谷粒商城_08_商品首页+nginx+压力测试
文章目录
- 商城系统首页
-
- 页面与静态资源处理
- 渲染一级分类菜单
- 渲染三级分类菜单
- Nginx
-
- nginx配置
- nginx代理
- nginx+网关
- 压力测试
-
- Jmeter
- Jmeter Address Already in use错误解决
- 优化
-
- Nginx动静分离
- 优化三级分类

商城系统首页
页面与静态资源处理
不使用前后端分离开发了,管理后台用vue
静态资源处理
1、nginx发给网关集群,网关再路由到微服务
2、静态资源放到nginx中,后面的很多服务都需要放到nginx中
3、index文件放到gulimall-product下的static文件夹
4、把index.html放到templates中
pom依赖
导入thymeleaf依赖、热部署依赖devtools使页面实时生效,修改之后ctrl+f9:build一下
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
关闭thymeleaf缓存,方便开发实时看到更新
thymeleaf:
cache: false
suffix: .html # 后缀
prefix: classpath:/templates/ # 前缀
web开发放到web包下,原来的controller是前后分离对接手机等访问的,所以可以改成app,对接app应用
启动测试:
- 访问页面:http://localhost:10000
- 访问静态资源:http://localhost:10000/index/css/CL.css
渲染一级分类菜单
刚导入index.html时,里面的分类菜单都是写死的,我们要访问数据库拿到放到model中,然后在页面foreach填入
/**
* @author ljy
* @version 1.0.0
* @Description 首页controller
* @createTime 2021年12月16日 16:43:00
*/
@Controller
public class IndexController {
@Autowired
private CategoryService categoryService;
@GetMapping({"/", "index.html"})
public String getIndex(Model model) {
// 获取所有的一级分类,getLevel1Catagories
List<CategoryEntity> catagories = categoryService.getLevel1Catagories();
// 放给页面取值
model.addAttribute("catagories", catagories);
// 视图解析器进行拼串,classpath:/templates/+返回值+.html
return "index";
}
}
页面遍历菜单数据
<html lang="en" xmlns:th="http://www.thymeleaf.org"> # 导入语法
<li th:each="catagory:${catagories}" >
<a href="#" class="header_main_left_a" ctg-data="3" th:attr="ctg-data=${catagory.catId}"><b th:text="${catagory.name}">xxxb>a>
li>
# th:attr="ctg-data=${catagory.catId}" 替换 ctg-data="3"
# th:text="${catagory.name}" 替换 : xxx
渲染三级分类菜单
- 根据前端请求的接口,进行后端开发
@ResponseBody
@RequestMapping("index/catalog.json")
public Map<String, List<Catelog2Vo>> getCatlogJson() {
Map<String, List<Catelog2Vo>> map = categoryService.getCatelogJson();
return map;
}
@Override
public Map<String, List<Catelog2Vo>> getCatelogJson() {
List<CategoryEntity> entityList = baseMapper.selectList(null);
// 查询所有一级分类
List<CategoryEntity> level1 = getCategoryEntities(entityList, 0L);
Map<String, List<Catelog2Vo>> parent_cid = level1.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
// 拿到每一个一级分类 然后查询他们的二级分类
List<CategoryEntity> entities = getCategoryEntities(entityList, v.getCatId());
List<Catelog2Vo> catelog2Vos = null;
if (entities != null) {
catelog2Vos = entities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), l2.getName(), l2.getCatId().toString(), null);
// 找当前二级分类的三级分类
List<CategoryEntity> level3 = getCategoryEntities(entityList, l2.getCatId());
// 三级分类有数据的情况下
if (level3 != null) {
List<Catalog3Vo> catalog3Vos = level3.stream().map(l3 -> new Catalog3Vo(l3.getCatId().toString(), l3.getName(), l2.getCatId().toString())).collect(Collectors.toList());
catelog2Vo.setCatalog3List(catalog3Vos);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
return parent_cid;
}
Nginx
nginx配置
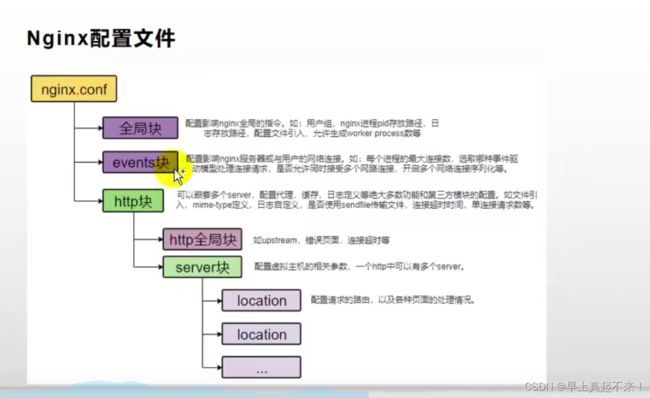
nginx.conf:
-
