深入理解MySQL(3):详谈SQL的执行顺序
MySQL
五、SQL执行顺序
编写的一条sql语句
SELECT DISTINCT <select_list>
FROM <left_table>
<join_type>JOIN<right_table>
ON <join_condition>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
ORDER BY <order_by_condition>
LIMIT <limit_number>
实际上执行的顺序是
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE<where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number>

其中jion种类有:mysql并不支持全外连接,可以通过LEFT JOIN + UNION + RIGHT JOIN 来实现FULL JOIN
在很多博客上看到前面这些说法,但细想一想无论什么联表都先生成笛卡尔乘积中间表显然是不太合理的,因此通过查询相关博客、书籍及MySQL官方文档,MySQL关联查询是基于循环嵌套算法的说法更为准确的,下文会有详细解释。
5.1驱动表
MySQL执行关联查询的过程可称之为循环嵌套,从一个表(驱动表)中循环取出单条数据,再嵌套循环到下一个表中寻找匹配的行,这其中MySQL也做了很多优化。
那么如何确定的谁是驱动表呢,具体的可以参考: Mysql多表连接查询的执行细节(一)、Mysql多表连接查询的执行细节(二) ,这里就说下结论:
- 对于内关联来说,谁是驱动表并不是按照sql语句中写的先后顺序来决定的,而是根据谁的查询数量少决定的(以及考虑是否会回表等综合因素)。
- 对于外联来说,左联一般左表是驱动表,右联一般右表是驱动表,但也不是百分百的,比如有时候左联被优化为内联,驱动表不一定是左表。
可通过explain来查看,排在第一个的就是驱动表,此外可以发现第三个表的Extra列有一个Using join buffer的值,它显示了该关联查询使用的算法,具体的后面再讲。
EXPLAIN SELECT * FROM job ,emp,dept WHERE job.`id`=emp.`job_id`AND emp.`dept_id`=dept.id
![]()
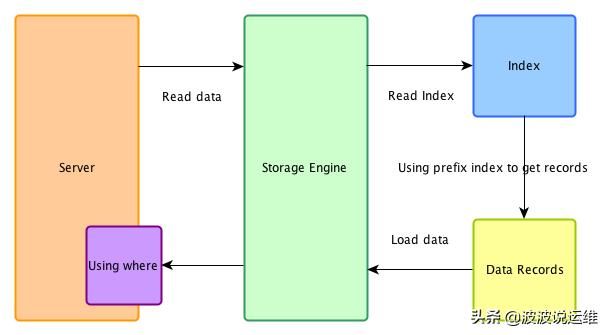
5.2SQL的where条件、ICP及MRR
为了便于后续内容的理解,这里补充一些关于SQL的where条件和5.6版本后引入的ICP、MRR
以下面这个sql为例,表num1中建有索引(a,b,c)
SELECT * FROM num1 WHERE a>1 AND b<2 AND c>3 AND d<8
where条件可以应用于三种情况:
- Index Key,用于确定SQL查询在索引中的连续范围,分为Index First Key、Index Last Key
- Index First Key,只是用来定位索引的起始范围,因此只在索引第一次Search Path(沿着索引B+树的根节点一直遍历,到索引正确的叶节点位置)时使用,一次判断即可;
- Index Last Key,用来定位索引的终止范围,因此对于起始范围之后读到的每一条索引记录,均需要判断是否已经超过了Index Last Key的范围,若超过,则当前查询结束;
- Index Filter,用于过滤索引查询范围中不满足查询条件的记录,因此对于索引范围中的每一条记录,均需要与Index Filter进行对比,若不满足Index Filter则直接丢弃,继续读取索引下一条记录;
