JVM问题排查
本文详细说明了Java应用运行过程中几种常见的JVM相关问题,并给出了问题排查步骤。
一、堆中OOM
现象:Java线程负载过高,JVM内存几乎占满,甚至抛出java.lang.OutOfMemoryError错误。
思路:通过jmap能查看到对内存中实例,可以查看到哪些类的实例比较多,排查出OOM原因。
工具:jmap
步骤:
1.查看实例信息:
jmap -histo 14660 #查看历史生成的实例
jmap -histo:live 14660 #查看当前存活的实例,执行过程中可能会触发一次full gc2.查看堆信息:jmap -heap
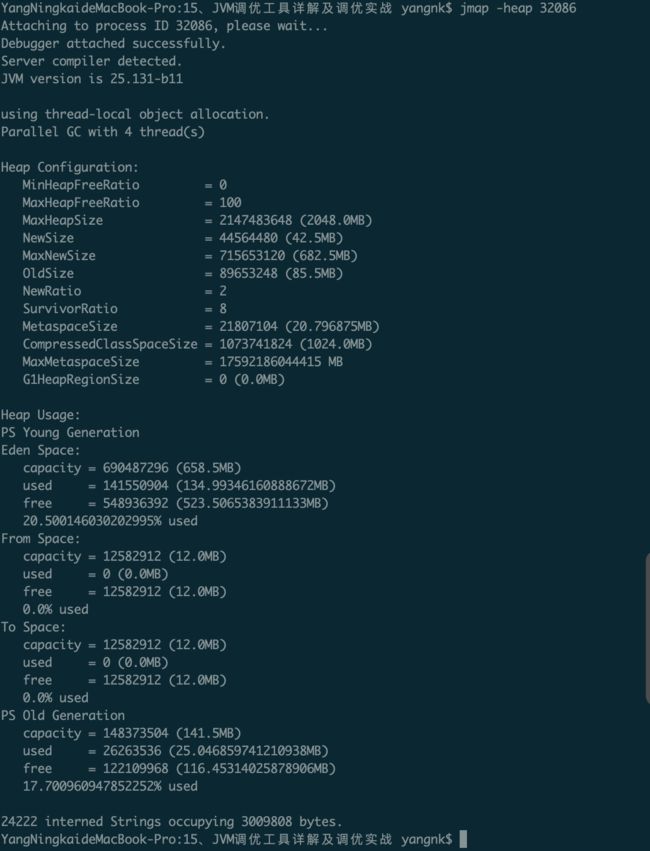
3.堆内存dump下来:
(1)jmap -dump:format=b,file=eureka.hprof 14660
(2)使用jvisualvm命令工具导入该dump文件分析

二、死锁排查
现象:多个线程处于死锁状态,无法再正常执行。
背景:当两个线程互相加了对方所依赖的锁时就会进入死锁状态,例如执行以下代码会进入死锁状态:
public class Test1 {
public static void main(String[] args) {
Object lock = new Object();
Object lock1 = new Object();
new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock1) {
}
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
synchronized (lock1) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lock) {
}
}
}
}).start();
}
}思路:通过jmap能看到所有线程的状态,但线程状态处于blocked时候就是被加锁的状态中。
工具:jmap
步骤:
jps 查看进程号
用jstack 查找死锁状态中线程。

"Thread-1" 线程名
tid=0x000000079582bc98 线程id
nid=0x3e03 线程对应的本地线程标识nid
java.lang.Thread.State: BLOCKED 线程状态
三、CPU飙升
现象:JVM的CPU飙升
思路:通过top查看出占用最大的java线程id,再通过命令top -Hp找到该线程下关联的进程id,找到占用cpu最高的线程id,将其转换为十六进制,在通过jstack来查看进程状态
工具:top+jstack
步骤:
- 用top命令查找出CPU占用最大的java进程和下面的线程;
查找CPU占用最高的进程:top 查找该进程下面的线程:top -Hp ,可以看到该进程下所有子线程,可以找到占用CPU最高的线程Id,可以用命令:printf "%x\n" <线程id> 将十进制线程id转为十六进制,便于后面jstack命令使用打印GC日志:jstat -gc
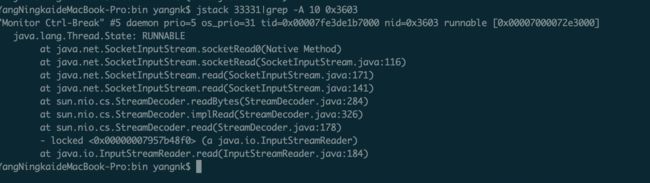
- 用jstack查找出对应线程的日志信息;
通过进程id查看栈内信息:jstack (-A 30表示向下打印30行)
总结:cpu飙升可能的原因大概为:
代码存在死循环,导致消耗cpu;
代码一直在创建大对象,导致频繁GC,这个时候内存占用率也会很高;
四、频繁Full GC
问题说明:系统中某服务为图方便缓存使用一个hashmap,运行过程中会不断往里面放缓存数据,但是没有考虑这个map的容量问题,结果这个缓存map越来越大,一直占用着老年代的很多空间,时间长了就会导致full gc非常频繁,这就是一种内存泄漏,对于一些老旧数据没有及时清理导致一直占用着宝贵的内存资源,时间长了除了导致full gc,还有可能导致OOM。
这种情况完全可以考虑采用一些成熟的JVM级缓存框架来解决,比如guava、ehcache等自带一些LRU数据淘汰算法的框架来作为JVM级的缓存。
工具:jstat
步骤:
- jstat -gc 可以评估程序内存使用及GC压力整体情况

- S0C:第一个幸存区的大小,单位KB
- S1C:第二个幸存区的大小
- S0U:第一个幸存区的使用大小
- S1U:第二个幸存区的使用大小
- EC:伊甸园区的大小
- EU:伊甸园区的使用大小
- OC:老年代大小
- OU:老年代使用大小
- MC:方法区大小(元空间)
- MU:方法区使用大小
- CCSC:压缩类空间大小
- CCSU:压缩类空间使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间,单位s
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间,单位s
- GCT:垃圾回收消耗总时间,单位s
优化思路:简单来说就是尽量让每次Young GC后的存活对象都留存在年轻代里,尽量别让对象进入老年代,尽量减少Full GC的频率,避免频繁Full GC对JVM性能的影响。
JVM参数说明:
-Xms1536M -Xmx1536M -Xmn512M -Xss256K -XX:SurvivorRatio=6 -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly 
本文由博客一文多发平台 OpenWrite 发布!