Kafka-消费者
《Kafka权威指南》学习笔记
Kafka-消费者一一从Kafka读取数据
应用程序使用KafkaConsumer向Kafka订阅主题,并从订阅的主题上接收消息。
消费者和消费者群组
Kafka消费者从属于消费者群组。一个群组里的消费者订阅的是同一个主题,每个消费者接收主题一部分分区的消息。
注意:同一个分区的数据只能由一个消费者读取,如果消费者数超过分区数,则会有一部分消费者闲置,不会出现多个同一个group中的消费者同时读取同一个分区的情况。
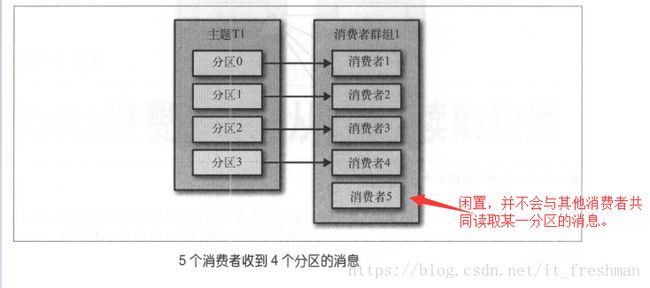
消费者群组和分区再均衡
群组里的消费者共同读取主题的分区。
- 一个新的悄费者加入群组时,它读取的是原本由其他消费者读取的消息。
- 当一个消费者被关闭或发生崩溃时,它就离开群组,原本由它读取的分区将由群组里的其他消费者来读取。
在主题发生变化时,比如管理员添加了新的分区,会发生分区重分配。分区的所有权从一个消费者转移到另一个消费者,这样的行为被称为再均衡。
消费者通过向被指派为群组协调器的broker(不同的群组可以有不同的协调器)发送心跳来维持它们和群组的从属关系以及它们对分区的所有权关系。
创建Kafka消费者
在读取消息之前,需要先创建一个KafkaConsumer对象。创建KafkaConsumer对象对象与创建KafkaProducer对象非常相似一一把想要传给消费者的属性放在Properties对象里。
必选属性
我们只需要使用3个必要的属性:
bootstrap.server:KafkaProducer对象配置类似,指定Kafka集群的连接字符串。key.deserializer和value.deserializer:同KafkaProducer的serializer类似,不过它的作用是把byte[]->Objectgroup.id:不是必须的。但是我们姑且认为它是必须的。它指定了消费者属于哪一个消费者组。
API创建消费者
Properties kafkaProps=new Properties();
kafkaProps.put("bootstrap.servers","s159:9092");
//deserializer
kafkaProps.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
kafkaProps.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
//消费组---非必须条件
kafkaProps.put("group.id","gp12");
consumer=new KafkaConsumer(kafkaProps);
订阅主题
创建好消费者之后,下一步可以开始订阅主题了。
//接受一个主题列表作为参数
consumer.subscribe(Arrays.asList("test.a","test.b"));
//正则表达式订阅test.开头的所有主题
consumer.subscribe("test.*");
轮询
消息轮询是消费者API的核心,通过一个简单的轮询向服务器请求数据。
一旦消费者订阅了主题,轮询就会处理所有的细节,包括群组协调、分区再均衡、发送心跳和获取数据,开发者只需要使用一组简单的API来处理从分区返回的数据。
try{
while(true){
/**
*timeout:用于控制timeout的阻塞时间。
*在消费者缓冲区内没有数据时会发生阻塞。
*若设置为0:表示不阻塞,直接返回。
*/
ConsumerRecords records = consumer.poll(10000);
for(ConsumerRecord record : records){
System.out.println("----------"+record.value());
}
}
}finally{
consumer.close();
}
线程安全
同一个群组里,我们无法让一个线程运行多个消费者,也无法让多个线程安全的共享一个消费者。按照规则,一个消费者使用一个线程。如果要在同一个消费组里运行多个消费者,需要让每个消费者都运行在自己(独享)的线程里。
消费者配置
fetch.min.bytes:该属性指定了消费者,从服务器获取记录的最小字节数。broker在收到消费者的数据请求时它会等到有足够的可用数据时才把它返回给消费者。fetch.max.bytes: 单次fetch请求将返回的最大字节数. Default: 57671680 (55 mebibytes),最小值为: 1024- https://kafka.apache.org/documentation/#brokerconfigs_fetch.max.bytes
fetch.max.wait.ms:指定broker的等待时间,默认是500ms。如果broker在超过设置的时间内,仍然没有足够的数据,也依然会返回给消费者。max.partition.fetch.bytes:该属性指定了服务器从每个分区里返回给消费者的最大字节数。它的默认值是1MB.session.timeout.ms:默认是3sauto.offset.reset:该属性指定了消费者在读取一个没有偏移量的分区或者偏移量无效的情况下(因消费者长时间失效,包含偏移量的记录已经过时井被删除)该作何处理。latest(默认值):它的意思是,在偏移量无效的情况下,消费者将从最新的记录开始读取(在消费者启动之后生成的记录)。earliest:在偏移量无效的情况下,消费者将从起始位置读取分区的记录。
enable.auto.commit:该属性指定了消费者是否自动提交偏移量,默认值是true.- 为了尽量避免出现重复数据和数据丢失,可以把它设为false,由自己控制何时提交偏移量。