- Table Filter,则是最后一道where条件的防线,用于过滤通过前面索引的层层考验的记录,此时的记录已经满足了Index First Key与Index Last Key构成的范围,并且满足Index Filter的条件,回表读取了完整的记录,判断完整记录是否满足Table Filter中的查询条件,同样的,若不满足,跳过当前记录,继续读取索引的下一条记录,若满足,则返回记录,此记录满足了where的所有条件,可以返回给前端用户。
其中Index key在是引擎层完成的,而在5.6版本之前Index Filter是在server层完成的,这使得更多无效的数据返回到了server层,既增加了引擎访问磁盘的次数也增加了server层访问次数,因此在MySQL 5.6版本后提出了**ICP(index condition pushdown)**的优化,将索引过滤条件推送到存储引擎。以上面的sql为例,之前对于b<2和c>3的过滤都在是server层,而开启ICP后,在使用(a,b,c)索引完成a的查找后,会在索引树上基于b,c的where条件再次过滤,然后再去聚簇索引获取数据(优化前所有a>1数据都会回表查询),最后将结果集返回server层后基于d<8进行Table Filter。
此外,ICP仅用于二级索引(二级索引才会回表查询),对于innodb聚集索引,b、c的条件无法用来过滤,因此,完整的记录已被读入到innodb缓冲区,在这种情况下,ICP不会减少IO。
控制ICP启闭的语句是
SET optimizer_switch='index_condition_pushdown=on/off';
开启和关闭的效果示意图如下:
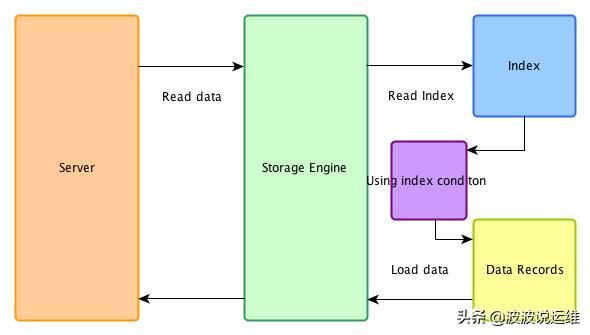
更为局部的效果图,图源:mariadb
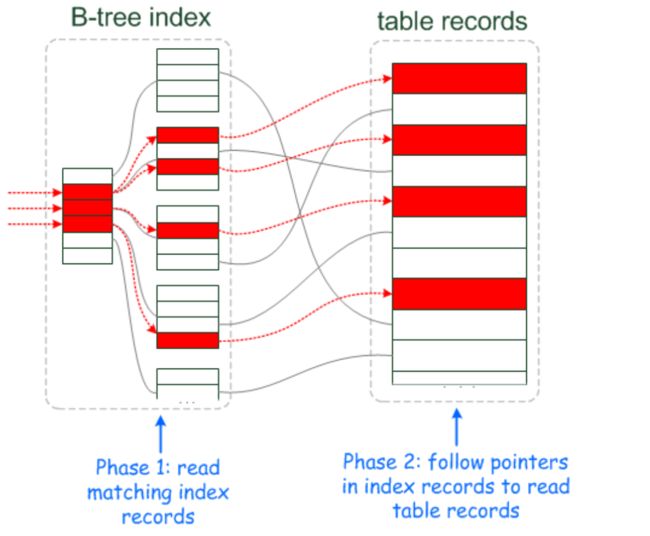
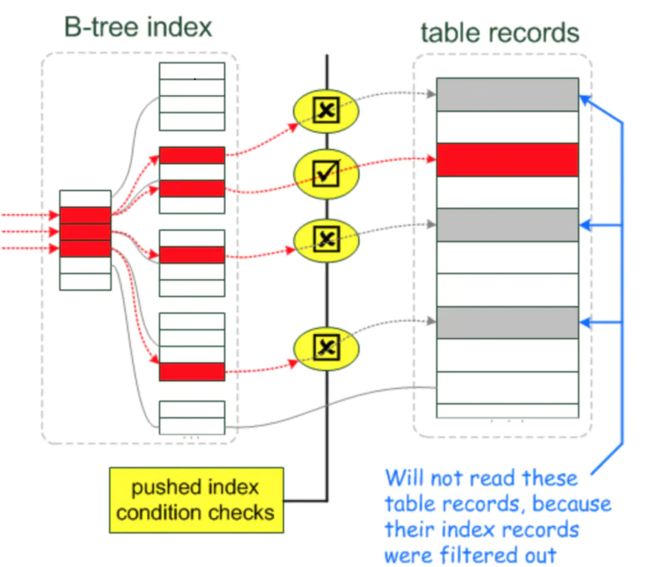
当我们使用二级索引查询结果集时,如果不是覆盖索引,需要回到聚簇索引查询完整的行记录,这个过程成为回表。如果二级索引中有多行记录满足查询要求,那么是进行一次回表还是多次回表呢?在MySQL 5.6版本 之前是多次回表,因为在二级索引树上顺序排列的结果集对应的主键并不一定是连续的,很有可能会造成大量的随机IO,因此,在5.6版本之后提出了Mutil Range Read 优化,将二级索引得到的结果集按主键进行排序,再去聚簇索引树上查询,减少了随机IO,优化了性能。
并不是任何场景都会使用MRR,MySQL只会在某些特定场景使用,参考Multi Range Read Optimization:
rangeref和eq_ref访问,当他们使用Batched Key Acess(BLA算法,后续介绍)
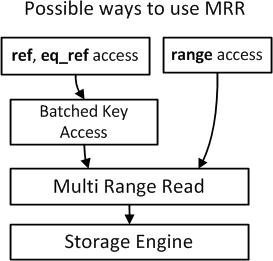
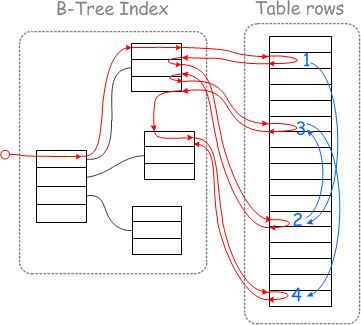
以Range acess为例:
explain select * from tbl where tbl.key1 between 1000 and 2000;
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
| 1 | SIMPLE | tbl | range | key1 | key1 | 5 | NULL | 960 | Using index condition |
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
执行此查询时,磁盘 IO 访问模式将遵循此图中的红线,可以清楚的看到回表的过程时大量的随机IO。
此外,可以发现MySQL默认是没有使用MRR进行优化的,主要原因是优化器觉得使用MRR的成本更高。因此控制是否使用MRR的参数有两个mrr和mrr_cost_based,默认值都是on。它们的关系如下:

设置参数的语句为
-- 开启MRR
SET optimizer_switch='mrr=on';
-- 强制优化器使用MRR
