Docker实操4——Stable Baselines3强化算法库
Docker——强化算法库StableBaselines3
- 概述
- 一、跑通Stable_baselines
- 二、Stable-Baselines
-
- 2.1 看setup.py
- 2.2 package的基本信息
- 2.3 RL Baselines Zoo[^2]
- 2.4 PyBullet[^3]
- 2.5 Atari
- 三、总结
概述
- 上一篇文章里制作好了一个强化环境的镜像Docker实操3——配置强化学习环境镜像——dm_control:py38_mujoco210
- 这次主要目的是接入强化学习算法库Stable Baselines31:https://github.com/DLR-RM/stable-baselines3
一、跑通Stable_baselines
- 跑起上一篇文章里Dockerfile配置的环境镜像,其容器命名为stable_baselines
# 实际使用时,可挂载volume来保存container中自己想保存的数据(后续细说)
nvidia-docker run -itd --name stable_baselines --network host dm_control:py38_mujoco210 bash
- 进入容器,并激活镜像中我们配置的conda虚拟环境deep_rl
# 以用户pamirl的身份进入
docker exec -it -u pamirl stable_baselines bash
cd ~
conda activate deep_rl
- 容器内安装stable_baselines3算法库
pip install stable-baselines3[extra]
pip install pyglet
- 首先测试一下之前装的mujoco210:
python test_mujoco.py
# test_mujoco.py
import mujoco_py
import os
mj_path = mujoco_py.utils.discover_mujoco()
xml_path = os.path.join(mj_path, 'model', 'humanoid.xml')
model = mujoco_py.load_model_from_path(xml_path)
sim = mujoco_py.MjSim(model)
print(sim.data.qpos)
sim.step()
print(sim.data.qpos)
结果如下:

5. 再测试一下cuda是否正常:python test_cuda.py
# test_cuda.py
import torch
print(torch.__version__)
print(torch.cuda.is_available()) #cuda是否可用
print(torch.cuda.device_count()) #返回GPU的数量
print(torch.cuda.get_device_name(0)) #返回gpu名字

- 调用PPO跑一个CartPole:
python test_stable_baselines.py
# test_stable_baselines.py
import gym
from stable_baselines3 import PPO
env = gym.make("CartPole-v1")
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=100000)
obs = env.reset()
for i in range(1000):
action, _states = model.predict(obs, deterministic=True)
obs, reward, done, info = env.step(action)
#env.render()
if done:
obs = env.reset()
env.close()
跑了10万步的训练结果如下:

7. 调用PPO跑一百万步的HalfCheetah-v3,结果如下:
二、Stable-Baselines
2.1 看setup.py
在github上看看stable-baselines的setup.py,对照一下关键包的版本问题
- setup.py


- 在容器上运行
conda list | grep gym,容器内gym版本刚好满足,pytorch更不用说啦,本来安装的就是1.10.1版本!
- 在容器上运行
conda list | grep atari
(有点担心,可能会埋下隐患,但我相信atari_py的兼容性!)

