online-DDL详细原理介绍及gh-ost讲解
文章目录
-
- 1. MySQL online DDL 各版本介绍
-
- 1.1 online DDL in mysql 5.5
- 1.2 online DDL in mysql5.6
- 1.3 online DDL in mysql5.7
- MDL-Metadata Lock
- 1.4 pt-online-schema-change
- 2. GH-OST工具
-
- 2.1 GH-OST原理分析:
- 2.2 GH-OST工作流程
- 2.3 GH-OST的三种工作模式
- 2.4 GH-OST使用限制:
- 2.5 GH-OST安装测试
- 2.6 各个工具的总结对比
- 2.7 sysbench压测online DDL,PT-OSC,gh-ost
1. MySQL online DDL 各版本介绍
1.1 online DDL in mysql 5.5
在mysql5.5版本中已经增加了in-place方式,但依然会阻塞insert,update,delete操作。
mysql 5.5 online ddl 原理:
a. 按照原表的定义创建临时表;
b. 对原表进行加写锁;
c. 对新的临时表进行ddl操作;
d. 将原表中的数据copy到临时表中;
e. 释放原表的写锁;
f. 将旧表删除,临时表重命名
存在的问题:
a. 在进行copy data的过程中消耗的时间长,和消耗大量的存储空间;
b. 在原表进行加锁时,业务会中断访问。
1.2 online DDL in mysql5.6
在mysql5.6版本中,引入了新特性,Fast Index Create(FIC特性),支持更多的alter table语句来避免copy data同时支持了在线上DDL的过程中不阻塞DML操作。

mysql5.6参数设置:
innodb_online_alter_log_max_size参数,默认为128M,但是在生产场景中512M会适合。在进行在线索引添加操作时,数据库性能有20-30%的下降
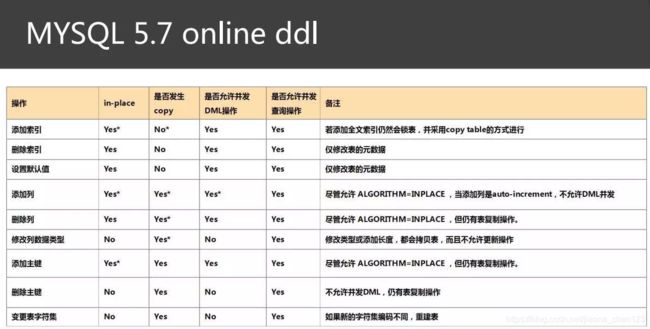
1.3 online DDL in mysql5.7
mysql5.7支持的新特性:
a. 增加了alter table rename index 的语法支持,同时也继续支撑online DDL特性;
b. 修改varchar列长度操作支持online特性。
alter table t1 algorithm=INPLACE, change column c1 c1 varchar(255);
ALTER TABLE t1 ADD COLUMN new_column ALGORITHM=INPLACE,LOCK=DEFAULT;
algorithm子句用来指定执行DDL采用的方式,可取值为DEFAULT,INPLACE,COPY
LOCK子句描述特有的锁类型人控制DML的并发,取值DEFAULT,NONE,SHARED,EXCLUSIVE
mysql5.7 online DDL的原理:
PREPARE:
a. 创建新的临时.frm 文件;
b. 持有排他-MDL锁,禁止读写;
c. 根据alter 类型确定执行方式;
d. 更新数据字典的内存对象;
e. 分配row_log对象用来记录增量;
f. 生成新的临时ibd文件;
DDL:
g. 降级排他锁为S锁;
h. 扫描old_table的聚簇索引每一条记录reo,并遍历新表的索引进行处理;
i. 根据reo构造对应的索引项对应的索引项,将构造索引项插入soft_buffer块排序;
j. 将sort_buffer块更新到新的索引上;
k. 记录ddl执行过程中产生的增量并在新表上重放;
l. 记录ddl执行过程中产生的增量(仅rebuild类型需要);
m. 重放row_log间产生dml操作append到row_log最后一个block;
COMMIT;
n. 当前block为row_log最后一个时,禁止读写,升级到排他-MDL锁;
o.重做row_log中最后一部分增量;
p.更新innodb的数据字典表;
q. 提交事务(刷事务的redo日志)
r. 修改统计信息;
s. rename临时ibd文件,.frm文件
online DDL使用限制与问题:
a. 仍然存在排他锁,有锁等待的风险;
b. 跟5.6一样,增量日志大小是有限制的;
c. 有可能造成主从延迟;
d. 无法暂停,只能中断。
MDL-Metadata Lock
**MDL概念:**MDL的引入会导致一定的性能的损耗,对同一个database objects访问越多,就会导致该对象的MDL的争用;
为了维护表元数据的一致性,在表中有显示或隐式的活动事务时,不可以对元数据进行写入操作,mysql 引入了metadata lock,来保护元数据信息。因此在对表进行上述操作时,如果表上有活动事务,请求写入的会话,会等待在metadata lock wait ;
造成mdl锁的场景:
a. 当session1开启事务,没有提交对t表的查询,同时session2对t表进行alter修改,则会造成MDL锁;
b. 当session1开启事务没有提交对t表的查询,同时session2对t表进行drop 操作,则会造成MDL锁;
哪些操作会获得MDL锁:
a. 表结构的更改;
b. 创建,删除索引;
c. 删除表;
d. 对表加写锁,进行读操作。对表加读锁,进行写操作;
MDL劣势:
MDL锁是表锁,无论是读或者写操作都无法进行,导致SQL阻塞;
如果监控不到位,在高并发场景中,会造成大量的SQL阻塞。除非人工DDL结束;
