Selenium元素定位——八大方法详述
这里写目录标题
- 一、元素的概念
- 二、元素定位方法
-
- (一)根据id定位
- (二)根据name定位
- (三)根据class name定位
- (四)根据tag定位
- (五)根据link text定位
- (六)根据partial link text定位
- (七)根据XPath定位
- (八)根据css selector定位
- 三、代码示例
一、元素的概念
元素:由标签头 + 标签尾 + 标签头和标签尾包括的文本内容;
元素的信息就是指元素的标签名及元素的属性;
元素的层级结构就是指元素之间相互嵌套的层级结构;
元素定位最终就是通过元素的信息或者元素的层级结构来进行元素定位;
二、元素定位方法
webdriver 提供了一系列的对象定位方法,常用的有以下8种:
| 定位一个元素 | 定位多个元素 | 含义 |
|---|---|---|
| find_element(By.ID,value) | find_elements(By.ID,value) | 通过元素id定位 |
| find_element(By.NAME,value) | find_elements(By.NAME,value) | 通过元素name定位 |
| find_element(By.XPATH,value) | find_elements(By.XPATH,value) | 通过xpath表达式定位 |
| find_element(By.LINK_TEXT,value) | find_elements(By.LINK_TEXT,value) | 通过完整超链接定位 |
| find_element(By.PARTIAL_LINK_TEXT,value) | find_elements(By.PARTIAL_LINK_TEXT,value) | 通过部分链接定位 |
| find_element(By.TAG_NAME,value) | find_elements(By.TAG_NAME,value) | 通过标签定位 |
| find_element(By.CLASS_NAME,value) | find_elements(By.CLASS_NAME,value) | 通过类名进行定位 |
| find_element(By.CSS_SELECTOR,value) | find_elements(By.CSS_SELECTOR,value) | 通过css选择器进行定位 |
(一)根据id定位
在HTML当中,id属性是唯一标识一个元素的属性,因此在selenium当中,通过id来进行元素的定位也较为常用。
百度搜索框的元素如图所示:

百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位(下面有代码详细,此处仅简单展示方法):
element = web.find_element(By.ID, "kw")
(二)根据name定位
在HTML当中,name属性和id属性的功能基本相同,只是name属性并不是唯一的,如果遇到没有id标签的时候,我们可以考虑通过name标签来进行定位。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位(下面有代码详细,此处仅简单展示方法):
element = web.find_elements(By.NAME,"wd")
(三)根据class name定位
我们也可以基于class属性来定位元素。通常当我们看到有多个并列的元素如list表单,class用的都是共用同一个。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位(下面有代码详细,此处仅简单展示方法):
element = web.find_element(By.CLASS_NAME,"s_ipt")
(四)根据tag定位
HTML是通过tag来定义一类功能的,比如input是输入,table是表格,tbody是表格主体等。每个元素其实就是一个tag,由于一个tag用来定义一类功能,一个网页往往有很多同类tag,所以很难通过tag去区分不同的元素。
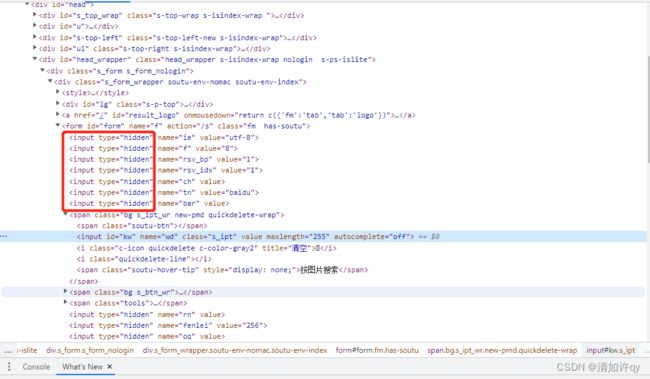
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位(下面有代码详细,此处仅简单展示方法):
element = web.find_elements(By.TAG_NAME,"input")
由于百度首页有很多标签名字都是”input",因此上述代码只会定位到网页的第一个“input”标签。
(五)根据link text定位
通过超链接的文本定位元素。
百度上方超链接”新闻“元素如图所示:

百度上方超链接”新闻“元素元素html结构:
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻a>
元素定位(下面有代码详细,此处仅简单展示方法):
element = web.find_element(By.LINK_TEXT,"新闻")
(六)根据partial link text定位
有时候一个超链接的文本很长,我们如果全部输入,既麻烦,又显得代码很不美观,这时候我们就可以只截取一部分字符串,进行模糊匹配。
百度上方超链接”新闻“元素html结构:
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻a>
元素定位(下面有代码详细,此处仅简单展示方法):
element = web.find_element(By.LINK_TEXT,"新")
(七)根据XPath定位
Xpath是一种在XML和HTML文档中查找信息的语言,通过Xpath路径来定位元素的时候也是分绝对路径和相对路径。
XPath比较复杂,但十分好用,具体可看小编的另一篇文章:
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
xpath定位表达式:
//*[@id="kw"]
Python通过xpath定位语句:
element = web.find_element(By.XPATH,'//*[@id="kw"]')
