interview2-框架篇
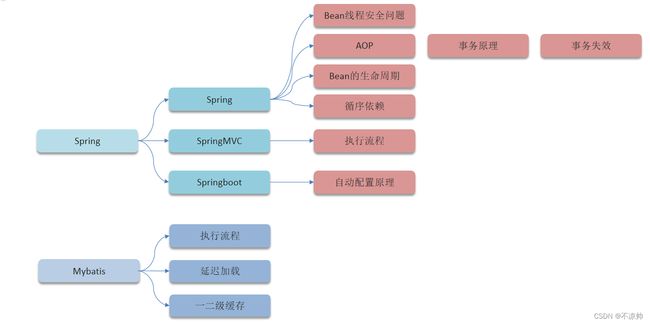 一、Spring篇
一、Spring篇
1、Spring
(1)Bean线程安全问题
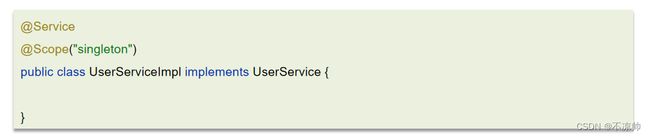
不是线程安全的。Spring框架中有一个@Scope注解,默认的值就是singleton,单例的。因为一般在spring的bean的中都是注入无状态的对象,没有线程安全问题,如果在bean中定义了可修改的成员变量,是要考虑线程安全问题的,可以使用多例或者加锁来解决。
(2)AOP、事务原理、事务失效
1.AOP
AOP称为面向切面编程,用于将那些与业务无关,但却对多个对象产生影响的公共行为和逻辑,抽取并封装为一个可重用的模块,这个模块被命名为“切面”(Aspect),减少系统中的重复代码,降低了模块间的耦合度,同时提高了系统的可维护性。
常见的AOP使用场景:
-
记录操作日志
-
缓存处理
-
Spring中内置的事务处理
2.事务原理
Spring支持编程式事务管理和声明式事务管理两种方式。
-
编程式事务控制:需使用TransactionTemplate来进行实现,对业务代码有侵入性,项目中很少使用
-
声明式事务管理:声明式事务管理建立在AOP之上的。其本质是通过AOP功能,对方法前后进行拦截,将事务处理的功能编织到拦截的方法中,也就是在目标方法开始之前加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。
3.事务失效
事务失效的场景主要有:异常捕获处理、抛出检查异常、非public方法
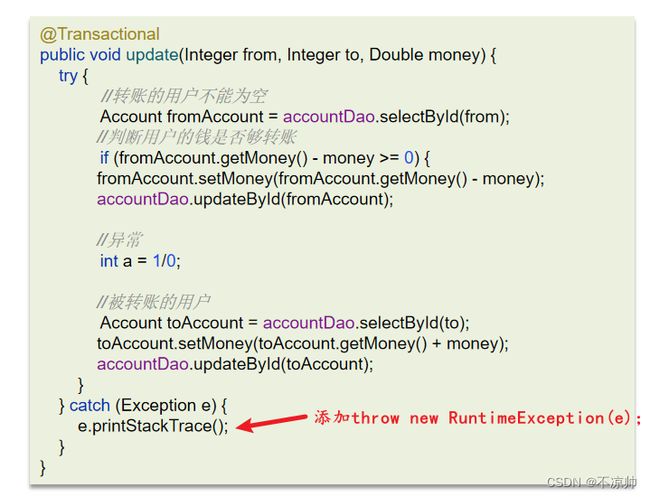
异常捕获处理:事务通知只有捉到了目标抛出的异常,才能进行后续的回滚处理,如果目标自己处理掉异常,事务通知无法知悉。
解决方法:在catch块添加throw new RuntimeException(e)抛出。
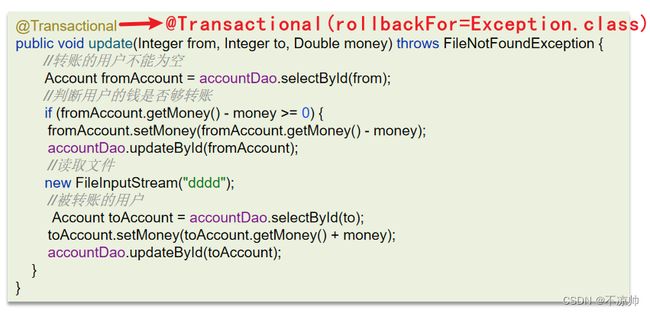
抛出检查异常:Spring 默认只会回滚非检查异常。
解决方法:配置rollbackFor属性@Transactional(rollbackFor=Exception.class)
非public方法导致的事务失效:Spring 为方法创建代理、添加事务通知,前提条件都是该方法是 public 的
解决方法:改为 public 方法
(3)Bean的生命周期
Spring容器在进行实例化时,会将xml配置的

