kind: ConfigMap
apiVersion: v1
metadata:
name: fluentd-es-config-v0.2.0
namespace: default
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
system.conf: |-
root_dir /tmp/fluentd-buffers/
containers.input.conf: |-
# This configuration file for Fluentd / td-agent is used
# to watch changes to Docker log files. The kubelet creates symlinks that
# capture the pod name, namespace, container name & Docker container ID
# to the docker logs for pods in the /var/log/containers directory on the host.
# If running this fluentd configuration in a Docker container, the /var/log
# directory should be mounted in the container.
#
# These logs are then submitted to Elasticsearch which assumes the
# installation of the fluent-plugin-elasticsearch & the
# fluent-plugin-kubernetes_metadata_filter plugins.
# See https://github.com/uken/fluent-plugin-elasticsearch &
# https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter for
# more information about the plugins.
#
# Example
# =======
# A line in the Docker log file might look like this JSON:
#
# {"log":"2014/09/25 21:15:03 Got request with path wombat\n",
# "stream":"stderr",
# "time":"2014-09-25T21:15:03.499185026Z"}
#
# The time_format specification below makes sure we properly
# parse the time format produced by Docker. This will be
# submitted to Elasticsearch and should appear like:
# $ curl 'http://elasticsearch-logging:9200/_search?pretty'
# ...
# {
# "_index" : "logstash-2014.09.25",
# "_type" : "fluentd",
# "_id" : "VBrbor2QTuGpsQyTCdfzqA",
# "_score" : 1.0,
# "_source":{"log":"2014/09/25 22:45:50 Got request with path wombat\n",
# "stream":"stderr","tag":"docker.container.all",
# "@timestamp":"2014-09-25T22:45:50+00:00"}
# },
# ...
#
# The Kubernetes fluentd plugin is used to write the Kubernetes metadata to the log
# record & add labels to the log record if properly configured. This enables users
# to filter & search logs on any metadata.
# For example a Docker container's logs might be in the directory:
#
# /var/lib/docker/containers/997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b
#
# and in the file:
#
# 997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b-json.log
#
# where 997599971ee6... is the Docker ID of the running container.
# The Kubernetes kubelet makes a symbolic link to this file on the host machine
# in the /var/log/containers directory which includes the pod name and the Kubernetes
# container name:
#
# synthetic-logger-0.25lps-pod_default_synth-lgr-997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b.log
# ->
# /var/lib/docker/containers/997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b/997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b-json.log
#
# The /var/log directory on the host is mapped to the /var/log directory in the container
# running this instance of Fluentd and we end up collecting the file:
#
# /var/log/containers/synthetic-logger-0.25lps-pod_default_synth-lgr-997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b.log
#
# This results in the tag:
#
# var.log.containers.synthetic-logger-0.25lps-pod_default_synth-lgr-997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b.log
#
# The Kubernetes fluentd plugin is used to extract the namespace, pod name & container name
# which are added to the log message as a kubernetes field object & the Docker container ID
# is also added under the docker field object.
# The final tag is:
#
# kubernetes.var.log.containers.synthetic-logger-0.25lps-pod_default_synth-lgr-997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b.log
#
# And the final log record look like:
#
# {
# "log":"2014/09/25 21:15:03 Got request with path wombat\n",
# "stream":"stderr",
# "time":"2014-09-25T21:15:03.499185026Z",
# "kubernetes": {
# "namespace": "default",
# "pod_name": "synthetic-logger-0.25lps-pod",
# "container_name": "synth-lgr"
# },
# "docker": {
# "container_id": "997599971ee6366d4a5920d25b79286ad45ff37a74494f262e3bc98d909d0a7b"
# }
# }
#
# This makes it easier for users to search for logs by pod name or by
# the name of the Kubernetes container regardless of how many times the
# Kubernetes pod has been restarted (resulting in a several Docker container IDs).
# Json Log Example:
# {"log":"[info:2016-02-16T16:04:05.930-08:00] Some log text here\n","stream":"stdout","time":"2016-02-17T00:04:05.931087621Z"}
# CRI Log Example:
# 2016-02-17T00:04:05.931087621Z stdout F [info:2016-02-16T16:04:05.930-08:00] Some log text here
@id fluentd-containers.log
@type tail
path /var/log/containers/*.log
pos_file /var/log/es-containers.log.pos
tag raw.kubernetes.*
read_from_head true
@type multi_format
format json
time_key time
time_format %Y-%m-%dT%H:%M:%S.%NZ
format /^(?