- 如果把它设为true,还可以通过配置
auto.commit.interval.ms属性来控制提交的频率,默认是5000(5s)。
partition.assignment.strategy:分区会被分配给群组里的消费者。PartitionAssignor根据给定的消费者和主题,决定哪些分区应该被分配给哪个消费者。Kafka有两个默认的分配策略。Range:该策略会把主题的若干个连续的分区分配给消费者。如topic有3个分区(P0,P1,P2),而消费者组有两个消费者C1和C2,那么C1可能会分配到分区P0、P1,而C2分配到分区P2.RoundRobin:该策略把主题的所有分区逐个分配给消费者。如topic有3个分区(P0,P1,P2),而消费者组有两个消费者C1和C2,那么可能C1先分配P0,C2分配P1,然后C1再分配P2,
client.id:该属性可以是任意字符串,broker用它来标识从客户端发送过来的消息,通常被用在日志、度量指标和配额里。max.poll.records:单词poll()可以返回的记录数量。
消费群组配置
列出并描述群组
- list
- 旧版本:
./kafka-consumer-groups.sh --zookeeper s159:2181,s162:2181,s163:2181 --list
This will only show information about consumers that use ZooKeeper (not those using the Java consumer API).
- 新版本:
./kafka-consumer-groups.sh [--new-consumer] --bootstrap-server s159:9092,s162:9092 --list; --new-consumer可选
Note: This will not show information about old Zookeeper-based consumers.
- 旧版本:
describe
查看消费群组详情,只需将 --list 改为 --describe,并添加 --group XXX即可。
./kafka-consumer-groups.sh --bootstrap-server s159:9092,s162:9092 --describe --group group1

delete
删除group。注意,在进行删除操作之前,需要先关闭消费者,或者不要让它们读取即将被删除的主题。
./kafka-consumer-groups.sh --bootstrap-server s159:9092,s162:9092 --delete --group group1
提交和偏移量
每次调用poll()方法,它总是返回由生产者写入Kafka但还没有被消费者读取过的记录,我们因此可以追踪到哪些记录是被群组里的哪个消费者读取的。
消费者可以使用Kafka来追踪消息在分区里的位置(偏移量),更新偏移量的操作叫做提交。
那么消费者是如何提交偏移量的呢?
消费者往一个叫作__consumer_offser的特殊主题发送消息,消息里包含每个分区的偏移量。
如果消费者一直处于运行状态,那么偏移量就没有什么用处。不过,如果消费者发生崩溃或者有新的消费者加入群组,就会触发再均衡,完成再均衡之后,每个消费者可能分配到新的分区,而不是之前处理的那个。
为了能够继续之前的工作,消费者需要读取每个分区最后一次提交的偏移量,然后从偏移量指定的地方继续处理。
- 如果提交的偏移量小于客户端处理的最后一个消息的偏移量,那么处于
两个偏移量之间的消息就会被重复处理 - 如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于
两个偏移量之间的消息将会丢失
KafkaConsumerAPI提供了很多种方式来提交偏移量。
自动提交
enable.auto.commit设置为true,auto.commit.interval.ms时间间隔会自动提交偏移量。
手动提交
enable.auto.commit设置为false,让应用程序来决定何时提交偏移量。
同步:consumer.commitSync():处理完当前批次的消息,在轮询更多的消息之前,调用此方法提交当前批次最新的偏移量(阻塞)。只要没有发生不可恢复的错误,该方法会一直尝试直至提交成功。如果提交失败,我们也只能把异常记录到错误日志里。异步:consumer.commitAsync():同步提交后,在broker对提交请求作出回应之前,应用程序会一直阻塞,这样会限制应用程序的吞吐量。
在成功提交或碰到无怯恢复的错误之前,consumer.commitSync()会一直重试,但是consumer.commitAsync()不会重试。
同步和异步组合提交
在消费者关闭前一般会组合使用commitSync()和commitAsync()。
public void polling(){
try{
while(true){
ConsumerRecords records= consumer.poll(10000);
for(ConsumerRecord record : records){
System.out.println("----------"+record.value());
}
//每次轮询处理完,异步提交offset
consumer.commitAsync();
}
}finally{
//当出现异常、或关闭时 同步提交
consumer.commitSync();
consumer.close();
}
}
提交特定的偏移量
提交偏移量的频率与处理消息批次的频率是一样的。但如果想要更频繁地提交出怎么办?
