【Spring框架】一篇文章带你彻底搞懂Spring解决循环依赖的底层原理
目录
一、前言
二、什么是循环依赖
三、Spring Bean 的循环依赖问题
3.1 Bean 的创建步骤
3.2 为什么 Spring Bean 会产生循环依赖问题?
3.3 什么情况下循环依赖可以被处理?
四、Spring 如何解决循环依赖问题?
4.0 什么是三级缓存
4.1 简单的循环依赖(没有AOP)
4.1.0 创建Bean的前期流程源码分析
4.1.1 创建A:调用doGetBean()
4.1.1.1 调用getSingleton(beanName):调用的第一个名为getSingleton的方法,尝试从缓存中获取Bean
4.1.1.2 调用getSingleton(beanName, singletonFactory):调用的第二个名为getSingleton的方法,去创建Bean
4.1.1.2.1 createBean()方法:创建Bean
4.1.1.2.1.1 调用addSingletonFactory方法:这个方法就是解决循环依赖问题的关键
4.1.2 创建B
4.1.2.1 调用第一个getSingleton()方法实现对B注入A
4.1.2.1.1 调用getEarlyBeanReference()方法:用来从singletonFactory工厂类中返回Bean
4.1.3 创建A和B的流程总结
4.2 结合了AOP的循环依赖
1、在给B注入的时候为什么要注入一个代理对象?
2、明明在创建A的时候,到初始化这一步完成的时候仍然还是原始的A对象,那么如果对A有AOP增强的话,为什么最终在Spring容器中取出的A是代理增强的对象呢?Spring是在什么时候将代理对象放入到容器中的呢?
3、初始化的时候是对A对象本身进行初始化(初始化之前也都是对原始A对象进行的处理),而添加到Spring容器中以及注入到B中的都是代理对象,这样不会有问题吗?
4、三级缓存为什么要使用工厂而不是直接使用引用?换而言之,为什么需要这个三级缓存,直接通过二级缓存暴露一个引用不行吗?
4.3 Spring 解决 Bean 的循环依赖的流程总结
4.4 三级缓存真的提高了效率了吗?
五、循环依赖问题的解决方案
5.1 重新设计
5.2 使用 Setter/Field 注入
5.3 使用@Lazy注解
5.4 使用 @PostConstruct注解
5.5 实现ApplicationContextAware 和 InitializingBean接口
5.6 思考题:为什么在下表中的第三种情况的循环依赖能被解决,而第四种情况不能被解决呢?
第三种情况
第四种情况
六、什么样的循环依赖无法处理?
七、面试题
7.1 Spring是如何解决的循环依赖?
7.2 为什么不直接使用一级缓存来解决循环依赖
7.3 为什么要使用三级缓存呢?直接使用一级缓存和二级缓存能解决循环依赖吗?
一、前言
Spring中的循环依赖一直是Spring中一个很重要的话题,一方面是因为源码中为了解决循环依赖做了很多处理,另外一方面是因为面试的时候,如果问到Spring中比较高阶的问题,那么循环依赖必定逃不掉。如果你回答得好,那么这就是你的必杀技,反正,那就是面试官的必杀技,这也是取这个标题的原因,当然,本文的目的是为了让你在之后的所有面试中能多一个必杀技,专门用来绝杀面试官!
本文的核心思想就是,当面试官问:
“请讲一讲Spring中的循环依赖。”的时候,我们到底该怎么回答?
主要分下面几点:
- 什么是循环依赖?
- 什么情况下循环依赖可以被处理?
- Spring是如何解决的循环依赖?
同时本文希望纠正几个目前业界内经常出现的几个关于循环依赖的错误的说法:
- 只有在setter方式注入的情况下,循环依赖才能解决(错)
- 使用第三级缓存的目的是为了提高效率(错)
二、什么是循环依赖
通俗来讲,循环依赖指的是一个实例或多个实例存在相互依赖的关系(类之间循环嵌套引用)。
举个例子
@Component
public class AService {
// A中注入了B
@Autowired
private BService bService;
}
@Component
public class BService {
// B中也注入了A
@Autowired
private AService aService;
}
上述例子中 AService 依赖了 BService,BService 也依赖了 AService,这就是两个对象之间的相互依赖。

当然循环依赖还包括 自身依赖、多个实例之间相互依赖(A依赖于B,B依赖于C,C又依赖于A)。
// 自己依赖自己
@Component
public class A {
// A中注入了A
@Autowired
private A a;
}
如果我们在普通Java环境下正常运行上面的代码调用 AService 对象并不会出现问题,也就是说普通对象就算出现循环依赖也不会存在问题,因为对象之间存在依赖关系是很常见的,那么为什么被 Spring 容器管理后的对象有循环依赖的情况会出现问题呢?
三、Spring Bean 的循环依赖问题
被 Spring 容器管理的对象叫做 Bean,为什么 Bean 会存在循环依赖问题呢?
想要了解 Bean 的循环依赖问题,首先需要了解 Bean 是如何创建的(需要了解Bean的生命周期)。
3.1 Bean 的创建步骤
为了能更好的展示出现循环依赖问题的环节,所以这里的 Bean 创建步骤做了简化:
- 在创建 Bean 之前,Spring 会通过扫描获取 BeanDefinition。
- BeanDefinition就绪后会读取 BeanDefinition 中所对应的 class 来加载类。
- 实例化阶段:根据构造函数来完成实例化 (未属性注入以及初始化的对象 这里简称为 原始对象)
- 属性注入阶段:对 Bean 的属性进行依赖注入 (这里就是发生循环依赖问题的环节)
- 如果 Bean 的某个方法有AOP操作,则需要根据原始对象生成代理对象。
- 最后把代理对象放入单例池(一级缓存singletonObjects)中。
两点说明:
- 上面的 Bean 创建步骤是对于 单例(singleton) 作用域的 Bean。
- Spring 的 AOP 代理就是作为 BeanPostProcessor 实现的,而 BeanPostProcessor 是发生在属性注入阶段后的,所以 AOP 是在 属性注入 后执行的。
3.2 为什么 Spring Bean 会产生循环依赖问题?
通过上面的 Bean 创建步骤可知:实例化 Bean 后会进行 属性注入(依赖注入)。
如最初举例的 AService 和 BService 的依赖关系,当 AService 创建时,会先对 AService 进行实例化生成一个原始对象,然后在进行属性注入时发现了需要 BService 对应的 Bean,此时就会去为 BService 进行创建,在 BService 实例化后生成一个原始对象后进行属性注入,此时会发现也需要 AService 对应的 Bean。
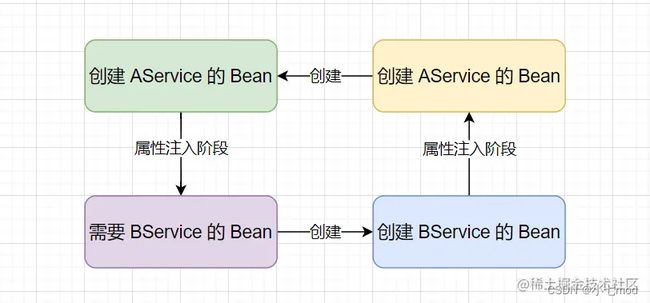
这样就会造成 AService 和 BService 的 Bean 都无法创建,就会产生 循环依赖 问题。
而这种情况只会在将Bean交给Spring管理的时候才会出现,因为上面的这些属性注入操作都是Spring去做的,如果只是我们自己在Java中创建对象可以不去注入属性,让成员属性为NULL也可以正常执行的,这样也就不会出现循环依赖的问题了。
3.3 什么情况下循环依赖可以被处理?
