谈一谈凸优化问题
谈一谈凸优化问题
看到好多人都在学习凸优化,但是有感觉有多少问题多符合凸优化条件的呢?为什么非得是凸优化这么重要?现有的优化方法不是都能解决吗?那凸优化又有什么用呢?

优化问题的具体应用场景
投资组合优化
优化变量:投资于不同投资方案的金额
约束:预算/每个投资方案的最大或最小投资额/最小回报率
目标函数:整个投资组合的风险回报率
电子电路中的设备大小
优化变量:设备的长和宽
约束:制造工艺的限制/时间要求/最大面积
目标函数:功耗
数据拟合(机器学习中的一些算法,譬如svm等应用)
优化变量:模型的参数
约束:参数的限制/优先的条件
目标函数:预测的误差函数(loss function等)
除了这些之外优化问题在其他各个领域还有很多的应用,总之优化问题在实际应用场景中是非常常见的。
如何解决优化问题
一般的优化问题:都比较难解决,解决方法一般都是一种折中方案(逼近),由于非常长的计算时间,或者一直没有找到问题的解。
一些特例(能够高效和可靠的被解决的一类问题):
最小二乘法问题
线性规划问题
凸优化问题
不过在看我的回答之前,可以先了解下凸函数、凸集、凸锥(简称“三凸”)的定义。
首先,我们还是要看下,什么是凸优化?抛开凸优化中的种种理论和算法不谈,纯粹的看优化模型,**凸优化就是:1、在最小化(最大化)的要求下,2、目标函数是一个凸函数(凹函数),3、同时约束条件所形成的可行域集合是一个凸集。**以上三个条件都必须满足。而世间万物千变万化,随便抽一个函数或集合它都可能不是凸的。
所以,先回答题主的第一个问题,这个世上的绝大部分优化问题当然不是凸优化问题。既然如此,为什么凸优化这么重要呢,以及凸优化有什么用呢?(另外,凸优化并不能看成是某一种优化方法)无非三点:
**1、还是有相当一部分问题是或等价于凸优化问题。**有许多问题都可以直接建立成凸优化模型(比如:线性规划LP(Linear Programming)、某些特殊的二次规划QP(Quadratic Programming)、锥规划CP(Conic Programming)其中包括:要求约束中变量落在一个二阶锥里的二阶锥规划SOCP(Second Order Cone Programming)、要求约束中变量是半正定矩阵的半定规划SDP(Semi-Definite Programming)等)。以上这些类型,总之就是要符合凸优化上述的要求。需要说明的就是,许多可行域都可以看作是凸锥(Convex Cone)的交集,所以将以上一些类型的约束混合起来,依然是凸优化问题。
另外还有一些问题,可以等价的转化为凸优化问题。例如 Linear-Fractional Programming (LFP),目标函数是两个仿射函数(Affine Function)的比,约束是一个多面体。这种目标函数具有既是拟凸又是拟凹的性质,通过一个叫做 Charnes-Cooper transformation 的转化,可以变成一个线性规划。同时,如果我们要最大化 LFP 的目标函数,且其约束仅是一个0-1整数约束(这显然不是一个凸集),我们可以将其直接松弛(Relax)成0到1的约束,并且和原问题等价。因为最大化拟凸函数,最优值一定可以落在可行域的极点上。这个结论可以用来帮助解决 Multi Nomial Logit(MNL)选择模型下的商品搭配问题( Assortment Optimization)。
**2、大部分凸优化问题解起来比较快,也即多项式时间可解问题(P)。如果你的问题能直接或间接(但必须是等价的)**转化成上面我提到的那些类型,那恭喜你,后面的事儿基本就可以交给solver啦,当然大规模问题还需要考虑诸如列生成(Column Generation)之类的方法,提高运算效率。
那为什么大部分凸优化解起来比较快呢?这涉及到凸函数的局部最优即全局最优的性质以及凸集分离定理(Seperation Theorem)。我们形象一点来思考这个问题,而不拘泥于理论。如果了解凸函数(或凹函数)的定义,我们可以想象成站在函数的曲线上去搜索最优解,所要做的无非就是向下到底(或向上到顶),需要考虑的是用什么样的角度迈出第一步以及每的步子要迈多大才更快的到达最优值。同时,作为凸集的可行域,让我们更容易在有限范围内迅速锁定最优解,而不用四处打探。(以下为简单说明这个道理,脑补了一段情节,对理论熟悉的可以略过)