MDL优势:
MDL的主要目的是为了保护元数据,假如,没有MDL锁,会导致读入的数据不一致,写入的时候发生元数据冲突。同时MDL也是可以避免的,例如可以在业务低峰期使用pt-osc进行操作或者gh-ost,做好报警工作,对于未提交的事务要尽快提交,或者kill到没有commit的事务。
MDL常见的四种锁对象:
与innodb层类似的是,某些类型的MDL 锁会从上入下一层层加锁。例如,lock table … write这样的SQL,会对GLOBAL级别加INTENTION_EXCLUSIVE锁,再对SCHEMA加INTENTION_EXCLUSIVE锁,最后给TABLE加SHARED_NO_READ_WRITE锁。COMMIT对象层次的锁最主要应用于XA事务中,当分页式事务已经prepare成功,但是在xa commit之前有其他会话执行了FLUSH TABLES READ LOCK这样的操作,那么分页式事务的提交就需要等待;
| 锁模式 | 对应的SQL |
|---|---|
| MDL_INTENTION_EXCLUSIVE | GLOBAL,SCHEMA对象操作会加锁 |
| MDL_SHARED | FLUSH TABLES WITH READ LOCK |
| MDL_SHARED_HIGH_PRIO | 仅对MYISAM存储引擎有效 |
| MDL_SHARED_READ | SELECT语句(相当于Innodb共享锁) |
| MDL_SHARED_WRITE | DML语句(相当于Innodb排他锁) |
| MDL_SHARED_WRITE_LOW_PRIO | 对myisam存储引擎有效 |
| MDL_SHARED_UPGRADABLE | ALTER TABLE |
| MDL_SHARED_READ_ONLY | LOCK TABLE T READ ; |
| MDL_SHARED_NO_WRITE | FLUSH TABLES xxx,yyy,zz READ |
| MDL_SHARED_NO_READ_WRITE | FLUSH TABLE XX WRITE |
| MDL_EXCLUSIVE | ALTER TABLE XXX PARTITION BY 。。 |
监控MDL锁:
mysql 5.5:
select * from information_schema.processlist where state = 'Waiting for table metadata lock';
mysql 5.6:
select * from performance_schema.metadata_locks;
需要开启performance_schema:
root@mysqldb 10:03: [performance_schema]> update performance_schema.setup_instruments set ENABLED = 'YES',TIMED='YES' where name = 'wait/lock/metadata/sql/mdl';
root@mysqldb 10:02: [performance_schema]> update performance_schema.setup_consumers set ENABLED = 'YES' where name in ('global_instrumentation');
mysql5.7:
select * from sys.schema_table_lock_waits;
故障模拟:
session1:
mysql> lock table test read;
Query OK, 0 rows affected (0.01 sec)
session2:
mysql> insert into test values (5,'fd');
查看锁状态:
mysql> select * from sys.schema_table_lock_waits\G
*************************** 1. row ***************************
object_schema: test_db
object_name: test
waiting_thread_id: 35
waiting_pid: 10
waiting_account: root@localhost
waiting_lock_type: SHARED_WRITE
waiting_lock_duration: TRANSACTION
waiting_query: insert into test values (5,'fd')
waiting_query_secs: 23
waiting_query_rows_affected: 0
waiting_query_rows_examined: 0
blocking_thread_id: 34
blocking_pid: 9
blocking_account: root@localhost
blocking_lock_type: SHARED_READ_ONLY
blocking_lock_duration: TRANSACTION
sql_kill_blocking_query: KILL QUERY 9
sql_kill_blocking_connection: KILL 9
1 row in set (0.00 sec)
