表引擎,通过定义一个
sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。
- 每次需要新增数据时,写入一行sign标记为1的数据;
- 需要删除数据时,则写入一行sign标记为-1的数据。
07-CK 引擎之多版本折叠树引擎
目标
VersionedCollapsingMergeTree引擎,使用version列来实现乱序情况下的数据折叠。
结果
结果的问题时多用户同时插入时乱序的问题,
同version版本计算sign的和
路径
- VersionedCollapsingMergeTree引擎作用
- 如何创建表
- 案例演示
为什么不可以用sign(collapsingmergeTree)?
举例多线程同时对主键为1的数据一个进行插入一个进行删除,就会乱序。故不可以。
实施
该引擎继承自 MergeTree 并将折叠行的逻辑添加到合并数据部分的算法中,这个引擎:

允许以多个线程的任何顺序插入数据,特别是
Version列有助于正确折叠行。
比如1个表:
- 第一步、插入id=1数据,sign=1,version=1
- 第二步、插入id=1数据,sign=-1,version=1
- 第三步、插入id=1数据,sign=1,version=3
- 第四步、插入id=1数据,sign=1,version=2
- 第五步、插入id=1数据,sign=-1,version=2
其中表中存在两个字段:
- 1)、
Sign:标识字段,类型:Int8,值:1:状态行和-1:删除行- 2)、
Version:版本字段,类型UInt8,值为正整数
创建表,进行演示:
# 1. 创建表
CREATE TABLE UAct
(
`UserID` UInt64,
`PageViews` UInt8,
`Duration` UInt8,
`Sign` Int8,
`Version` UInt8
)
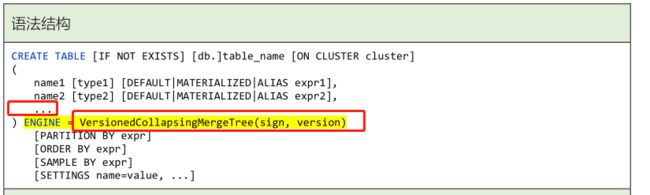
ENGINE = VersionedCollapsingMergeTree(Sign, Version)
ORDER BY UserID ;
# 2. 插入数据
INSERT INTO UAct VALUES (4324182021466249494, 5, 146, 1, 1) ;
# 3. 查询数据
SELECT * FROM UAct ;
# 4. 插入数据
INSERT INTO UAct VALUES (4324182021466249494, 5, 146, -1, 1),(4324182021466249494, 6, 185, 1, 2) ;
# 5. 查询数据
SELECT * FROM UAct ;
# 6. 优化数据
OPTIMIZE TABLE UAct FINAL ;
# 7. 查询数据
SELECT * FROM UAct ;
小结
VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。