以线性规划为例(目标函数既凸且凹,所以最大化最小化皆可),想象你在目标函数那个超平面上一路狂奔,因为是最小化(或最大化),你得往觉得最轻松(或费劲)的下坡(上坡)方向跑,跑着跑着,你就碰到可行域这个多面体的墙壁了。没关系,你感觉贴着壁的某个方向还是可以轻松(或费劲)地继续跑,跑着跑着到了一个拐角,即所谓的极点。你觉得再走下去就费劲(或省力)了,这样就找到了一个最优的极小值(极大值),否则,你可以沿着墙壁继续走下去。如果,这个时候的可行域不是凸集,而是被人胡乱咬了一口,形成了凹凸不平的缺口。如上方法搜索,你可能已经到达这个缺口的某一个角落,前方已经没有任何能改善你可行解的道路了,你可以就此停止吗?不能!因为想象有另一个你,也如上所述,跑到了这个缺口的另一个无处可走的角落,他也认为自己可以停止了,那你们就还需要比较两个各自所在的位置的解,哪一个会更优。当然,可能还有第三个你,第四个你。。。但不要忘了,每一个你的搜索都需要时间,最终的比较也需要时间(除非你们之间没有缺口,可能都会继续跑下去,到达了一个共同的最优值)。所以非凸的可行域要比一个凸集的可行域麻烦的多。(注:以上形象化的描述的未必就是多项式时间的算法。现实中如单纯形法就不是多项式时间的算法,但实际运用中仍然很高效。)
当然,也有例外,即虽然是凸优化但不是多项式时间可解的。比如在约束中,要求变量是一个Copositive 矩阵或者 Completely Positive 矩阵,这两种矩阵所在的锥恰为对偶锥。此类问题很难解的原因在于,你要去检查一个矩阵是不是落在这样的锥里,就已经不是多项式时间可以解决的了,更不用说整个优化问题。
**3、很多非凸优化或NP-Hard的问题可以转化(并非是等价的)为P的凸优化问题。并给出问题的界或近似。这对如何设计合理的算法,或衡量算法结果的优劣起到很大的帮助。**非凸优化的问题基本上都是NP-Hard的,所以要找到其最优解,理论上是不确定有一个多项式时间的算法的,所以这时候会考虑设计一些近似算法,或者启发式算法,就要依靠凸优化。要把一个优化问题转化为凸优化的方法和例子有很多,以下试举几例说明。
**对偶(Duality)**是每个学习运筹学或者凸优化的人都必须熟练掌握的方法,对偶有很多种,本科运筹就教会大家写一个线性规划的对偶形式,高等数学里面也会提到用到拉格朗日乘子之类的约束优化问题,也即解拉格朗日对偶或者KKT条件。一般的,对于许多非凸优化的问题,我们仍然可以写出它的拉格朗日对偶,拉格朗日对偶永远都是一个关于对偶变量的凸优化问题,并且根据弱对偶定理,可以给出原问题的下界。
**松弛(Relaxation)**也是常用的方法之一,在第一点里,我们举了一些例子可以通过松弛,去掉整数约束,使其等价为凸优化。通常情况下,我们松弛原问题,只能得到一个可行域更大的问题,如果原问题是求最小,则松弛后的问题的最优值一定小于等于原问题的最优值,这也是一种给出下界的方法。松弛不仅仅用于整数约束,只要利于将可行域非凸变为凸集皆可。
当然,相应的处理方法还有很多,面临一些随机优化(Stochastic Optimization)、机会约束规划(Chance Constrained Programming)、鲁棒优化(Robust Optimization)、离散凸优化(Discrete Convex Optimization)问题,还有更多其他的处理方法,就不在此一一道来。更多内容,可以看各位答案里推荐的书籍,都是经典教材
1. 为什么凸优化重要?