全局块:配置影响nginx全局的指令。如:用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process故障等
-
events块:配置影响 Nginx 服务器与用户的网络连接,常用的设置包括是否开启对多 work process下的网络连接进行序列化,是否允许同时接收多个网络连接,选取哪种事件驱动模型来处理连接请求,每个 word process 可以同时支持的最大连接数等。
-
http块:
- http全局块:配置的指令包括文件引入、MIME-TYPE 定义、日志自定义、连接超时时间、单链接请求数上限等。错误页面等
- server块:这块和虚拟主机有密切关系,虚拟主机从用户角度看,和一台独立的硬件主机是完全一样的。每个 http 块可以包括多个 server 块,而每个 server 块就相当于一个虚拟主机。
- location1:配置请求的路由,以及各种页面的处理情况
- location2
-
nginx.conf:在这里最重要的是这个再转给网关的配置
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
include /etc/nginx/conf.d/*.conf; # 包含了哪些配置文件
}
-
conf.d/gulimall.conf
-
监听来自gulimall:80的请求,
- 对于以/static开头的请求,就是找 /usr/share/nginx/html这个相对路径。
- 为什么找那个?因为我们映射了docker外面的/mydata/data/nginx/html某一列到这个目录,所以在docker中就是去这找静态资源
- 其他的请求,转发到http://gulimall 这个upstream ,并且由于nginx的转发会丢失
host头(host头是HTTP1.1开始新增的请求头),造成网关不知道原host,所以我们添加头信息
- 对于以/static开头的请求,就是找 /usr/share/nginx/html这个相对路径。
server {
listen 80;
server_name gulimall.com *.gulimall.com;
location /static {
root /usr/share/nginx/html;
}
#charset koi8-r;
#access_log /var/log/nginx/log/host.access.log main;
location / {
proxy_pass http://gulimall;
proxy_set_header Host $host; #
}
upstream gulimall{
# 88是网关
server 192.168.56.1:88;
}
include /etc/nginx/conf.d/*.conf; # 包含了哪些配置文件
}
nginx代理
1、访问域名找到转到服务器ip
2、服务器默认80端口,就是nginx代理,帮我们代理到我们需要的后端服务
- 修改主机hosts,映射
gulimall.com到服务器的ipxxxxx,本机浏览器请求gulimall.com,通过配置hosts文件之后,那么当你在浏览器中输入gulimall.com的时候,相当于域名解析DNS服务解析得到我们的服务器 :ip xxxxxx - 在nginx的配置文件中映射gulimall.com,当访问gulimall.com先去找服务器的ip地址,默认端口是80,所以会走到我们的nginx。
- 请求到了nginx之后,在nginx的配置文件中定义我们需要转交的服务即可,其中的192.168.56.1 就是本机ip,也就是通过192.168.56.1:10000就可以直接访问服务,也就是127.0.0.1:10000

最主要的还是server块,负载均衡的配置,用来配置我们的服务信息
nginx+网关
访问域名转到服务器ip,被nginx监听,通过nginx转到网关(注意会丢失host信息),网关在根据配置转到相应的后端服务
1、修改主机hosts,映射gulimall.com到ipxxxxx。关闭防火墙
2、修改nginx/conf/nginx.conf,将upstream映射到我们的网关服务,http块里面,自己配置上由服务器组:gulimall
upstream gulimall{
# 88是网关,192.168.56.1:88也就是本机网关地址
server 192.168.56.1:88;
# ......
}
- server块的location就直接转交给我们的网关,我们的上由服务组:gulimall
3、修改nginx/conf/conf.d/gulimall.conf,接收到gulimall.com的访问后,如果是/,转交给指定的upstream
location / {
proxy_pass http://gulimall; # 转交给谁
}
4、配置gateway为服务器,将域名为**.gulimall.com转发至商品服务。配置的时候注意 网关优先匹配的原则,所以要把这个配置放到后面
- id: gulimall_host_route
uri: lb://gulimall-product
predicates:
- Host=**.gulimall.com # gulimall下的子域名的请求都交给我们的gulimall-product服务
我们的网关拿不到gulimall.com的域名请求,因为nginx代理的,nginx代理给网关的时候会丢掉请求中的host信息(也就是gulimall.com),所以我们要配置nginx,由于nginx的转发会丢失
host头,造成网关不知道原host,所以我们添加头信息
location / {
proxy_pass http://gulimall; # 转交给谁
proxy_set_header Host $host; # 将host设置到请求头里
}
-
测试即可
-
http://gulimall.com/api/product/attrgroup/list/1
-
http://localhost:88/api/product/attrgroup/list/1
-
请求结果相同
压力测试
Jmeter
下载:https://jmeter.apache.org/download_jmeter.cgi
1、创建测试计划,添加线程组
- 1、线程属性,例如2w个请求
- 2、线程数==用户:200个
- 3、ramp-up :多长时间内发送完:1s
- 4、循环次数:每个线程执行多少次:100
2、发送请求 - 1、给线程组添加-取样器-HTTP请求
3、查看结果 - 1、给线程组添加-监听器-查看结果树
- 2、给线程组添加-监听器-汇总报告
4、除此还有聚合报告,汇总图等等
Jmeter Address Already in use错误解决
报错原因
1、windows系统为了保护本机,限制了其他机器到本机的连接数.