简单解释原因,由于MDL锁是表级锁是SERVER层的锁,主要用于隔离DML和DDL操作之间的干扰。每执行一条DML,DDL语句时都会申请MDL锁,DML操作需要MDL读锁,DDL操作需要MDL写锁(MDL加锁是系统自动控制的,无法直接干涉,读读共享,读写互斥,写写互斥)。申请MDL锁的操作会形成一个队列,队列中的写锁获取优先级高于读锁,如果出现写锁,不但当前的操作会被阻塞,同时还会阻塞后续该表的所有操作。事务一旦申请到MDL锁后,直到事务执行完才会将锁释放。(这里有特殊情况如果事务中包含DDL操作,mysql会在DDL操作语句执行后,隐式提交COMMIT,以保证该DDL语句操作作为一个单独的事务而存在,同时也保证元数据排遣他锁的释放,例如:
总结元数据锁信息:
a. shared_upgradable:(alter table语句)本身为读锁,但是有特殊,优先级为0;
-
并不受队列中的写锁等待而阻塞,只和当前持锁的session比对,当前持锁session为排他锁X,则等待,反之则获得锁;
-
为了保证一张表同时只有一个DDL操作进行,shared_upgradable之间是互斥的,一个时间只能有一个share_upgradable的状态是granted ,其余被阻塞;
b. eclusive,shared_no_read_write级别相同,先进先出;
c. shared_write(DML)和shared_read(SELECT)兼容,但shared_write优先级高于shared_read_only(LOCK TABLE T READ)且不兼容;
d. shared_read_only优先级最低,主要是因为被shared_write互斥,但如果只有shared_read则他们的优先级是兼容的。
处理MDL锁造成的阻塞:
a. 处理掉长事务;
session1的事务没有执行完毕,则kill session2可以通过下面的SQL进行洞察,可以自行评估;
root@mysqldb 10:17: [information_schema]> select * from information_schema.INNODB_TRX\G
可以自行kill session1;
b. 直接kil ddl语句
则kill session1 选择业务低峰期执行,如果DDL执行到80%-90%,则kill 其 他会话,视实际情况而定;
1.4 pt-online-schema-change
percona-toolkit源自maatkit和Aspersa工具,用来管理mysql和系统任务,主要包括:
a. 验证主节点和复制数据的一致性,pt-table-checksum,pt-table,sync
b. 有效的对记录行进行归档 【pt-archiver】
c. 分析索引使用情况 【pt-index-usage】
d. 总结 MySQL 服务器 【pt-summary】
e. 从日志和 tcpdump 中分析查询 【pt-query-digest】
f. 问题发生时收集重要的系统信息 【pt-stalk】
g. kill 符合条件的 mysql thread 【pt-kill】
h. 在线修改表结构 【pt-online-schema-change】
优势:支持并发DML操作,稳定性强;
pt-osc原理:
a. 创建一张新表,并与原表的结构相同;
b. 对新表进行alter操作;
c. 在原表上创建insert ,update,delete 三种类型的触发器;
d. 将旧表数据copy到新表中,同时通过触发器将旧表的操作映射到新表中;
e. 如果原表有外键约束,处理外键;
f. 原表重命名为old表,new表重命名为原表,整个过程为原子操作;
g. 删除old表
PT-OSC 使用限制:
1.原表不能存在触发器。
2.原表必须存在主键 PRIMARY KEY 或者 UNIQUE KEY
3.外键的处理需要指定 alter-foreign-keys-method 参数,存在风险
4.在 pt-osc 的执行过程中,如果有对主键的更新操作则会出现重复的数据,见下面链接的 bug 说明:
https://bugs.launchpad.net/percona-toolkit/+bug/1646713
PT-OSC 存在的风险
-
触发器是以解释型代码保存的,因此每次查询都需要对触发器的代码进行解释的开销。
-
触发器与原始查询共享相同的事务空间,原始查询在表上有锁竞争,触发器也会在另一张表上有锁竞争。同时,在触发器删除时同样会有元数据锁。
-
触发器无法暂停,当主库 LOAD 变高,希望停止变更时,但触发器是不会停止。因此在整个操作过程中,触发器都会存在直到执行结束。
2. GH-OST工具
GH-OST(gitHub’s online schema transformer):github的在线表定义转换器;
GH-OST优势:
a. 无触发器设计;
b. 切换方案的设计;
c. 最大限度的减少了对主机的影响;
d. 实现了增量数据的获取;基本做到了原子性的切换;
2.1 GH-OST原理分析:
a. 第一步先测试数据库是否可以连通,并且验证database是否存在;
b. 确认连接的实例是否正确;
c. 权限验证 show /* gh-ost */ grants for current_user();
d. binlog验证,包括row格式验证和修改binlog格式后的重启replicate;
e. 原表存储引擎,外键,触发器检查,行数评估等;
f. 初始化stream的连接,添加binlog的监听;
g. 初始化applier连接,创建ghosttable和change logtable;
h. 并发的执行row copy和binlog copy;
i. cut over;
j. 结束