Spring 并不能解决所有 Bean 的循环依赖问题,接下来通过例子来看看哪些场景下的循环依赖问题是可以被解决的。
Spring中循环依赖场景有:
(1)构造器的循环依赖
(2)field属性的循环依赖。
在回答什么情况下循环依赖问题可以被解决前,首先要明确一点,Spring解决循环依赖是有前置条件的:
- 出现循环依赖的Bean必须要是单例
- 依赖注入的方式不能全是构造器注入的方式(很多博客上说,只能解决setter方法的循环依赖,这是错误的)
其中第一点应该很好理解,如果原型的Bean出现循环依赖,Spring会直接报错,Spring 无法解决 原型作用域 出现的循环依赖问题。因为 Spring 不会缓存 原型 作用域的 Bean,而 Spring 依靠 缓存 来解决循环依赖问题,所以 Spring 无法解决 原型 作用域的 Bean。Spring Bean默认都是单例的。
第二点:不能全是构造器注入是什么意思呢?我们还是用代码说话:
@Component
public class A {
public A(B b) {
}
}
@Component
public class B {
public B(A a){
}
}
在上面的例子中,A中注入B的方式是通过构造器,B中注入A的方式也是通过构造器,这个时候循环依赖是无法被解决,如果你的项目中有两个这样相互依赖的Bean,在启动时就会报出以下错误:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
以上报错说明 Spring 无法解决 构造器注入 出现的循环依赖问题。因为 构造器注入 发生在 实例化阶段,而 Spring 解决循环依赖问题依靠的 三级缓存 在 属性注入阶段,也就是说调用构造函数时还未能放入三级缓存中,所以无法解决 构造器注入 的循环依赖问题。
为了测试循环依赖的解决情况跟注入方式的关系,我们做如下四种情况的测试
| 依赖情况 |
依赖注入方式 |
循环依赖是否被解决 |
| AB相互依赖(循环依赖) |
均采用setter方法注入 |
是 |
| AB相互依赖(循环依赖) |
均采用构造器注入 |
否 |
| AB相互依赖(循环依赖) |
A中注入B的方式为setter方法,B中注入A的方式为构造器 |
是 |
| AB相互依赖(循环依赖) |
B中注入A的方式为setter方法,A中注入B的方式为构造器 |
否 |
具体的测试代码跟简单,我就不放了。从上面的测试结果我们可以看到,不是只有在setter方法注入的情况下循环依赖才能被解决(setter注入可以利用三级缓存解决循环依赖问题),即使存在构造器注入的场景下,循环依赖依然被可以被正常处理掉。
那么到底是为什么呢?Spring到底是怎么处理的循环依赖呢?不要急,我们接着往下看。
四、Spring 如何解决循环依赖问题?
Spring的循环依赖的理论依据其实是基于Java的引用传递,当我们获取到对象的引用时,对象的field或则属性是可以延后设置的(但是构造器必须是在获取引用之前)。
Spring 是靠 三级缓存 来解决循环依赖问题的,接下来了解一下 什么是三级缓存 以及 解决循环依赖问题的具体流程。
4.0 什么是三级缓存
那么Spring如何解决的循环依赖问题呢,对于单例来说,在Spring容器整个生命周期内,有且只有一个对象,所以很容易想到这个对象应该存在Cache中,Spring为了解决单例的循环依赖问题,使用了三级缓存。
这三个缓存都是定义在DefaultSingletonBeanRegistry类中的:
/** Cache of singleton objects: bean name --> bean instance */
// 单例对象的cache:一级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(64);
/** Cache of early singleton objects: bean name --> bean instance */
// 提前暴光的单例对象的Cache:二级缓存
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
/** Cache of singleton factories: bean name --> ObjectFactory */
// 单例对象工厂的cache:三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
循环依赖主要的三级缓存分别是 :
- singletonObbjects:一级缓存单例池,主要存放最终形态的单例bean;我们一般获取一个bean都是从这个缓存中获取;需要说明的是并不是所有单例bean都存在这个缓存当中,有些特殊的单例bean不存在这个缓存当中
- earlySingletonObjects:二级缓存,主要存放的是过渡bean(原始对象/原始对象的代理对象);也就是从三级缓存当中产生出来的对象;它的作用是防止在多级循环依赖的情况下重复从三级缓存当中创建对象,其他对象都可以直接从二级缓存中获取到原始对象(的代理对象);因为三级缓存当中创建对象是需要牺牲一定得性能;有了这个缓存可以一定程度上提高效率(但是提高的效率并不明显)。只有在调用了三级缓存中的ObjectFactory的getObject() 方法获取原始对象(的代理对象)时,才会将原始对象(的代理对象)放入二级缓存,而调用三级缓存中的ObjectFactory的getObject() 方法获取原始对象(的代理对象)这种情况只会发生在有循环依赖的时候,所以,二级缓存在没有循环依赖的情况下不会被使用到。二级缓存是为了提前暴露 Bean 来解决循环依赖问题,此时的 Bean 可能还没有进行属性注入,只有等完成了属性注入、初始化后的 Bean 才会上移到一级缓存(单例池)中。
- singletonFactories 三级缓存,用于存放原始对象对应的ObjectFactory,它的作用主要是为了产生一个对象;每生成一个原始对象,都会将这个原始对象对应的ObjectFactory放到三级缓存中,通过调用ObjectFactory的getObject() 方法,就能够在需要动态代理的情况下为原始对象生成代理对象并返回,否则返回原始对象,以此来处理循环依赖时还需要动态代理的情况。
因为这个缓存当中存到的是一个工厂;可以产生特定对象;程序员可以去扩展BeanPostProcessor来定制这个工厂产生对象的过程;比如AOP就是扩展了这个工厂的产生过程;从而完成完整的aop功能;如果没有这个缓存那么极端情况下会出现循环依赖注入的bean不是一个完整的bean,或者说是一个错误的bean。
为什么会存在三级缓存,主要原因就是:延迟代理对象的创建。设想一下,如果在实例化出一个原始对象的时候,就直接将这个原始对象的代理对象创建出来(如果需要创建的话),然后就放在二级缓存中,似乎感觉三级缓存就没有存在的必要了对吧,但是请打住,这里存在的问题就是,如果真这么做了,那么每一个对象在实例化出原始对象后,就都会去创建代理对象,而Spring的原始设计中,代理对象的创建应该是由AnnotationAwareAspectJAutoProxyCreator这个后置处理器的postProcessAfterInitialization() 来完成,也就是:在对象初始化完毕后,再去创建代理对象。如果真的只用两个缓存来解决循环依赖,那么就会打破Spring对AOP的一个设计思想。
下面我们就通过分析源码,来讲解Spring是如何解决循环依赖为题的。关于循环依赖的解决方式应该要分两种情况来讨论:
- 简单的循环依赖(没有AOP)
- 结合了AOP的循环依赖
4.1 简单的循环依赖(没有AOP)
我们先来分析一个最简单的例子,就是上面提到的那个demo
@Component
public class A {
// A中注入了B
@Autowired
private B b;
}
@Component
public class B {
// B中也注入了A
@Autowired
private A a;
}
通过上文我们已经知道了这种情况下的循环依赖是能够被解决的,那么具体的流程是什么呢?我们一步步分析。
首先,我们要知道Spring在创建Bean的时候默认是按照自然排序来进行创建的(按照Bean名称字典序,比如A类就要早于B类被创建),所以第一步Spring会去创建A。
与此同时,我们应该知道,Spring在创建Bean的过程中分为三步:
- 实例化,其实也就是调用对象的构造方法实例化对象。对应方法:AbstractAutowireCapableBeanFactory中的createBeanInstance方法
- 属性注入,这一步主要是对bean的依赖属性进行填充。对应方法:AbstractAutowireCapableBeanFactory的populateBean方法
- 初始化,在属性注入之后,Spring会调用设置的init()方法来进行初始化,对Bean进一步进行处理完善。对应方法:AbstractAutowireCapableBeanFactory的initializeBean方法

这些方法在之前源码分析的文章中都做过详细的解读了,如果你之前没看过我的文章,那么你只需要知道:
- 实例化,简单理解就是new了一个对象
- 属性注入,为实例化中new出来的对象填充属性
- 初始化,执行aware接口中的方法,初始化方法,完成AOP代理
其实我们简单的思考一下就发现,出现循环依赖的问题主要在 (1)和 (2)两个步骤上,也就是也就是(1)实例化阶段会造成构造器循环依赖和(2)属性注入阶段会造成field循环依赖。
4.1.0 创建Bean的前期流程源码分析
我们先讲一下创建Bean的前期流程,这些内容其实在之前IOC源码笔记中已经讲过了,这里我们就简要复习一下。
在Spring中,如果基于XML配置bean,那么使用的容器为ClassPathXmlApplicationContext,如果是基于注解配置bean,则使用的容器为AnnotationConfigApplicationContext。以AnnotationConfigApplicationContext为例,其构造函数如下所示:
public AnnotationConfigApplicationContext(Class<?>... componentClasses) {
this();
register(componentClasses);
// 初始化容器
refresh();
}
在AnnotationConfigApplicationContext的构造函数中会调用到AbstractApplicationContext的refresh() 方法,实际上无论是基于XML配置bean,还是基于注解配置bean,亦或者是Springboot中,在初始化容器时都会调用到AbstractApplicationContext的refresh() 方法中。下面看一下refresh() 方法:
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
StartupStep contextRefresh = this.applicationStartup.start("spring.context.refresh");
// ......