2.2 package的基本信息
pip show stable-baselines3:查看包的metadata
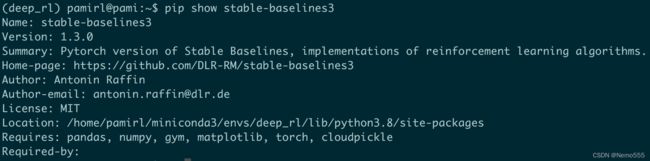
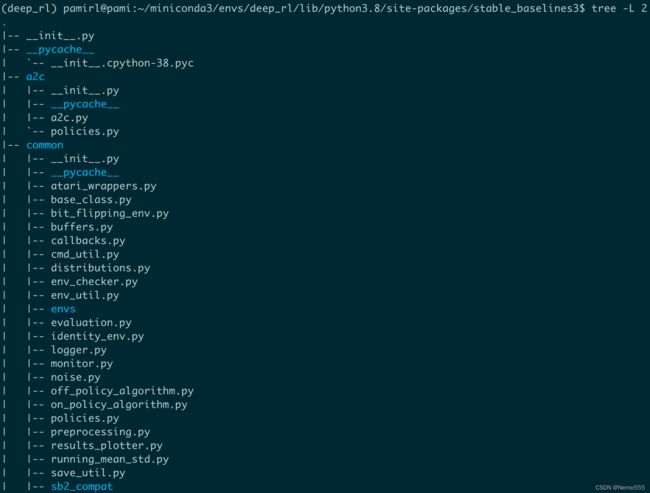
cd /home/pamirl/miniconda3/envs/deep_rl/lib/python3.8/site-packages && tree -L 2:查看包的结构
- 然后就是看Stable-Baselines3 Documentation,具体代码去学习各种算法的写法以及封装了
2.3 RL Baselines Zoo2
- 假设我们学会了怎么用stable baselines,发现还要写好多辅助脚本:监控训练过程、模型载入、保存、评估、画图、调参等。这时候就可以看RL Baselines Zoo ,里面提供了许多训练、画图、评估的脚本
- git clone RL Baselines Zoo,直接用它脚本ok!
- 剩下的就是仔细看Stable Baselines 和 RL Baslines Zoo的文档就好了,那么使用就没问题!后面再仔细介绍如何魔改stable-baselines的开发流程,I mean 利用stable-baselinses创造新算法,监控训练过程,保存、加载、评估模型、绘
2.4 PyBullet3
pip3 install pybullet --upgrade --user:惊喜地发现使用pybullet环境也非常简单
# python test_pybullet.py
import os
import gym
import pybullet_envs
from stable_baselines3.common.vec_env import DummyVecEnv, VecNormalize
from stable_baselines3 import PPO
env = DummyVecEnv([lambda: gym.make("HalfCheetahBulletEnv-v0")])
# Automatically normalize the input features and reward
env = VecNormalize(env, norm_obs=True, norm_reward=True,
clip_obs=10.)
model = PPO('MlpPolicy', env)
model.learn(total_timesteps=2000)
print("finish learning")
# Don't forget to save the VecNormalize statistics when saving the agent
log_dir = "/tmp/"
model.save(log_dir + "ppo_halfcheetah")
print("saving model at {0}".format(log_dir))
stats_path = os.path.join(log_dir, "vec_normalize.pkl")
env.save(stats_path)
print("saving env at {}".format(stats_path))
# To demonstrate loading
del model, env
# Load the saved statistics
env = DummyVecEnv([lambda: gym.make("HalfCheetahBulletEnv-v0")])
print("loading env and model")
env = VecNormalize.load(stats_path, env)
# do not update them at test time
env.training = False
# reward normalization is not needed at test time
env.norm_reward = False
# Load the agent
model = PPO.load(log_dir + "ppo_halfcheetah", env=env)
2.5 Atari
如果想使用atari环境,还需要装ROMs,为了完整性:
wget http://www.atarimania.com/roms/Roms.rar
unrar e ~/atari_roms
python -m atari_py.import_roms ~/atari_roms
三、总结
- 一共创建了test_cuda.py test_mujoco.py test_stable_baselines3.py test_pybullet.py四个测试文件
- 目前这个容器,可以重新commit一下或加到之前的Dockerfile中,pybullet、mujoco、atari这三个强化环境竟然都能在强化算法库stable-baselines3下以gym的环境接口统一调用了,舒服!
实际上,我们仅仅是在原镜像基础上pip install stable-baselines3[extra] pyglet pybullet,可能再git clone一个RL Baselinses Zoo,呵,继续搬砖了!
- 美中不足的是,没法使用env.render(),要处理一下X-server的问题
- 如果是在docker container所在的linux 服务器上接显示器看的话,那还算简单,参见Docker_Display with X Server
- 如果像我这样:Mac的iTerm ssh到remote linux server,再exec到container,想render到本Mac的界面上,捣鼓过但还没解决; 或者是Vscode ssh到remote linux server上运行代码,有大佬解决了请告诉我一下!
- 折中方案:在docker container中开jupyter notebook,在jupyter notebook上画出来看
下次有时间再仔细写用jupyter notebook的远端开发RL算法的过程
https://github.com/DLR-RM/stable-baselines3 ↩︎
https://github.com/DLR-RM/rl-baselines3-zoo ↩︎
https://github.com/bulletphysics/bullet3 ↩︎