一步一步解析HTTP响应报文并解析显示PNG图片

一、准备工作:
1、使用工具资源:python,socket库
2、预备知识:简单的HTTP协议,包括请求及响应等
二、发送请求
在操作系统层面,使用socket库算是比较底层的了,再底层就是硬件打包使用TCP/IP协议栈发送数据,再包裹MAC头部等等,太过复杂。
因此为了方便我们可以使用python的socket库建立与百度服务器的连接,使用C++调用windows操作系统的socket库也是类似的。
import socket
host = 'www.baidu.com'
port = 80
s = socket.socket()
s.connect((host, port))
message = "GET /img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png HTTP/1.1\r\nHost: www.baidu.com\r\n\r\n"
s.send(message.encode())
以上代码,首先添加设置了一个socket,然后将套接字连接到www.baidu.com的80服务器端口上,最后发送http请求消息。
请注意:必须将如下的http请求转化成上述的message字符串,并进行encode编码成字节数组才可以在socket中发送;
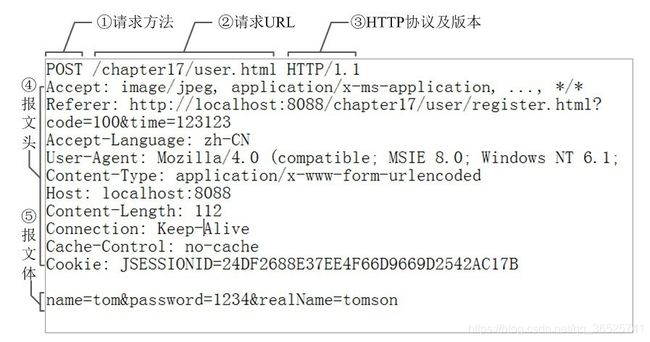
请注意: \r是回车,意思是使光标回到当前行的开头,\n是换行,即将光标下移一格,因此上述字符串中的\r\n是换行至下一行,而\r\n\r\n即下一行、再下一行,也即空一行。如下找到的网图中的http请求报文格式,我们这里虽然省略了报文主题,但是空行不能省略,即\r\n\r\n不能省。
GET /img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png HTTP/1.1
Host: www.baidu.com
# 请注意这里开始是请求报文的主体,不能忘记空行即字符串中的\r\n\r\n
三、接收响应
成功发送了请求报文后,需要在socket中接受http响应报文,由于我们不清楚返回的报文的字节长度,所以只能采用拼接的方式,每次接收最大1024个字节数据然后拼接在一起,直到接收不到字节数据即下述代码中的len(part)为0为止。
data = b''
while True:
part = s.recv(1024)
if not len(part):
break
data += part
至此我们完成了http的请求及响应,如果不发生错误的话,一般会收到的http响应码应该是200 ok,并在响应报文主体中接收到png图片数据。不妨让我们打印下试试:
print(data)
此时可以看到诸如:b’HTTP/1.1 200 OK\r\nAccept-Ranges: bytes\r\nCache-Control: max-age=315360000\r\nContent-Length: 15444\r\nContent-Type: image/png\r\nDate: Thu, 27 May 2021 07:40:37 GMT\r\nEtag: “3c54-5c2e6da42cd6e”\r\nExpires: Sun, 25 May 2031 07:40:37 GMT\r\nLast-Modified: Sat, 22 May 2021 08:20:43 GMT\r\nP3p: CP=" OTI DSP COR IVA OUR IND COM "\r\nServer: Apache\r\nSet-Cookie: BAIDUID=577A788F38F24B232CAD442676711C7B:FG=1; expires=Fri, 27-May-22 07:40:37 