CGO入门和OCR文字识别(非第三方API,有源码,效果好)实战
文章目录
- CGO入门和OCR文字识别(非第三方API,有源码,效果好)实战
-
- CGO是什么
-
- 极简入门
- CGO基础类型
- 字符串、数组和函数调用
- CGO实战
-
- 分离Go和C代码
- 常用cgo编译指令
- 调用C静态库和动态库
-
- 静态库
- 动态库
- 调用C++动态库
- CGO的缺陷
- CGO最佳使用场景总结
- CGO案例:在Go中调用动态库实现OCR文字识别
-
- chineseocr_lite介绍
- 识别效果
- 编译chineseocr_lite
- 导出c函数
- 环境变量设置
- 运行
- 参考
CGO入门和OCR文字识别(非第三方API,有源码,效果好)实战
CGO是什么
简单点来讲,如果要调用C++,C写的库(动态库,静态库),那么就需要使用Cgo。其他情况下一般用不到,只需要知道Go能调用C就行了,当然C也可以回调到Go中。
使用Cgo有2种姿势:
- 直接在go中写c代码
- go调用so动态库(c++要用extern “c”导出)
为了熟悉CGO,我们先介绍第一种方法,直接在Go中写C代码。
极简入门
引用:Command cgo
首先,通过import “C”导入伪包(这个包并不真实存在,也不会被Go的compile组件见到,它会在编译前被CGO工具捕捉到,并做一些代码的改写和桩文件的生成)
import "C"
然后,Go 就可以使用C的变量和函数了, C.size_t 之类的类型、诸如 C.stdout 之类的变量或诸如 C.putchar 之类的函数。
func main(){
cInt := C.int(1) // 使用C中的int类型
fmt.Println(goInt)
ptr := C.malloc(20) // 调用C中的函数
fmt.Println(ptr) // 打印指针地址
C.free(ptr) // 释放,需要 #include 如果“C”的导入紧跟在注释之前,则该注释称为序言。例如:
// #include
/* #include */
import "C"
序言可以包含任何 C 代码,包括函数和变量声明和定义。然后可以从 Go 代码中引用它们,就好像它们是在包“C”中定义的一样。可以使用序言中声明的所有名称,即使它们以小写字母开头。例外:序言中的静态变量不能从 Go 代码中引用;静态函数是允许的。
所以,你可以直接在/**/里面写C代码(注意,C++不行!):
package main
/*
int add(int a,int b){
return a+b;
}
*/
import "C"
import "fmt"
func main() {
a, b := 1, 2
c := C.add(a, b)
}
编译下,会出现下面的问题( fmt.Println(C.add(1, 2)) 能编译通过,思考下为什么? ):
./main.go:20:12: cannot use a (type int) as type _Ctype_int in argument to _Cfunc_add
./main.go:20:12: cannot use b (type int) as type _Ctype_int in argument to _Cfunc_add
为什么呢?因为C没有办法使用Go的类型,必须先转换成CGO类型才可以,改成这样就行了:
func main() {
cgoIntA, cgoIntB := C.int(1), C.int(2)
c := C.add(cgoIntA, cgoIntB)
fmt.Println(c)
}
运行后输出:
3
CGO基础类型
就像上面的代码一样,Go没有办法直接使用C的东西,必须先转换成CGO类型,下面是一个基础类型对应表。
| C类型 | CGO类型 | GO类型 |
|---|---|---|
| char | C.char | byte |
| signed char | C.schar | int8 |
| unsigned char | C.uchar | uint8 |
| short | C.short | int16 |
| unsigned short | C.ushort | uint16 |
| int | C.int | int32 |
| unsigned int | C.uint | uint32 |
| long | C.long | int32 |
| unsigned long | C.ulong | uint32 |
| long long int | C.longlong | int64 |
| unsigned long long int | C.ulonglong | uint64 |
| float | C.float | float32 |
| double | C.double | float64 |
| size_t | C.size_t | uint |
如果直接在C中#include
| C类型 | CGO类型 | GO类型 |
|---|---|---|
| int8_t | C.int8_t | int8 |
| int16_t | C.int16_t | int16 |
| uint32_t | C.uint32_t | uint32 |
| uint64_t | C.uint64_t | uint64 |
字符串、数组和函数调用
那么,在Go要如何传递字符串、字节数组以及指针?
