性能测试分析与性能调优诊断--史上最全的服务器性能分析监控调优篇
性能测试分析与性能调优诊断--史上最全的服务器性能分析监控调优篇
from:https://www.cnblogs.com/laoqing/p/11629941.html
一个系统或者网站在功能开发完成后一般最终都需要部署到服务器上运行,那么服务器的性能监控和分析就显得非常重要了,选用什么配置的服务器、如何对服务器进行调优、如何从服务器监控中发现程序的性能问题、如何判断服务器的瓶颈在哪里等 就成为了服务器性能监控和分析时重点需要去解决的问题了。
本文章节目录:
1 服务器的性能监控和分析
1.1、 Linux服务器的性能指标监控和分析
1.1.1 、 通过vmstat深挖服务器的性能问题
1.1.2 、 如何通过mpstat 分析服务器的性能指标
1.1.3 、 从lsof中能看到什么
1.1.4 、 如何通过free看懂内存的真实使用
1.1.5、 网络流量如何监控
1.1.6 、 nmon对Linux服务器的整体性能监控
1.1.7 、 如何通过top发现问题
1.1.8、 如何通过pidstat发现性能问题
1.2 、 Windows服务器的性能指标监控和分析
1.2.1、 Windows性能监视器
1.2.2、 Windows性能监视器下的性能分析
备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。
1.1 、 Linux服务器的性能指标监控和分析
1.1.1 、通过vmstat深挖服务器的性能问题
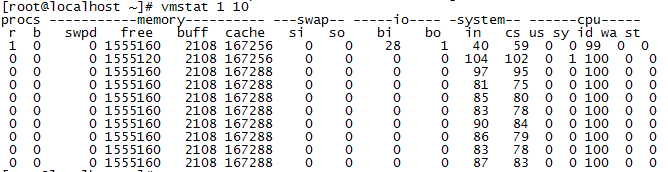
vmstat差不多是性能测试时在linux服务器上执行最多的命令,使用该命令往往能辅助我们进行很多的性能问题定位。
我们先来看一下执行vmstat 命令后,获取到的服务器的资源使用的监控数据有哪些。
 转存失败重新上传取消
转存失败重新上传取消
我们在执行vmstat 的时候,后面加了两个参数,其中参数1代表每隔1秒获取一次服务器的资源使用数据,10代表总共获取10次。
| 指标 |
含义 |
| r |
r是第一列的监控数据,代表了目前实际在运行的指令队列(也就是有多少任务需要CPU来进行执行),从数据来看,这台服务器目前CPU的资源比较空闲,如果发现这个数据超过了服务器CPU的核数,就可能会出现CPU瓶颈了(在判断时,还需要结合CPU使用的百分比一起来看,也就是上图中最后5列的数据指标),一般该数据超出了CPU核数的3个时,就比较高了,超出了5个就很高了,如果都已经超过了10时,那就很不正常了,服务器的状态就很危险了。如果运行队列超过CPU核数过多,表示CPU很繁忙,通常会造成CPU的使用率很高。 |
| b |
b是第二列的监控数据,表示目前因为等待资源而阻塞运行的指令个数,比如因为等待I/O、内存交换、CPU等资源而造成了阻塞,该值如果过高了的话,就需要检查服务器上I/O、内存,CPU等资源是不是出现了瓶颈。 |
| swpd |
swpd是第三列的监控数据,表示虚拟内存(swap)已使用的大小(swap指的是服务器的物理运行内存不够用的时候,会把物理内存中的部分空间释放出来,以供需要运行的程序去使用,而那些释放出来的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间会被临时保存到Swap中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中,swap分区一般使用的都是磁盘的空间,磁盘的I/O读写一般会比物理内存慢很多,如果存在大量的swap读写交换,将会非常影响程序运行的性能),也就是切换到内存交换区的内存数量(单位为k),此处需要注意,并不是swpd的值大于0,就是服务器的物理内存已经不够用了,通常还需要结合si和so这两个数据指标来一起分析,如果si和so 还维持在0左右,那服务器的物理内存还是够用的。 |
| free |
free是第四列的监控数据,表示空闲的物理内存的大小,就是还有多少物理内存没有被使用(单位为k),这个free的数据是不包含buff和cache这两列的数据值在内的。 |
| buff |
buff 是第五列的监控数据,表示作为Linux/Unix系统的缓存的内存大小(单位为k),一般对块设备的读写才需要缓冲,一般内存很大的服务器,这个值一般都会比较大,操作系统也会自动根据服务器的物理内存去调整缓冲区的内存使用大小,以提高读写的速度。 |
| cache |
cache是第6列的监控数据,表示用来给已经打开的文件做缓冲的内存大小,cache直接用来记忆我们打开的文件,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用,当空闲的物理内存不足时(即free的内存不足),这些缓存的内存便可以释放出来。 |
| si |
si是第7列的监控数据,表示每秒从磁盘(虚拟内存swap)读入到内存的大小,如果这个值长期大于0,那物理运行内存可能已经是不够用了。 |
| so |
so是第8列的监控数据,表示每秒写入磁盘(虚拟内存swap)的内存大小,so刚好和si相反,si一般是将磁盘空间调入内存,so一般是将内存数据调入磁盘。 |
| bi |
bi是第9列的监控数据,表示块设备每秒读取的块数量(从磁盘读取数据,这个值一般表示每秒读取了磁盘的多少个block),这里的块设备(block)是指系统上所有的磁盘和其他块设备,默认块大小是1024byte。 |
| bo |
bo是第10列的监控数据,表示块设备每秒写入的块数量(往磁盘写入数据,这个值一般表示每秒有多少个block写入了磁盘)。通常情况下,随机磁盘读写的时候,bi和bo这2个值越大(如超出1024k),能看到CPU在IO等待的值也会越大。 |
| in |
in是第11列的监控数据,表示 每秒CPU的中断次数,包括时钟中断。 |
| cs |
cs是第12列的监控数据,表示 CPU每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。系统运行时,如果观察到in和cs 这两个指标非常高,那就需要对系统进行性能调优了。 |
| us |
us(user time)是第13列的监控数据,表示用户模式CPU使用时间的百分比,该值一般越高,说明CPU被正常利用的越好,笔者曾经在给一个机器学习算法(密集型CPU应用)做压力测试时,us的值可以接近100,那说明CPU已经充分被算法服务使用了。 |
| sy |
sy是第14列的监控数据,表示系统内核进程执行时间百分比(system time),sy的值高时,说明系统内核消耗的CPU资源多,这并不是一个服务器性能好的表现,通常in、cs、io的频繁操作等过高,都会引起sy的指标过高,这个时候我们应该要去定位原因了。 |
| id |
id是第15列的监控数据,表示空闲 CPU时间的占比,一般来说,id + us + sy = 100,一般可以认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。 |
| wa |
wa是第16列的监控数据,表示I/O等待时间百分比,wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作) |
| st |
st是第17列的监控数据,表示CPU等待虚拟机调度的时间占比,这个指标一般在虚拟机中才会有,物理机中,该值一般维持为0,我们都知道虚拟机中的CPU一般是物理机CPU的虚拟核,一台物理机一般会有多个虚拟机同时在运行,那么此时虚拟机之间就会存在CPU的争抢情况,比如某台虚拟机上运行着占用CPU很高的密集型计算,就会导致其他的虚拟机上的CPU需要一直等待密集型计算的虚拟机上CPU的释放,st就是等待时间占CPU时间的占比,该值如果一直持续很高,那么表示虚拟服务器需要长期等待CPU,运行在该服务器的应用程序的性能会受到直接的影响,笔者曾经在压测时发现,该值越高,也会引起sy的值变高(因为操作系统内核需要不断的去调度CPU)。 |
vmstat还可以支持其他的参数使用,我们可以通过执行vmstat --help 命令查看到它支持的其他参数
备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。文章链接:https://www.cnblogs.com/laoqing/p/11629941.html

l -a, --active 显示活跃和非活跃的内存
l -f, --forks 显示操作系统从启动至今的fork数量,fork一般指的就是启动过的进程数量,linux操作系统用fork()函数来创建进程。
l -m, --slabs 显示slab的相关信息,slab是linux内核中按照对象大小进行分配的内存分配器,通过slab的信息可以来查看各个内核模块占用的内存空间,可以通过cat /proc/meminfo |grep Slab 命令查看Slab占用的总内存大小,如果占用的内存过大,那么可能是内核模块出现了内存泄漏了。
l -n, --one-header 这个参数表示只显示头部第一行的信息
l -s, --stats event counter statistics 显示内存相关的统计信息及多种系统操作活动发生数量统计,比如CPU时钟中断的次数,CPU上下文切换的次数等。
l -d, --disk disk statistics 显示每一块磁盘I/O相关的明细信息
l -D, --disk-sum 显示磁盘I/O相关的汇总信息,-D 显示的信息是对-d参数显示的每个磁盘块的信息的汇总。
l -p, --partition
l -S, --unit
l -w, --wide wide output 这个参数用于调整命令输出结果的显示方式,输出的结果和单独执行vmstat命令得到的结果是完全一样,只是在输出时,会以更宽的宽度来展示数据。
l -t, --timestamp show timestamp 在vmstat命令输出的数据的基础上,增加每次获取数据时的当前时间戳的输出显示
l -V, --version output version information and exit 输出vmstat命令得版本信息
1.1.2、 如何通过mpstat 分析服务器的性能指标
linux中的mpstat 命令也是在性能测试时经常用来监控服务器整体性能指标的一种方式,mpstat命令和上面我们讲到的vmstat命令非常类似,我们来看一下执行vmstat 命令后,获取到的服务器的资源使用的监控数据。