GMT; max-age=31536000; path=/; domain=.baidu.com; version=1\r\n\r\n\x89PNG\r\n\x1a\n\x00\x00\x00\rIHDR\x00\x00\x02\x1c\x00\x00\x01\x02\x08\x06\x00\x00\x00\xb5\xca\x0e\n\x00\x00\x00\x01sRGB\x00\xae\xce\x1c\xe9\x00\x00\x00DeXIfMM\x00*\x00\x00\x00\x08\x00\x01\x87i\x00\x04\x00\x00\x00\x01\x00\x00\x00\x1a\x00\x00\x00\x00\x00\x03\xa0\x01\x00\x03\x00\x00\x00\x01\x00\x01\x00\x00\xa0\x02\x00\x04\x00\x00\x00\x01\x00\x00\x02\x1c\xa0\x03\x00\x04\x00\x00\x00\x01\x00\x00\x01\x02\x00\x00\x00\x00u\xe5eg\x00\x00;\xbeIDATx\x01\……这样的十六进制字节数组。而我们需要的png数据,就在\r\n\r\n之后的响应报文主体之中。因此,我们可以先忽略前面的响应信息,直接获得报文主体。
pos = 0
for i, num in enumerate(data):
if chr(num) == '\r':
if chr(data[i + 1]) == '\n':
if chr(data[i + 2]) == '\r':
if chr(data[i + 3]) == '\n':
pos = i + 4
break
设置pos变量的作用显而易见,即找到响应报文主体的开始位置————\r\n\r\n后第一个字节。那么,很明显的,data[pos:] 即为png图像的所有数据。
接下来就是处理这些十六进制字节数组,首先请参阅链接链接一:一步一步解码PNG图片,这个里面关于IDAT的filter滤波函数部分说的不算清楚,至少我看的时候懵懵的,所以IDAT部分的filter相关请见链接二:IDAT的filter函数。
根据链接一的内容,我们可以知道,png数据的开头是文件签名,占八个字节,于是我们可以打印看看:
tag = list(data[pos:pos+8])
print(tag)
hex_tag = ["0x%x"%i for i in tag]
print(hex_tag)
pos = pos + 8
第一步的tag让byte字节数组直接隐式转化为int型的list,第二步转化为十六进制,打印输出可以看到tag的值为[137, 80, 78, 71, 13, 10, 26, 10],hex_tag的值为[‘0x89’, ‘0x50’, ‘0x4e’, ‘0x47’, ‘0xd’, ‘0xa’, ‘0x1a’, ‘0xa’]均符合png文件签名。最后让pos加8移动到下个数据块开始的位置。
接下来就进入png的数据块了,基本上符合如下的格式:
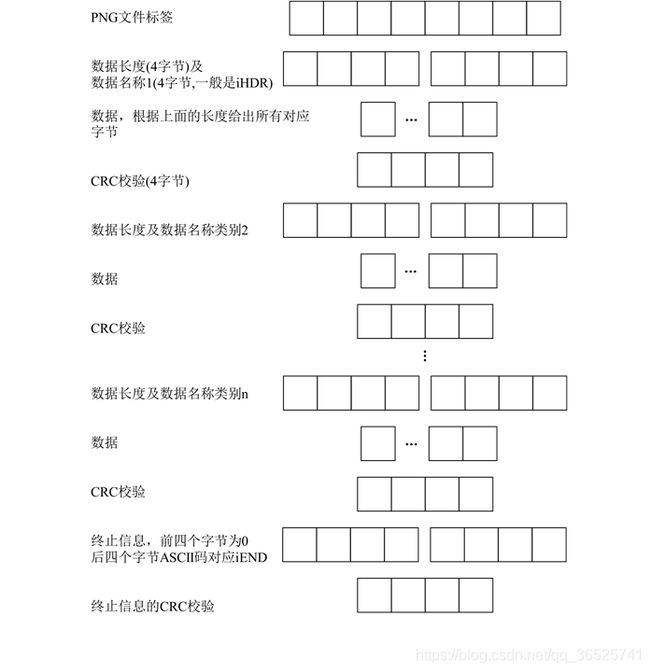
按照链接一及上图里的说明,我们继续往下读取:接下来是8字节的开始信息部分,包括4字节的数据长度和4字节的数据名称:
head = list(data[pos:pos+8])
print(head)
pos = pos + 8
此处打印得到[0, 0, 0, 13, 73, 72, 68, 82]按照上述说明,表示接下来有13个字节的IHDR字段数据(73,72,68, 82对应的ASCII码值为IHDR),同样让pos加8移至下个位置,因此我们继续读取:
IHDR = list(data[pos:pos+13])
print(IHDR)
pos = pos + 13
此处打印得到[0, 0, 2, 28, 0, 0, 1, 2, 8, 6, 0, 0, 0],根据链接一中的说明前4个字节为图像宽度,接着四个字节为图像高度,最后的5个字节分别表示depth, colorType, compression, filter,interlace,经计算可知图像宽度为2x256+28=540,高度为 1x256+2=258(一个字节256个数),图像深度为8,即一个通道的像素用一个字节表示其值,6表示RGBA图像。