如果poll()方告返回一大批数据,为了避免因再均衡引起的重复处理整批消息,
想要在批次中间提交偏移量该怎么办?
这种情况无法通过调用commitSync()或commitAsync()来实现,因为它们只会提交最后一个偏移量,而此时该批次里的消息还没有处理完。
幸运的是,消费者API允许在调用commitSync()或commitAsync()方桂时传进去希望提交的分区和偏移量的map。假设你处理了半个批次的消息,你可以调用commitSync(Map< TopicPartition , OffsetAndMetadata > currentOffsets)方法来提交它。
不过,因为消费者可能不只读取一个分区,偶尔需要跟踪所有分区的偏移量,所以在这个层面上控制偏移量的提交会让代码变复杂。
例:
public void polling2(){
try{
Map currentOffsets = new HashMap<>();
int count=0;
while(true){
ConsumerRecords records = consumer.poll(10000);
for(ConsumerRecord record : records){
//消费消息
System.out.println("----------"+record.value());
currentOffsets.put(new TopicPartition(record.topic(),record.partition()),new OffsetAndMetadata((record.offset()+1),"nometadata"));
//每处理1000条记录,手动提交偏移量
if(count % 1000 == 0){
consumer.commitSync(currentOffsets);
}
count++;
}
}
}finally{
consumer.close();
}
}
再均衡监昕器
消费者在退出和进行分区再均衡之前,会做一些清理工作。
你可以在消费者失去对一个分区的所有权之前提交最后一个已处理记录的偏移量。
在为消费者分配新分区或移除旧分区时,可以通过消费者API执行一些应用程序代码,在调用subscribe方法时传进去一个ConsumerRebalanceListener实例就可以了,ConsumerRebalanceListener有两个需要实现的方法。
consumer.subscribe(Collections.singleton("x"),new ConsumerRebalanceListener() {
@Override
public void onPartitionsAssigned( Collection partitions) {
//在获得新分区后 do- nothing
}
@Override
public void onPartitionsRevoked( Collection partitions ) {
//即将失去分区所有权时提交偏移量
consumer.commitSync(currentOffsets);
}
});
从特定偏移量处开始处理记录
我们知道了如何使用poll()方告从各个分区的最新偏移量处开始处理消息,不过,有时候我们也需要从特定的偏移量处开始读取悄息。
seekToBeginning(Collection:从分区的起始位置开始读取消息tp) seekToEnd(Collection:接跳到分区的末尾开始读取消息tp)
Kafka也为我们提供了用于查找特定偏移量的API,在使用Kafka以外的系统来存储偏移量时,它提供了很大的便利。
试想一下这样的场景:应用程序从Kafka读取事件,对它们进行处理,然后把结果保存到数据库、NoSQL存储引擎或Hadoop。假设我们真的不想丢失任何数据,也不想在数据库里多次保存相同的结果。
这种情况下,消费者的代码可能是这样的:
public void testDBSeek(){
consumer.subscribe(Collections.singleton("x"),new ConsumerRebalanceListener() {
@Override
public void onPartitionsAssigned(Collection partitions){
//在获得新分区后,从db查找offset
for(TopicPartition partition : partitions){
//定位到指定偏移量
consumer.seek(partition,getOffsetFromDB(partition));
}
}
@Override
public void onPartitionsRevoked(Collection partitions){
//提交数据库事务
commitDBTransaction();
}
});
try{
while(true){
ConsumerRecords records = consumer.poll(10000);
for(ConsumerRecord record : records){
//消费消息
currentOffsets.put(new TopicPartition(record.topic(),record.partition()),new OffsetAndMetadata((record.offset()+1),"nometadata"));
//处理record
processRecord(record);
//记录record到数据库
storeRecordInDB(record);
//记录偏移量到数据库
rstoreOffsetinDB(record.topic(),record.partition(),record.offset());
}
//提交事务
commitDBTransaction();
}
}finally{
consumer.close();
}
}
如何退出
消费者poll()会在一个无限循环里轮询消息,如何优雅地退出循环?
如果确定要退出循环,需要通过另一个线程调用consumer.wakeup()方住,它是消费者唯一一个可以从其他线程里安全调用的方法。
Runtime.getRuntime().addShutdownHook(new Thread(()->{
consumer.wakeup();
}));