K8s(Kubernetes)学习(四):Controller 控制器:Deployment、StatefulSet、Daemonset、Job
- 什么是 Controller 以及作用
- 常见的 Controller 控制器
- Controller 如何管理 Pod
- Deployment 基本操作与应用
- 通过控制器实现 Pod 升级回滚和弹性伸缩
- StatefulSet 基本操作与应用
- Daemonset 基本操作与应用
- Job 基本操作与应用
- Controller 无法解决问题
1 Controller 控制器
官网: http://kubernetes.p2hp.com/docs/concepts/architecture/controller.html
1.1 什么是 Controller
Kubernetes 通常不会直接创建 Pod, 而是通过 Controller 来管理 Pod 的。Controller 中定义了 Pod 的部署特性,比如有几个副本、在什么样的 Node 上运行等。通俗的说可以认为 Controller 就是用来管理 Pod 一个对象。其核心作用可以通过一句话总结: 通过监控集群的公共状态,并致力于将当前状态转变为期望的状态。
通俗定义: controller 可以管理 pod 让 pod 更具有运维能力
1.2 常见的 Controller 控制器
-
Deployment是最常用的 Controller。Deployment 可以管理 Pod 的多个副本,并确保 Pod 按照期望的状态运行。- ReplicaSet 实现了 Pod 的多副本管理。使用 Deployment 时会自动创建 ReplicaSet,也就是说 Deployment 是通过 ReplicaSet 来管理 Pod 的多个副本的,我们通常不需要直接使用 ReplicaSet。
-
Daemonset用于每个Node 最多只运行一个 Pod 副本的场景。正如其名称所揭示的,DaemonSet 通常用于运行 daemon。 -
Statefuleset能够保证 Pod 的每个副本在整个生命周期中名称是不变的,而其他Controller 不提供这个功能。当某个 Pod 发生故障需要删除并重新启动时,Pod 的名称会发生变化,同时 StatefuleSet 会保证副本按照固定的顺序启动、更新或者删除。 -
Job用于运行结束就删除的应用,而其他 Controller 中的 Pod 通常是长期持续运行。
1.3 Controller 如何管理 Pod
注意: Controller 通过 label 关联起来 Pods
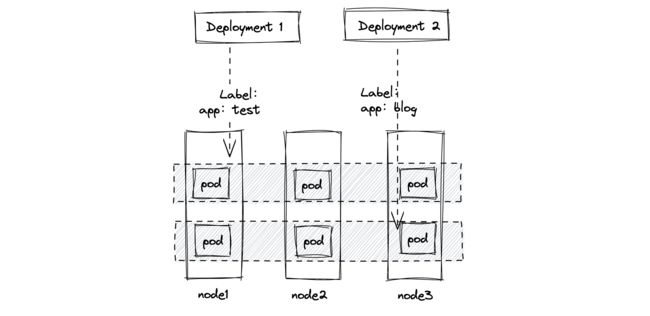
2 Deployment
官方地址: http://kubernetes.p2hp.com/docs/concepts/workloads/controllers/deployment.html
一个 Deployment 为 Pod 和 ReplicaSet提供声明式的更新能力。
你负责描述 Deployment 中的 目标状态,而 Deployment 控制器(Controller)以受控速率更改实际状态, 使其变为期望状态。你可以定义 Deployment 以创建新的 ReplicaSet,或删除现有 Deployment, 并通过新的 Deployment 收养其资源。
2.1 创建 deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.19
ports:
- containerPort: 80
2.2 查看 deployment
# 部署应用
$ kubectl apply -f app.yaml
# 查看 deployment
$ kubectl get deployment
# 查看 pod
$ kubectl get pod -o wide
# 查看 pod 详情
$ kubectl describe pod pod-name
# 查看 deployment 详细
$ kubectl describe deployment 名称
# 查看 log
$ kubectl logs pod-name
# 进入 Pod 容器终端, -c container-name 可以指定进入哪个容器。
$ kubectl exec -it pod-name -- bash
# 输出到文件
$ kubectl get deployment nginx-deployment -o yaml >> test.yaml
NAME列出了名字空间中 Deployment 的名称。READY显示应用程序的可用的“副本”数。显示的模式是“就绪个数/期望个数”。UP-TO-DATE显示为了达到期望状态已经更新的副本数。AVAILABLE显示应用可供用户使用的副本数。AGE显示应用程序运行的时间。
请注意期望副本数是根据
.spec.replicas字段设置 3。
2.3 扩缩 deployment
# 查询副本
$ kubectl get rs|replicaset
# 伸缩扩展副本
$ kubectl scale deployment nginx --replicas=5
2.4 回滚 deployment
说明:
仅当 Deployment Pod 模板(即
.spec.template)发生改变时,例如模板的标签或容器镜像被更新, 才会触发 Deployment 上线。其他更新(如对 Deployment 执行扩缩容的操作)不会触发上线动作。
# 查看上线状态
$ kubectl rollout status [deployment nginx-deployment | deployment/nginx]
# 查看历史
$ kubectl rollout history deployment nginx-deployment
# 查看某次历史的详细信息
$ kubectl rollout history deployment/nginx-deployment --revision=2
# 回到上个版本
$ kubectl rollout undo deployment nginx-deployment
# 回到指定版本
$ kubectl rollout undo deployment nginx-deployment --to-revision=2
# 重新部署
$ kubectl rollout restart deployment nginx-deployment