接下来是4个字节的CRC校验,我们可以直接不用管。此时需要pos+4跳过,然后继续往下读8个字节————下一个数据开始信息段:
pos = pos + 4
head = list(data[pos:pos+8])
print(head)
pos = pos + 8
得到[0, 0, 0, 1, 115, 82, 71, 66],对比链接一可知,这个是含有一个字节的sRGB数据段,因此:
sRGB = list(data[pos:pos+1])
print(sRGB)
pos = pos + 1
得到0,符合链接一所述。接下来又是四个字节的CRC校验,直接跳过再读8个字节:
pos = pos + 4
head = list(data[pos:pos+8])
print(head)
pos = pos + 8
得到[0, 0, 0, 68, 101, 88, 73, 102]为eXIf字段,有68个字节,这些都是png图像的附加信息,也可以略过,包含后面的4个字节校验,我们直接跳过,读取下一个8个字节:
pos = pos + 68 + 4
head = list(data[pos:pos+8])
print(head)
pos = pos + 8
得到[0, 0, 59, 190, 73, 68, 65, 84]为IDAT字段,非常重要的图像真正像素数据字段,有59x256+190=15294个字节,根据链接一中所述,这个字段的数据需要解压得到扫描线相关数据,我们使用zlib解压它:
import numpy as np
IDAT = data[pos:pos+15294]
import zlib
decps_IDAT = zlib.decompress(IDAT)
decps_IDAT = list(decps_IDAT)
print(len(decps_IDAT))
IDAT_data = np.asarray(decps_IDAT,dtype=np.uint8).reshape(258, -1)
print(IDAT_data.shape)
打印的解压后的IDAT数组长为557538,然后我们根据链接一知道每行都有扫描线,由于前面我们获取了图像的高度为258,因此可以将其转化为numpy矩阵,做个变形打印可得矩阵的维度为258x2161,为什么会是2161?原因是,每行都是一个扫描线,2161个字节数据中,第一个字节代表了滤波函数的类型,分5类,值为0~4,然后的2160=540x4,因为是RGBA图像,因此每个像素用四个字节表示,每列共540个像素,即图像的宽,故每行有4x540+1=2161个字节数据。
接下来就是解析这个矩阵数据了,我们首先需要提取矩阵的第一列,即滤波函数部分,然后根据相应的滤波函数,恢复原始的图像像素值,此时就需要参考链接二:IDAT的filter函数。下图摘自于该链接,因此。对应的5种滤波函数为None、Sub、Up、Average、Paeth及其原像素值的恢复方法均可以按照下图进行一行一行的计算。

有一句话需要注意的是,滤波函数基于byte而不是pixel,即恢复原像素值需要按每个字节即AGBA分别对应处理而不是一个像素的整个RGBA处理。还有一点需要注意的是在滤波函数进行处理时,比如Sub函数,是可能出现负值的,例如24-236=-212,这时候由于需要转化成uint8型,故滤波后所得值为44,这时候我们恢复该值会用44+236=280得到280,显然不符合uint8的,需要将其强制转化或直接减去256得到原值24。这点尤其需要注意。另外,关于滤波函数4的Paeth算法,链接二中也有详细说明,也需要在计算中注意溢出uint8的情况。还有就是Sub和Up函数需要操作左方和上方数据,因此我们需要对IDAT_data矩阵左方和上方补零。经整理,解析IDAT的数据部分代码如下:
def path_abc(a, b, c):
p = a + b - c