SET optimizer_switch='mrr_cost_based=off'
开启MRR后,执行相关查询语句,查看extra列结果,显示使用了"Rowid-ordered scan"
explain select * from tbl where tbl.key1 between 1000 and 2000;
+----+-------------+-------+-------+---------------+------+---------+------+------+-------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+-------------------------------------------+
| 1 | SIMPLE | tbl | range | key1 | key1 | 5 | NULL | 960 | Using index condition; Rowid-ordered scan |
+----+-------------+-------+-------+---------------+------+---------+------+------+-------------------------------------------+
执行的过程如下:
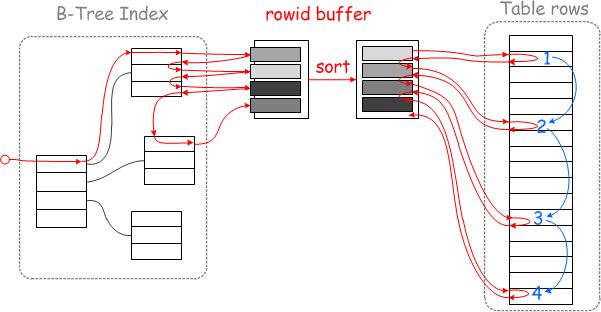
二级索引的查询结果先存储在rowid buffer,排序后再去聚簇索引中查询完整行数据。
MRR在很多场景下能有效提高IO效率,但在某些场景下就不是那么理想了:
- 如果扫描的表中的小数据范围足够小,以至于它完全适合操作系统磁盘缓存,那么MRR 反而会因为额外的缓冲/排序增加一些 CPU 开销。
LIMIT n和``ORDER BY ... LIMIT n中的n比较小时可能会变慢。原因是MRR是按磁盘顺序读取数据,而ORDER BY ... LIMIT n是需要按索引顺序的结果集。比如某个查询是将结果按age排序且只要前2个数据行,它的顺序并不总是和主键的顺序一致,这时开启了MRR反而影响了效率。
Multi Range Read 需要排序缓冲区来操作,缓冲区的大小受系统变量的限制。如果 MRR 必须处理的数据超过其缓冲区所能容纳的数据量,它会将扫描分成多次扫描。分次扫描的次数越多,速度上的优化效果就越差,因此需要在缓冲区太大(消耗大量内存)和缓冲区太小(限制可能的速度优化)之间取得平衡。具体的参数设置可参考:buffer-space-management。
5.3联表算法
MySQL 的联表算法是基于嵌套循环算法(nested-loop algorithm)而衍生出来的一系列算法,根据不同条件而选用不同的算法。对于最简单的循环嵌套算法,用伪代码表示即为:
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}
5.3.1时间复杂度
以inner join 为例分析,假设A表存在M条记录,B表存在N条记录,且A表为驱动表,执行的sql为:
select * from A join B on A.idx=B.idx
对于驱动表全表扫描,时间复杂度是O(M),对于B表,如果关联列有索引,那么首先搜索索引,然后再回表查询完整的行记录,搜索了2个B+树,时间复杂度为2log(N),如果B表中的关联列没有索引的话,那么复杂度是2N。因为A表一共要扫描M行,所以总的时间复杂度就是M *2log(N)或者M *2N。
因此,对于NLA算法来说,它的执行效率关键在于:1.驱动表扫描的行数;2.被驱动表关联列是否有索引。
根据是否使用索引关联,NLG算法大致可以分为两类:
- 在使用索引关联的情况下,有 Index Nested-Loop join 和 Batched Key Access join 两种算法;
- 在未使用索引关联的情况下,有 Simple Nested-Loop join 和 Block Nested-Loop join 两种算法;