我们在执行mpstat的时候,后面同样加了两个参数,其中参数1代表每隔1秒获取一次服务器的资源使用数据,10代表总共获取10次,这点和vmstat的使用很类似。
l %usr 表示的是用户模式下CPU使用时间的百分比,和vmstat中得到的us数据基本一致
l %nice 表示CPU在进程优先级调度下CPU占用时间的百分比,在操作系统中,进程的运行是可以设置优先级的,linux操作系统也是一样,优先级越高的,获取到CPU运行的机会越高。这个值一般的时候都会是0.00,但是一旦我们在程序运行时,修改过默认优先级时,%nice就会产生占用时间的百分比,在linux中,执行top或者ps命令时,通常会输出PRI/PR、NI、%ni/%nice这三个指标。
- PRI:表示进程执行的优先级,值越小,优先级就越高,会越早获得CPU的执行权。
- NI:表示进程的Nice值,表示进程可被执行的优先级的修正数值,PRI值越小会越早被CPU执行,在加入Nice值后,将会使得PRI的值发生变化,新的PRI值=老的PRI值+Nice值,那么可以看出PRI的排序是和Nice密切相关的,Nice值越小,那么PRI值就会越小,就会越早被CPU执行,在Linux操作系统中如果Nice值相同时进程uid为root进程的执行优先级会更高。通常情况下,子进程会继承父进程的Nice值,在操作系统启动时init进程会被赋予0,其它进程(其它的进程基本都是init进程开辟的子进程)会自动继承这个Nice值。
- %ni/%nice:可以形象的表示为改变过优先级的进程的占用CPU的百分比,即可以理解为Nice值影响了内核分配给进程的cpu时间片的多少。
l %sys表示系统内核进程执行时间百分比(system time),该值越高时,说明系统内核消耗的CPU资源越多,和vmstat命令中的sy数据基本一致。
l %iowait表示I/O等待时间百分比,该值越高时,说明IO等待越严重,和vmstat命令中的wa数据基本一致。
l %irq表示用于处理系统中断的 CPU 百分比,和vmstat命令中的in数据的含义类似,in越高,那么%irq也会越高。
l %soft表示用于软件中断的 CPU 百分比。
l %steal 表示CPU等待虚拟机调度的时间占比,这个指标一般在虚拟机中才会有,物理机中该值一般维持为0,和vmstat命令中的st数据基本一致。
l %guest表示运行vCPU(虚拟处理器)时所消耗的cpu时间百分比
l %gnice表示运行降级虚拟程序所使用的CPU占比
l %idle表示空闲 CPU时间的占比,和vmstat命令中的id数据基本一致。
我们上面通过执行mpstat 1 10 获取到的是服务器中所有的CPU核数的汇总数据,所以可以看到在显示时,CPU列显示的为all,如果我们需要查看服务器中么某一个CPU核的资源使用情况,可以在执行mpstat命令时,加上-P 这个参数,比如执行mpstat -P 0 1 10 命令可以获取到服务器中CPU核编号为0的CPU核的资源的使用情况(CPU核的编号是从0开始,比如图中我们的服务器有2个CPU核那么CPU核的编号就是0和1)。
 转存失败重新上传取消
转存失败重新上传取消
备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。文章链接:https://www.cnblogs.com/laoqing/p/11629941.html
1.1.3 、 从lsof中能看到什么
lsof 是对Linux操作系统中对文件进行监控的一个常用命令,使用该命令可以列出当前系统打开了哪些文件,系统中某个进程打开了哪些文件等。
我们直接执行lsof即可以显示当前操作系统打开了哪些文件,lsof命令必须运行在root用户下,这是因为lsof命令执行时需要访问核心内存和内核文件,如下图所示,我们直接执行lsof命令后得到的结果。
 转存失败重新上传取消
转存失败重新上传取消
l 第1列展示的为进程的名称,图中显示的进程名称为nginx。
l 第2列展示的为进程的id编号(也就是Linux操作系统中常说的PID)
l 第3列展示的为进程的所有者,也就是这个进程是运行在哪个Linux用户下的,可以看到图中的进程基本都是运行在root用户下,这是因为我在启动nginx时,就是在root用户下来启动的
l 第4列展示的为文件描述符(File Descriptor number),常见的类型如下
| 文件描述符简称 |
英文全称 |
中文解释 |
| cwd |
current working directory |
当前工作的目录 |
| mem |
memory-mapped file |
代表把磁盘文件映射到内存中 |
| txt |
program text |
进程运行的程序文件,包括编译后的代码文件以及产生的数据文件等,图中的nginx命令文件就属于txt类型。 |
| rtd |
root directory |
代表root目录 |
| pd |
parent directory |
父目录 |
| DEL |
a Linux map file that has been deleted |
代表已经删除的Linux映射文件 |
| 数字+字符,如0u、1w、2w等 |
|
0:表示标准输出 1:表示标准输入 2:表示标准错误 u:表示该文件被打开并处于读取/写入模式 r:表示该文件被打开并处于只读模式 w:表示该文件被打开并处于只写入模式 |
l 第5列展示的为打开的文件类型,常见的类型如下
| 类型 |
英文全称 |
解释 |
| DIR |
directory |
代表了一个文件目录 |
| CHR |
character special file |
特殊字符文件 |
| LINK |
symbolic link file |
链接文件 |
| IPv4 |
IPv4 socket |
IPv4 套接字文件 |
| IPv6 |
IPv6 network file |
打开了一个IPV6的网络文件 |
| REG |
regular file |
普通文件 |
| FIFO |
FIFO special file |
先进先出的队列文件 |
| unix |
UNIX domain socket |
unix下的域套接字,也称inter-process communication socket,也就是常说的IPC scoket(进程间的通信scoket),在开发中经常会被使用的一种通讯方式。 |
| MPB |
multiplexed block file |
多路复用的块文件 |
| MPC |
multiplexed character file |
多路复用的字符文件 |
| inet |
an Internet domain socket |
Intent 域套接字 |
l 第6列展示的是使用character special、block special表示的设备号
l 第7列展示的是文件的大小(前提是文件有效)
l 第8列展示的是操作系统本地文件的node number或者协议类型(在网络通讯的情况下会展示通讯协议类型,比如如下nginx的LISTEN监听进程就是一个TCP协议)
![]()
l 第9列展示的是文件的绝对路径或者网络通讯链接的地址、端口、状态或者挂载点等。
lsof 还可以支持其他的参数使用,常见的使用如下:
l lsof –c 查看某个进程名称当前打开了哪些文件,例如执行lsof –c nginx命令可以查看nginx进程当前打开了哪些文件
 转存失败重新上传取消
转存失败重新上传取消
l lsof –p 查看某个进程id 当前打开了哪些文件,例如执行lsof –p 1 命令可以查看进程id为1的进程当前打开了哪些文件
 转存失败重新上传取消
转存失败重新上传取消
l lsof –i 查看IPv4、IPv6下打开的文件,此时看到的大部分都是网络的链接通讯,会包括服务端的LISTEN监听或者客户端和服务端的网络通讯。

在lsof –i后加上 :(冒号) 端口号时,可以定位到某个端口下的IPv4、IPv6模式打开的文件和该端口下的网络链接通讯,例如执行lsof –i:80命令可以查看一下80端口下的网络链接通讯情况