2.2 GH-OST工作流程
a. 创建一个和临时表相似的GHOST表;缓慢将数据从原始表中复制到ghost表,同时不断的传输增量到ghost表;
b. 最后,再用ghost表替换原来的表;
c. ghost使用相同的模式,不同于现在的工具,不使用触发器;
d. gh-ost使用binlog流捕获表更改uses the binary log stream ,并异步地将它们应用到ghost表。ghost对迁移过程有更大的控制,可以真正的暂停,可以真正地将迁移的写负载与主工作负载分离
e. 此外,还提供了许多操作上的好处operational perks;
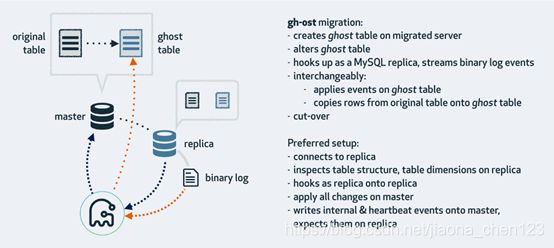
工作详细流程:
a. 首先,gh-ost连接到主库,根据alter 语句在gh-ost上创建临时表t —> t.bak;
b. gh-ost做为一个“备库”连接到真正的备库上,一连从主库copy已有的数据到gh-ost的t.bak表,一边从真正的备库上拉取增量的binlog,(此时,gh-ost上存储所有的数据和将t表的变更成功之后的数据)然后再把binlog应用给主库;
c. 上图中是cut-over是最后一步,锁住主库的源表,等待binlog应用完毕,替换gh-ost表的t.bak为源表;
d. 在gh-ost执行中,会在原本的binlog event 里面增加以下hint 和心跳包,用来控制整个流程的进度,检测状态等。这样的好处为:
1. 整个流程异步执行:对于源表的增量数据操作没有额外的开销,高峰期变更业务对性能影响小;
1. 降低写压力,触发器操作都在一个事务内,gh-ost应用binlog是另外一个连接在做;
1. 可停止,binlog有位置点记录,如果变更过程中发现主库性能有所影响,可以立刻停止拉binlog,停止应用binlog,稳定之后再继续应用;
1. 可测试,gh-ost提供了测试功能,可以连接到一个库上直接做online ddl,在备库上观察变更结果是否正确,再对主库操作。
2.3 GH-OST的三种工作模式
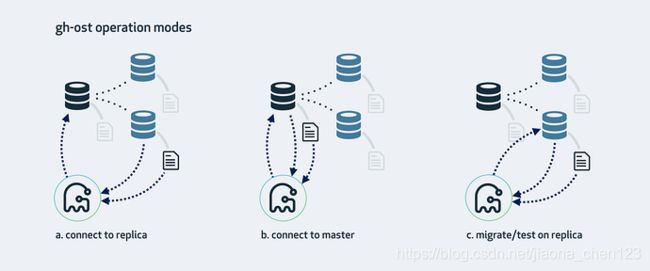
模式一:连上从库,在主库上修改(默认)
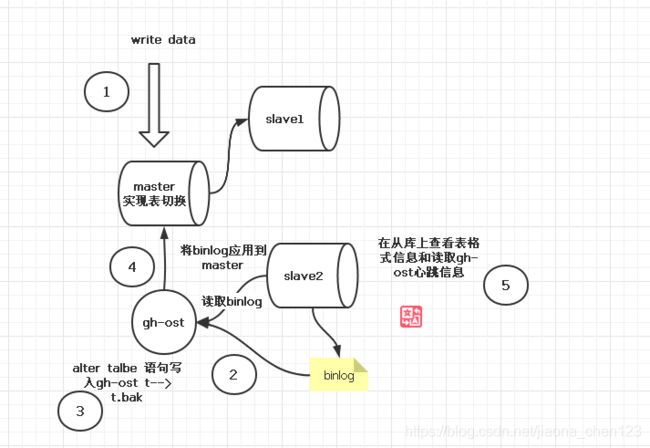
具体操作步骤:
a. 先在主库上读写行数据;
b. gh-ost将在从节点拉取binlog信息以及增量的binlog返回到ghost并将binlog信息应用给主库;
c. 在从库上查看表格式和主键,总行数信息;
d. 在从库上读取gh-ostt内部事件日志;
e. 在主库上完成表切换;
如果主库的二进制日志格式是statement,就可以使用这种模式,但从库就必须配成启用二进制日志(log_bin,log_slave_updates)还要设成row格式(binlog_format=ROW),实际上gh-ost会在从库上做这些设置。简而言之,即使把从库改成ROW格式,这仍然是对主为侵入最少的工作模式;
模式二:在主库上做修改
工作流程:
通过master节点写入数据,gh-ost拉取master节点的binlog日志及增量数据,在gh-ost进行alter操作之后,将binlog继续返回给master,并进行重命名操作。
所注意的点:
a. 主库必须产生ROW格式的二进制日志;
b. 启动gh-ost时必须用–allow-on-master选项来开启这种模式;
模式三:在从库上修改和测试
这个模式会在从库上做修改,但gh-ost仍然会连上主库,所有的操作都会在从库上做,对主库不会有影响。在操作过程中,gh-ost也会不时的暂停,以便从库的数据可以保持最新;
–migrate-on-replica:gh-ost直接在从库修改表结构,最终的切换过程也是在从库正常复制的状态下完成的;
–test-on-replica:测试为目的,在进行最终的切换操作前,复制就会被停止。原始表和测试表相互切换,再切回来。主从复制暂停的状态下,可以检查这两张表的数据。
cut over阶段:
即rename表阶段
a. 对应用请求的影响:所有请求在cut-over阶段直到临时表消失前会被阻塞,被释放后所有的请求都会在新表上执行,若cut-over阶段失败,则所有的请求一定会在旧表上执行;
b. 对主从复制的影响:备机只能看到rename操作,锁的event不会写入binlog,因此备机看到的是一个原子性的操作。
2.4 GH-OST使用限制:
a. 不能对外键关系及触发器的表进行online DDL ;
b. 要求所连接的获取增量数据的mysql binlog为row格式;
c. 若有同名但是字母大小写不同的表则无法进行修改;
d. 不支持mysql5.7json类型列的修改;
e. 不支持mysql 5.7generated coolumn 的修改。
2.5 GH-OST安装测试
准备环境:
| 主机名 | IP | |
|---|---|---|
| db01 | 192.168.214.1 | 主库 |
| db02 | 192.168.214.129 | 从库 |
a. 安装gh-ost软件:
# yum install gh-ost-1.0.49-1.x86_64.rpm
b. 配置主从:略
并开启log_slave_updates,binlog_format=row
c. 在主从上DDL
此时的操作大概是:
-
行数据在主库上读写
-
读取从库的二进制日志,将变更应用到主库
-
在从库收集表格式,字段&索引,行数等信息
-
在从库上读取内部的变更事件(如心跳事件)
-
在主库切换表