CGO的C虚拟包提供了以下一组函数,用于Go语言和C语言之间数组和字符串的双向转换:
// Go string to C string
// The C string is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CString(string) *C.char
// Go []byte slice to C array
// The C array is allocated in the C heap using malloc.
// It is the caller's responsibility to arrange for it to be
// freed, such as by calling C.free (be sure to include stdlib.h
// if C.free is needed).
func C.CBytes([]byte) unsafe.Pointer
// C string to Go string
func C.GoString(*C.char) string
// C data with explicit length to Go string
func C.GoStringN(*C.char, C.int) string
// C data with explicit length to Go []byte
func C.GoBytes(unsafe.Pointer, C.int) []byte
字符串,可以通过C.CString()函数(别忘记通过free释放):
// 通过C.CString,这里会发生内存拷贝,cgo通过malloc重新开辟了一块空间,使用完需要释放,否则内存泄露
imagePath := C.CString("a.png")
defer C.free(unsafe.Pointer(imagePath))
字节数组,直接使用go的数组,然后强制转换即可:
// 只能使用数组,无法使用切片用作缓冲区给C使用
var buffer [20]byte
// &buffer[0]: 数组在内存中是连续存储的,取首地址
// unsafe.Pointer():转换为非安全指针,类型是*unsafe.Pointer
// (*C.char)():再强转一次
cBuffer := (*C.char)(unsafe.Pointer(&buffer[0]))
对应类型的指针,直接使用Cgo类型,然后&取地址即可:
bufferLen := C.int(20)
cPoint := &bufferLen // cPoint在CGO中是*C.int类型,在C中是*int类型。
假如ocr识别函数如下:
int detect(const char* image_path, char * out_buffer, int *len);
有3个参数:
- image_path:指示了要识别的图片路径。
- out_buffer:识别到的文字输出到这里,是一个char字节数组。
- len:指示输出字节缓冲区大小,调用成功后,值变成字符串长度,便于外界读取。
在go中调用方式如下:
imagePath := C.CString("a.png")
defer C.free(unsafe.Pointer(imagePath))
var buffer [20]byte
bufferLen := C.int(20)
cInt := C.detect(imagePath, (*C.char)(unsafe.Pointer(&buffer[0])), &bufferLen)
if cInt == 0 {
fmt.Println(string(buffer[0:bufferLen]))
}
CGO实战
分离Go和C代码
为了简化代码,我们可以把C的代码放到xxx.h和xxx.c中实现。
有以下结构:
├── hello.c
├── hello.h
└── main.go
hello.h的内容:
#include hello.c:
#include "hello.h"
void sayHello(const char* text){
printf("%s", text);
}
main.go中调用hello.h中的函数:
#include "hello.h"
import "C" // 必须放在导入c代码活头文件的注释后面,否则不生效
func main() {
cStr := C.CString("hello from go")
defer C.free(unsafe.Pointer(cStr))
C.sayHello(cStr)
}
常用cgo编译指令
如果我们把h和c文件放到其他目录,则编译会报错:
├── main.go
└── mylib
├── hello.c
└── hello.h
Undefined symbols for architecture x86_64:
"_sayHello", referenced from:
__cgo_7ab15a91ce47_Cfunc_sayHello in _x002.o
(maybe you meant: __cgo_7ab15a91ce47_Cfunc_sayHello)
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