# Detect exceptions in the log output and forward them as one log entry.
@id raw.kubernetes
@type detect_exceptions
remove_tag_prefix raw
message log
stream stream
multiline_flush_interval 5
max_bytes 500000
max_lines 1000
# Concatenate multi-line logs
@id filter_concat
@type concat
key message
multiline_end_regexp /\n$/
separator ""
# Enriches records with Kubernetes metadata
@id filter_kubernetes_metadata
@type kubernetes_metadata
# Fixes json fields in Elasticsearch
@id filter_parser
@type parser
key_name log
reserve_data true
remove_key_name_field true
@type multi_format
format json
format none
system.input.conf: |-
# Example:
# 2015-12-21 23:17:22,066 [salt.state ][INFO ] Completed state [net.ipv4.ip_forward] at time 23:17:22.066081
@id minion
@type tail
format /^(?
# Example:
# Dec 21 23:17:22 gke-foo-1-1-4b5cbd14-node-4eoj startupscript: Finished running startup script /var/run/google.startup.script
@id startupscript.log
@type tail
format syslog
path /var/log/startupscript.log
pos_file /var/log/es-startupscript.log.pos
tag startupscript
# Examples:
# time="2016-02-04T06:51:03.053580605Z" level=info msg="GET /containers/json"
# time="2016-02-04T07:53:57.505612354Z" level=error msg="HTTP Error" err="No such image: -f" statusCode=404
# TODO(random-liu): Remove this after cri container runtime rolls out.
@id docker.log
@type tail
format /^time="(?
# Example:
# 2016/02/04 06:52:38 filePurge: successfully removed file /var/etcd/data/member/wal/00000000000006d0-00000000010a23d1.wal
@id etcd.log
@type tail
# Not parsing this, because it doesn't have anything particularly useful to
# parse out of it (like severities).
format none
path /var/log/etcd.log
pos_file /var/log/es-etcd.log.pos
tag etcd
# Multi-line parsing is required for all the kube logs because very large log
# statements, such as those that include entire object bodies, get split into
# multiple lines by glog.
# Example:
# I0204 07:32:30.020537 3368 server.go:1048] POST /stats/container/: (13.972191ms) 200 [[Go-http-client/1.1] 10.244.1.3:40537]
@id kubelet.log
@type tail
format multiline
multiline_flush_interval 5s
format_firstline /^\w\d{4}/
format1 /^(?\w)(?
创建fluentd-es-configmap.yaml
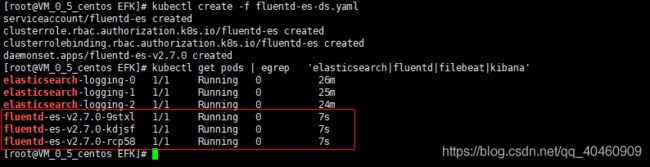
kubectl create -f fluentd-es-configmap.yaml
kubectl get cm | egrep 'elasticsearch|fluentd|filebeat|kibana'
好久不来iteye,今天又来看看,哈哈,今天碰到在编码时,反射中会抛出
Illegal overloaded getter method with ambiguous type for propert这么个东东,从字面意思看,是反射在获取getter时迷惑了,然后回想起java在boolean值在生成getter时,分别有is和getter,也许我们的反射对象中就有is开头的方法迷惑了jdk,
泛型
在Java SE 1.5之前,没有泛型的情况的下,通过对类型Object的引用来实现参数的“任意化”,任意化的缺点就是要实行强制转换,这种强制转换可能会带来不安全的隐患
泛型的特点:消除强制转换 确保类型安全 向后兼容
简单泛型的定义:
泛型:就是在类中将其模糊化,在创建对象的时候再具体定义
class fan
安装lua_nginx_module 模块
lua_nginx_module 可以一步步的安装,也可以直接用淘宝的OpenResty
Centos和debian的安装就简单了。。
这里说下freebsd的安装:
fetch http://www.lua.org/ftp/lua-5.1.4.tar.gz
tar zxvf lua-5.1.4.tar.gz
cd lua-5.1.4
ma
public class IsAccendListRecursive {
/*递归判断数组是否升序
* if a Integer array is ascending,return true
* use recursion
*/
public static void main(String[] args){
IsAccendListRecursiv
function init() {
var tt = document.getElementById("tt");
var childNodes = tt.childNodes[0].childNodes;
var level = 0;
for (var i = 0; i < childNodes.length; i++) {
在安装hadoop时,执行JPS出现下面错误
[slave16][email protected]:/tmp/hsperfdata_hdfs# jps
Error occurred during initialization of VM
java.lang.Error: Properties init: Could not determine current working