[root@db02 opt]# gh-ost --user="root" --password="" --host=192.168.214.129 --port=3380 --database="test" --table="t" --initially-drop-old-table --alter="ADD COLUMN y1 varchar(10),add column y2 int not null default 0 comment 'test' " --execute
[2020/06/17 17:15:00] [info] binlogsyncer.go:133 create BinlogSyncer with config {99999 mysql 192.168.214.129 3380 root false false <nil> false UTC true 0 0s 0s 0 false}
[2020/06/17 17:15:00] [info] binlogsyncer.go:354 begin to sync binlog from position (binlog.000007, 1016)
[2020/06/17 17:15:00] [info] binlogsyncer.go:203 register slave for master server 192.168.214.129:3380
[2020/06/17 17:15:00] [info] binlogsyncer.go:723 rotate to (binlog.000007, 1016)
# Migrating `test`.`t`; Ghost table is `test`.`_t_gho`
# Migrating db01:3380; inspecting db02:3380; executing on db02
# Migration started at Wed Jun 17 17:15:00 +0800 2020
# chunk-size: 1000; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: ; critical-load: ; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.t.sock
# Migrating `test`.`t`; Ghost table is `test`.`_t_gho`
# Migrating db01:3380; inspecting db02:3380; executing on db02
# Migration started at Wed Jun 17 17:15:00 +0800 2020
# chunk-size: 1000; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: ; critical-load: ; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.t.sock
Copy: 0/1 0.0%; Applied: 0; Backlog: 0/1000; Time: 0s(total), 0s(copy); streamer: binlog.000007:3378; Lag: 0.02s, State: migrating; ETA: N/A
Copy: 0/0 100.0%; Applied: 0; Backlog: 0/1000; Time: 0s(total), 0s(copy); streamer: binlog.000007:3378; Lag: 0.02s, State: migrating; ETA: due
# Migrating `test`.`t`; Ghost table is `test`.`_t_gho`
# Migrating db01:3380; inspecting db02:3380; executing on db02
# Migration started at Wed Jun 17 17:15:00 +0800 2020
# chunk-size: 1000; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: ; critical-load: ; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.t.sock
Copy: 0/0 100.0%; Applied: 0; Backlog: 0/1000; Time: 1s(total), 0s(copy); streamer: binlog.000007:9351; Lag: 0.02s, State: migrating; ETA: due
Copy: 0/0 100.0%; Applied: 0; Backlog: 0/1000; Time: 1s(total), 0s(copy); streamer: binlog.000007:9351; Lag: 0.02s, State: migrating; ETA: due
[2020/06/17 17:15:02] [info] binlogsyncer.go:164 syncer is closing...
[2020/06/17 17:15:02] [error] binlogstreamer.go:77 close sync with err: sync is been closing...
