Python读取Excel表格效率对比(openpyxl、xrld、csv)
文章目录
- 前言
- 安装模块
- 正文
-
- 一、openpyxl 读取 .xlsx
- 二、openpyxl 读取 .xlsx(只读模式)
- 三、xrld 读取 .xlsx
- 四、CSV 读取 .csv
- 结论
前言
搭了一个配置表检查平台,单个项目使用时执行效率还能接受,可后面部署到公司所有项目使用时执行就变的慢,毕竟数据量起来了,经过排查主要表现在表格的读取,所有才有这篇效率对比。
安装模块
CSV标准库自带,不用安装
pip install openpyxl
pip install xrld
环境:
Python版本:3.6.9
OS:MacOS 11.6.1
测试数据:
文件名:testdata.xlsx
size:14.5MB
65600行,25列
文件名:testdata.csv
size:9.6MB
65600行,25列
正文
一、openpyxl 读取 .xlsx
# workbook.py
from openpyxl import load_workbook
wb = load_workbook(filename='/Users/yourPath/Downloads/testdata.xlsx', data_only=True)
def get_all_sheet_copy(table='物品配置表.xlsx', start_row=6):
all_sheet_data = {}
for sheet in wb.sheetnames:
sheet_datas = {}
ws = wb[sheet]
rows_data = np.array([[i.value for i in row] for row in ws.rows])[6:]
field_data = rows_data[0]
nw = np.where(rows_data[1:] < 1000)
rows_data = np.delete(rows_data,nw[0],0)
for i in range(1,len(field_data)):
sheet_datas[field_data[i]] = list(rows_data[:,i])
all_sheet_data[sheet] = sheet_datas
return all_sheet_data
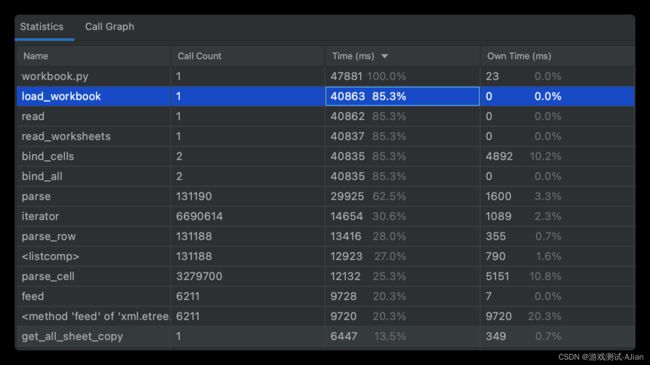
运行之后看看结果:
load数据总耗时 40.8秒,parse耗时29.9秒;
函数get_all_sheet_copy 耗时6.4秒
二、openpyxl 读取 .xlsx(只读模式)
# workbook.py
from openpyxl import load_workbook
wb = load_workbook(filename='/Users/yourPath/Downloads/testdata.xlsx', data_only=True, read_only=True)
def get_all_sheet_copy(table='物品配置表.xlsx', start_row=6):
all_sheet_data = {}
for sheet in wb.sheetnames:
sheet_datas = {}
ws = wb[sheet]
rows_data = np.array([[i.value for i in row] for row in ws.rows])[6:]
field_data = rows_data[0]
nw = np.where(rows_data[1:] < 1000)
rows_data = np.delete(rows_data,nw[0],0)
for i in range(1,len(field_data)):
sheet_datas[field_data[i]] = list(rows_data[:,i])
all_sheet_data[sheet] = sheet_datas
return all_sheet_data
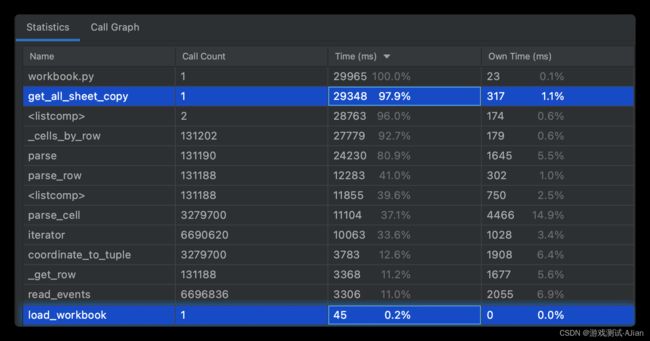
运行之后看看结果:
load_workbook数据耗时 45毫秒,parse耗时24.2秒;
我的函数get_all_sheet_copy 耗时29.3秒
只读模式和上面对比,总体效率更高,但前提是你的业务适合用只读模式。
三、xrld 读取 .xlsx
# workbook.py
import xlrd
wk = xlrd.open_workbook('/Users/yourPath/Downloads/testdata.xlsx')
def get_all_sheet_copy(table='物品配置表.xlsx', start_row=6):
# wb = load_workbook(filename=f'{table}', data_only=True)
all_sheet_data = {}
for sheet in wk.sheet_names():
sheet_datas = {}
ws = wk.sheet_by_name(sheet)
rows_data = np.array([ws.row_values(row_index) for row_index in range(7,ws.nrows)],dtype='int64')
# rows_data = np.array([row for row in ws.get_rows()])
field_data = ws.row_values(6)
nw = np.where(rows_data < 1000)
rows_data = np.delete(rows_data,nw[0],0)
for i in range(1,len(field_data)):
sheet_datas[field_data[i]] = list(rows_data[:,i])
all_sheet_data[sheet] = sheet_datas
return all_sheet_data
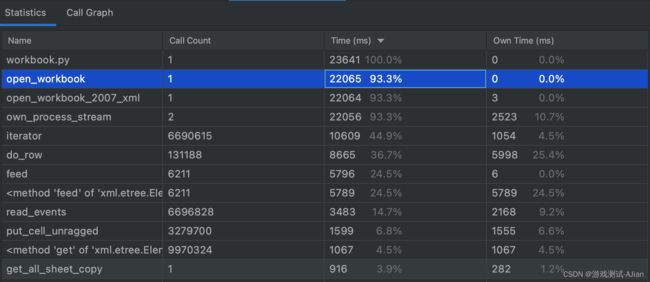
运行之后看看结果:
open_workbook数据耗时 22秒;
我的函数get_all_sheet_copy 耗时0.91秒
对比openpyxl的只读模式要快约7秒。
最后还有更快的xlwings和win32com,结合业务需求来选择。
四、CSV 读取 .csv
# workbook.py
import csv
with open('/Users/yourPath/Downloads/testdata.csv') as f:
reader = list(csv.reader(f))
rows = [[int(i) for i in row] for row in reader[1:]]
运行之后:
加载数据耗时 1.3秒;
对比xlsx,这速度真的没法比,如果能把xlsx转成csv的尽量转
结论
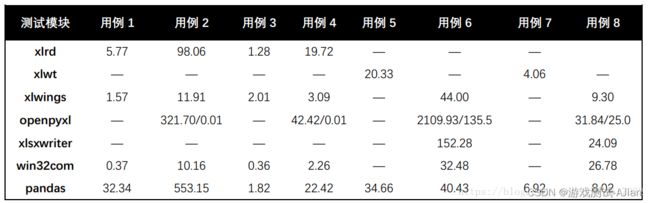
这里借用人家做的测试结果图:
.xlsx文件 我这里优先用xlrd 其次是openpyxl只读模式
图里是win32com和openpyxl 效率较高,但有依赖
最后是CSV,快是快,但先把文件转成.csv格式
欢迎小伙伴关注微信公众号ID:gameTesterGz
或关注我的CSDN:https://blog.csdn.net/qq_32557025
谢谢各位的关注、点赞!