从这个展示的通讯情况可以看到,80端口下起了两个LISTEN监听进程,分别是在root用户下和nobody用户下,并且可以看到ip为192.168.1.100的电脑和80端口进行了TCP通讯链接,TCP通讯链接的状态为
ESTABLISHED,并且链接时占用了服务器上的53151和53152 这两个端口。
TCP通讯链接是在做性能测试时经常需要关注的,尤其是在高并发的情况下如何优化TCP链接数和TCP链接的快速释放,是性能调优的一个关注点。链接的常用状态如下
| 状态 |
解释 |
| LISTEN |
监听状态,这个一般应用程序启动时,会启动监听,比如nginx程序启动后,就会产生监听进程,一般的时候,监听进程的端口都是可以自己进行设置,以防止端口冲突 |
| ESTABLISHED |
链接已经正常建立,表示客户端和服务端正在通讯中。 |
| CLOSE_WAIT |
客户端主动关闭连接或者网络异常导致连接中断,此时这次链接下服务端的状态会变成CLOSE_WAIT,需要服务端来主动进行关闭该链接。 |
| TIME_WAIT |
服务端主动断开链接,收到客户端确认后链接状态变为TIME_WAIT,但是服务端并不会马上彻底关闭该链接,只是修改了状态。TCP协议规定TIME_WAIT状态会一直持续2MSL的时间才会彻底关闭,以防止之前链接中的网络数据包因为网络延迟等原因延迟出现。处于TIME_WAIT状态的连接占用的资源不会被内核释放,所以性能测试中如果服务端出现了大量的TIME_WAIT状态的链接就需要分析原因了,一般不建议服务端主动去断开链接。 |
| SYN_SENT |
表示请求正在链接中,当客户端要访问服务器上的服务时,一般都需要发送一个同步信号给服务端的端口,在此时链接的状态就为SYN_SENT,一般SYN_SENT状态的时间都是非常短,除非是在非常高的并发调用下,不然一般SYN_SENT状态的链接都非常少。 |
| SYN_RECV |
表示服务端接收到了客户端发出的SYN请求并且服务器在给客户端回复SYN+ACK后此时服务端所处的中间状态。 |
| LAST_ACK |
表示TCP连接关闭过程中的一种中间状态,关闭一个TCP连接需要发送方和接收方分别都进行关闭,双方都是通过发送FIN(关闭连接标志)来表示单方向数据的关闭,当通信双方发送了最后一个FIN的时候,发送方此时处于LAST_ACK状态。 |
| CLOSING |
表示TCP连接关闭过程中的一种中间状态,一般存在的时间很短不是经常可以看到,在发送方和接收方都主动发送FIN并且在收到对方对自己发送的FIN之前收到了对方发送的FIN的时候,两边就都进入了CLOSING状态。 |
| FIN_WAIT1 |
同样是表示TCP连接关闭过程中的一种中间状态,存在的时间很短一般几乎看不到,发送方或者调用方主动调用close函数关闭连接后会立刻进入FIN_WAIT1状态,此时只要收到对端的ACK确认后马上会进入FIN_WAIT2状态。 |
| FIN_WAIT2 |
同样是表示TCP连接关闭过程中的一种中间状态,主动关闭连接的一方在等待对端FIN到来的过程中通常会一直保持这个状态。一般网络中断或者对端服务很忙还没及时发送FIN或者对端程序有bug忘记关闭连接等都会导致主动关闭连接的一方长时间处于FIN_WAIT2状态。如果主动关闭连接的一方发现大量FIN_WAIT2状态时, 应该需要去检查是不是网络不稳定或者对端的程序存在连接泄漏的情况。 |
在TCP协议层中有一个FLAGS字段,这个字段一般包含SYN(建立连接标志)、 FIN(关闭连接标志)、 ACK(响应确认标志)、 PSH(DATA数据传输标志)、 RST(连接重置标志)、 URG(紧急标志)这几种标志,每种标志代表一种连接信号。
 转存失败重新上传取消
转存失败重新上传取消
不管是什么状态下的TCP链接,都会占用服务器的大量资源,而且每个链接都会占用一个端口,Linux服务器的TCP和UDP的端口总数是有限制的(0-65535),超过这个范围就没有端口可以用了,程序会无法启动,链接也会无法进行。所以如果服务端出现了大量的CLOSE_WAIT和TIME_WAIT的链接时,就需要去及时去查找原因和进行优化。CLOSE_WAIT状态一般大部分的时候,都是自己写的代码或者程序出现了明显的问题造成。
针对如果出现了大量的TIME_WAIT状态的链接,可以从服务器端进行一些优化以让服务器快速的释放TIME_WAIT状态的链接占用的资源。优化的方式如下
使用vim /etc/sysctl.conf来编辑sysctl.conf文件以优化Linux操作系统的文件内核参数设置,加入如下配置:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
然后执行sysctl –p命令可以内核让参数立即生效,这种调优一般在nginx、apache 这种web服务器上会经常用到。
- net.ipv4.tcp_syncookies = 1 表示开启syn cookies,当出现syn等待队列溢出时启用cookies来处理,默认情况下是关闭状态。客户端向linux服务器建立TCP通讯链接时会首先发送SYN包,发送完后客户端会等待服务端回复SYN+ACK,服务器在给客户端回复SYN+ACK后,服务器端会将此时处于SYN_RECV状态的连接保存到半链接队列中以等待客户端继续发送ACK请求给服务器端直到最终链接完全建立,在出现大量的并发请求时这个半链接队列中可能会缓存了大量的SYN_RECV状态的链接从而导致队列溢出,队列的长度可以通过内核参数net.ipv4.tcp_max_syn_backlog进行设置,在开启cookies后服务端就不需要将SYN_RECV状态的半状态链接保存到队列中,而是在回复SYN+ACK时将链接信息保存到ISN中返回给客户端,当客户端进行ACK请求时通过ISN来获取链接信息以完成最终的TCP通讯链接。
- net.ipv4.tcp_tw_reuse = 1 表示开启链接重用,即允许操作系统将TIME-WAIT socket的链接重新用于新的tcp链接请求,默认为关闭状态。
- net.ipv4.tcp_tw_recycle = 1 表示开启操作系统中TIME-WAIT socket链接的快速回收,默认为关闭状态。
- net.ipv4.tcp_fin_timeout = 30 设置服务器主动关闭链接时,scoket链接保持等待状态的最大时间。
- net.ipv4.tcp_keepalive_time = 600 表示请求在开启keepalive(现在一般客户端的http请求都是开启了keepalive选项)时TCP发送keepalive消息的时间间隔,默认是7200秒,在设置短一些后可以更快的去清理掉无效的请求。
- net.ipv4.tcp_max_tw_buckets = 5000 表示链接为TIME_WAIT状态时linux操作系统允许其接收的套接字数量的最大值,过多的TIME_WAIT套接字会使Web服务器变慢
- fs.file-max = 900000 表示linux操作系统可以同时打开的最大句柄数,在web服务器中,这个参数有时候会直接限制了web服务器可以支持的最大链接数,需要注意的是这个参数是对整个操作系统生效的。而ulimit –n 可以用来查看进程能够打开的最大句柄数,在句柄数不够时一般会出现类似” Too many open files”的报错。在Centos7中可以使用cat /proc/sys/fs/file-max 命令来查看操作系统可以能够打开的最大句柄数。

- 使用vi /etc/security/limits.conf 编辑limits.conf配置文件,可以修改进程能够打开的最大句柄数,在limits.conf增加如下配置即可
soft nofile 65535 hard nofile 65535
- net.ipv4.tcp_max_syn_backlog 表示服务器能接受SYN同步包的最大客户端连接数,也就是上面说的半连接的最大数量,默认值为128
- net.core.somaxconn = 2048 表示服务器能处理的最大客户端连接数,这里的连接指的是能同时完成连接建立的最大数量,默认值为128
- net.ipv4.tcp_synack_retries = 1 表示服务器在发送SYN+ACK回复后,在未继续收到客户端的ACK请求时服务器端重新尝试发送SYN+ACK回复的重试次数
- net.ipv4.ip_local_port_range =2048 65535 修改可以用于和客户端建立连接的端口范围,默认为32768到61000,修改后,可以避免建立连接时端口不够用的情况。
- net.core.rmem_max = 2187154 表示linux操作系统内核scoket接收缓冲区的最大大小,单位为字节
- net.core.wmem_max = 2187154表示linux操作系统内核scoket发送缓冲区的最大大小,单位为字节
- net.core.rmem_default = 250000 表示linux操作系统内核scoket接收缓冲区的默认大小,单位为字节
- net.core.wmem_default = 250000表示linux操作系统内核scoket发送缓冲区的默认大小,单位为字节
备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。文章链接:https://www.cnblogs.com/laoqing/p/11629941.html
l lsof +d 列出指定目录下被使用的文件,例如执行lsof +d /usr/lib/locale/ 命令查看/usr/lib/locale/ 目录下有哪些文件被打开使用了
 转存失败重新上传取消
转存失败重新上传取消
l lsof +D 和上面+d 参数的作用类似,也是列出指定目录下被使用的文件,不同的是+D会以递归的形式列出,也就是会列出指定目录下所有子目录下被使用的文件,而-d 参数只会列出当前指定目录下被使用的文件,
而不会继续去列出子目录下被使用的文件,例如执行lsof +D /usr/lib/ 命令查看/usr/lib/ 目录以及子目录下有哪些文件被打开使用了