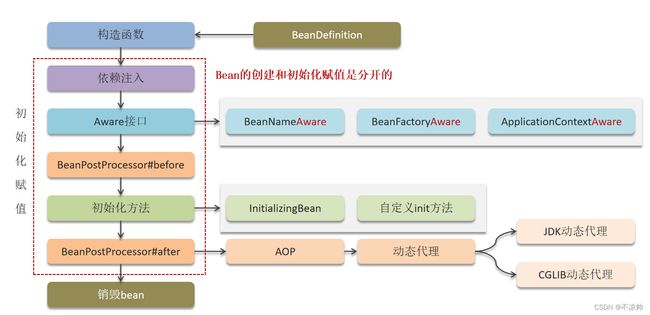 bean的生命周期:
bean的生命周期:
-
通过BeanDefinition获取bean的定义信息
-
调用构造函数实例化bean
-
bean的依赖注入处理Aware接口(BeanNameAware、BeanFactoryAware、ApplicationContextAware)
-
Bean的后置处理器BeanPostProcessor-前置
-
初始化方法(InitializingBean、init-method)
-
Bean的后置处理器BeanPostProcessor-后置
-
销毁bean
(4)循环依赖
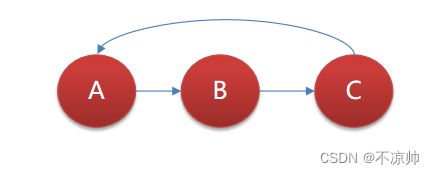
在创建A对象的同时需要使用的B对象,在创建B对象的同时需要使用到A对象。
循环依赖在spring中是允许存在,spring框架依据三级缓存已经解决了大部分的循环依赖:
-
一级缓存:单例池,缓存已经经历了完整的生命周期,已经初始化完成的bean对象
-
二级缓存:缓存早期的bean对象(生命周期还没走完)
-
三级缓存:缓存的是ObjectFactory,表示对象工厂,用来创建某个对象的
构造方法出现了循环依赖怎么解决?
A依赖于B,B依赖于A,注入的方式是构造函数
原因:由于bean的生命周期中构造函数是第一个执行的,spring框架并不能解决构造函数的的依赖注入
解决方案:使用@Lazy进行懒加载,什么时候需要对象再进行bean对象的创建
2、SpringMVC执行流程
(1)视图阶段(老旧JSP)