2、TCP/IP 可释放已关闭连接并重用其资源前,必须经过的时间。关闭和释放之间的此时间间隔通称 TIME_WAIT 状态或两倍最大段生命周期(2MSL)状态。此时间期间,重新打开到客户机和服务器的连接的成本少于建立新连接。减少此条目的值允许 TCP/IP 更快地释放已关闭的连接,为新连接提供更多资源。如果运行的应用程序需要快速释放和创建新连接,而且由于 TIME_WAIT 中存在很多连接,导致低吞吐量,则调整此参数。
修改操作系统注册表
1、打开注册表:运行-regedit
2、直接输入找到HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TCPIP\Parameters
3、右击Parameters新建 DWORD32值,name:TcpTimedWaitDelay,value:30(十进制) ——> 设置为30秒回收(默认240)
4、新建 DWORD值,name:MaxUserPort,value:65534(十进制) ——> 设置最大连接数65534
注意:修改时先选择十进制,再填写数字。
5、重启系统
优化
- 中间件越多,性能损失越大,大多都损失在网络交互了
- 全链路(Nginx+GateWay+简单服务)

- 打开thymeleaf缓存,数据库优化:加索引等,关闭日志
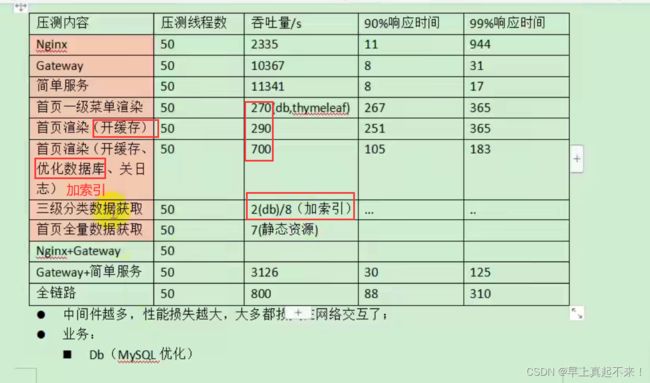
- product微服务的 -Xmx1024m -Xms1024m -Xmn512m。增加服务jvm占用内存:VM options:-Xmx512m
结论
- SQL耗时越小越好(数据库优化:给查询条件的字段加索引),一般情况下微秒级别
- 命中率越高越好,一般情况下不能低于95%
- 锁等待次数越低越好,等待时间越短越好
- 中间件越多,性能损失越大,大多都损失在网络交互了。Nginx(浪费CPU)、Gateway(浪费CPU)
Nginx动静分离
由于动态资源和静态资源目前都处于服务端,所以为了减轻服务器压力,我们将js、css、img等静态资源放置在Nginx端,以减轻服务器压力
-
静态文件上传到 mydata/nginx/html/static/index/img、js、css,这种格式
-
修改index.html的静态资源路径,加上static前缀
src="/static/index/img/img_09.png" -
修改
/mydata/nginx/conf/conf.d/gulimall.conflocation /static { root /usr/share/nginx/html; # 如果遇到有`/static`为前缀的请求,转发至html文件夹 } location / { proxy_pass http://gulimall; proxy_set_header Host $host; }
优化三级分类
优化前
对二级菜单的每次遍历都需要查询数据库,浪费大量资源
优化后
仅查询一次数据库,剩下的数据通过遍历得到并封装
//优化业务逻辑,仅查询一次数据库
List<CategoryEntity> categoryEntities = this.list();
//查出所有一级分类
List<CategoryEntity> level1Categories = getCategoryByParentCid(categoryEntities, 0L);
Map<String, List<Catalog2Vo>> listMap = level1Categories.stream().collect(Collectors.toMap(k->k.getCatId().toString(), v -> {
//遍历查找出二级分类
List<CategoryEntity> level2Categories = getCategoryByParentCid(categoryEntities, v.getCatId());
List<Catalog2Vo> catalog2Vos=null;
if (level2Categories!=null){
//封装二级分类到vo并且查出其中的三级分类
catalog2Vos = level2Categories.stream().map(cat -> {
//遍历查出三级分类并封装
List<CategoryEntity> level3Catagories = getCategoryByParentCid(categoryEntities, cat.getCatId());
List<Catalog2Vo.Catalog3Vo> catalog3Vos = null;
if (level3Catagories != null) {
catalog3Vos = level3Catagories.stream()
.map(level3 -> new Catalog2Vo.Catalog3Vo(level3.getParentCid().toString(), level3.getCatId().toString(), level3.getName()))
.collect(Collectors.toList());
}
Catalog2Vo catalog2Vo = new Catalog2Vo(v.getCatId().toString(), cat.getCatId().toString(), cat.getName(), catalog3Vos);
return catalog2Vo;
}).collect(Collectors.toList());
}
return catalog2Vos;
}));
return listMap;