l lsof 后面可以直接指定一个全路径的文件以列出该文件正在被哪些进程所使用,例如执行lsof /usr/lib/modules/3.10.0-862.el7.x86_64/modules.symbols.bin 命令可以查看到modules.symbols.bin文件目前正在被那个
进程使用
![]() 转存失败重新上传取消
转存失败重新上传取消![]()
l lsof –i:@ip 可以列出某个指定ip上的所有网络连接通讯,例如执行lsof [email protected] 命令可以查看到192.168.1.221这个ip上的所有的网络连接通讯

l lsof –i 网络协议 可以列出某个指定协议下的网络连接信息
lsof –i tcp 命令可以列出tcp下所有的网络连接信息

- lsof -i tcp:80 命令可以列出tcp下80端口所有的网络连接信息

- lsof –i udp 命令可以列出udp下所有的网络连接信息

- lsof -i udp:323 命令可以列出udp下323端口所有的网络连接信息

1.1.4 如何通过free看懂内存的真实使用
free命令是linux操作系统中对内存进行查看和监控的一个常用命令,我们可以直接执行free命令来看下可以获取到操作系统内存使用的哪些数据
 转存失败重新上传取消
转存失败重新上传取消
默认直接执行free 获取到的内存数据的单位都是k,Mem这一行展示的是物理内存的使用情况,Swap这一行展示的是内存交换区(通常也叫虚拟内存)的整体使用情况。
l total列展示的为系统总的可用物理内存和交换区的大小,单位为k
l used列展示的为已经被使用的物理内存和交换区的大小,单位为k
l free列展示的为还有多少物理内存和交换区没有被使用,单位为k
l shared 列展示的为共享区占用的物理内存大小,单位为k
l buff/cache 列展示的为被缓冲区和page高速缓存合计使用的物理内存大小,单位为k
- buff在操作系统中指的是缓冲区,是负责磁盘块设备的读写缓冲,会直接占用物理内存。
- cache 指的是操作系统中的 page cache(也就是通常所说的高速缓存),高速缓存是linux内核实现的磁盘缓存,可以减少内核对磁盘的I/O读写操作,会将磁盘中的数据缓存到物理内存中,这样对磁盘的访问就会变为对物理内存的访问,从而大大提高了读写速度。cache 有一点类似应用程序中使用redis来做缓存一样,把一些经常需要访问的数据存储到内存中来提高访问的速度。
l available 列展示的为还可以被使用的物理内存的大小,单位为k。通常情况下,available 的值等于free+ buff/cache ,linux内核为了提高磁盘读写的速度会使用一部分物理内存去缓存经常被使用的磁盘数据,所以buffer 和 cache对于Linux操作系统的内核来说都属于已经被使用的内存,而free列展示的是真实未被任何地方使用的物理内存,但是如果物理内存已经不够用并且应用程序恰巧又需要使用内存时内核就会从 buffer 和 cache 中回收内存来满足应用程序的使用,也就是说buffer 和 cache占用的内存是可以被内核释放的。
1.1.5 、 网络流量如何监控
备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。
在linux中,可以使用iftop命令来对服务器网卡的网络流量进行监控,iftop并不是linux操作系统中本身就有的工具,需要单独进行安装,可以从http://www.ex-parrot.com/~pdw/iftop/ 网站中下载iftop工具。
 转存失败重新上传取消
转存失败重新上传取消
下载完成后,首先执行./configure 命令进行安装前的自动安装配置检查
[root@localhost iftop-1.0pre4]# ./configure
checking build system type... x86_64-unknown-linux-gnu
checking host system type... x86_64-unknown-linux-gnu
........
configure: creating ./config.status
config.status: creating Makefile
config.status: creating config/Makefile
config.status: creating config.h
config.status: executing depfiles commands
configure: WARNING:
******************************************************************************
This is a pre-release version. Pre-releases are subject to limited
announcements, and therefore limited circulation, as a means of testing
the more widely circulated final releases.
Please do not be surprised if this release is broken, and if it is broken, do
not assume that someone else has spotted it. Instead, please drop a note on
the mailing list, or a brief email to me on [email protected]
Thank you for taking the time to be the testing phase of this development
process.
Paul Warren
******************************************************************************
备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。文章链接:https://www.cnblogs.com/laoqing/p/11629941.html
配置安装检查通过后,执行make && make install 命令对源码先进行编译,然后进行安装
[root@localhost iftop-1.0pre4]# make && make install
make all-recursive
make[1]: Entering directory `/home/iftop/iftop-1.0pre4'
Making all in config
make[2]: Entering directory `/home/iftop/iftop-1.0pre4/config'
make[2]: Nothing to be done for `all'.
make[2]: Leaving directory `/home/iftop/iftop-1.0pre4/config'
make[2]: Entering directory `/home/iftop/iftop-1.0pre4'
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT addr_hash.o -MD -MP -MF .deps/addr_hash.Tpo -c -o addr_hash.o addr_hash.c
mv -f .deps/addr_hash.Tpo .deps/addr_hash.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT edline.o -MD -MP -MF .deps/edline.Tpo -c -o edline.o edline.c
mv -f .deps/edline.Tpo .deps/edline.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT hash.o -MD -MP -MF .deps/hash.Tpo -c -o hash.o hash.c
mv -f .deps/hash.Tpo .deps/hash.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT iftop.o -MD -MP -MF .deps/iftop.Tpo -c -o iftop.o iftop.c
mv -f .deps/iftop.Tpo .deps/iftop.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT ns_hash.o -MD -MP -MF .deps/ns_hash.Tpo -c -o ns_hash.o ns_hash.c
mv -f .deps/ns_hash.Tpo .deps/ns_hash.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT options.o -MD -MP -MF .deps/options.Tpo -c -o options.o options.c
mv -f .deps/options.Tpo .deps/options.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT resolver.o -MD -MP -MF .deps/resolver.Tpo -c -o resolver.o resolver.c
mv -f .deps/resolver.Tpo .deps/resolver.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT screenfilter.o -MD -MP -MF .deps/screenfilter.Tpo -c -o screenfilter.o screenfilter.c
mv -f .deps/screenfilter.Tpo .deps/screenfilter.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT serv_hash.o -MD -MP -MF .deps/serv_hash.Tpo -c -o serv_hash.o serv_hash.c
mv -f .deps/serv_hash.Tpo .deps/serv_hash.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT sorted_list.o -MD -MP -MF .deps/sorted_list.Tpo -c -o sorted_list.o sorted_list.c
mv -f .deps/sorted_list.Tpo .deps/sorted_list.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT threadprof.o -MD -MP -MF .deps/threadprof.Tpo -c -o threadprof.o threadprof.c
mv -f .deps/threadprof.Tpo .deps/threadprof.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT ui_common.o -MD -MP -MF .deps/ui_common.Tpo -c -o ui_common.o ui_common.c
mv -f .deps/ui_common.Tpo .deps/ui_common.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT ui.o -MD -MP -MF .deps/ui.Tpo -c -o ui.o ui.c
mv -f .deps/ui.Tpo .deps/ui.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT tui.o -MD -MP -MF .deps/tui.Tpo -c -o tui.o tui.c
mv -f .deps/tui.Tpo .deps/tui.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT util.o -MD -MP -MF .deps/util.Tpo -c -o util.o util.c
mv -f .deps/util.Tpo .deps/util.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT addrs_ioctl.o -MD -MP -MF .deps/addrs_ioctl.Tpo -c -o addrs_ioctl.o addrs_ioctl.c
mv -f .deps/addrs_ioctl.Tpo .deps/addrs_ioctl.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT addrs_dlpi.o -MD -MP -MF .deps/addrs_dlpi.Tpo -c -o addrs_dlpi.o addrs_dlpi.c
mv -f .deps/addrs_dlpi.Tpo .deps/addrs_dlpi.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT dlcommon.o -MD -MP -MF .deps/dlcommon.Tpo -c -o dlcommon.o dlcommon.c
mv -f .deps/dlcommon.Tpo .deps/dlcommon.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT stringmap.o -MD -MP -MF .deps/stringmap.Tpo -c -o stringmap.o stringmap.c
mv -f .deps/stringmap.Tpo .deps/stringmap.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT cfgfile.o -MD -MP -MF .deps/cfgfile.Tpo -c -o cfgfile.o cfgfile.c
mv -f .deps/cfgfile.Tpo .deps/cfgfile.Po
gcc -DHAVE_CONFIG_H -I. -g -O2 -MT vector.o -MD -MP -MF .deps/vector.Tpo -c -o vector.o vector.c
mv -f .deps/vector.Tpo .deps/vector.Po
gcc -g -O2 -o iftop addr_hash.o edline.o hash.o iftop.o ns_hash.o options.o resolver.o screenfilter.o serv_hash.o sorted_list.o threadprof.o ui_common.o ui.o tui.o util.o addrs_ioctl.o addrs_dlpi.o dlcommon.o stringmap.o cfgfile.o vector.o -lpcap -lm -lcurses -lpthread
make[2]: Leaving directory `/home/iftop/iftop-1.0pre4'
make[1]: Leaving directory `/home/iftop/iftop-1.0pre4'
Making install in config
make[1]: Entering directory `/home/iftop/iftop-1.0pre4/config'
make[2]: Entering directory `/home/iftop/iftop-1.0pre4/config'
make[2]: Nothing to be done for `install-exec-am'.
make[2]: Nothing to be done for `install-data-am'.
make[2]: Leaving directory `/home/iftop/iftop-1.0pre4/config'
make[1]: Leaving directory `/home/iftop/iftop-1.0pre4/config'
make[1]: Entering directory `/home/iftop/iftop-1.0pre4'
make[2]: Entering directory `/home/iftop/iftop-1.0pre4'
/usr/bin/mkdir -p '/usr/local/sbin'
/usr/bin/install -c iftop '/usr/local/sbin'
/usr/bin/mkdir -p '/usr/local/share/man/man8'
/usr/bin/install -c -m 644 iftop.8 '/usr/local/share/man/man8'
make[2]: Leaving directory `/home/iftop/iftop-1.0pre4'
make[1]: Leaving directory `/home/iftop/iftop-1.0pre4'
命令执行完成后,可以看到iftop已经被安装到/usr/local/sbin目录下了
![]()
完成iftop的安装后,就可以直接执行iftop命令了,命令执行后可以看到如下图的网络流量使用信息

