实际场景中的多线程并发编程案例
目录
使用多线程的意义:
CountDownLatch
案例一:多线程同步发起并发请求
案例二:rocketmq内,每个broker将自己注册到所有的nameserver时
案例三:利用异步线程实现同步请求
CompletableFuture
应用一:并行调用
线程池
案例一:开10个线程,同时往单表中插入
案例二:做简易定时任务
线程同步版块
案例一:wait/notify方法应用
案例二:读写锁的使用
使用多线程的意义:
多线程能合理充分地利用CPU资源,去实现任务的并行处理,从而提升程序性能
适合使用多线程的场景
1. IO的处理:网络IO,文件IO,用线程池异步提升响应速度
2. Tomcat8.0之前,默认的IO模型bio模式下,使用线程池异步处理accept()到的每个socket
支付场景

public class AsyncPaymentService {
// 构建阻塞队列
LinkedBlockingQueue taskQueues = new LinkedBlockingQueue(100);
// 单线程池
final ExecutorService singleThread = Executors.newSingleThreadExecutor();
// 第三方支付服务
ThirdPaymentService paymentService = new ThirdPaymentService();
// 控制线程运行的属性
private volatile boolean status = true;
public String submitPay(PaymentRequest request){
taskQueues.add(request);
return "PROCESSING";
}
@PostConstruct
public void init(){
singleThread.execute(()->{
while (status){
try{
// 阻塞式获取队列中的,支付请求
PaymentRequest request = taskQueues.take();
String payResult = paymentService.doPay(request);
System.out.println("支付处理结果:"+payResult);
}catch (Exception e){
e.printStackTrace();
// 处理支付异常问题
}
}
});
}
} 注:
1. LinkedBlockingQueue初始化固定长度后,放入元素超过容量,
会抛异常:java.lang.IllegalStateException: Queue full
CountDownLatch
CountDownLatch典型用法1:某一线程在开始运行前等待n个线程执行完毕。将CountDownLatch的计数器初始化为n new CountDownLatch(n) ,每当一个任务线程执行完毕,就将计数器减1 countdownlatch.countDown(),当计数器的值变为0时,在CountDownLatch上 await() 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续后续的业务执行
CountDownLatch典型用法2:实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的CountDownLatch(1),将其计数器初始化为1,多个线程在开始执行任务前首先 coundownlatch.await(),当主线程调用 countDown() 时,计数器变为0,多个线程同时被唤醒
案例一:多线程同步发起并发请求
ExecutorService pool = Executors.newFixedThreadPool(200);
CountDownLatch waitBefore = new CountDownLatch(7000);
CountDownLatch afterBefore = new CountDownLatch(7000);
long now = System.currentTimeMillis();
for (int i=0;i<7000;i++){
pool.execute(()->{
try {
waitBefore.await();
TimeUnit.MILLISECONDS.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
afterBefore.countDown();
}
});
waitBefore.countDown();
}
afterBefore.await();
System.out.println("7000个任务执行完的总耗时:"+(System.currentTimeMillis() - now));搞个线程池,线程数是 200。然后提交 7000 个任务,每个任务耗时 100ms,用 CountDownLatch 模拟了一下并发,在我的 机器上运行耗时 3.8s 的样子
上面这个例子,实际上就把CountDownLatch的两种用法都展示出来的,用法一是,做发令枪当所有7000个线程一起开始执行;用法二是,等所有7000个子线程都执行完后,主线程再开始执行;
案例二:rocketmq内,每个broker将自己注册到所有的nameserver时
public List registerBrokerAll(
final String clusterName,
final String brokerAddr,
final String brokerName,
final long brokerId,
final String haServerAddr,
final TopicConfigSerializeWrapper topicConfigWrapper,
final List filterServerList,
final boolean oneway,
final int timeoutMills,
final boolean compressed) {
final List registerBrokerResultList = Lists.newArrayList();
List nameServerAddressList = this.remotingClient.getNameServerAddressList();
if (nameServerAddressList != null && nameServerAddressList.size() > 0) {
final RegisterBrokerRequestHeader requestHeader = new RegisterBrokerRequestHeader();
requestHeader.setBrokerAddr(brokerAddr);
requestHeader.setBrokerId(brokerId);
requestHeader.setBrokerName(brokerName);
requestHeader.setClusterName(clusterName);
requestHeader.setHaServerAddr(haServerAddr);
requestHeader.setCompressed(compressed);
RegisterBrokerBody requestBody = new RegisterBrokerBody();
requestBody.setTopicConfigSerializeWrapper(topicConfigWrapper);
requestBody.setFilterServerList(filterServerList);
final byte[] body = requestBody.encode(compressed);
final int bodyCrc32 = UtilAll.crc32(body);
requestHeader.setBodyCrc32(bodyCrc32);
final CountDownLatch countDownLatch = new CountDownLatch(nameServerAddressList.size());
for (final String namesrvAddr : nameServerAddressList) {
brokerOuterExecutor.execute(new Runnable() {
@Override
public void run() {
try {
RegisterBrokerResult result = registerBroker(namesrvAddr,oneway, timeoutMills,requestHeader,body);
if (result != null) {
registerBrokerResultList.add(result);
}
log.info("register broker[{}]to name server {} OK", brokerId, namesrvAddr);
} catch (Exception e) {
log.warn("registerBroker Exception, {}", namesrvAddr, e);
} finally {
// 注册完一个nameserver,计数器减一
countDownLatch.countDown();
}
}
});
}
// 等待broker给所有的nameserver都注册完成后,再返回
try {
countDownLatch.await(timeoutMills, TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
}
}
return registerBrokerResultList;
}
案例三:利用异步线程实现同步请求
同步请求指:客户端线程发起调用后,需要在指定的超时时间内,等到响应结果,才能完成本次调用。如果超时时间内没有得到结果,那么会抛出超时异常。
RocketMQ 的同步发送消息接口见下图:

追踪源码,真正发送请求的方法是通讯模块的同步请求方法 invokeSyncImpl 。

整体流程:
发送消息线程 Netty channel 对象调用 writeAndFlush 方法后 ,它的本质是通过 Netty 的读写线程将数据包发送到内核 , 这个过程本身就是异步的;
ResponseFuture 类中内置一个 CountDownLatch 对象 ,responseFuture 对象调用 waitRepsone 方法,发送消息线程会阻塞 ;
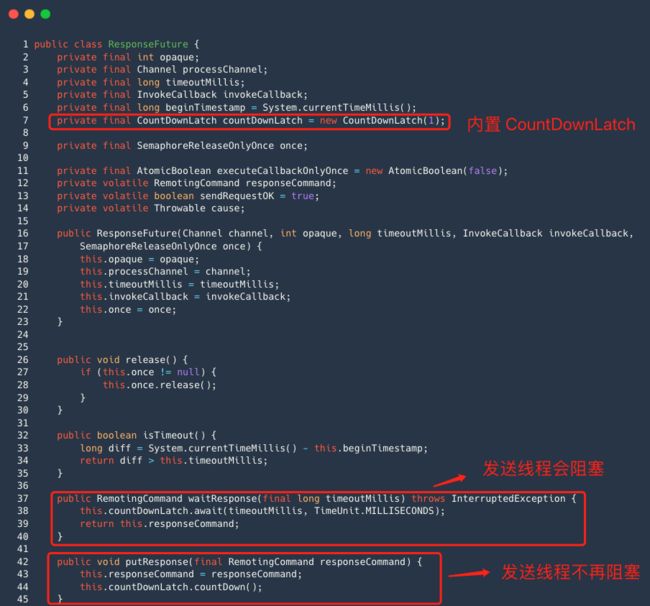
客户端收到响应命令后, 执行 processResponseCommand 方法,核心逻辑是执行 ResponseFuture 的 putResponse 方法

该方法的本质就是填充响应对象,并调用 countDownLatch 的 countDown 方法 , 这样发送消息线程就不再阻塞。
CountDownLatch 实现网络同步请求是非常实用的技巧,在很多开源中间件里,比如 Metaq ,Xmemcached 都有类似的实现
CompletableFuture
应用一:并行调用
1)使用CompletableFuture 将串行调用多个远程接口,改成并行调用,提高大接口性能
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1,
1,
60,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(1));
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo();
CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {
getRemoteUserAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {
getRemoteBonusAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
// 执行到这里,回抛java.util.concurrent.RejectedExecutionException异常
CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {
getRemoteGrowthAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();
userFuture.get();
bonusFuture.get();
growthFuture.get();
return userInfo;
}ps:
当使用自定义线程池时,如果放入的任务超过线程池能容忍的上线,任然会抛RejectedExecutionException异常;
2)RocketMQ中,broker端的消息写入流程中,消息刷盘与消息主从复制,这两个动作就同时丢入了CompletableFuture中,使得原本串行的动作并行化

