【C++】详解std::thread
2023年9月10日,周日下午开始
2023年9月10日,周日晚上23:35完成
虽然这篇博客我今天花了很多时间去写,但是我对std::thread有了一个完整的认识
不过有些内容还没完善,以后有空再更新....
目录
- 头文件
- 类的成员
- 类型
- 方法
- (constructor)
- terminate called without an active exception是什么?
- operation=
- get_id
- joinable
- join
- detach
- native_handle
- swap
- hardware_concurrency
头文件
#include
类的成员
类型
id 线程ID(公共成员类型)
native_handle_type 本地句柄类型(公共成员类型)
方法
(constructor) 构造线程(公共成员函数)
(destructor) 线程析构函数(公共成员函数)
operator= 移动赋值线程(公共成员函数)
get_id 获取线程ID(公共成员函数)
joinable 检查是否可加入(公共成员函数)
join 加入线程(公共成员函数)
detach 分离线程(公共成员函数)
swap 交换线程(公共成员函数)
native_handle 获取本地句柄(公共成员函数)
hardware_concurrency [static] 检测硬件并发性(公共静态成员函数)
(constructor)
该构造函数用来创建线程,并执行传入的函数
#include
#include
void func()
{
std::cout << "func executes!" << std::endl;
}
int main()
{
std::thread t1(func);
return 0;
}

这里的“terminate called without an active exception”暂时不用管
terminate called without an active exception是什么?
"terminate called without an active exception"是一个C++程序运行时可能遇到的异常信息。
它表示程序在没有活动异常的情况下被终止了。
这个异常通常发生在以下情况下:
- 程序主动调用了
std::terminate()函数来终止程序的执行。这可能是因为程序遇到了无法处理的错误或异常情况。 - 程序由于未捕获的异常而终止。当程序抛出一个未捕获的异常时,如果没有其他活动的异常,系统会调用
std::terminate()来终止程序。 - 程序由于某些特定的终止条件而被操作系统或其他外部因素终止。例如,操作系统可能会根据内存使用情况或其他资源限制来终止程序。
operation=
在C++中,std::thread类提供了operator=运算符重载函数,用于将一个线程对象赋值给另一个线程对象。使用operator=可以将一个线程对象的控制转移到另一个线程对象,从而实现线程的交换或转移。这意味着调用operator=后,原线程对象将结束执行,而新线程对象将开始执行之前正在执行的代码。
get_id
该方法用来获取线程ID
#include
#include
void func()
{
std::cout <<"func executes!" << std::endl;
}
int main()
{
std::thread t1(func);
std::cout<<"ID of thread t1 is "< 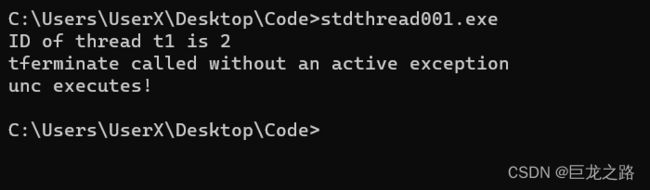
可以看到线程ID为2
joinable
什么是join呢?join是什么意思?
在线程中,join指的是等待一个线程执行完毕并返回结果后再继续执行主线程。当主线程调用子线程的join方法时,主线程会阻塞并等待子线程执行完成。这样可以确保所有线程按照预期的顺序执行,并且最后的结果是正确的。
那不用join会发生什么事情呢?