l ![]() 转存失败重新上传取消
转存失败重新上传取消![]() 代表了网络流量的流转方向
代表了网络流量的流转方向
l TX:表示发送的总流量
l RX:表示接收的总流量
l TOTAL:表示总流量
l peak:表示每秒流量的峰值
l rates:分别表示过去 2s 10s 40s 的平均流量
iftop 命令还可以支持添加其它参数的使用
iftop –i 指定网卡名 可以用来监控指定网卡的网络流量信息,例如执行iftop -i ens33命令可以监控ens33这块网卡的网络流量使用

iftop –P 可以在网络流量信息中展示host信息和对应的端口信息,如下图所示

备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。
1.1.6、 nmon对Linux服务器的整体性能监控
nmon 是一个监控aix和linux服务器性能的免费工具,nmon可以监控的数据主要包括:CPU 使用信息、内存使用信息,内核统计信息、运行队列信息、磁盘 I/O 速度、传输和读/写比率、网络 I/O 速度、传输和读/写比
率、消耗资源最多的进程,虚拟内存使用信息等,配合nmon_analyser一起可以nmon的监控数据转换为excel形式的报表,nmon也不是操作系统自带的监控工具,需要单独进行安装,可以从、
https://sourceforge.net/projects/nmon/网站中下载nmon进行安装使用。

安装完成后,执行nmon 命令后,可以进入nmon的监控选项视图
 转存失败重新上传取消
转存失败重新上传取消
- 键盘按下c后,可以实时监控到服务器CPU中每一个CPU核的使用信息

- 键盘按下l后,可以实时监控CPU的整体使用信息,此时展示的不再是单个CPU核的使用信息,而是所有CPU核整体的平均使用信息,如下图所示

- 键盘按下m后,可以实时监控到服务器的物理内存和虚拟内存的使用信息

- 键盘按下k后,可以实时监控到服务器的内核信息

内核监控中可以看到操作系统内核中的运行队列(RunQueue)大小、每秒CPU上下文(ContextSwitch)切换的次数、每秒CPU的中断(Interrupts)次数,每秒调用Forks的次数(Linux操作系统创建新的进程一般都是调用fork函数进行创建,从中可以看到每秒创建了多少新的进程)以及CPU的使用信息等。
- 键盘按下d后,可以实时监控到服务器的磁盘I/O的读写信息

- 键盘按下j后,可以实时监控到服务器的文件系统的相关信息

- 键盘按下n后,可以实时监控到服务器网卡流量的相关信息

- 键盘按下t后,可以实时监控top process的相关资源使用信息

1.1.7、 如何通过top发现问题
在性能测试时,linux操作系统中还可以通过top命令来发现和定位服务器性能消耗问题,执行top命令后获取到的数据如下图所示。

从图中可以看到:
- 第一行展示的为系统运行信息:系统当前时间为02:11:13、系统运行了41分钟、当前登录的用户有2个、系统的平均负载压力情况为0.00(1分钟的平均负载压力) 0.01(5分钟的平均负载压力) 0.05(15分钟的平均负载压力),load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值,一般当这个数值除以CPU的核数得到的值大于3-5时就表明系统的负载压力已经超高了。
- 第二行展示的为任务信息:总共108个进程、1个进程正在占用CPU进行运行、107个进程正在休眠中、0个进程停止、0个进程假死。
- 第三行展示的为CPU的运行信息:0.0 us表示 用户模式下CPU占用比为0.0%,0.2 sy 表示系统模式下CPU占用比为0.2%,0.0 ni表示改变过优先级的进程的CPU占用比为0.0%,99.8 id 表示空闲状态的CPU占比为99.8%,0.0 wa 表示因为I/O等待造成的CPU占比为0.0%,0.0 hi表示硬中断的CPU占比,0.0 si 表示软中断的CPU的占比,0.0 st表示CPU等待虚拟机调度的时间占比,这个指标一般在虚拟机中才会有,物理机中,该值一般维持为0。
- 第四行展示的为内存的使用信息:1865308 total 表示物理内存的总量, 1457604 free表示物理内存的空闲大小, 198808 used表示已使用的物理内存的大小, 208896 buff/cache表示用作缓存的物理内存的大小
- 第五行展示的为虚拟内存(swap)的使用信息:2097148 total 表示虚拟内存空间大小, 2097148 free 表示虚拟内存空间的空闲大小, 0 used表示虚拟内存空间的使用大小. 1479036 avail Mem 表示还可以被使用的有效内存大小。
- 第七行展示的为每个进程的资源消耗信息,详情如下表所示。
| 列名 |
描述 |
| PID |
进程id编号 |
| USER |
进程的持有用户 |
| PR |
进程运行的优先级,值越小优先级就越高,会越早获得CPU的执行权。
|
| NI |
进程的nice值,表示进程可被执行的优先级的修正数值 |
| VIRT |
进程使用的虚拟内存总大小,单位为KB |
| RES |
进程使用的并且未被虚拟内存换出的物理内存大小,一般也称为常驻内存,单位为KB |
| SHR |
进程使用的共享内存大小,单位为KB |
| S |
进程当前的运行状态。 D:不可中断的睡眠状态 R:运行中 S:休眠中 T:跟踪/停止 Z:假死中 |
| %CPU |
进程运行时CPU的占比 |
| %MEM |
进程使用的内存占比 |
| TIME+ |
进程占用的CPU总时长 |
| COMMAND |
正在运行的命令 |
top命令支持的其它常用参数如下:
- top –p:查看指定进程id的top信息,例如执行top -p 2081可以查看进程编号为2081的top信息,如下图所示。

- top –H –p:查看指定进程id的所有线程的top信息,例如执行top -H -p 2081可以查看进程编号为2081的所有线程的top信息,如下图所示,此时图中的PID展示的为线程的id编号。

通过top --help还可以查看到更多的关于top命令的参数使用信息。
备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。文章链接:https://www.cnblogs.com/laoqing/p/11629941.html
1.1.8、 如何通过pidstat发现性能问题
pidstat是针对Linux操作系统中某个进程进行资源监控的一个常用命令。使用该命令可以列出每个进程id占用的资源情况,如下图所示。