线程池
案例一:开10个线程,同时往单表中插入
疯狂试探mysql单表insert极限:已实现每秒插入8.5w条数据_成都彭于晏-CSDN博客

5000w行数据,大约占用5G内存空间
案例二:做简易定时任务


Semaphore 信号量限流,这东西真管用吗?
1)注意信号量获取的,阻塞方法和超时方法
2)多线程阻塞时,可能会拖垮Tomcat服务的tps
ArrayList的线程不安全案例
semaphore信号量支持多线程进入临界区,所以,执行ArrayList的add和remove方法时,可能时多线程并发执行的
public class ExecutorTest {
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(20);
AtomicInteger count = new AtomicInteger();
ObjectPool pool = new ObjectPool<>(10,2);
for (int i=0;i<1000000;i++){
service.execute( () -> {
pool.exec(t -> {
System.out.println("当前线程为:"+Thread.currentThread().getName() + ",执行第:"+count.incrementAndGet()+"个任务");
System.out.println(t);
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
return t.toString();
});
});
}
}
}
class ObjectPool{
List poolList;
Semaphore semaphore;
public ObjectPool(int size,T t){
/**
用ArrayList,下面就会抛数组越界异常
因为,此时ArrayList,就成为了多线程并发修改的共享资源
*/
pool = new ArrayList<>();
// pool = new Vector<>();
for (int i=0;i function){
T t = null;
try{
semaphore.acquire();
t = poolList.remove(0);
return function.apply(t);
}catch (Exception e){
System.out.println("============================== 完了,数组越界啦 ==============================");
e.printStackTrace();
}finally {
pool.add(t);
semaphore.release();
}
return null;
}
}
线程同步版块
案例一:wait/notify方法应用
题目:
一个文件中有10000个数,用Java实现一个多线程程序将这个10000个数输出到5个不用文件中(不要求输出到每个文件中的数量相同)。要求启动10个线程,两两一组,分为5组。每组两个线程分别将文件中的奇数和偶数输出到该组对应的一个文件中,需要偶数线程每打印10个偶数以后,就将奇数线程打印10个奇数,如此交替进行。同时需要记录输出进度,每完成1000个数就在控制台中打印当前完成数量,并在所有线程结束后,在控制台打印”Done”.
参考:https://blog.csdn.net/qq_42449963/article/details/103482405
public class Test {
public static void main(String[] args) {
PrintWriter printWriter = null;
PrintWriter writer = null;
BufferedReader bufferedReader = null;
try {
printWriter = new PrintWriter("input.txt");
Random random = new Random();
for (int i = 0; i < 10000; i++) {
int nextInt = random.nextInt(1000);
printWriter.print(nextInt + " ");
}
printWriter.flush();
bufferedReader = new BufferedReader(new FileReader("input.txt"));
String s = null;
StringBuilder str = new StringBuilder();
while ((s = bufferedReader.readLine()) != null) {
str.append(s);
}
String[] split = str.toString().split(" ");
int m = 0;
for (int i = 0; i < 5; i++) {
int[] records = new int[2000];
for (int j = 0; j < 2000; j++) {
records[j] = Integer.parseInt(split[m]);
m++;
}
writer = new PrintWriter("output" + i + ".txt");
MyRunnable myRunnable = new MyRunnable(records, writer);
new Thread(myRunnable).start();
new Thread(myRunnable).start();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (printWriter != null) {
printWriter.close();
}
if (writer != null) {
printWriter.close();
}
if (bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
任务类
class MyRunnable implements Runnable {
private static int count = 0;
private static final Object lock = new Object();
private static final int EVEN = 0;
private static final int ODD = -1;
private int type;
private PrintWriter writer;
private int[] records;
private int evenPoint = 0;
private int oddPoint = 0;
public MyRunnable(int[] records, PrintWriter writer) {
this.records = records;
this.writer = writer;
this.type = EVEN;
}
@Override
public void run() {
while (print()) ;
}
private synchronized boolean print() {
for (int i = 0; i < 10; ) {
if (evenPoint >= records.length && oddPoint >= records.length) {
notifyAll();
return false;
}
if ((evenPoint >= records.length && type == EVEN) || (oddPoint >= records.length && type == ODD)) {
break;
}
if (type == EVEN) {
if (records[evenPoint] % 2 == 0) {
i++;
writer.print(records[evenPoint] + " ");
writer.flush();
synchronized (lock) {
count++;
if (count % 1000 == 0) {
System.out.println("已经打印了" + count+"个");
if (count == 10000) {
System.out.println("Done!");
}
}
}
}
evenPoint++;
} else {