try {
// ......
// 初始化所有非延时加载的单例bean
finishBeanFactoryInitialization(beanFactory);
// ......
}
catch (BeansException ex) {
// ......
throw ex;
}
finally {
resetCommonCaches();
contextRefresh.end();
}
}
}
重点关心refresh() 方法中调用的finishBeanFactoryInitialization() 方法,该方法会初始化所有非延时加载的单例bean(也就是提前将非延迟加载的单例Bean装配到Spring容器中),其实现如下:
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
beanFactory.setTempClassLoader(null);
beanFactory.freezeConfiguration();
// 初始化所有非延时加载的单例bean
beanFactory.preInstantiateSingletons();
}
在finishBeanFactoryInitialization() 方法中会调用到DefaultListableBeanFactory的preInstantiateSingletons() 方法,如下所示:
public void preInstantiateSingletons() throws BeansException {
// ......
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// 在这个循环中通过getBean()方法初始化bean
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// 判断是否是FactoryBean
if (isFactoryBean(beanName)) {
// ......
}
else {
// 不是FactoryBean,则通过getBean()方法来初始化bean
getBean(beanName);
}
}
}
// ......
}
到了这里我们就了解到Spring中初始化bean,是通过调用容器的getBean() 方法来完成,在getBean() 方法中如果获取不到bean,此时就会初始化这个bean。所以开始创建Bean的流程是从AbstractBeanFactory的getBean() 方法开始的,这也是我们讲解循环依赖的重点。AbstractBeanFactory的getBean() 方法的实现如下:
public Object getBean(String name) throws BeansException {
// 有三种情况会调用到这里
// 1. 容器启动的时候初始化A,所以调用到这里以进行A的初始化
// 2. 初始化A的时候要属性注入B,所以调用到这里以进行B的初始化
// 3. 初始化B的时候要属性注入A,所以调用到这里以获取A的bean
return doGetBean(name, null, null, false); // 最终会调用doGetBean()
}
基于上面的知识,我们开始解读整个循环依赖处理的过程,整个流程应该是以A的创建为起点,前文也说了,第一步就是创建A嘛!

创建A的过程实际上就是调用getBean方法,这个方法有两层含义:
- 创建一个新的Bean
- 从缓存中获取到已经被创建的对象
我们现在分析的是第一层含义,因为这个时候缓存中还没有A嘛!
下面我们来从源码的层面,梳理 Spring 解决 Bean 的循环依赖的整个流程。
4.1.1 创建A:调用doGetBean()
上面已经分析过了,创建A的流程从 AbstractApplicationContext 的 refresh() 方法出发,进入 finishBeanFactoryInitialization() 方法再进入 preInstantiateSingletons() 方法再进入 getBean() 方法再进入 doGetBean() 方法。
下面我们来看看 doGetBean() 方法:
AbstractBeanFactory.java
@SuppressWarnings("unchecked")
protected
String name, @Nullable Class
throws BeansException {
String beanName = transformedBeanName(name);
Object bean;
// Eagerly check singleton cache for manually registered singletons.
// 1、第一个getSingleton()方法,判断此时缓存中是否有想要获取的Bean了,如果有了直接从缓存中获取。如果没有则在后面的第二个调用的getSingleton()方法中去创建该Bean
Object sharedInstance = getSingleton(beanName);
if (sharedInstance != null && args == null) {
...
}
else {
// Fail if we're already creating this bean instance:
// We're assumably within a circular reference.
// 非单例bean是无法支持循环依赖的,所以这里判断是否是非单例bean的循环依赖场景,如果是则抛出异常
if (isPrototypeCurrentlyInCreation(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
// Check if bean definition exists in this factory.
BeanFactory parentBeanFactory = getParentBeanFactory();
if (parentBeanFactory != null && !containsBeanDefinition(beanName)) {
...
}
if (!typeCheckOnly) {
markBeanAsCreated(beanName);
}
try {
RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
...
}
// Create bean instance.
if (mbd.isSingleton()) {
// 2、第二个getSingleton()方法,当从三个缓存中都没有找到这个Bean的话,就会执行第二个getSingleton(),在getSingleton()方法中会去调用createBean() 创建一个 Bean 对象出来。
sharedInstance = getSingleton(beanName, () -> {
try {
// 在上面的getSingleton()方法中会调用到createBean()方法
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
.....
return (T) bean;
}
其中的第一个 getSingleton(beanName) 是判断 三个缓存 中是否有创建好的 Bean 对象,下面看它的源码。
4.1.1.1 调用getSingleton(beanName):调用的第一个名为getSingleton的方法,尝试从缓存中获取Bean
首先调用getSingleton(a)方法,这个方法又会调用getSingleton(beanName, true),在上图中我省略了这一步。
DefaultSingletonBeanRegistry.java
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
DefaultSingletonBeanRegistry.java
@Nullable
// allowEarlyReference表示是否允许提前引用,如果为true,那么在Bean创建过程中,就可以通过第三级缓存获取到该Bean,否则只能在Bean创建完成后才能获取到该Bean。这个参数的作用在后面会讲到。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 尝试从一级缓存singletonObjects中获取该Bean
Object singletonObject = this.singletonObjects.get(beanName);
// 如果一级缓存中没有该Bean,并且该Bean正在被创建(只要这个beanName在SingletonCurrentlyInCreation集合中,就表明这个Bean正在被创建)
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 如果一级缓存中没有该Bean,并且该Bean正在被创建,那么尝试从二级缓存earlySingletonObjects中获取该Bean
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果二级缓存中没有该Bean,并且当前允许Bean可以被提前引用(不用等Bean完全创建完成),那么尝试从三级缓存singletonFactories中获取该Bean
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 从三级缓存singletonFactories中获取该Bean的BeanFactory
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 通过三级缓存中这个Bean的工厂类来获取这个Bean的实例化对象(此时返回的只是完成实例化的Bean,并没有完成属性注入和初始化,所以并不是一个完整的Bean),具体的源码细节会在后面创建B类的时候讲解
singletonObject = singletonFactory.getObject();
// 通过singletonFactory工厂类获取到的bean添加到二级缓存中(如果这个Bean没有AOP增强,那么加入到二级缓存的就是这个Bean原始的实例化对象;如果这个Bean有AOP增强,那么工厂类返回的就是这个Bean的代理对象,就会将代理对象添加到二级缓存中)
this.earlySingletonObjects.put(beanName, singletonObject);
// 将三级缓存中这个Bean的工厂类移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
getSingleton(beanName, true)这个方法实际上就是到缓存中尝试去获取Bean,整个缓存分为三级(这三个缓存其实就相当于一个Map,key就是BeanName,value就是各自要存储的对象):
- singletonObjects,一级缓存,存储的是所有创建好了的单例Bean
- earlySingletonObjects,完成实例化,但是还未进行属性注入及初始化的对象
- singletonFactories,提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象
通过上面的源码可以看到这里分别去每一级的缓存中取数据,依次从第一级开始取数据,如果取得到则直接返回,取不到则往下一级查找,步骤如下:
- Spring首先从一级缓存singletonObjects中获取。
- 如果获取不到,并且对象正在创建中,就再从二级缓存earlySingletonObjects中获取。
- 如果还是获取不到且允许singletonFactories通过getObject()获取,就从三级缓存singletonFactory.getObject()(三级缓存)获取。
- 如果从三级缓存中获取后,就将这个Bean放入earlySingletonObjects中,并将这个singletonFactory从singletonFactories中移除。其实也就是从三级缓存移动到了二级缓存。
通过源码可以看到在第三级缓存中调用了 singletonFactories.get(beanName) 按照上文所说的会触发执行有 AOP 操作返回代理对象,没有AOP操作就直接返回原始对象,并且在这里会判断是否成功从三级缓存中取出了singletonFactory对象,如果成功获取则通过singletonFactory获取Bean,然后将这个半成品Bean添加到二级缓存中并删除三级缓存中这个Bean的singletonFactory数据。
从三级缓存的分析来看,Spring解决循环依赖的诀窍就在于singletonFactories这个第三级cache。这个cache的类型是ObjectFactory,定义如下:
/**
* 定义一个可以返回对象实例的工厂
* @param
*/
public interface ObjectFactory<T> {
T getObject() throws BeansException;
}
因为A是第一次被创建,所以不管哪个缓存中必然都是没有的,因此会进入getSingleton的另外一个重载方法getSingleton(beanName, singletonFactory)。第二个 getSingleton() 其实就是去执行传入的singletonFactory的lambda表达式中的 createBean() 来创建一个 Bean 对象出来。
4.1.1.2 调用getSingleton(beanName, singletonFactory):调用的第二个名为getSingleton的方法,去创建Bean
这个方法传入的ObjectFactory<?>实际是一个Lambdas表达式,所以调用传入参数singletonFactory的getObject() 方法,就会调用到createBean() 方法来创建Bean,创建好的Bean会加入到一级缓存中。其源码如下:
DefaultSingletonBeanRegistry.java
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(beanName, "Bean name must not be null");
synchronized (this.singletonObjects) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
// ....