这里应该可以使用#cgo预编译解决(CFLAGS、CPPFLAGS、CXXFLAGS、FFLAGS和LDFLAGS) :
// #cgo CFLAGS: -DPNG_DEBUG=1 -I ./include
// #cgo LDFLAGS: -L /usr/local/lib -lpng
// #include - CFLAGS:-D部分定义了宏PNG_DEBUG,值为1。-I定义了头文件包含的检索目录
- LDFLAGS:-L指定了链接时库文件检索目录,-l指定了链接时需要链接png库
通常实际的工作中遇到要使用cgo的场景,都是调用动态库的方式,所以这里没有继续往下深究上面的错误如何解决了。
调用C静态库和动态库
目录结构如下:
├── call_shared_lib
│ └── main.go
├── call_static_lib
│ └── main.go
└── mylib
├── hello.c
├── hello.h
├── libhello.a
└── libhello.so
静态库
把上面的hello.h 和 hello.c 生成为静态库(需要安装gcc,省略):
# 生成o对象
$ gcc -c hello.c
# 生成静态库
$ ar crv libhello.a hello.o
# 查看里面包含的内容
# ar -t libhello.a
# 使用静态库
#gcc main.c libhello.a -o main
在go中调用:
package main
/*
#cgo CFLAGS: -I ../mylib
#cgo LDFLAGS: -L ../mylib -lhello
#include
#include "hello.h"
*/
import "C"
import "unsafe"
func main() {
cStr := C.CString("hello from go")
defer C.free(unsafe.Pointer(cStr))
C.sayHello(cStr)
}
- CFLAGS:C的编译参数,-I指示 include路径
- LDFLAGS: 链接参数,-L 指示搜索静态库的路径,-lhello表示链接libhello.a,记住lib这里不用写,编译器会自己补全。
动态库
生成
# 生成o对象
$ gcc -fPIC -c hello.c
# 生成动态库
$ gcc -shared -fPIC -o libhello.so hello.o
# 使用动态库
#gcc main.c -L. -lhello -o main
Go中调用和静态库一样:
package main
// 注意,生成的so文件一定的得增加lib前缀,如libhello.so
// 然后在Go中只需要写-lhello(代表libhello.a或libhello.so)即可
// linux下会自动增加lib前缀。
/*
#cgo CFLAGS: -I ../mylib
#cgo LDFLAGS: -L ../mylib -lhello
#include
#include "hello.h"
*/
import "C"
import "unsafe"
func main() {
cStr := C.CString("hello from go")
defer C.free(unsafe.Pointer(cStr))
C.sayHello(cStr)
}
唯一不同的是,静态库需要指定so文件的搜索路径或者把so动态库拷贝到/usr/lib下,在环境变量中配置:
$ export LD_LIBRARY_PATH=../mylib
$ go run main.go
# 也可以在goland中在Run -> Edit Configurations -> Environment
# 配置 LD_LIBRARY_PATH=../mylib ,方便调试
更多关于静态库和动态库的区别:https://segmentfault.com/a/1190000020651578
调用C++动态库
本质上和调用c动态库在Go的写法上是一样的,只是需要导出成C风格的即可:
#ifdef __cplusplus
extern "C"
{
#else
// 导出C 命名风格函数,函数名字和定义的一样,C++因为支持重载,所以导出的函数名被编译器改变了
#ifdef __cplusplus
}
#endif
然后在go的LDFLAGS中增加 -lstdc++:
#cgo LDFLAGS: -L ../mylib -lhello -lstdc++
CGO的缺陷
cgo is not Go中总结了cgo 的缺点:
- 编译变慢,实际会使用 c 语言编译工具,还要处理 c 语言的跨平台问题
- 编译变得复杂
- 不支持交叉编译
- 其他很多 go 语言的工具不能使用
- C 与 Go 语言之间的的互相调用繁琐,是会有
性能开销的 - C 语言是主导,这时候 go 变得不重要,其实和你用 python 调用 c 一样
- 部署复杂,不再只是一个简单的二进制
这篇文章描述了CGO通过go去调用C性能开销大的原因:https://blog.csdn.net/u010853261/article/details/108186405
- 必须切换go的协程栈到系统线程的主栈去执行C函数
- 涉及到系统调用以及协程的调度。
- 由于需要同时保留C/C++的运行时,CGO需要在两个运行时和两个ABI(抽象二进制接口)之间做翻译和协调。这就带来了很大的开销。