-
用户发送出请求到前端控制器DispatcherServlet
-
DispatcherServlet收到请求调用HandlerMapping(处理器映射器)
-
HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet。
-
DispatcherServlet调用HandlerAdapter(处理器适配器)
-
HandlerAdapter经过适配调用具体的处理器(Handler/Controller)
-
Controller执行完成返回ModelAndView对象
-
HandlerAdapter将Controller执行结果ModelAndView返回给DispatcherServlet
-
DispatcherServlet将ModelAndView传给ViewReslover(视图解析器)
-
ViewReslover解析后返回具体View(视图)
-
DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)
-
DispatcherServlet响应用户
(2)前后端分离阶段
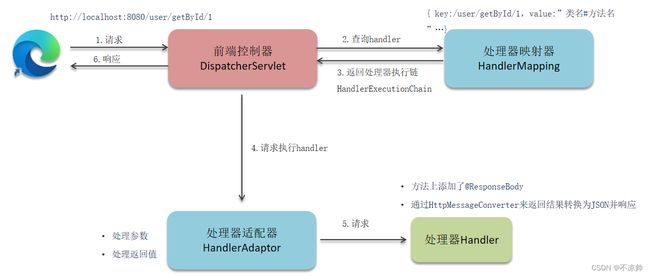
-
用户发送出请求到前端控制器DispatcherServlet
-
DispatcherServlet收到请求调用HandlerMapping(处理器映射器)
-
HandlerMapping找到具体的处理器,生成处理器对象及处理器拦截器(如果有),再一起返回给DispatcherServlet。
-
DispatcherServlet调用HandlerAdapter(处理器适配器)
-
HandlerAdapter经过适配调用具体的处理器(Handler/Controller)
-
方法上添加了@ResponseBody
-
通过HttpMessageConverter来返回结果转换为JSON并响应
3、SpringBoot自动配置原理
1, 在Spring Boot项目中的引导类上有一个注解@SpringBootApplication,这个注解是对三个注解进行了封装,分别是:
-
@SpringBootConfiguration:该注解与 @Configuration 注解作用相同,用来声明当前也是一个配置类。
-
@ComponentScan:组件扫描,默认扫描当前引导类所在包及其子包。
-
@EnableAutoConfiguration:SpringBoot实现自动化配置的核心注解。
2, 其中@EnableAutoConfiguration是实现自动化配置的核心注解。 该注解通过@Import注解导入对应的配置选择器。内部就是读取了该项目和该项目引用的Jar包的的classpath路径下META-INF/spring.factories文件中的所配置的类的全类名。 在这些配置类中所定义的Bean会根据条件注解所指定的条件来决定是否需要将其导入到Spring容器中。
3, 条件判断会有像@ConditionalOnClass这样的注解,判断是否有对应的class文件,如果有则加载该类,把这个配置类的所有的Bean放入spring容器中使用。
二、MyBatis篇
1、执行流程

-
读取MyBatis配置文件:mybatis-config.xml加载运行环境和映射文件
-
构造会话工厂SqlSessionFactory
-
会话工厂创建SqlSession对象(包含了执行SQL语句的所有方法)
-
操作数据库的接口,Executor执行器,同时负责查询缓存的维护
-
Executor接口的执行方法中有一个MappedStatement类型的参数,封装了映射信息
-
输入参数映射
-
输出结果映射
2、延迟加载
查询用户的时候,把用户所属的订单数据也查询出来,这个是立即加载。
查询用户的时候,暂时不查询订单数据,当需要订单的时候,再查询订单,这个就是延迟加载,也叫懒加载。Mybatis支持延迟记载,但默认没有开启。

延迟加载的原理:
-
使用CGLIB创建目标对象的代理对象
-
当调用目标方法时,进入拦截器invoke方法,发现目标方法是null值,执行sql查询
-
获取数据以后,调用set方法设置属性值,再继续查询目标方法,就有值了
3、一、二级缓存
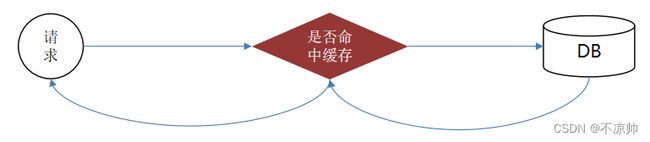

一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当Session进行flush或close之后,该Session中的所有Cache就将清空,默认打开一级缓存。

二级缓存: 基于nameSpace和mapper的作用域起作用的,不是依赖SQL session,默认也是采用 PerpetualCache,HashMap 存储。
注意事项:
1,对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了新增、修改、删除操作后,默认该作用域下所有 select 中的缓存将被 clear。
2,二级缓存需要缓存的数据实现Serializable接口。
3,只有会话提交或者关闭以后,一级缓存中的数据才会转移到二级缓存中。