// 省略异常处理及日志
// ....
// 在单例对象创建前先做一个标记
// 将beanName放入到singletonsCurrentlyInCreation这个集合中(这个集合相当于一个Set集合)
// 标志着这个单例Bean正在创建
// 如果同一个单例Bean多次被创建,这里会抛出异常
// 加入到这个集合的BeanName就表示这个Bean正在被创建,这一个标记很关键,后面还会用到
beforeSingletonCreation(beanName);
boolean newSingleton = false;
boolean recordSuppressedExceptions = (this.suppressedExceptions == null);
if (recordSuppressedExceptions) {
this.suppressedExceptions = new LinkedHashSet<>();
}
try {
// 上游传入的lambda(也就是一个工厂类singletonFactory)在这里会被执行,调用singletonFactory.getObject()方法会触发执行在lambda表达式中调用的createBean方法,去创建一个Bean后返回
// 此时这个Bean相当于通过createBean()方法被实例化出来了,实例化对象赋值给了singletonObject
// 这里得到的singletonObject就是初始化后得到的bean(或者代理bean)
singletonObject = singletonFactory.getObject();
newSingleton = true;
}
// ...
// 省略catch异常处理
// ...
finally {
if (recordSuppressedExceptions) {
this.suppressedExceptions = null;
}
// 创建完成后将对应的beanName从singletonsCurrentlyInCreation移除(表示这个Bean已经创建完成了,不再是创建中的状态了)
afterSingletonCreation(beanName);
}
if (newSingleton) {
// 创建好的Bean,会添加到一级缓存singletonObjects中,同时将这个Bean从二级缓存和三级缓存中移除。
addSingleton(beanName, singletonObject);
}
}
// 返回创建好的Bean
return singletonObject;
}
}
// 将完全创建好的Bean添加到一级缓存中
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
// 将完全创建完成的Bean添加到一级缓存中
this.singletonObjects.put(beanName, singletonObject);
// 将Bean从三级缓存中移除
this.singletonFactories.remove(beanName);
// 将Bean从二级缓存中移除
this.earlySingletonObjects.remove(beanName);
// 将完成创建的Bean添加到已注册的单例Bean集合中
this.registeredSingletons.add(beanName);
}
}
上面getSingleton()的代码我们主要抓住一点,通过createBean方法返回的创建完成的Bean最终通过addSingleton()方法添加到了一级缓存,也就是单例池中。
那么到这里我们可以得出一个结论:一级缓存中存储的是已经完全创建好了的单例Bean。
4.1.1.2.1 createBean()方法:创建Bean
我们再展开讲一下创建Bean的过程,创建Bean本质是通过执行 createBean() 方法中的 doCreateBean() 方法来创建的。源码如下:
AbstractAutowireCapableBeanFactory.java
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
if (logger.isTraceEnabled()) {
logger.trace("Creating instance of bean '" + beanName + "'");
}
// 拿到BeanDefinition(Bean定义)
RootBeanDefinition mbdToUse = mbd;
// Make sure bean class is actually resolved at this point, and
// clone the bean definition in case of a dynamically resolved Class
// which cannot be stored in the shared merged bean definition.
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// Prepare method overrides.
try {
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// Give BeanPostProcessors a chance to return a proxy instead of the target bean instance.
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
try {
// 通过调用doCreateBean()来创建完整的Bean
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isTraceEnabled()) {
logger.trace("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
catch (BeanCreationException | ImplicitlyAppearedSingletonException ex) {
// A previously detected exception with proper bean creation context already,
// or illegal singleton state to be communicated up to DefaultSingletonBeanRegistry.
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation", ex);
}
}
AbstractAutowireCapableBeanFactory.java
/**
* 实际创建指定的bean的方法。 这个方法完成了 1、Bean的实例化 2、Bean的属性注入 3、Bean的初始化
* 此时,预创建处理已经发生,
* 例如 检查{@code postProcessBeforeInstantiation}回调。
* 区分默认bean实例化、使用工厂方法和自动装配构造函数。
*/
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args) {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
.....
if (instanceWrapper == null) {
// 1、实例化Bean,生成的对象被称为原始对象
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 这里的bean就是A或者B的原始对象,此时没有被属性注入,也没有执行初始化逻辑
Object bean = instanceWrapper.getWrappedInstance();
.....
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
// A是单例的,mbd.isSingleton()条件满足
// allowCircularReferences:这个变量代表是否允许循环依赖,默认是开启的,条件也满足
// isSingletonCurrentlyInCreation:正在在创建A,也满足
// 所以earlySingletonExposure=true
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 将创建的BeanFactory添加到三级缓存中。注意此时Bean并没有彻底创建完成,此时只进行了实例化,Bean还是一个半成品
addSingletonFactory(beanName, new ObjectFactory<Object>() {
// ObjectFactory的getObejct()方法实际就会调用到getEarlyBeanReference()方法
// 如果需要动态代理,getEarlyBeanReference()方法会返回原始对象的代理对象
// 如果不需要动态代理,getEarlyBeanReference()方法会返回原始对象
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
// 2、Bean的属性注入
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null) {
// 3、Bean的初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
......
// 返回创建完成的Bean
return exposedObject;
}
注:createBeanInstance(...)该步骤会调用构造方法,来实例化Bean
AbstractAutowireCapableBeanFactory.java
/**
* 使用适当的实例化策略为指定的bean创建一个新实例:
* 工厂方法,构造函数自动装配或简单实例化。
* @return BeanWrapper for the new instance
*/
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, Object[] args) {
.......