《GO原本》中进一步通过runtime源码解读了原因。
所以,使用的时候,自己灵活根据场景取舍吧。
CGO最佳使用场景总结
CGO的一些缺点:
- 内存隔离
- C函数执行切换到g0(系统线程)
- 收到GOMAXPROC线程限制
- CGO空调用的性能损耗(50+ns)
- 编译损耗(CGO其实是有个中间层)
CGO 适合的场景:
C 函数是个大计算任务(不在乎CGO调用性能损耗)C 函数调用不频繁- C 函数中不存在阻塞IO
- C 函数中不存在新建线程(与go里面协程调度由潜在可能互相影响)
- 不在乎编译以及部署的复杂性
更多可以阅读:
- 【Free Style】CGO: Go与C互操作技术(一):Go调C基本原理
- 【Free Style】CGO: Go与C互操作技术(三):Go调C性能分析及优化
- Go语言使用cgo时的内存管理笔记
CGO案例:在Go中调用动态库实现OCR文字识别
chineseocr_lite介绍
GitHub: https://github.com/DayBreak-u/chineseocr_lite
Star: 7.1 k
介绍:超轻量级中文ocr,支持竖排文字识别, 支持ncnn、mnn、tnn推理 ( dbnet(1.8M) + crnn(2.5M) + anglenet(378KB)) 总模型仅4.7M。
这个开源项目提供了C++、JVM、Android、.Net等实现,只依赖OpenCV和微软的Onnx推理框架,有源码,经作者实践,识别效果中等,越小的图片越快。
识别效果
比如识别一个发票号码,只需要50ms左右:
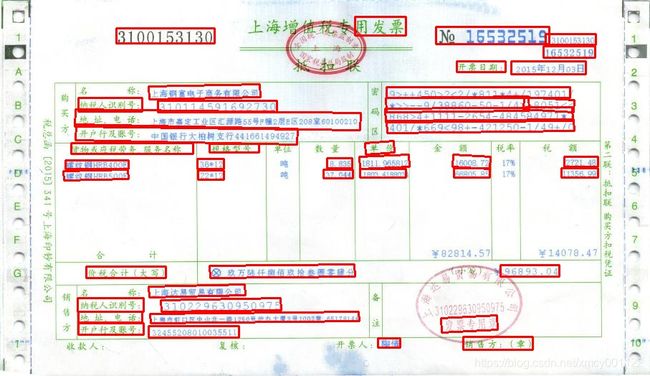
复杂的图片识别大概500-900ms左右:
表格识别效果一般
所以,适合格式一致的识别场景。比如发票的某个位置,身份证,银行卡等等。
编译chineseocr_lite
按照 chineseocr_lite/cpp_projects/OcrLiteOnnx 中的README.md文档编译即可,推荐在Linux下,我再windows和Macos没编译通过。
然后需要改造成动态库,我改动的内容有:
- 默认生成动态库,给ocr_http_server使用
- 去掉jni的支持
- 增加ocr.h,导出c风格函数
导出c函数
ocr.h
/** @file ocr.h
* @brief 封装给GO调用
* @author teng.qing
* @date 8/13/21
*/
#ifndef ONLINE_BASE_OCRLITEONNX_OCR_H
#define ONLINE_BASE_OCRLITEONNX_OCR_H
#ifdef __cplusplus
extern "C"
{
#else
// c
typedef enum{
false, true
}bool;
#endif
const int kOcrError = 0;
const int kOcrSuccess = 1;
const int kDefaultPadding = 50;
const int kDefaultMaxSideLen = 1024;
const float kDefaultBoxScoreThresh = 0.6f;
const float kDefaultBoxThresh = 0.3f;
const float kDefaultUnClipRatio = 2.0f;
const bool kDefaultDoAngle = true;
const bool kDefaultMostAngle = true;
/**@fn ocr_init
*@brief 初始化OCR
*@param numThread: 线程数量,不超过CPU数量
*@param dbNetPath: dbnet模型路径
*@param anglePath: 角度识别模型路径
*@param crnnPath: crnn推理模型路径
*@param keyPath: keys.txt样本路径
*@return <0: error, >0: instance
*/
int ocr_init(int numThread, const char *dbNetPath, const char *anglePath, const char *crnnPath, const char *keyPath);
/**@fn ocr_cleanup
*@brief 清理,退出程序前执行
*/
void ocr_cleanup();
/**@fn ocr_detect
*@brief 识别图片
*@param image_path: 图片完整路径,会在同路径下生成图片识别框选效果,便于调试
*@param out_json_result: 识别结果输出,json格式。
*@param buffer_len: 输出缓冲区大小
*@param padding: 50
*@param maxSideLen: 1024
*@param boxScoreThresh: 0.6f
*@param boxThresh: 0.3f
*@param unClipRatio: 2.0f
*@param doAngle: true
*@param mostAngle: true
*@return 成功与否
*/