[2020/06/17 17:15:02] [info] binlogsyncer.go:179 syncer is closed
# Done
进度提示:
Copy: 0/1 0.0%; Applied: 0; Backlog: 0/1000; Time: 0s(total), 0s(copy); streamer: binlog.000007:3378; Lag: 0.02s, State: migrating; ETA: N/A
Copy: 0/1 0.0%; 1 是指要迁移的总行数,0是已经迁移的行数 0.0%迁移完成的百分比;
Applied: 0:是指在二进制日志中处理的event数量,0的意思是迁移表没有流量,没有处理的event
Backlog: 0/1000:表示我们在读取二进制日志方面表现良好,在二进制日志队列中没有任何积压(Backlog)事件。
treamer: binlog.000007:3378;表示当前已经应用到binlog文件位置
在执行DDL中,从库会执行一次stop/start slave,要是确定从的binlog是ROW的话可以添加参数:–assume-rbr。如果从库的binlog不是row,可以用参数–switch-to-rbr来转换成ROW,此时需要注意的是执行完毕之后,binlog模式不会被转换成原来的值。–assume-rbr和–switch-to-rbr参数不能一起使用。
在主库上执行DDL:
# gh-ost --user="root" --password="" --host=192.168.214.1 --database="test" --table="t" --alter="ADD COLUMN cc2 varchar(10),add column cc3 int not null default 0 comment 'test' " --allow-on-master --execute[root@db01 data]# gh-ost --user="root" --password="" --host=192.168.214.1 --port=3380 --database="test" --table="tt" --alter="ADD COLUMN cc2 varchar(10),add column cc3 int not null default 0 comment 'test' " --allow-on-master --execute
[2020/06/17 17:53:54] [info] binlogsyncer.go:133 create BinlogSyncer with config {99999 mysql 192.168.214.1 3380 root false false <nil> false UTC true 0 0s 0s 0 false}
[2020/06/17 17:53:54] [info] binlogsyncer.go:354 begin to sync binlog from position (binlog.000001, 11485)
[2020/06/17 17:53:54] [info] binlogsyncer.go:203 register slave for master server 192.168.214.1:3380
[2020/06/17 17:53:54] [info] binlogsyncer.go:723 rotate to (binlog.000001, 11485)
# Migrating `test`.`tt`; Ghost table is `test`.`_tt_gho`
# Migrating `test`.`tt`; Ghost table is `test`.`_tt_gho`
# Migrating db01:3380; inspecting db01:3380; executing on db01
# Migrating db01:3380; inspecting db01:3380; executing on db01
# Migration started at Wed Jun 17 17:53:54 +0800 2020
# Migration started at Wed Jun 17 17:53:54 +0800 2020
# chunk-size: 1000; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: ; critical-load: ; nice-ratio: 0.000000
# chunk-size: 1000; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: ; critical-load: ; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.tt.sock
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.tt.sock
Copy: 0/1 0.0%; Applied: 0; Backlog: 0/1000; Time: 0s(total), 0s(copy); streamer: binlog.000001:13640; Lag: 0.02s, State: migrating; ETA: N/A
Copy: 0/0 100.0%; Applied: 0; Backlog: 0/1000; Time: 0s(total), 0s(copy); streamer: binlog.000001:13640; Lag: 0.02s, State: migrating; ETA: due
# Migrating `test`.`tt`; Ghost table is `test`.`_tt_gho`
# Migrating db01:3380; inspecting db01:3380; executing on db01
# Migration started at Wed Jun 17 17:53:54 +0800 2020
# chunk-size: 1000; max-lag-millis: 1500ms; dml-batch-size: 10; max-load: ; critical-load: ; nice-ratio: 0.000000
# throttle-additional-flag-file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.tt.sock
Copy: 0/0 100.0%; Applied: 0; Backlog: 0/1000; Time: 1s(total), 0s(copy); streamer: binlog.000001:19701; Lag: 0.01s, State: migrating; ETA: due
Copy: 0/0 100.0%; Applied: 0; Backlog: 0/1000; Time: 1s(total), 0s(copy); streamer: binlog.000001:19701; Lag: 0.01s, State: migrating; ETA: due
[2020/06/17 17:53:55] [info] binlogsyncer.go:164 syncer is closing...
[2020/06/17 17:53:55] [error] binlogstreamer.go:77 close sync with err: sync is been closing...