// Need to determine the constructor...(确定构造函数)
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
return autowireConstructor(beanName, mbd, ctors, args);
}
// No special handling: simply use no-arg constructor.(使用默认无参构造器,
// 编程时候要求尽量保留无参构造器,因为你不知道哪个框架在哪会用到)
return instantiateBean(beanName, mbd);
}
至于其他的属性注入populateBean()和初始化initializeBean()的源码分析,在之前的IOC笔记中已经讲过了,这里就不再赘述了。
在populateBean()属性注入这一步里,进入到给A注入B的流程。
4.1.1.2.1.1 调用addSingletonFactory方法:这个方法就是解决循环依赖问题的关键
调用位置如下图所示:
AbstractAutowireCapableBeanFactory..doCreateBean()

在完成Bean的实例化后,属性注入之前Spring将Bean包装成一个工厂添加进了三级缓存中,对应源码如下:
DefaultSingletonBeanRegistry.java
/**
* 添加一个构建指定单例对象的单例工厂
* 紧急注册单例对象,用于解决解决循环依赖问题
* To be called for eager registration of singletons, e.g. to be able to
* resolve circular references.
*/
// 这里传入的参数也是一个lambda表达式,() -> getEarlyBeanReference(beanName, mbd, bean)
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
// 如果在一级缓存中不存在这个Bean,那么就添加到三级缓存中
if (!this.singletonObjects.containsKey(beanName)) {
// 添加到三级缓存中
this.singletonFactories.put(beanName, singletonFactory);
// 从二级缓存中移除
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
通过这个代码的注释我们就能知道,第三级缓存就是坚决循环依赖问题的关键,而这个方法也是解决循环依赖的关键所在,这段代码发生在doCreateBean(...) 方法中 createBeanInstance之后,也就是说单例对象此时已经被实例化出来了(调用了构造器)。这个对象已经被生产出来了,虽然还不完美(还没有进行创建Bean的第二步和第三步),但是已经能被人认出来了(根据对象引用能定位到堆中的对象),所以Spring此时将这个对象提前曝光出来让大家认识,让大家使用。
这样做有什么好处呢?让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了创建的第一步(完成实例化),并且将自己提前曝光到singletonFactories中,此时进行创建的第二步(属性注入),发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create(B)的流程,B在创建第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了创建的阶段1、2、3,B完成创建后之后将自己放入到一级缓存singletonObjects中。此时返回A的创建流程中,A此时能拿到B的对象顺利完成自己的创建阶段2、3,最终A也完成了创建,将创建好的A添加到一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在持有的A对象也完成了创建。(简单来说,就是spring创造了一个循环依赖的结束点标识)
再回到这个方法源码本身,这个方法只是添加了一个工厂,在创建A的流程中执行到这个方法时,A只是完成了实例化,还没有完成属性注入和初始化。上面的文字也讲了B通过这个工厂(ObjectFactory)的getObject方法可以得到A对象,而这个A对象实际上就是通过getObject方法中再去调用getEarlyBeanReference这个方法创获取的。既然singletonFactory.getObject()方法是在创建B的流程中调用的,下面我们就再进入到创建B的流程中进行讲解。
4.1.2 创建B
当A完成了实例化并添加进了三级缓存后,就要通过方法populateBean()开始为A进行属性注入了,在注入时发现A依赖了B,那么这个时候Spring又会去getBean(b),然后反射调用setter方法完成属性注入。
流程图如下:

4.1.2.1 调用第一个getSingleton()方法实现对B注入A
因为B需要注入A,所以在创建B的时候,又会去调用getBean(a),这个时候就又回到之前的流程了,但是不同的是,之前的getBean是为了创建Bean,而此时再调用getBean不是为了创建了,而是要从缓存中获取,因为之前A在实例化后已经将其放入了三级缓存singletonFactories中,所以此时getBean(a)的流程就是这样子了:
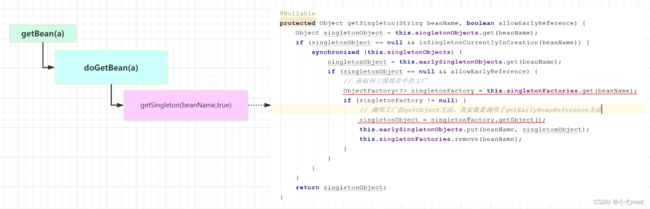
上面执行的就是其实就是第一个getSingleton()方法,因为A此时并不在一级和二级缓存中,而是在三级缓存中,所以最终会从三级缓存中获取A,来将A注入给B。
@Nullable
// allowEarlyReference表示是否允许提前引用,如果为true,那么在Bean创建过程中,就可以通过getBean()方法获取到该Bean,否则只能在Bean创建完成后才能获取到该Bean
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 尝试从一级缓存singletonObjects中获取该Bean
Object singletonObject = this.singletonObjects.get(beanName);
// 如果一级缓存中没有该Bean,并且该Bean正在被创建(只要这个beanName在SingletonCurrentlyInCreation集合中,就表明这个Bean正在被创建)
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 如果一级缓存中没有该Bean,并且该Bean正在被创建,那么尝试从二级缓存earlySingletonObjects中获取该Bean
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果二级缓存中没有该Bean,并且当前允许Bean可以被提前引用(不用等Bean完全创建完成),那么尝试从三级缓存singletonFactories中获取该Bean
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
// 从三级缓存singletonFactories中获取该Bean的BeanFactory
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 调用工厂的getObject方法,其实本质调用的就是从上游lambda表达式传入的getEarlyBeanReference()方法
singletonObject = singletonFactory.getObject();
// 通过singletonFactory工厂类获取到的bean添加到二级缓存中(如果这个Bean没有AOP增强,那么加入到二级缓存的就是这个Bean原始的实例化对象;如果这个Bean有AOP增强,那么工厂类返回的就是这个Bean的代理对象,就会将代理对象添加到二级缓存中)
this.earlySingletonObjects.put(beanName, singletonObject);
// 将三级缓存中这个Bean的工厂类移除
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
4.1.2.1.1 调用getEarlyBeanReference()方法:用来从singletonFactory工厂类中返回Bean
从上面的源码我们可以看出,注入到B中的A是通过getEarlyBeanReference方法提前暴露出去的一个对象,还不是一个完整的Bean,那么getEarlyBeanReference到底干了啥了,我们看下它的源码:
// 这个方法名字其实就告诉了我们它的作用了,得到一个比较早的Bean引用(还没有完全创建好的Bean,仅仅只是完成了实例化的Bean,还没有完成属性注入和初始化)
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// AOP增强操作
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
它实际上就是调用了后置处理器的getEarlyBeanReference,而真正实现了这个方法的后置处理器只有一个,就是通过@EnableAspectJAutoProxy注解导入的AnnotationAwareAspectJAutoProxyCreator。也就是说如果在不考虑AOP的情况下,上面的代码等价于:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// 相当于直接返回了原始Bean,并没有进行AOP增强
return exposedObject;
}
也就是说这个工厂啥都没干,直接将之前实例化阶段创建的对象A返回了!所以说在不考虑AOP的情况下三级缓存有用嘛?讲道理,真的没什么用,我直接将这个对象放到二级缓存中不是一点问题都没有吗?所以三级缓存并没有提高任何效率。
那么三级缓存到底有什么作用呢?不要急,我们先把整个流程走完,在下文结合AOP分析循环依赖的时候你就能体会到三级缓存的作用!
4.1.3 创建A和B的流程总结
到这里不知道小伙伴们会不会有疑问,B中提前注入了一个没有经过初始化的A类型对象不会有问题吗?