# 暂停运行,暂停后,对 deployment 的修改不会立刻生效,恢复后才应用设置
$ kubectl rollout pause deployment ngixn-deployment
# 恢复
$ kubectl rollout resume deployment nginx-deployment
2.5 删除 deployment
# 删除 Deployment
$ kubectl delete deployment nginx-deployment
$ kubect delete -f nginx-deployment.yml
# 删除默认命名空间下全部资源
$ kubectl delete all --all
# 删除指定命名空间的资源
$ kubectl delete all --all -n 命名空间的名称
3 StatefulSet
3.1 什么是 StatefulSet
官方地址: https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/statefulset/
StatefulSet 是用来管理有状态应用的工作负载 API 对象。
无状态应用: 应用本身不存储任何数据的应用称之为无状态应用。
有状态应用: 应用本身需要存储相关数据应用称之为有状态应用。
博客: 前端vue 后端 java mysql redis es …
数据采集: 采集程序 有状态应用
StatefulSet 用来管理某 Pod 集合的部署和扩缩, 并为这些 Pod 提供持久存储和持久标识符。
和 Deployment 类似, StatefulSet 管理基于相同容器规约的一组 Pod。但和 Deployment 不同的是, StatefulSet 为它们的每个 Pod 维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID。
如果希望使用存储卷为工作负载提供持久存储,可以使用 StatefulSet 作为解决方案的一部分。 尽管 StatefulSet 中的单个 Pod 仍可能出现故障, 但持久的 Pod 标识符使得将现有卷与替换已失败 Pod 的新 Pod 相匹配变得更加容易。
3.2 StatefulSet 特点
StatefulSet 对于需要满足以下一个或多个需求的应用程序很有价值:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和扩缩。
- 有序的、自动的滚动更新。
在上面描述中,“稳定的”意味着 Pod 调度或重调度的整个过程是有持久性的。 如果应用程序不需要任何稳定的标识符或有序的部署、删除或扩缩, 则应该使用由一组无状态的副本控制器提供的工作负载来部署应用程序,比如 Deployment或者 ReplicaSet 可能更适用于你的无状态应用部署需要。
3.3 限制
- 给定 Pod 的存储必须由 PersistentVolume Provisioner 基于所请求的
storage class来制备,或者由管理员预先制备。 - 删除或者扩缩 StatefulSet 并不会删除它关联的存储卷。 这样做是为了保证数据安全,它通常比自动清除 StatefulSet 所有相关的资源更有价值。
- StatefulSet 当前需要无头服务来负责 Pod 的网络标识。你需要负责创建此服务。
- 当删除一个 StatefulSet 时,该 StatefulSet 不提供任何终止 Pod 的保证。 为了实现 StatefulSet 中的 Pod 可以有序且体面地终止,可以在删除之前将 StatefulSet 缩容到 0。
- 在默认 Pod 管理策略(
OrderedReady) 时使用滚动更新, 可能进入需要人工干预才能修复的损坏状态。
3.4 使用 StatefulSet
1 搭建 NFS 服务
#安装nfs-utils
$ yum install -y rpcbind nfs-utils
#创建nfs目录
mkdir -p /root/nfs/data
#编辑/etc/exports输入如下内容
# insecure:通过 1024 以上端口发送 rw: 读写 sync:请求时写入共享 no_root_squash:root用户有完全根目录访问权限
echo "/root/nfs/data *(insecure,rw,sync,no_root_squash)" >> /etc/exports
#启动相关服务并配置开机自启动
systemctl start rpcbind
systemctl start nfs-server
systemctl enable rpcbind
systemctl enable nfs-server
#重新挂载 使 /etc/exports生效
exportfs -r
#查看共享情况
exportfs
2 客户端测试
# 1.安装客户端 所有节点安装
$ yum install -y nfs-utils
# 2.创建本地目录
$ mkdir -p /root/nfs
# 3.挂载远程nfs目录到本地
$ mount -t nfs 10.15.0.9:/root/nfs /root/nfs
# 4.写入一个测试文件
$ echo "hello nfs server" > /root/nfs/test.txt
# 5.去远程 nfs 目录查看
$ cat /root/nfs/test.txt
# 挂取消载
$ umount -f -l nfs目录
3 使用 statefulset
- class.yml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner # or choose another name, must match deployment's env PROVISIONER_NAME'
parameters:
archiveOnDelete: "false"
- nfs-client-provider
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: chronolaw/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 10.15.0.10
- name: NFS_PATH
value: /root/nfs/data
volumes:
- name: nfs-client-root
nfs:
server: 10.15.0.10
path: /root/nfs/data
- rbac.yml
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