另外还可以通过在pidstat 命令后面增加数字参数来轮询获取资源使用的数据,例如执行pidstat 1 3 可以轮询每隔1s自动获取3个活动的进程的CPU使用情况,如下图所示。
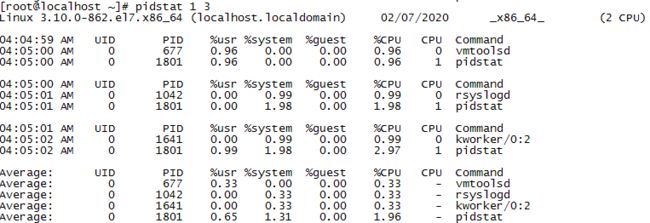
执行pidstat后获得的性能监控指标详细说明如下表所示:
| 指标 |
含义 |
| UID |
用户id |
| PID |
进程id |
| %usr |
进程对用户模式cpu使用时间的百分比 |
| %system |
进程对系统模式cpu使用时间的百分比 |
| %guest |
进程在虚拟机(运行虚拟处理器)中占用的cpu百分比 |
| %CPU |
指定进程使用cpu的时间的百分比 |
| CPU |
执行指定进程的cpu编号 |
| Command |
当前进程运行的命令 |
pidstat还可以支持其他的参数使用,我们可以通过执行pidstat --help 命令查看到它支持的其他参数,如下图所示。

- pidstat –d:展示每个进程的I/O使用情况,如下图所示:
 转存失败重新上传取消
转存失败重新上传取消
| 指标 |
含义 |
| kB_rd/s |
进程每秒从磁盘读取的数据大小,单位为KB |
| kB_wr/s |
进程每秒写入磁盘的数据大小,单位为KB |
| kB_ccwr/s |
进程写入磁盘被取消的数据大小,单位为KB |
- pidstat –p:如果只需要看指定进程id的资源使用情况,可以通过-p参数来进行指定,例如执行pidstat -p 1533 可以看到进程编号为1533的进程占用的CPU资源情况,如下图所示。

执行pidstat -d -p 1533可以看到进程编号为1533的进程的I/O使用情况,如下图所示。

- pidstat –r:展示每个进程的内存使用情况,如下图所示:

| 指标 |
含义 |
| minflt/s |
进程读取内存数据时每秒出现的次要错误的数量,这些错误指的是不需要从磁盘载入内存的数据,一般是虚拟内存地址映射成物理内存地址所产生的page fault次数。 |
| majflt/s |
进程读取内存数据时每秒出现的主要错误的数量,这些错误指的是需要从磁盘载入内存的数据。当虚拟内存地址映射成物理内存地址时,相应的page数据在swap中,这样的page fault(页面数据错误)为major page fault(主要页面数据错误),一般在物理内存使用紧张时才产生。 |
| VSZ |
进程占用的虚拟内存的大小,单位为KB |
| RSS |
进程占用的物理内存的大小,单位为KB |
| %MEM |
进程占用的内存百分比 |
- pidstat –u:和执行pidstat 命令获取的数据是一致的。
- pidstat –w:展示每个进程的CPU上下文切换次数,如下图所示。
 转存失败重新上传取消
转存失败重新上传取消
| 指标 |
含义 |
| cswch/s |
每秒主动进行cpu上下文切换的数量,一般由于需要的资源不可用而发生阻塞时,会自愿主动进行上下文切换。 |
| nvcswch/s |
每秒被动进行cpu上下文切换的数量,比如当进程在其cpu时间片内执行,然后由于cpu时间片调度被迫放弃该cpu处理器时,会发生被动非自愿的上下文切换。 |
- pidstat –l: 显示进程正在执行的命令以及该命令对应的所有参数,如下图所示。

- pidstat –t:展示进程以及进程对应的线程的资源使用情况,如下图所示。

图中的TGID表示的就是进程id,而TID表示的是对应的进程id下的线程id。
例如还可以执行pidstat -r -t -p 1533 来查看进程id为1533的进程以及该进程对应的线程的内存使用情况,如下图所示。

- pidstat –s:展示每个进程的堆栈使用情况,如下图所示。

| 指标 |
含义 |
| StkSize |
进程保留在内存中的堆栈占用的内存大小,单位为KB,这些堆栈数据并一定全部会被进程使用。 |
| StkRef |
进程实际引用的用作堆栈的内存大小(即实际使用的堆栈空间大小),单位为KB。 |
- pidstat –U:展示进程的资源使用数据时同时展示进程id对应的用户名称,如下图所示,USER列可以看到用户的名称。

1.2、 Windows服务器的性能指标监控和分析
1.2.1、 Windows性能监视器
Windows服务器在安装完Windows操作系统后,操作系统中默认就自带了性能监控工具,这个自带的性能监控工具通过访问操作系统的控制面板->所有控制面板项->管理工具->性能监视器就能打开自带的这个性能监控工
具,也可以通过在命令行中运行Perfmon.msc命令来打开自带的性能监控工具,打开后的界面如下图所示。

在Windows2003服务器操作系统中,这个性能监控工具是直接叫性能,如下图所示
在Windows2003中,打开性能监控工具的界面如下图所示,界面展示略有不同,但是包含的功能基本一致。

针对Processor、Process、Memory、TCP/UDP/IP/ICMP、PhysicalDisk等监控对象,Windows自带的性能监视器提供了数百个性能计数器可以对这些对象进行监控,计数器可以提供应用程序、Windows服务、操作系统等的相关的性能信息来辅助分析程序性能瓶颈和对系统及应用程序性能进行诊断和调优。
在进入性能监视器界面后,可以通过点击![]() 按钮来添加对应的计数器,如下图所示。
按钮来添加对应的计数器,如下图所示。
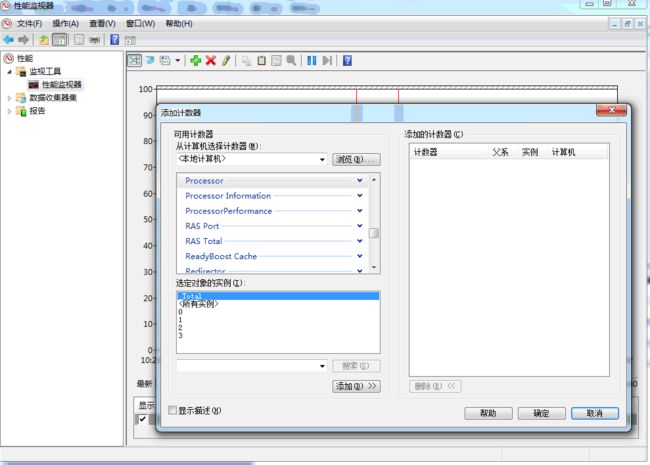
常见的计数器如下
l Processor:指的就是Windows服务器的CPU,在添加时会有实例的选择,每一个实例代表了CPU的每一个核,比如4核的CPU的就会有4个实例,可以根据需要选择对应的实例,在选择了Processor后,可以看到该实例下所有和Processor相关的计数器,如下图