下面就依次简单介绍一下。
5.3.2Simple Nested-Loop
简单嵌套循环,简称 SNL;逐条逐条匹配,用伪代码表示整个过程

这种算法性能很差,时间性能上来说是 n(表中记录数) 的 m(表的数量) 次方,所以 MySQL 做了优化,联表查询的时候不会出现这种算法,即使在无 WHERE 条件且 ON 的连接键上无索引时,也不会选用这种算法。
5.3.3Block Nested-Loop join
缓存块嵌套循环连接,简称 BNL,是对 SNL 的一种优化;一次性缓存多条驱动表的数据到 Join Buffer,然后拿 Join Buffer 里的数据批量与内层循环读取的数据进行匹配,用伪代码表示就是
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer
if buffer is full {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
empty join buffer
}
}
}
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
}
例如,如果将 10 行读入缓冲区并将缓冲区传递到下一个内部循环,则可以将内部循环中读取的每一行与缓冲区中的所有 10 行进行比较。这将读取被驱动表的次数减少了一个数量级。
5.3.4Index Nested-Loop
索引嵌套循环,简称 INL,是基于被驱动表的索引进行连接的算法;驱动表的记录逐条与被驱动表的索引进行匹配,避免和被驱动表的每条记录进行比较,减少了对被驱动表的匹配次数,大致流程如下图
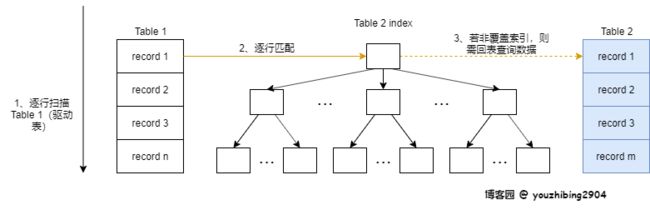
5.3.5Batched Key Access
BKA 是对 INL 优化后的一种联表算法(BKA Algorithm),BKA算法在需要对被驱动表回表的情况下利用MRR优化了执行逻辑,如果不需要回表,那么自然不需要BKA算法。如果要使用 BKA 优化算法的话,你需要在执行 SQL 语句之前先进行设置:
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
5.5on和where的执行顺序
先简单介绍下where和on的使用。on用于join连接,用于确定表与表之间关联列的条件关系。where的应用场景更为广泛,主要是用来过滤数据,逻辑判断为true的记录才会返回,而逻辑值为false和unknown的都会被过滤掉。关于MySQL中的逻辑值unknown可参考三值逻辑与NULL。
首先说明一点,在inner join中,条件放在on和where中对结果而言并没有区别。
以job(职位)表和emp(员工)表内连接查询为例
SELECT * FROM job JOIN emp ON job.id=emp.`job_id`
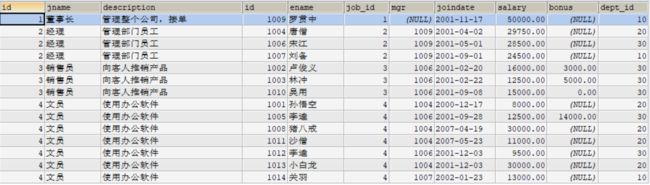
SELECT * FROM job JOIN emp ON job.id=emp.`job_id` AND job.`id`=2

SELECT * FROM job JOIN emp ON job.id=emp.`job_id` WHERE job.`id`=2

在outter join中,条件放在on和where 中会影响结果,并且where条件的字段是否是索引列会影响where和on条件执行的顺序。
关于此的分析在博文on和where的生效时机有很详细的案例描述。之所以会有这样的情况,我认为就是因为前文介绍的where有三个应用场景,不同的应用场景执行的时机不同使得where和on条件执行顺序并不固定。
本章的大部分内容都整理自系列博文:神奇的SQL,看完很有收获。
我实在太困了 明天搞吧 mysql的东西太多了
注:内容是从语雀上的学习笔记迁移过来的,有些参考来源已经无法追溯,侵权私删。