(八)根据css selector定位
css selector可以通过很多方式定位元素
ID:
element = web.find_element(By.CSS_SELECTOR,"#kw")
class name:
element = web.find_element(By.CLASS_NAME,"s_ipt")
属性选择器:
根据标签中的属性来定位元素, 格式: [属性名=”属性值”],或标签名[属性名=属性值]。如果属性是唯一的,那么标签名可以不用写。
百度搜索框元素html结构:
<input type="text" class="s_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
元素定位:
element = web.find_element_by_css_selector('[id="kw"]')
element = web.find_element_by_css_selector('input[id="kw"]')
三、代码示例
"""
元素定位:
ID = "id" 通过id元素定位
XPATH = "xpath" 通过xpath定位
LINK_TEXT = "link text" 通过链接文本定位
PARTIAL_LINK_TEXT = "partial link text" 通过部分链接文本定位
NAME = "name" 通过标签名称定位
TAG_NAME = "tag name" 通过标签名称定位
CLASS_NAME = "class name" 通过css class定位
CSS_SELECTOR = "css selector" 通过css选择器
"""
from time import sleep
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
class TestCase(object):
def setup(self):
"""
Service: 传入 chromedriver 的路径
driver: 创建会话 session 和 将后续的代码传入到 chromedriver 并且执行
:return:
"""
service = Service(executable_path=ChromeDriverManager().install())
self.driver = webdriver.Chrome(service=service)
self.driver.get("https://www.baidu.com/")
self.driver.maximize_window()
def teardown(self):
self.driver.quit() #在case执行完后关闭浏览器
# todo 通过id元素定位 id 是唯一的
def test_id(self):
# 1 对象 driver 2 element
element = self.driver.find_element(By.ID, "kw") #kw为ID内容,通过抓包取得,此条为搜索框
element.send_keys("任意内容") #填入搜索框的内容
print(dir(element))
print(type(element))
# #element类型
self.driver.find_element(By.ID, "su").click()
sleep(2) #页面展示两秒,可根据需求自行调节
# todo 通过标签名称定位 name 方法可能定位到多个元素,返回第一个
def test_name(self):
ele = self.driver.find_elements(By.NAME,"wd") #wd为name内容,通过抓包取得,此条为搜索框
print(ele)
ele[0].send_keys("任意内容") #填入搜索框的内容
self.driver.find_element(By.ID,"su").click()
sleep(3)
# todo 通过链接文本定位
def test_link_text(self):
sleep(4)
self.driver.find_element(By.LINK_TEXT,"登录").click()
sleep(4)
# todo 通过部分链接文本定位
def test_partial_link_text(self):
self.driver.find_element(By.PARTIAL_LINK_TEXT,"登").click()
sleep(3)
# todo 通过标签名称定位 返回一个标签列表 通过下表可以取值
def test_tag_name(self):
input = self.driver.find_elements(By.TAG_NAME,"input")
print(input)
sleep(3)
#todo 通过xpath定位 路径
def test_xpath(self):
sleep(2)
self.driver.find_element(By.XPATH,'//a[span="4"]').click()
sleep(3)
self.driver.find_element(By.XPATH,'//ur[@class="s-hotsearch-content]/li[4]').click()
sleep(3)
#todo 通过css选择器
def test_css_selector(self):
self.driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("任意内容")
self.driver.find_element(By.ID,"su").click()
sleep(3)
self.driver.close()
#todo 通过css class定位
def test_class_name(self):
self.driver.find_element(By.CLASS_NAME,"s_ipt").send_keys('任意内容')
self.driver.find_element(By.CLASS_NAME,"s_btn").click()
sleep(3)
self.driver.close()