Processor相关的计数器指标说明如下
| 计数器 |
说明 |
| %Processor Time |
CPU执行非闲置进程和线程时间的百分比(可以通俗的理解为CPU处于繁忙使用状态的时间占比),该计数器一般可以用来作为CPU的整体利用率指标 |
| %User Time |
CPU处于用户模式下的使用时间占比,该计数器和Linux下的%usr指标含义类似 |
| %Privileged Time |
CPU在特权模式下处理线程所花的时间占比,该计数器一般可以作为系统服务、操作系统自身模式下耗费的CPU时间占比,这个指标一般不会太高,如果太高就需要去定位原因,一般的时候%User Time越高,说明CPU被利用的越好。 |
| Interrupts/sec |
CPU每秒的中断次数, 该计数器和Linux下的in指标的含义类似 |
| %Interrupt Time |
CPU中断时间占比,该计数器和Linux下的%irq指标的含义类似 |
| %Idle Time |
CPU空闲时间占比,该计数器和Linux下的%idle指标的含义类似 |
| %DPC Time |
CPU处理网络传输等待的时间占比 |
l Memory:指的就是Windows服务器的物理内存,在选择了Memory后,可以看到该实例下所有和Memory相关的计数器,如下图
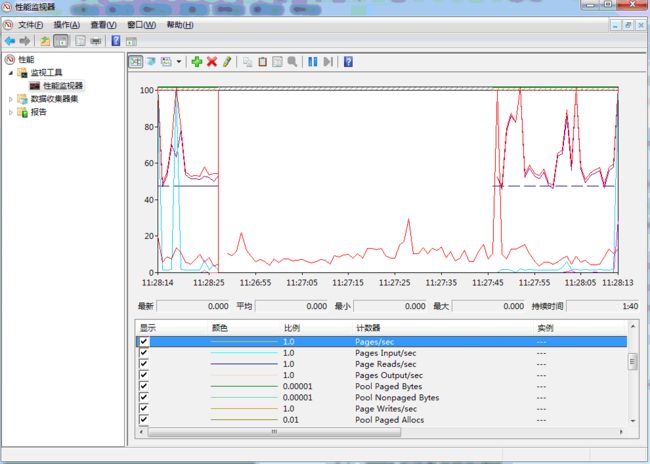 转存失败重新上传取消
转存失败重新上传取消
Memory相关的计数器指标说明如下
| 计数器 |
说明 |
| Available Bytes |
服务器剩余的可用物理内存的大小(单位为字节),如果该值很小说明服务器总的内存可能不够或者部分应用一直都没有及时释放内存, 服务器的可用物理内存是通过将程序释放的内存、空闲内存、备用内存相加在一起计算出来的。 |
| Committed Bytes |
已被提交的虚拟内存字节数,内存分配时会先在虚拟地址空间上保留一段空间保留一段时间,此时系统还没有分配真正的物理内存只是分配了一段内存地址,在这一步操作成功后再提交分配的这段内存地址,操作系统接收到提交的内存地址后才会分配真正的物理内存。 |
| Page Faults/sec |
每秒缺页中断或者页面错误的数量,一般内存中不存在需要访问的数据导致需要从硬盘读取可能会导致此指标较高。 |
| Reads/sec |
每秒为了解决硬错误(一般指引用的页面在内存中不存在)而从硬盘上读取页面的次数 |
| Writes/sec |
每秒为了释放物理内存空间而需要将页面写入磁盘的次数 |
| Input/sec |
每秒为了解决硬错误而从硬盘读取的页面数量,一般是指内存引用时页面不在内存,为解决这种情况而从磁盘读取的页面数量。 |
| Output/sec |
每秒内存中的页面发生了修改从而需要写入磁盘的页面数量 |
| Pages/sec |
每秒为了解决硬错误(一般指引用的页面在内存中不存在)而从硬盘上读取或写入硬盘的页面数量 |
| Cathe Bytes |
Windows文件系统的缓存,这块也是占用服务器的物理内存,但是在物理内存不够时是可以释放的,Windows在释放内存时一般会使用页交换的方式进行,页交换会将固定大小的代码和数据块从 物理内存移动到磁盘。 |
| Pool Nonpaged Allocs |
在非分页池中分配空间的调用数,这个计数器是以调用分配空间的次数来衡量的,而不会管每次调用分配的空间量是多少。 一般内核或者设备驱动使用非分页池来保存可能访问的数据,一旦加载到该池就始终驻留在物理内存中,并且在访问的时候又不能出现错误,未分页池不执行换入换出操作,如果一旦发生内存泄漏,将会非常严重。与非分页池对应的就是分页池(Paged Pool),指的是可以存到操作系统的分页文件中,允许其占用的物理内存被重新设置,类似用户模式的虚拟内存。 |
| Pool Nonpaged Bytes |
非分页池的大小(单位:字节)。内存池非分页字节的计算方式不同于进程池中非分页字节,因此它可能不等于进程池非分页字节总数。 |
| Pool Paged Allocs |
在分页池中分配空间的调用数。它也是以调用分配空间的次数来衡量的,而不管每次调用分配的空间量是多少。 |
| Pool Paged Bytes |
分页池的大小(单位:字节)。内存池分页字节的计算方式与进程池分页字节的计算方式不同,因此它可能不等于进程池分页字节总数。 |
| Transition Faults/sec |
通过恢复共享页中被其它进程正在使用的页、已修改页列表或待机列表中的页、或在页故障时写入磁盘的页来解决页故障的速率。在没有其他磁盘活动的情况下恢复了这些页。转换错误按错误数计算,因为每个操作中只有一个页面出错,所以它也等于出错的页面数。 |
| Write Copies/sec |
通过从物理内存中的其他位置复制页来满足的写入尝试导致页错误的速率。这是一种效率很高的共享数据的方式,因为页面只在写入时被复制,否则页面被共享。此计数器只显示副本数而不考虑每次操作中复制的页数。 |
| System Code Total Bytes |
虚拟内存中当前可分页给操作系统程序的空间大小(单位:字节)。它是操作系统使用的物理内存量的量度并且可以在不使用时写入磁盘。这个值是通过添加ntoskrnl.exe、hal.dll、引导驱动程序和ntldr/osloader加载的文件系统中的字节来计算的。此计数器不包括必须保留在物理内存中且无法写入磁盘的操作系统程序。 |
| System Driver Total Bytes |
设备驱动程序当前使用的可分页虚拟内存的大小(单位:字节),包括物理内存(内存/系统驱动程序驻留空间)和写入磁盘的代码和数据。它是内存/系统代码总字节数的组成部分 |
l PhysicalDisk:指的就是Windows服务器的磁盘设备,在选择了PhysicalDisk后,可以看到该实例下所有和PhysicalDisk相关的计数器,如下图

备注:作者的原创文章,转载须注明出处。原创文章归作者所有,欢迎转载,但是保留版权。对于转载了博主的原创文章,不标注出处的,作者将依法追究版权,请尊重作者的成果。
本文作者:张永清 文章选自 作者2020年初即将出版的《性能测试分析与性能诊断调优核心思想》一书。文章链接:https://www.cnblogs.com/laoqing/p/11629941.html
PhysicalDisk相关的计数器指标说明如下
| 计数器 |
说明 |
| Disk Bytes/sec |
每秒从磁盘I/O读取和写入的字节数 |
| Disk Read Bytes/sec |
每秒从磁盘I/O读取的字节数,这个计数器是以字节大小来描述每秒对磁盘的读取操作。 |
| Disk Write Bytes/sec |
每秒写入磁盘I/O的字节数,这个计数器是以字节大小来描述每秒对磁盘的写入操作。 |
| Disk Reads/sec |
对磁盘读取操作的速率,这个计数器是以每秒对磁盘I/O的读取次数来描述对磁盘的读取频率 |
| Disk Writes/sec |
对磁盘写入操作的速率,这个计数器是以每秒对磁盘I/O的写入次数来描述对磁盘的写入频率 |
| Disk Transfers/sec |
每秒对磁盘I/O读取和写入的次数 |
| %Disk Time |
所选磁盘驱动器正忙于处理读取或写入请求所用时间占比 |
| %Disk Read Time |
所选磁盘驱动器正忙于处理读取请求的时间占比 |
| %Disk Write Time |
所选磁盘驱动器正忙于处理写入磁盘请求的时间占比 |
| Avg. Disk Queue Length |
所选磁盘在性能监视器性能数据采样间隔期间需要排队的平均读写请求数 |
| Avg. Disk Read Queue Length |
所选磁盘在性能监视器性能数据采样间隔期间需要排队的平均读取请求数 |
| Avg. Disk Write Queue Length |
所选磁盘在性能监视器性能数据采样间隔期间需要排队的平均写入请求数 |
| Split IO/Sec |
对磁盘I/O的读写请求拆分为多个请求的速率。分割I/O可能是由于请求的数据太大,无法容纳单个I/O,或者物理磁盘在单个磁盘系统上已经被被分割。 |
l IPv4:指的就是Windows服务器的IPv4网络请求,在选择了IPv4后,可以看到该实例下所有和IPv4相关的计数器,如下图