答:不会,因为其实B中注入了A的引用,在后面A彻底完成创建之后,A的引用并不会变,所以B最终会得到一个完整的A。
这个时候我们将整个创建A这个Bean的流程总结一下,如下图:
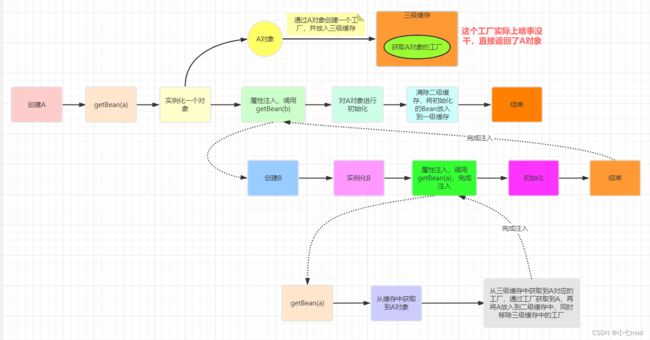
从上图中我们可以看到,虽然在创建B时会提前给B注入了一个还未初始化的A对象,但是在创建A的流程中一直使用的是注入到B中的A对象的引用,之后会根据这个引用对A进行初始化,所以这是没有问题的。
4.2 结合了AOP的循环依赖
之前我们已经说过了,在普通的循环依赖的情况下,三级缓存没有任何作用。三级缓存实际上跟Spring中的AOP相关,我们再来看一看getEarlyBeanReference的代码:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
// 如果不是合成的bean,且有实例化后置处理器,就说明这个Bean有AOP代理增强操作,需要提前暴露出来
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
// 进到这个if分支,说明开启了AOP功能,且当前Bean有实例化后置处理器
// 遍历当前Bean的所有实例化后置处理器
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// 如果当前实例化后置处理器是SmartInstantiationAwareBeanPostProcessor类型的,则调用getEarlyBeanReference方法获取代理增强后的Bean
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
// 调用SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference方法,获取代理增强后的Bean。调用的AnnotationAwareAspectJAutoProxyCreator的getEarlyBeanReference方法
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
如果在开启AOP的情况下,那么就是调用到AnnotationAwareAspectJAutoProxyCreator(SmartInstantiationAwareBeanPostProcessor 的实现类)的getEarlyBeanReference方法,对应的源码如下:
public Object getEarlyBeanReference(Object bean, String beanName) {
Object cacheKey = getCacheKey(bean.getClass(), beanName);
// earlyProxyReferences 存储的是 (beanName, bean) 键值对,这里的 bean 指的是原始对象(刚实例化后的对象)
this.earlyProxyReferences.put(cacheKey, bean);
// wrapIfNecessary() 方法用于执行 AOP 操作,生成一个代理对象(也就是说如果有 AOP 操作最后返回的是代理对象,否则返回的还是原始对象)。
return wrapIfNecessary(bean, beanName, cacheKey);
}
回到上面的例子,我们对A进行了AOP代理的话,那么此时getEarlyBeanReference将返回一个代理后的对象,而不是实例化阶段创建的对象,这样就意味着B中注入的A将是一个代理对象而不是A的实例化阶段创建后的对象。
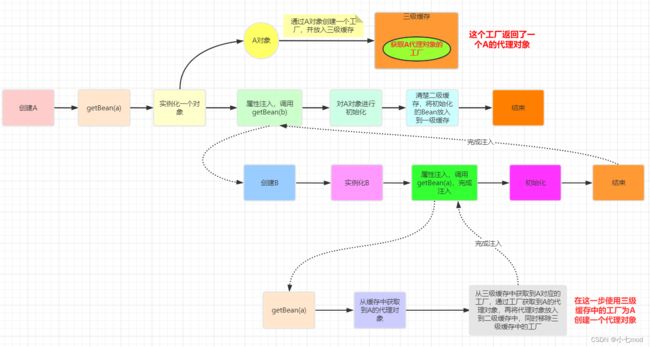
看到这个图你可能会产生下面这些疑问:
1、在给B注入的时候为什么要注入一个代理对象?
答:当我们对A进行了AOP代理时,说明我们希望从容器中获取到的就是A代理后的对象而不是A本身,因此把A当作依赖进行注入时也要注入它的代理对象。
2、明明在创建A的时候,到初始化这一步完成的时候仍然还是原始的A对象,那么如果对A有AOP增强的话,为什么最终在Spring容器中取出的A是代理增强的对象呢?Spring是在什么时候将代理对象放入到容器中的呢?
由上图可见,创建A的流程中,在完成对A的初始化后,此时仍然还是原始的A对象。我们知道在A实例化之后,会将A的BeanFactory加入到第三级缓存中,这个BeanFactory可以返回AOP代理增强之后的A对象,但是此时在创建A的流程中,一直操作的是A的原始对象,并没有通过BeanFactory获取A的代理增强对象。只不过是在创建A所依赖的B时,因为B也同样依赖A,而根据自然顺序(按照BeanName的字典序)B在A之后创建,所以在对B注入A的时候三级缓存中已经存在了A的BeanFactory,所以B注入的A是通过BeanFactory返回的A的代理增强后的对象。但是针对A本身的创建流程来说,在A初始化后,操作的仍然是A的原始对象。
那么问题来了,在我们最终通过Spring容器获取A对象的时候一定是代理增强之后的A对象,那么究竟是什么时候Spring将A的代理对象加入到容器中的呢?我们还是要通过源码来找到答案。
我们回到创建A的流程,定位到doCreateBean()方法,我们看当完成对A的初始化之后,后面又再一次调用了上面讲的第一个getSingleton()方法,这个方法是尝试从缓存中获取Bean。这里相当于通过getSingleton(A)从缓存中获取A。
/**
* 实际创建指定的bean的方法。 这个方法完成了 1、Bean的实例化 2、Bean的属性注入 3、Bean的初始化
* 此时,预创建处理已经发生,
* 例如 检查{@code postProcessBeforeInstantiation}回调。
* 区分默认bean实例化、使用工厂方法和自动装配构造函数。
*/
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args) {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
.....
if (instanceWrapper == null) {
// 1、实例化Bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
.....
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 将创建的BeanFactory添加到三级缓存中。注意此时Bean并没有彻底创建完成,此时只进行了实例化,Bean还是一个半成品
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
// 2、Bean的属性注入
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null) {
// 3、Bean的初始化
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
......
// exposedObject就是最终创建完成的Bean
if (earlySingletonExposure) {
// 在完成了Bean的初始化后,再一次调用了上面讲过的第一个getSingleton()方法,区别就是这次传入的第二个参数是false
// 这次调用实现了从二级缓存中获取到代理后的Bean
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
// 将最终完成的Bean替换成了代理对象,在上游方法中向后执行addSingleton()方法时会将代理对象添加到一级缓存中
exposedObject = earlySingletonReference;
}
...
}
}
......
// 返回最终创建完成的Bean
return exposedObject;
}
由源码可知Spring又调用了一次getSingleton方法,但这一次传入的参数又不一样了,第二个参数传入的是false,false可以理解为禁用第三级缓存,前面图中已经提到过了,在为B中注入A后,就将A的BeanFactory返回的代理对象加到了二级缓存中,并就将A的BeanFactory从三级缓存中的移除。此时A的BeanFactory已经不在三级缓存中了,并且在本次调用getSingleton方法是传入的参数已经保证了禁用第三级缓存了,所以这里的这个getSingleton方法做的实际就是从二级缓存中获取到这个代理后的A对象。exposedObject == bean可以认为是一定成立的,除非你非要在初始化阶段的后置处理器中替换掉正常流程中的Bean,例如增加一个后置处理器:
@Component
public class MyPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("a")) {
// 换成别的Bean
return new A();
}
return bean;
}
}
不过,请不要做这种骚操作,徒增烦恼!
至此,在A的创建流程中,就已经将原始Bean换成了经过AOP增强的Bean了。在前面讲过的创建A的流程中addSingleton()方法中,也就将这个彻底创建完成的代理增强的Bean加入到了一级缓存中,并且在最后返回给了Spring容器。
3、初始化的时候是对A对象本身进行初始化(初始化之前也都是对原始A对象进行的处理),而添加到Spring容器中以及注入到B中的都是代理对象,这样不会有问题吗?