主线程不会等待子线程完成,这样有可能子线程还没执行完主线程就结束了。
#include
#include
void func()
{
std::cout <<"func executes!" << std::endl;
}
int main()
{
std::thread t1(func);
std::cout<<"ID of thread t1 is "< 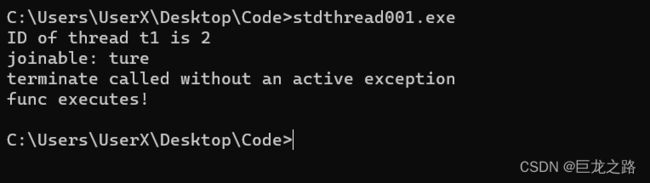
join
上面已经说过,所以不再赘述
#include
#include
void func()
{
std::cout <<"func executes!" << std::endl;
}
int main()
{
std::thread t1(func);
std::cout<<"ID of thread t1 is "< 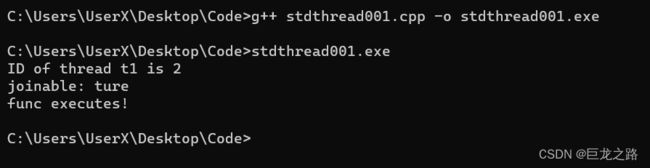
值得注意的是,没有了“terminate called without an active exception”
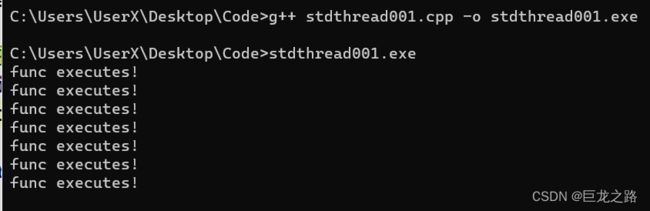
detach
什么是detach呢?detach是什么意思?
分离线程的主要目的是允许主线程在子线程执行一些耗时的操作时继续执行其他任务。通过分离线程,主线程可以避免被阻塞,从而提高程序的整体效率。
使用detach和不使用join有什么区别?
目前我还没搞懂....以后弄懂了再更新
#include
#include
void func()
{
for(int i=0;i<10000;i++){
//让线程休眠1秒
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout <<"func executes!" << std::endl;
}
}
int main()
{
std::thread t1(func);
t1.detach();
//让主线程给子线程足够的执行时间
for(int i=0;i<10000;i++)
std::this_thread::sleep_for(std::chrono::seconds(1);
return 0;
}
native_handle
C++标准库中的native_handle是一个低级接口,可以获取底层操作系统的句柄(handle)。
native_handle主要用于一些需要直接与操作系统交互的低级场景。
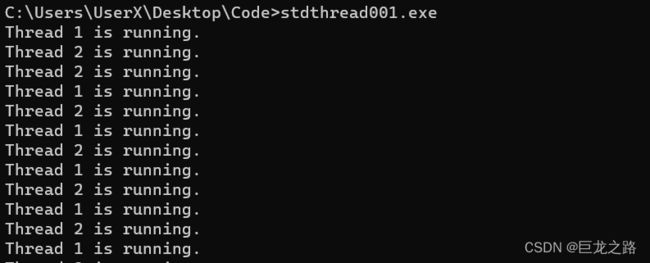
swap
swap()函数的作用是将两个线程对象的控制转移到彼此,从而实现线程的交换。这意味着调用swap()后,两个线程将开始执行对方之前正在执行的代码。
#include
#include
void threadFunction1() {
// 线程1的代码
for(int i=0;i<10000;i++){
//让线程休眠1秒
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Thread 1 is running." << std::endl;
}
}
void threadFunction2() {
// 线程2的代码
for(int i=0;i<10000;i++){
//让线程休眠1秒
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "Thread 2 is running." << std::endl;
}
}
int main() {
std::thread t1(threadFunction1); // 创建线程1
std::thread t2(threadFunction2); // 创建线程2
t1.swap(t2); // 交换线程1和线程2的状态
t1.join(); // 等待线程1结束
t2.join(); // 等待线程2结束
return 0;
}
hardware_concurrency
在C++中,hardware_concurrency是一个用于确定系统上可用的处理器核心数量的函数。它返回一个整数值,表示可以并行执行的最大线程数。通常,hardware_concurrency()函数返回的值取决于底层操作系统和硬件平台。
#include
#include
int main() {
unsigned int numThreads = std::thread::hardware_concurrency();
std::cout << "Number of available processor cores: " << numThreads << std::endl;
return 0;
}

可以看到我的最大并行线程数是8,这是由我电脑的CPU决定的。