int ocr_detect(const char *image_path, char *out_buffer, int *buffer_len, int padding, int maxSideLen,
float boxScoreThresh, float boxThresh, float unClipRatio, bool doAngle, bool mostAngle);
/**@fn ocr_detect
*@brief 使用默认参数,识别图片
*@param image_path: 图片完整路径
*@param out_buffer: 识别结果,json格式。
*@param buffer_len: 输出缓冲区大小
*@return 成功与否
*/
int ocr_detect2(const char *image_path, char *out_buffer, int *buffer_len);
#ifdef __cplusplus
}
#endif
#endif //ONLINE_BASE_OCRLITEONNX_OCR_H
ocr.cpp
/** @file ocr.h
* @brief
* @author teng.qing
* @date 8/13/21
*/
#include "ocr.h"
#include "OcrLite.h"
#include "omp.h"
#include "json.hpp"
#include ocr_wrapper.go
package ocr
// -I: 配置编译选项
// -L: 依赖库路径
/*
#cgo CFLAGS: -I ../../../OcrLiteOnnx/include
#cgo LDFLAGS: -L ../../../OcrLiteOnnx/lib -lOcrLiteOnnx -lstdc++
#include
#include
#include "ocr.h"
*/
import "C"
import (
"runtime"
"unsafe"
)
//const kModelDbNet = "dbnet.onnx"
//const kModelAngle = "angle_net.onnx"
//const kModelCRNN = "crnn_lite_lstm.onnx"
//const kModelKeys = "keys.txt"
const kDefaultBufferLen = 10 * 1024
var (
buffer [kDefaultBufferLen]byte
)
func Init(dbNet, angle, crnn, keys string) int {
threadNum := runtime.NumCPU()
cDbNet := C.CString(dbNet) // to c char*
cAngle := C.CString(angle) // to c char*
cCRNN := C.CString(crnn) // to c char*
cKeys := C.CString(keys) // to c char*
ret := C.ocr_init(C.int(threadNum), cDbNet, cAngle, cCRNN, cKeys)
C.free(unsafe.Pointer(cDbNet))
C.free(unsafe.Pointer(cAngle))
C.free(unsafe.Pointer(cCRNN))
C.free(unsafe.Pointer(cKeys))
return int(ret)
}
func Detect(imagePath string) (bool, string) {
resultLen := C.int(kDefaultBufferLen)
// 构造C的缓冲区
cTempBuffer := (*C.char)(unsafe.Pointer(&buffer[0]))
cImagePath := C.CString(imagePath)
defer C.free(unsafe.Pointer(cImagePath))
isSuccess := C.ocr_detect2(cImagePath, cTempBuffer, &resultLen)
return int(isSuccess) == 1, C.GoStringN(cTempBuffer, resultLen)
}
func CleanUp() {
C.ocr_cleanup()
}
环境变量设置
路径包含库所在目录,或者直接把动态库拷贝到/usr/lib中,推荐后者:
export LD_LIBRARY_PATH=../mylib
运行
效果如下

参考
- 【Free Style】CGO: Go与C互操作技术(一):Go调C基本原理
- 【Free Style】CGO: Go与C互操作技术(三):Go调C性能分析及优化
- Command cgo
- C? Go? Cgo!
- How to use C++ in Go?
- 深入学习CGO
- 如何把Go调用C的性能提升10倍?
- Go语言使用cgo时的内存管理笔记
- GO原本:cgo
- CGO 和 CGO 性能之谜
- cgo is not Go
- 深入CGO编程(Gopherchina2018)
- how-to-use-c-in-go
- 使用gcc生成静态库和动态库
- 如何使用GCC生成动态库和静态库
- gcc编译工具生成动态库和静态库之一----介绍