答:不会,这是因为不管是cglib代理还是jdk动态代理生成的代理类,内部都持有一个目标类的引用,当调用代理对象的方法时,实际会去调用目标对象的方法,A原始类完成初始化相当于代理对象自身也完成了初始化。
4、三级缓存为什么要使用工厂而不是直接使用引用?换而言之,为什么需要这个三级缓存,直接通过二级缓存暴露一个引用不行吗?
答:这个工厂的目的在于延迟对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象。
我们思考一种简单的情况,就以单独创建A为例,假设AB之间现在没有依赖关系,但是A被代理了,这个时候创建A会进入到doCreateBean()方法中,当A完成实例化后还是会继续向下执行这段代码:
AbstractAutowireCapableBeanFactory..doCreateBean()
......
// A是单例的,mbd.isSingleton()条件满足
// allowCircularReferences:这个变量代表是否允许循环依赖,默认是开启的,条件也满足
// isSingletonCurrentlyInCreation:正在在创建A,也满足
// 所以earlySingletonExposure=true
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
// 还是会进入到这段代码中
if (earlySingletonExposure) {
// 还是会通过三级缓存提前暴露一个工厂对象
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
......
通过源码我们就能发现,即使没有循环依赖,也会将其添加到三级缓存中,而且是不得不添加到三级缓存中,因为到目前为止还没有到对A进行属性注入的阶段,Spring也不能确定这个Bean有没有跟别的Bean出现循环依赖。
假设我们在这里直接使用二级缓存的话,那么意味着所有的Bean在这一步都要完成AOP代理。这样做有必要吗?
不仅没有必要,而且违背了Spring在结合AOP和Bean的生命周期的设计原则!Spring结合AOP和Bean的生命周期本身就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的(上面讲过的返回AOP代理的getEarlyBeanReference()方法就是这个后置处理器提供的),在这个后置处理器的postProcessAfterInitialization方法会在初始化后被调用,完成对Bean的AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理;但是没有出现循环依赖的情况下,Spring的源码设计就是在Bean完成初始化之后,调用执行postProcessAfterInitialization方法完成AOP代理,也就是在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。所以如果只使用二级缓存的话,那么完成代理的步骤就会被提到实例化之后了,和Spring的底层源码流程不符。在下一节我们会展示使用三级缓存和使用二级缓存的Bean创建流程的差异,就能很直观地看出来了。
4.3 Spring 解决 Bean 的循环依赖的流程总结
还是以 AService 和 BService 的循环依赖为例,我们来总结一下 Spring 是如何解决 Bean 的循环依赖问题。
梳理整个流程:
- 首先会获取 AService 对应的 Bean 对象。
- 先是调用 doGetBean() 中的第一个 getSingleton(beanName) 判断是否有该 Bean 的实例,有就直接返回了。(显然这里没有)
- 然后调用 doGetBean() 中的第二个 getSingleton() 方法来执行 doCreateBean() 方法。
- 先进行实例化操作(也就是利用构造函数实例化),此时实例化后生成的是原始对象。
- 将原始对象通过 lambda表达式 进行封装成 ObjectFactory 对象,通过 addSingletonFactory 加入三级缓存中。
- 然后再进行属性注入,此时发现需要注入 BService 的 Bean,会通过 doGetBean() 去获取 BService 对应的 Bean。
- 同样调用 doGetBean() 中的第一个 getSingleton(beanName) 判断是否有该 Bean 的实例,显然这里也是不会有 BService 的 Bean 的。
- 然后只能调用 doGetBean() 中的第二个 getSingleton() 方法来执行 doCreateBean() 方法来创建一个 BService 的 Bean。
- 同样地先进行实例化操作,生成原始对象后封装成 ObjectFactory 对象放入三级缓存中。
- 然后进行属性注入,此时发现需要注入 AService 的 Bean,此时调用调用 doGetBean() 中的第一个 getSingleton(beanName) 查找是否有 AService 的 Bean。此时会触发三级缓存,也就是调用 singletonFactories.get(beanName)。
- 因为三级缓存中有 AService 的原始对象封装的 ObjectFactory 对象,所以可以获取到的代理对象或原始对象,并且上移到二级缓存中,提前暴露给 BService 调用。
- 所以 BService 可以完成属性注入,然后进行初始化后,将 Bean 放入一级缓存,这样 AService 也可以完成创建。
以上就是 Spring 解决 Bean 的循环依赖问题的整个流程了。
带着调用方法的流程图:

4.4 三级缓存真的提高了效率了吗?
现在我们已经知道了第三级缓存的真正作用,但是这个答案可能还无法说服你,所以我们再最后总结分析一波,三级缓存真的提高了效率了吗?分为两点讨论:
- 没有进行AOP的Bean间的循环依赖
从上文分析可以看出,这种情况下第三级缓存根本没用!所以不会存在什么提高了效率的说法
- 进行了AOP的Bean间的循环依赖
就以我们上的A、B为例,其中A被AOP代理,我们先分析下使用了第三级缓存的情况下,A、B的创建流程

假设不使用第三级缓存,直接将代理对象放到二级缓存中

上面两个流程的唯一区别在于为A对象创建代理的时机不同,在使用了三级缓存的情况下为A创建代理的时机是在B中需要注入A的时候,而不使用三级缓存的话在A实例化后就需要马上为A创建代理然后放入到二级缓存中去。对于整个A、B的创建过程而言,消耗的时间是一样的
综上,不管是哪种情况,三级缓存提高了效率这种说法都是错误的!
五、循环依赖问题的解决方案
解决循环依赖问题有一些比较常用的解决方案,下面来依次讲解。
5.1 重新设计
当你面临一个循环依赖问题时,有可能是你对JavaBean的设计有问题,没有将各自的依赖做到很好的分离。你应该尽量正确地重新设计JavaBean,以保证它们的层次是精心设计的,避免没有必要的循环依赖。
如果不能重新设计组件(可能有很多的原因:遗留代码,已经被测试并不能修改代码,没有足够的时间或资源来完全重新设计......),但有一些变通方法可以解决这个问题。
5.2 使用 Setter/Field 注入
最流行的解决循环依赖的方法,就是Spring文档中建议的,设计Bean的时候都使用setter注入。简单地说,你对你须要注入的bean是使用setter注入(或字段注入),而不是构造函数注入。通过这种注入方式产生循环依赖的Bean,Spring框架自身就能解决,也就是上面我们用了这么大篇幅讲解的内容。
5.3 使用@Lazy注解
如果产生循环依赖的Bean,都是通过构造方法来注入彼此的,那么这种情况是没有办法通过Spring框架自身来解决的。
解决这种情况的一个简单方法就是对一个Bean使用延时加载。也就是说:通过在构造器参数中标识@Lazy注解,Spring 生成并返回了一个代理对象,因此给CircularDependencyA注入的CircularDependencyB并非真实对象而是其代理。
举一个具体的例子:
@Component
public class CircularDependencyA {
private CircularDependencyB circB;
@Autowired
public CircularDependencyA(CircularDependencyB circB) {
this.circB = circB;
}
}
@Component
public class CircularDependencyB {
private CircularDependencyA circA;
@Autowired
public CircularDependencyB(CircularDependencyA circA) {
this.circA = circA;
}
}
我们对CircularDependencyA 进行修改,结果如下:
@Component
public class CircularDependencyA {
private CircularDependencyB circB;
@Autowired
// 对传入的B实行延迟加载,即可解决循环依赖的问题
public CircularDependencyA(@Lazy CircularDependencyB circB) {
this.circB = circB;
}
}
如果你现在运行测试,你会发现之前的循环依赖错误不存在了。
结论:
Spring构造器注入循环依赖的解决方案是@Lazy,其基本思路是:对于强依赖的对象,一开始并不注入对象本身,而是注入其代理对象,以便顺利完成实例的构造,形成一个完整的对象,这样与其它应用层对象就不会形成互相依赖的关系;当需要调用真实对象的方法时,通过TargetSource去拿到真实的对象(DefaultListableBeanFactory#doResolveDependency),然后通过反射完成调用
5.4 使用 @PostConstruct注解
打破循环的另一种方式是,在要注入的属性(该属性是一个bean)上使用 @Autowired,并使用@PostConstruct 标注在另一个方法,且该方法里设置对其他的依赖。
我们的Bean将修改成下面的代码:
@Component
public class CircularDependencyA {
@Autowired
private CircularDependencyB circB;
// A的构造方法完成后执行
@PostConstruct
public void init() {
// 通过setter给B注入A
circB.setCircA(this);
}
public CircularDependencyB getCircB() {
return circB;
}
}
@Component
public class CircularDependencyB {
private CircularDependencyA circA;
private String message = "Hi!";
public void setCircA(CircularDependencyA circA) {
this.circA = circA;
}
public String getMessage() {
return message;
}
}
现在我们运行我们修改后的代码,发现并没有抛出异常,并且依赖正确注入进来。
5.5 实现ApplicationContextAware 和 InitializingBean接口
如果一个Bean实现了ApplicationContextAware,该Bean可以访问Spring上下文,并可以从那里获取到其他的bean。实现InitializingBean接口,表明这个bean在所有的属性设置完后做一些后置处理操作(调用的顺序为init-method后调用)。在这种情况下,我们需要手动设置依赖。
@Component
public class CircularDependencyA implements ApplicationContextAware, InitializingBean {
private CircularDependencyB circB;
private ApplicationContext context;
public CircularDependencyB getCircB() {
return circB;
}
@Override
public void afterPropertiesSet() throws Exception {
circB = context.getBean(CircularDependencyB.class);
}
@Override
public void setApplicationContext(final ApplicationContext ctx) throws BeansException {
context = ctx;
}
}
public class CircularDependencyB {
private CircularDependencyA circA;
private String message = "Hi!";
@Autowired
public void setCircA(CircularDependencyA circA) {
this.circA = circA;
}
public String getMessage() {
return message;
}
}
同样,发现没有异常抛出,程序结果是我们所期望的那样。
5.6 思考题:为什么在下表中的第三种情况的循环依赖能被解决,而第四种情况不能被解决呢?