[2020/06/17 17:53:55] [info] binlogsyncer.go:179 syncer is closed
# Done
在DDL上进行测试:
[root@db02 opt]# gh-ost --user="root" --password="" --host=192.168.214.129 --database="test" --table="t" --port=3380 --alter="ADD COLUMN abc1 varchar(10),add column abc2 int not null default 0 comment 'test' " --test-on-replica --switch-to-rbr --execute
## 参数--test-on-replica:在从库上测试gh-ost,包括在从库上数据迁移(migration),数据迁移完成后stop slave,原表和ghost表立刻交换而后立刻交换回来。继续保持stop slave,使你可以对比两张表。如果不想stop slave,则可以再添加参数:--test-on-replica-skip-replica-stop
上面三种是gh-ost操作模式,上面的操作中,到最后不会清理临时表,需要手动清理,再下次执行之前果然临时表还存在,则会执行失败,可以通过参数进行删除:
--initially-drop-ghost-table:gh-ost操作之前,检查并删除已经存在的ghost表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。
--initially-drop-old-table:gh-ost操作之前,检查并删除已经存在的旧表。该参数不建议使用,请手动处理原来存在的ghost表。默认不启用该参数,gh-ost直接退出操作。
--initially-drop-socket-file:gh-ost强制删除已经存在的socket文件。该参数不建议使用,可能会删除一个正在运行的gh-ost程序,导致DDL失败。
--ok-to-drop-table:gh-ost操作结束后,删除旧表,默认状态是不删除旧表,会存在_tablename_del表。
参数详解:
--user: mysql用户
--password: mysql密码
--host: 数据库地址
--database: 要操作的数据库
--table: 数据表
--alter:DDL语句
--allow-on-master:允许gh-ost直接运行在主库上,默认gh-ost连接的从库。
--execute:实际执行alter&migrate表,默认为noop,不执行,仅仅做测试并退出,如果想要ALTER TABLE语句真正落实到数据库中去,需要明确指定-execute
--max-load string:string是状态表达式,当设置多个状态值,用逗号分隔,如“threads_running=100,threads_connected=500”,当超过该值,迁移暂停等待;
--chunk-size:在每次迭代中处理的行数量,范围为(100-100000),默认是1000
--serve-socket-file:gh-ost的socket文件绝对路径;
-exact-rowcount:准确统计表行数(用select count(*)方式)得到更准确的时间;
--test-on-replica:在从库上测试gh-ost,包括在从库上数据迁移(migration),数据迁移完成后stop slave,原表和ghost表立刻交换而后立刻交换回来。继续保持stop slave,使你可以对比两张表。
--max-lag-millis:主从复制最大延迟时间,当主从复制延迟时间超过该值后,gh-ost将采取节流措施,默认值是1500s
--ok-to-drop-table:gh-ost操作结束后,删除旧表,默认状态是不删除旧表,会存在_tablename_del表
--postpone-cut-over-flag-file string:当这个文件存在的时候,gh-ost的cut-over阶段将会被推迟,数据仍然在复制,直到该文件被删除。
终止,暂停,恢复文件:
gh-ost --user="root" --password="" --host=192.168.241.1 --port=3380 --database="test" --table="t" --alter="ADD COLUMN o2 varchar(10),add column o1 int not null default 0 comment 'test' " --exact-rowcount --serve-socket-file=/tmp/gh-ost.t1.sock --panic-flag-file=/tmp/gh-ost.panic.t1.flag --postpone-cut-over-flag-file=/tmp/ghost.postpone.t1.flag --allow-on-master --execute
(1) 标示着文件终止:–panic-flag-file 创建文件终止运行,例子中创建/tmp/gh-ost.panic.t1.flag文件,终止正在运行的gh-ost,临时文件清理需要手动进行;
(2) 表示文件禁止cut-over进行,即禁止表名切换,数据复制正常进行。--postpone-cut-over-flag-file