pos = np.argmin([abs(p - a), abs(p - b), abs(p - c)], axis=0)
m = np.concatenate([a.reshape(1, -1), b.reshape(1, -1), c.reshape(1, -1)], axis=0)[pos, np.arange(a.shape[0])] # 这里是基于byte的处理,即一个像素的RGBA分别处理取离a+b-c最近的
return m
img = IDAT_data[:, 1:]
op = IDAT_data[:, 0] # 保存每行的滤波函数
tmp = np.zeros((img.shape[0] + 1, img.shape[1] + 4)) # 补零操作
# 注意上述这里不要dtype = np.uint8,否则后续计算中会隐式的自动将大于255的值和小于0的值转化,尤其是计算paeth即我的函数path_abc的地方,这些地方情况不同,是需要手动改的
tmp[1:, 4:] = img
print(img.shape, tmp.shape)
mid = 0
for i in range(1, tmp.shape[0]):
for j in range(1, tmp.shape[1] // 4):
if op[i-1] == 0: # None函数,i行j列
mid = tmp[i, 4 * j:4 * j + 4]
elif op[i-1] == 1: # Sub函数,前一列即j-1
mid = tmp[i, 4 * j:4 * j + 4] + tmp[i, 4 * (j - 1):4 * (j - 1) + 4]
elif op[i-1] == 2: # Up函数,上一行即i-1
mid = tmp[i, 4 * j:4 * j + 4] + tmp[i - 1, 4 * j:4 * j + 4]
elif op[i-1] == 3: # Average函数
mid = tmp[i, 4 * j:4 * j + 4] + (tmp[i - 1, 4 * j:4 * j + 4] + tmp[i, 4 * (j - 1):4 * (j - 1) + 4]) / 2
elif op[i-1] == 4: # Paeth函数,注意这里需要按byte算,见path_abc
p = path_abc(tmp[i, 4 * (j - 1):4 * (j - 1) + 4], tmp[i - 1, 4 * j:4 * j + 4], tmp[i - 1, 4 * (j - 1):4 * (j - 1) + 4])
mid = p + tmp[i, 4 * j:4 * j + 4]
t_f = mid > 255
mid[t_f] = mid[t_f] - 256 # 对中间值进行溢出处理
tmp[i, 4 * j:4 * j + 4] = mid # 赋值返回修改tmp矩阵,得到恢复处理好的原矩阵
img = tmp[1:, 4:]
img = img.reshape((258, 540, 4))
img = np.array(img, dtype=np.uint8)
img = cv2.cvtColor(img, cv2.COLOR_RGBA2BGR) # 显示图像
cv2.imshow("img", img)
cv2.waitKey(0)
到此为止,我们终于可以看到一张图像如下,我们终于成功了!

至此我们基于http协议和png格式的从底层解析http响应报文中报文主体的png二进制数据并显示出图像就完成了,这一步步走来,每一步都需要小心注意,我们不仅了解了http协议格式,并调用python的socket库发送了请求报文,还熟悉了png图像的数据格式,并从http响应报文的二进制数据里解析出了原图像数据并加以显示,证明我们真正的理解了。还是那句话,计算机无论是存储还是通信,都是以二进制来做的,能从二进制数据中读到解析出你想要的东西,多么令人振奋!继续加油吧!你甚至可以基于此,做一个图片浏览器!或者照片查看器!