提示:Spring在创建Bean时默认会根据自然排序进行创建,所以A会先于B进行创建
| 依赖情况 |
依赖注入方式 |
循环依赖是否被解决 |
| AB相互依赖(循环依赖) |
均采用setter方法注入 |
是 |
| AB相互依赖(循环依赖) |
均采用构造器注入 |
否 |
| AB相互依赖(循环依赖) |
A中注入B的方式为setter方法,B中注入A的方式为构造器 |
是 |
| AB相互依赖(循环依赖) |
B中注入A的方式为setter方法,A中注入B的方式为构造器 |
否 |
其实这个原因很好理解。通过上面对Spring解决循环依赖问题原理的讲解,我们已经对它底层代码有了一定了解。我们再拿过来这个流程图,对着图来进行讲解:

第三种情况
第三种情况的循环依赖是可以被Spring自身解决的。我们按照上面的流程图梳理一下就能明白了。
Spring根据beanName字典序来进行创建,所以先创建A。A是通过setter方法注入B的,所以A可以正常执行完createBeanInstance()方法完成实例化,在执行完实例化方法之后,就会执行addSingletonFactory()方法来讲A的beanFactory加入到第三级缓存中,在后面对A进行属性注入时,发现它依赖了B,就进入到了创建B的流程,而B也依赖了A,是通过构造方法注入的A,所以B在执行到实例化阶段时候,在构造方法中就开始尝试注入A了,会通过前面已经加入到第三级缓存的beanFactory来获取到A,注入给B,所以B就顺利注入了A,完成了整个创建过程。然后A也就能顺利注入B,最终完成了创建过程。至此,A和B都完成了创建。
第四种情况
这个情况的循环依赖是没办法通过Spring自身解决的。
依然是先创建A,但是A是通过构造方法注入的B,也就是说A在注入B的时候,仍然还在实例化阶段,实例化方法还没有执行完。通过上面我们知道,将A的beanFactory加入到三级缓存的addSingletonFactory()方法是在完成实例化方法createBeanInstance()之后执行的,但是此时仍然在实例化的过程中,三级缓存中还没有A的beanFactory,这个时候就去注入B,在进入到创建B的流程中时,又会对B来注入A,但此时三级缓存中获取不到对应的beanFactory,也就无法得到A,无法完成对B的创建,后续的流程也就无法推进下去,这样就直接报错循环依赖问题了。
六、什么样的循环依赖无法处理?
1、因为加入singletonFactories三级缓存的前提是执行了构造器来创建半成品的对象,所以构造器的循环依赖没法解决(指的是没办法通过Spring自身解决,但是可以通过程序员自己使用@Lazy注解来解决)。因此Spring不能解决“A的构造方法中依赖了B的实例对象,同时B的构造方法中依赖了A的实例对象”这类问题了!
2、spring不支持原型(prototype)bean属性注入循环依赖,不同于构造器注入循环依赖会在创建spring容器context时报错,它会在用户执行代码如context.getBean()时抛出异常。因为对于原型bean,spring容器会在每一次使用它的时候创建一个全新的Bean。
因为spring容器不缓存prototype类型的bean,使得无法提前暴露出一个创建中的bean。spring容器在获取prototype类型的bean时,如果因为循环依赖的存在,检测到当前线程已经正在处理该bean时,就会抛出异常。核心代码:
public abstract class AbstractBeanFactory{
/** Names of beans that are currently in creation */
private final ThreadLocal<Object> prototypesCurrentlyInCreation =
new NamedThreadLocal<>("Prototype beans currently in creation");
protected boolean isPrototypeCurrentlyInCreation(String beanName) {
Object curVal = this.prototypesCurrentlyInCreation.get();
// 如果beanName已经存在于正在处理中的prototype类型的bean集中,后面会抛出异常
return (curVal != null &&
(curVal.equals(beanName) || (curVal instanceof Set && ((Set<?>) curVal).contains(beanName))));
}
}
七、面试题
7.1 Spring是如何解决的循环依赖?
答:Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么通过这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
简单点说,Spring解决循环依赖的思路就是:当A的bean需要B的bean的时候,提前将A的bean放在缓存中(实际是将A的ObjectFactory放到三级缓存),然后再去创建B的bean,但是B的bean也需要A的bean,那么这个时候就去缓存中拿A的bean,B的bean创建完毕后,再回来继续创建A的bean,最终完成循环依赖的解决。Spring 利用 三级缓存 巧妙地将出现 循环依赖 时的 AOP 操作 提前到了 属性注入 之前(通过第三级缓存实现的),解决了循环依赖问题。
7.2 为什么不直接使用一级缓存来解决循环依赖
答:一级缓存中预期存放的是一个正常完整的bean,而如果只用一级缓存来解决循环依赖,那么一级缓存中会在某个时间段存在不完整的bean,这是不安全的。
7.3 为什么要使用三级缓存呢?直接使用一级缓存和二级缓存能解决循环依赖吗?
答:这个问题需要结合为什么引入三级缓存来分析。引用前面的论述,使用一级缓存和二级缓存确实可以解决循环依赖,但是这要求每个原始对象创建出来后就立即生成动态代理对象(如果有的AOP代理增强话),然后将这个动态代理对象放入二级缓存,这就打破了Spring对AOP的设计原则,即:在对象初始化完毕后,再去创建代理对象。所以引入三级缓存,并且在三级缓存中存放一个对象的ObjectFactory,目的就是:延迟代理对象的创建,这里延迟到啥时候创建呢,有两种情况:第一种就是确实存在循环依赖,那么没办法,只能在需要的时候就创建出来代理对象然后放到二级缓存中,第二种就是不存在循环依赖,那就应该正常地在初始化的后置处理器中创建。
因此不直接使用一级缓存和二级缓存来解决循环依赖的原因就是:希望在不存在循环依赖的情况下不破坏Spring对AOP的设计原则。
所以总结来说,如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。
参考资料:https://www.cnblogs.com/daimzh/p/13256413.html#!comments