- mysql.yml
apiVersion: v1
kind: Namespace
metadata:
name: ems
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: mysql-nfs-sc
namespace: ems
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
onDelete: "remain"
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
labels:
app: mysql
namespace: ems
spec:
serviceName: mysql #headless 无头服务 保证网络标识符唯一 必须存在
replicas: 1
template:
metadata:
name: mysql
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql/mysql-server:8.0
imagePullPolicy: IfNotPresent
env:
- name: MYSQL_ROOT_PASSWORD
value: root
volumeMounts:
- mountPath: /var/lib/mysql #自己容器写入数据目录
name: data #保存到指定一个变量中 变量名字就是 data
ports:
- containerPort: 3306
restartPolicy: Always
volumeClaimTemplates: #声明动态创建数据卷模板
- metadata:
name: data # 数据卷变量名称
namespace: ems # 在哪个命名空间创建数据卷
spec:
accessModes: # 访问数据卷模式是什么
- ReadWriteMany
storageClassName: mysql-nfs-sc # 使用哪个 storage class 模板存储数据
resources:
requests:
storage: 2G
selector:
matchLabels:
app: mysql
---
4 DaemonSet
4.1 什么是 DaemonSet
https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/daemonset/
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
DaemonSet 的一些典型用法:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
一种简单的用法是为每种类型的守护进程在所有的节点上都启动一个 DaemonSet。 一个稍微复杂的用法是为同一种守护进程部署多个 DaemonSet;每个具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求。
4.2 使用 DaemonSet
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: nginx
name: nginx
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.19
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
restartPolicy: Always
5 Job
5.1 什么是 Job
https://kubernetes.io/zh-cn/docs/concepts/workloads/controllers/job/
Job 会创建一个或者多个 Pod,并将继续重试 Pod 的执行,直到指定数量的 Pod 成功终止。 随着 Pod 成功结束,Job 跟踪记录成功完成的 Pod 个数。 当数量达到指定的成功个数阈值时,任务(即 Job)结束。 删除 Job 的操作会清除所创建的全部 Pod。 挂起 Job 的操作会删除 Job 的所有活跃 Pod,直到 Job 被再次恢复执行。
一种简单的使用场景下,你会创建一个 Job 对象以便以一种可靠的方式运行某 Pod 直到完成。 当第一个 Pod 失败或者被删除(比如因为节点硬件失效或者重启)时,Job 对象会启动一个新的 Pod。
你也可以使用 Job 以并行的方式运行多个 Pod。
5.2 使用 Job
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
# 当前任务出现失败 最大的重试次数
backoffLimit: 4
5.3 自动清理完成的 Job
完成的 Job 通常不需要留存在系统中。在系统中一直保留它们会给 API 服务器带来额外的压力。 如果 Job 由某种更高级别的控制器来管理,例如 CronJob, 则 Job 可以被 CronJob 基于特定的根据容量裁定的清理策略清理掉。
- 已完成 Job 的 TTL 机制
- 自动清理已完成 Job (状态为
Complete或Failed)的另一种方式是使用由 TTL 控制器所提供的 TTL 机制。 通过设置 Job 的.spec.ttlSecondsAfterFinished字段,可以让该控制器清理掉已结束的资源。TTL 控制器清理 Job 时,会级联式地删除 Job 对象。 换言之,它会删除所有依赖的对象,包括 Pod 及 Job 本身。 注意,当 Job 被删除时,系统会考虑其生命周期保障,例如其 Finalizers。
- 自动清理已完成 Job (状态为
apiVersion: batch/v1
kind: Job
metadata:
name: pi-with-ttl
spec:
ttlSecondsAfterFinished: 100
template:
spec:
containers:
- name: pi
image: perl:5.34.0
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
Job pi-with-ttl 在结束 100 秒之后,可以成为被自动删除的对象。如果该字段设置为 0,Job 在结束之后立即成为可被自动删除的对象。 如果该字段没有设置,Job 不会在结束之后被 TTL 控制器自动清除。
6 控制器无法解决问题
- 如何为 Pod 提供网络服务
- 如何实现多个 Pod 间负载均衡