创建文件延迟cut-over进行,即推迟切换操作。例子中创建**/tmp/ghost.postpone.t1.flag**文件,gh-ost 会完成行复制,但并不会切换表,它会持续的将原表的数据更新操作同步到临时表中。
(3) 使用socket监听请求,操作者可以在命令运行后更改相应的参数. --server-socket-file,server-tcp-port(默认)
暂停:echo throttle | socat - /tmp/gh-ost.test.t1.sock
恢复:echo no-throttle | socat - /tmp/gh-ost.test.t1.sock
修改限速:
echo chunk-size=100 | socat - /tmp/gh-ost.t1.sock
echo max-lag-millis=200 | socat - /tmp/gh-ost.t1.sock
echo max-load=Thread_running=3 | socat - /tmp/gh-ost.t1.sock
2.6 各个工具的总结对比
| 优点 | 缺点 | |
|---|---|---|
| online DDL | 索引的创建和删除,修改默认值速度快,没有性能影响 | a. 在高并发场景存在大量写请求执行ddl会有性能影响; b. 在请求量大时,有可能因为增量数据缓存不够而失败; c. 会造成较大的主备延迟; d. 当有大量写请求写入造成数据库load过高时,不能暂停 |
| pt-osc | 并发DML支持较好,不会出现请求过多失败的情况 | a. 当被修改表的主键为自增字段时,在有大量的写请求可能会产生大 量的表锁从而影响性能; b. 对主键的更新操作会产生重复数据;c. 触发器带来的开销和风险; d. 处理外键里会带来风险; |
| gh-ost | 对主机性能几乎没有影响 | a. 不支持外键和触发器; b. 不支持对JSON格式,generated column的修改; c. 不能对表名字母大小但拼写相同的表进行修改(Mytable,myTable)d. 要求binlog格式一定是row格式; e.binlog解析时会有风险 |
2.7 sysbench压测online DDL,PT-OSC,gh-ost
环境:sysbench压测200w行200张单表,连接主机获取增量
测试online DDL:
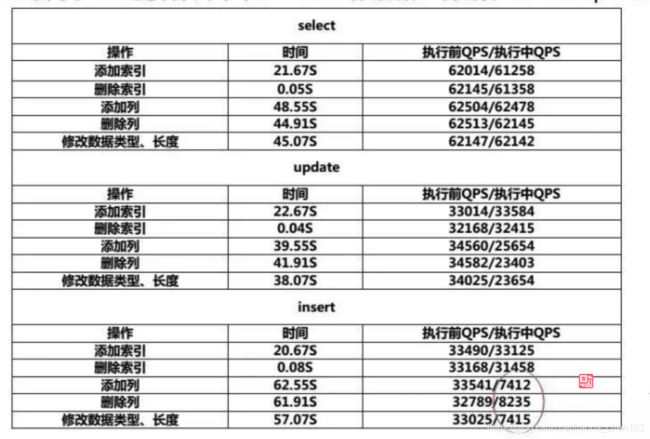
测试pt-osc:
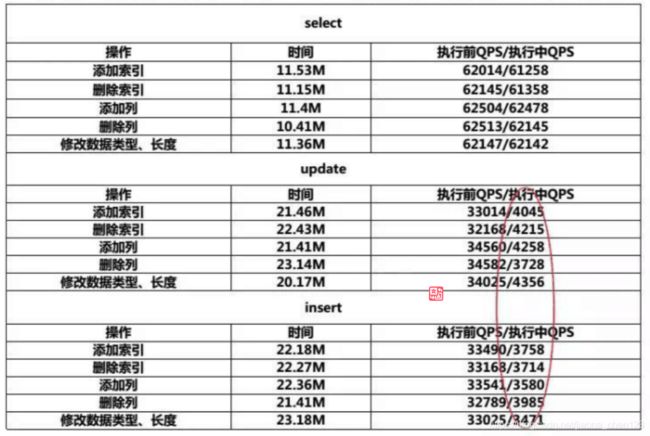
我们可以看到对于select执行前的QPS和执行后的QPS差距较小,对性能没有什么影响。但是update和insert 这种大量的写入的场景中延迟会比较大,如果表中不是自增字段,可以获得比较好的性能。如果在写入量较大的场景中,且线上环境有自增列的话,使用pt-osc会造成大量的自增锁,lock_mode=AUTO_INC,同时也跟innodb_autoinc_lock_mode的配置有关系。
auto_inc: 是一个表级锁,这种锁作用于SQL语句中而不是事务。只要语句执行完成,锁就会释放。
设置innodb_autonic_lock_mode参数可以达到性能与安全的平衡;
在子解此参数之前,我们先对自增长的插入进行划分:
a. insert-like:指所有插入语句。insert,replace,insert … select ,replace … select ,load data等;
b. simple inserts:是指能在插入前就确定插入行数的语句.insert into t(name) values (“aaa”);
c. builk inserts:指在插入前不能确定得到插入行数的语句。insert into t(id,name) values(1,‘a’),(2,‘b’);
d. mixed-mode insert:指插入中有一部分的值是自增长的,有一部分是确定的。如INSERT INTO t1(c1,c2) VALUES(1,‘a’),(NULL,‘b’),(5,‘c’),(NULL,‘d’);
- 当Innodb_autonic_lock_mode=0时,每次都会产生表锁:
不管上述哪种类型,每条sql语句都会产生auto-inc表锁,每次产生新的记录就会获取一个auto_increment值。此种情况下产生的insert_id是连续的,但是并发性较差;
- 当Innodb_autonic_lock_mode=1时
这一模式对simple insert做了优化,由于simple insert 一次性插入值的个数可以马上得到确定,所以Mysql可以一次生成几个连续的值,保证了基于语句的复制安全;
这个模式是默认模式,模式的好处是auto_inc锁不要一直保持到语句结束,只要语句得到了相应的值后就可以提前释放锁;
- innodb_autoinc_lock_mode=2时,不会锁表
这种方式并发性能最高,且不会通过auto-inc locking的方式。当然也会带来很多问题,因为在并发场景时,批量插入的值可能是不连续的。此外,基于最重要的是sbr会出现问题,因此,使用这个模式,任何都应该使用rbr模式,这样才能保证最大的并发及主从复制一致。
gh-ost测试:
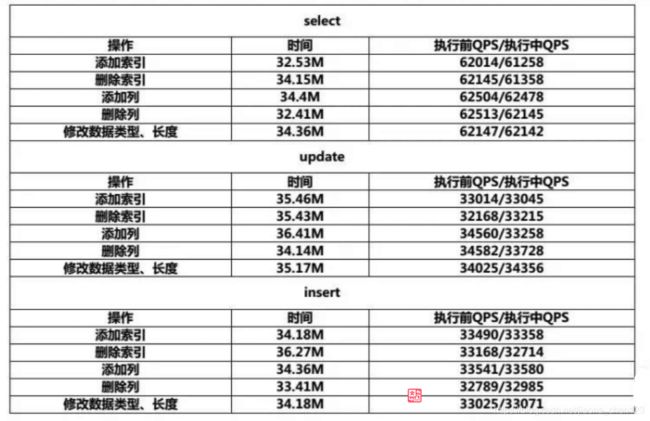
测试结果:使用gh-ost对性能的影响是最小的,无触发器可以避免MDL锁和DML锁等待。