各位答主们已经洋洋洒洒写了很多了。我这边简单来说就是两点,凸优化性质好,并且即使是日常生活中的许多非凸优化问题,目前最有效的办法也只能是利用凸优化的思路去近似求解。一些例子有:带整数变量的优化问题,松弛之后变成凸优化问题(所以原问题其实是凸优化问题+整数变量);任意带约束的非凸连续优化问题,其对偶问题作为原问题解的一个lower bound,一定是凸的!一个更具体的例子,大家都知道针对带有hidden variable的近似求解maximum likelihood estimate的EM算法,或者贝叶斯版本里头所谓的variational Bayes(VB) inference。而原本的MLE其实是非凸优化问题,所以EM和VB算法都是找到了一个比较好优化的concave lower bound对这个lower bound进行优化。
这是什么意思呢?也就是说到今天2019年为止,我们还是只对凸优化问题比较有把握。当然有人可能要说了,现在各种深度学习中的优化问题都是极其复杂的非凸优化问题,不是大家也能解的挺好?这个问题的回答就更难一些,我个人观点,简单来说是这样,目前对于这些非凸优化问题取得的算法理论方面的突破大体其实归结于找到这些非凸优化问题中“凸”的结构。这也是为什么我们看到一阶算法(SGD, ADAM等)仍然大行其道,而分析这些非凸优化算法的时候其实很多的lemma(引理)仍然是凸优化(凸分析)里的引理或者引申。举个例子,我们大家都知道凸函数的各种等价定义。而在Zeyuan Allen-Zhu的一系列非凸优化算法的文章中所谓的非凸性的刻画仍然是基于此衍生出来的:
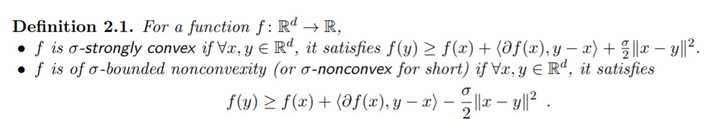
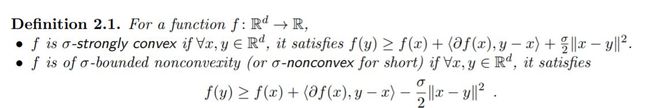 来源:Allen-Zhu, Zeyuan. Natasha: Faster Non-Convex Stochastic Optimization via Strongly Non-Convex Parameter. International Conference on Machine Learning. 2017.
来源:Allen-Zhu, Zeyuan. Natasha: Faster Non-Convex Stochastic Optimization via Strongly Non-Convex Parameter. International Conference on Machine Learning. 2017.
我们知道它里面这个刻画非凸性的参数 如果取成0,那就等价于凸函数的定义,如果取成负的,那么实际上就是所谓strongly convex,而如果是正的,就变成它这里的non-convexity了。实际上,现在非凸优化里面很多的非凸性刻画都是脱胎于凸优化,比如prox regularity之类的,或者一些更弱的convexity定义(这在经典凸分析里就已经有不少研究了,quasi-convex,psuedo-convex等等),这里不再赘述。
个人认为,我们能真正一般化地解决非凸优化问题,那肯定是要对一般的混合整数(线性)规划(MILP, mixed integer linear programming)要有好的办法求解才算。因为任意一个非凸优化问题,都可以用很多的分段线性函数逼近,最后变成一个MILP。当然,因为P!=NP这个猜想的存在,这件事情在理论上肯定是hopeless,但是在实际当中,基于硬件能力的提升,还有比如量子计算机一类的新技术,我个人对人类未来能够在实际中求解MILP还是持一个比较乐观的态度。到那个时候,我觉得我们才能说传统的凸优化理论才是真正过时了。
2. 现有的优化方法不是都能解决(凸优化)吗?那凸优化又有什么用呢?