IPv4相关的计数器指标说明如下
| 计数器 |
说明 |
| Datagrams/sec |
服务器每秒发送和接收到的请求报文数 |
| Datagrams Received/sec |
服务器每秒接收到的请求报文数 |
| Datagrams Received Header Errors/sec |
服务器每秒接收到的请求报文中header 错误的数量 |
| Datagrams Received Address Errors/sec |
服务器每秒接收到的请求报文中请求地址错误的数量 |
| Datagrams Forwarded/sec |
服务器每秒转发的请求报文数 |
| Datagrams Received Unknown Protocol/sec |
服务器每秒接收到无法处理的未知网络协议的请求报文数 |
| Datagrams send/sec |
服务器每秒发送的报文数 |
l Process:指的就是Windows服务器的进程监控,在选择了Process后,可以看到该实例下所有和Process相关的计数器,如下图
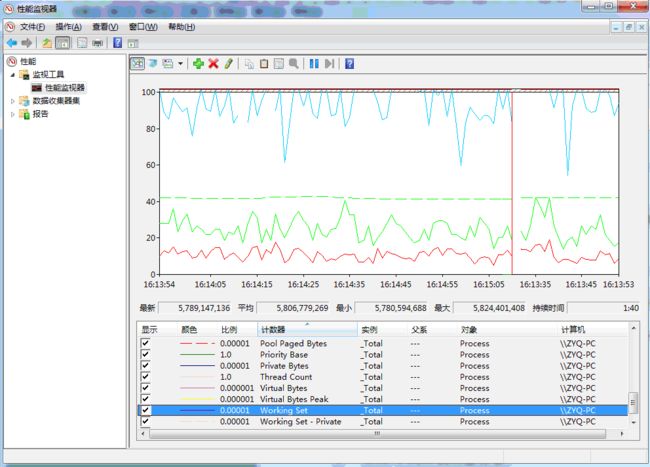
Process相关的计数器指标说明如下
| 计数器 |
说明 |
| Thread Count |
表示当前正在运行的线程数 |
| Virtual Bytes |
表示进程占用的全部虚拟地址空间大小(单位为字节),包括进程间的共享地址空间 |
| Virtual BytesPeak |
表示进程占用的全部虚拟地址空间的峰值大小,峰值表示从服务器开始运行一直到现在的时间中曾经使用的最大值。 |
| Working Set |
表示进程工作集占用内存的大小,包含了每个进程下的各个线程引用过的页面空间以及可能被其他程序共享的内存空间。 |
| WorkingSetPeak |
表示进程工作集占用内存的峰值大小,峰值表示从服务器开始运行一直到现在的时间中曾经使用的最大值。 |
| Private Bytes |
表示进程占用的虚拟地址空间大小(单位为字节),并且不包括进程间的共享地址空间,可以认为占用的空间大小是进程私有使用的。 |
| Handle Count |
表示进程使用的kernel object handle数量,当程序进入稳定运行状态的时候, Handle Count数量也应该维持在一个稳定的区间。 如果发现Handle Count在整个程序周期内总体趋势连续向上,应该考虑程序是否有Handle 泄漏。 |
| Pool Paged Bytes |
表示分页池的使用大小,单位为字节 |
| Pool Nonpaged Bytes |
表示非分页池的使用大小,单位为字节 |
1.2.2、 Windows性能监视器下的性能分析
l 内存泄漏:Windows服务器下借助性能监视器的计数器分析内存泄漏问题的一般步骤如下:

如果剩余的有效物理内存一直在减少并且已提交的虚拟内存一直在增加,那么此时程序代码可能存在内存泄漏的风险,但是此时还需要观察Process计数器中的Private Bytes和Working Set是不是也在持续增加,
如果同样在持续增加那么从服务器端监控看存在内存泄漏的可能性就非常大了,此时就需要去看部署在服务器上的程序是不是存在内存不能回收的情况,可以停止压测,看下内存使用是否会释放和回落。另外如果
观察到HandleCount 的使用一直上涨,那么可能是内核模式进程导致了内存泄露,那么此时就还需要持续观察内存分页池中的Paged Bytes和 Pool Paged Bytes是不是也是在一直上涨。
未完待续.......
性能测试分析与性能诊断调优核心思想目录提纲(计划2020年上架出版)
序... 4
1 性能测试和性能分析的基础概念... 5
1.1. 性能测试的基础概念... 5
1.1.1 性能测试的分类... 6
1.1.2 性能测试的场景... 6
1.2. 常见的性能测试指标... 7
1.2.1 响应时间... 7
1.2.2 TPS/QPS. 8
1.2.3 并发用户... 8
1.2.4 PV/UV.. 8
1.2.5 点击率... 9
1.2.6 吞吐量... 9
1.2.7 资源开销... 9
1.3. 性能测试的目标... 10
1.4. 性能测试的基本流程... 11
1.4.1 性能需求分析... 11
1.4.2 制定性能测试计划... 12
1.4.3 编写性能测试方案... 13
1.4.4 编写性能测试案例... 15
2 性能分析与调优思想... 15
2.1 性能分析调优模型... 15
2.2 性能分析调优思想... 18
2.2.1 分层分析... 18
2.2.2 科学论证... 19
2.2.3 问题追溯与归纳总结... 19
2.3 性能调优技术... 22
2.3.1 缓存调优... 22
2.3.2 同步转异步推送... 23
2.3.3 拆分... 23
2.3.4 任务分解与并行计算... 24
2.3.5 代码优化... 24
2.3.6 索引与分库分表... 24
3 服务器的性能监控和分析... 24
3.1 Linux服务器的性能指标监控和分析... 25
3.1.1 通过vmstat深挖服务器的性能问题... 25
3.1.2 如何通过mpstat 分析服务器的性能指标... 29
3.1.3 如何通过pidstat发现性能问题... 31
3.1.4 从lsof中能看到什么... 39
3.1.5 如何通过free看懂内存的真实使用... 49
3.1.6 如何通过top发现问题... 50
3.1.7 网络流量如何监控... 54
3.1.8 nmon对Linux服务器的整体性能监控... 61
3.2 Windows服务器的性能指标监控和分析... 64
3.2.1 Windows性能监视器... 64
3.2.2 Windows性能监视器下的性能分析... 79
4 web中间件的性能分析... 84
4.1 nginx的性能分析和调优... 84
4.1.1 nginx的负载均衡策略的选择... 84
4.1.2 nginx进程数的配置优化... 87
4.1.3 nginx事件处理模型的优化... 87
4.1.4 nginx客户端连接数的优化... 90
4.1.5 nginx中文件传输的优化... 91
4.1.6 nginx中FastCGI配置的优化... 94
4.1.7 nginx的监控... 97
4.2 apache的性能分析和调优... 99
4.2.1 apache的工作模式选择和进程数调优... 99
4.2.2 apache的mod选择和优化... 104
4.2.3 apache的keepAlive优化... 107
4.2.4 apache的ab压力测试工具... 108
4.2.5 apache的性能监控... 111
5 应用中间件的性能分析... 112
5.1 tomcat的性能分析和调优... 113
5.1.1 tomcat的组件以及工作原理... 113
5.1.2 tomcat容器Connector性能参数优化... 118
5.1.3 tomcat容器的I/O优化... 120
5.2 wildfly的性能分析和调优... 125
5.2.1 wildfly standalone模式介绍... 125
5.2.2 wildfly standalone模式管理控制台性能参数优化... 129
5.2.3 wildfly standalone模式性能监控... 140
6 java应用程序的性能分析和调优... 149
6.1 jvm基础知识... 149
6.1.1 jvm简介... 149
6.1.2 类加载器... 151
6.1.3 java虚拟机栈和本地方法栈... 154
6.1.4 方法区与元数据区... 154
6.1.5 堆区... 155
6.1.6 程序计数器... 157
6.1.7 垃圾回收... 157
6.1.8 并行与并发... 162
6.1.9 垃圾回收器... 163
6.2 jvm如何监控... 165
6.2.1 jconsole. 165
6.2.2 jvisualvm.. 173
6.2.3 jmap. 186
6.2.4 jstat 187
6.3 jvm性能分析与诊断... 188
6.3.1 如何读懂gc日志... 188
6.3.2 jstack. 193
6.3.3 MemoryAnalyzer. 200
6.4 jvm性能调优技巧... 211
6.4.1 如何减少gc. 211
6.4.2 另类java内存泄漏... 213
7 数据库的性能分析... 214
7.1 mysql数据库的性能监控... 214
7.1.1 如何查看mysql数据库的连接数... 214
7.1.2 如何查看mysql数据库当前运行的事务与锁... 214
7.1.3 mysql中数据库表的监控... 218
7.1.4 性能测试时mysql中其它常用监控... 222
7.2 mysql数据库的性能定位... 225
7.2.1 慢sql 225
7.2.2 执行计划... 226
8 性能测试案例分析... 229
8.1 jmeter对http 服务的性能压测分析... 229
8.2 LoadRunner对http 服务的性能压测分析... 243
8.3 jmeter对rpc 服务的性能压测分析... 262
8.3.1 jmeter 如何通过自定义Sample来压测RPC服务... 262
8.3.2 jmeter对GRPC服务的性能压测分析... 273
9 安卓APP的性能分析... 281
9.1 adb. 281
9.2 DDMS. 284
9.3 Android Studio profiler 299
9.4 systrace 306
链接:https://www.cnblogs.com/laoqing/p/11629941.html