if (records[oddPoint] % 2 == 1) {
i++;
writer.print(records[oddPoint] + " ");
writer.flush();
synchronized (lock) {
count++;
if (count % 1000 == 0) {
System.out.println("已经打印了" + count+"个");
if (count == 10000) {
System.out.println("Done!");
}
}
}
}
oddPoint++;
}
}
type = ~type;
notifyAll();
try {
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
return true;
}
}
案例二:读写锁的使用
Eureka服务端获取增量数据
获取所有应用增量信息,registry.getApplicationDeltas():
public Applications getApplicationDeltas() {
Applications apps = new Applications();
apps.setVersion(responseCache.getVersionDelta().get());
Map applicationInstancesMap = new HashMap();
try {
/**
这里虽然是在读取,但是用的却是写锁,原因是:
这里的写锁实际上是对“遍历”最近变化队列的动作加的锁,让遍历的过程中不允许其他线程修改最近变化队列,防止出现并发修改异常
*/
write.lock();
//遍历recentlyChangedQueue,获取所有增量信息
Iterator iter = this.recentlyChangedQueue.iterator();
logger.debug("The number of elements in the delta queue is :"
+ this.recentlyChangedQueue.size());
while (iter.hasNext()) {
Lease lease = iter.next().getLeaseInfo();
InstanceInfo instanceInfo = lease.getHolder();
Object[] args = {instanceInfo.getId(),
instanceInfo.getStatus().name(),
instanceInfo.getActionType().name()};
logger.debug(
"The instance id %s is found with status %s and actiontype %s",
args);
Application app = applicationInstancesMap.get(instanceInfo
.getAppName());
if (app == null) {
app = new Application(instanceInfo.getAppName());
applicationInstancesMap.put(instanceInfo.getAppName(), app);
apps.addApplication(app);
}
app.addInstance(decorateInstanceInfo(lease));
}
//读取其他Region的Apps信息,我们目前不关心,略过这部分代码......
Applications allApps = getApplications(!disableTransparentFallback);
//设置AppsHashCode,在之后的介绍中,我们会提到,客户端读取到之后更新好自己的Apps缓存之后会对比这个AppsHashCode,如果不一样,就会进行一次全量Apps信息请求
apps.setAppsHashCode(allApps.getReconcileHashCode());
return apps;
} finally {
write.unlock();
}
}这里虽然是在读取,但是用的却是写锁,原因是:
写锁实际上是对“遍历”最近变化队列的动作加的锁,让遍历的过程中不允许其他线程修改最近变化队列,防止出现并发修改异常
遍历recentlyChangedQueue,获取所有增量信息,可以看到这个随着时间动态往后滑动的180s的时间窗口,就是实现时间窗口式的增量信息保存的关键结构
为何这里读写锁这么用,首先我们来分析下这个锁保护的对象是谁,可以很明显的看出,是recentlyChangedQueue这个最近队列。那么谁在修改这个队列,谁又在读取呢?每个服务实例注册取消的时候,都会修改这个队列,这个队列是多线程修改的。但是读取,只有以ALL_APPS_DELTA为key读取LoadingCache时,LoadingCache的初始化线程会读取recentlyChangedQueue(客户端调用增量查询接口时,EurekaClient的查询请求实际查询也是通过LoadingCache的初始化线程先读取到读写缓存的),而且在缓存失效前LoadingCache的初始化线程都不会再读取recentlyChangedQueue
所以可以归纳为:多线程频繁修改,但是单线程不频繁读取。 如果没有锁,那么recentlyChangedQueue在遍历读取时如果遇到修改,就会抛出并发修改异常(需要加锁的根本原因)。如果用writeLock锁住多线程修改,那么同一时间只有一个线程能修改则效率不好。所以,利用读锁锁住多线程修改,利用写锁锁住单线程读取正好符合这里的场景
recentlyChangedQueue是ConcurrentLinkedQueue,对它的并发读写本身都是线程安全的,我们要加锁的原因仅仅是因为:让“并发读写”和“遍历”这两组动作能互斥,加锁并不是为了让读和写互斥
注册流程,也就是对最近变化队列加读锁的过程
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
try {
/**
register()虽然看上去好像是修改recentlyChangedQueue,但是这里用的是读锁
加读锁仅为了在修改recentlyChangedQueue的过程中,没有其他线程遍历recentlyChangedQueue
*/
read.lock();
//从registry中查看这个app是否存在
Map> gMap = registry.get(registrant.getAppName());
//不存在就创建
if (gMap == null) {
final ConcurrentHashMap> gNewMap = new ConcurrentHashMap>();
gMap = registry.putIfAbsent(registrant.getAppName(), gNewMap);
if (gMap == null) {
gMap = gNewMap;
}
}
//查看这个app的这个实例是否已存在
Lease existingLease = gMap.get(registrant.getId());
if (existingLease != null && (existingLease.getHolder() != null)) {
//如果已存在,对比时间戳,保留比较新的实例信息......
} else {
// 如果不存在,证明是一个新的实例
//更新自我保护监控变量的值的代码.....
}
Lease lease = new Lease(registrant, leaseDuration);
if (existingLease != null) {
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
//放入registry
gMap.put(registrant.getId(), lease);
//加入最近修改的记录队列
recentlyChangedQueue.add(new RecentlyChangedItem(lease));
//初始化状态,记录时间等相关代码......
//主动让Response缓存失效
invalidateCache(registrant.getAppName(), registrant.getVIPAddress(), registrant.getSecureVipAddress());
} finally {
read.unlock();
}
}
聊聊并发编程的12种业务场景