首先先明确一点,凸优化难吗?嗯相比非凸优化,各种NP-complete问题,凸优化里各种P问题,那肯定是简单的。然而,在实际当中,我们完全不可能满足于有一个“多项式时间算法”就好了。
我们知道,运筹学,优化问题,反映到现实世界里面就是各种数学建模问题。这些问题,普遍地出现在航空业、金融业、广告业、电商零售业、能源业、医疗业、交通业等各个领域。我们必须要明确一点,计算复杂性理论(P,NP这套东西)在实际当中其实是没什么用处的。嗯,NP hard, NP complete问题很难,没有多项式时间算法,但如果你实际的问题规模不太大,比如几十个城市的旅行商问题(TSP, travelling salesman problem),几十x几十的图上的NP-complete问题,是不是很难?然而现在2019年,你在iphone上下个app,一部小小的手机不要几秒钟就能给你算出最优解。(实际上,他们这个app,1000个左右城市的TSP iphone也顶多要算个几小时就能找到全局最优解,无近似)求解app,当然,这得益于他们家目前行业领先的解大规模TSP底层算法…
与此相对应的,即使是一个P问题,但是如果实际当中你的问题规模超级大呢?实际上反而这个问题会让你更头疼的。举个例子,比如现在优酷、天猫、京东、亚马逊这些个平台,每天你登陆网站,它在推荐栏都需要根据你的历史活动记录决定推荐哪些产品给你。这个在线推荐算法,本质上只是需要求解一个线性规划问题(LP, linear programming, 比一般的凸优化还简单),甚至还不是一个一般的线性规划,有个专门的名字叫做packing LP,这类packing LP理论上可以有跟问题规模呈线性的复杂度的算法(忽略log项,跟排个序差不多…)。听起来是不是很简单?然而,实际这些问题的规模无比巨大,每天这些平台上线人次可以以亿记,这些平台可以推荐的商品也是至少百万千万规模的。。而且实际问题还有各种各样的现实约束,比如我们希望我们的算法可以完全在线更新(online,甚至是streaming algorithm),我们的算法需要灵活运用存储数据的数据结构,需要利用计算集群的并行能力,分布式能力,这也是需要非常非常专门的(一阶)优化算法设计的。。这边就不再多说了,因为我个人确实在之前公司实习的时候,发现中国最好的IT公司面对这类海量规模的“简单”LP,实际上远没有能力去完美地求解。。
因此说现有的方法能解决所有的凸优化问题,但从实际的角度其实还差的远。事实上,目前的大公司面对如此规模的优化问题,也就LP还可以勉强接受,像是什么second-order cone prorgamming (SOCP), semidefinite programming (SDP)根本目前实际中都不可能大规模求解。而这两类问题在理论上还仍然都是**“线性”**的,因为可以写成linear conic programming,所以就更不要说一般的带约束的凸优化问题了。实际上,在这个方面,无论是求解器(solver)还是更好的理论算法的开发都还有大量的研究空间。比如,SDP实际当中的大规模算法设计目前来看还基本一片空白,有很多很基本的问题都还没有在理论上得到满意的解答(像SDP其实和另一类凸优化问题只有一丝之隔,copositive programming,**而这类凸优化问题的计算复杂度却是NP complete的,所以即使是凸优化也未必复杂度就容易!实际上,所有mixed 0/1 nonconvex quadratic program都可以写成copositive program这个凸优化的形式。**两者的算法设计也因此都很蛋疼)。。还有这么多没有解决的问题,又如何能说凸优化的问题都已经被“解决”了呢?
5月29号召开的非凸优化与分布式优化的理论,算法及应用国际研讨会对该问题做了合理深入的讨论
有喜欢研究这方面的大佬可以深入了解一下
参考:https://blog.csdn.net/chan_cyx/article/details/80274747
https://www.zhihu.com/question/24641575