百度飞桨目标检测教程三:YOLO系列论文解析
百度飞桨目标检测教程三:YOLO系列论文解析
Anchor-based 单阶段目标检测算法 YOLO系列论文解析
涉及论文:YOLOv1 YOLOv2 YOLOv3 PPYOLO
YOLOv1
ppt1
性价比最高,不是精度最高的,但是精度没有很大损失的情况下速度大幅领先,实时性要求>30FPS就可以
| Network | Accuracy | Speed |
|---|---|---|
| YOLO | 63.4VOC | 45 |
| YOLO-Lite | 52.7VOC | 155 |
| YOLOv2 | 78.6VOC | 40 |
| YOLOv2-Lite | 76.8VOC | 67 |
| YOLOv3 | 33.0coco | SSD * 3 RetianNet * 3.8 |
YOLOv1
[You only look once: Unified, real-time object detection](https://xueshu.lanfanshu.cn/scholar_url?url=https%3A%2F%2Fwww.cv-foundation.org%2Fopenaccess%2Fcontent_cvpr_2016%2Fhtml%2FRedmon_You_Only_Look_CVPR_2016_paper.html&hl=zh-CN&sa=T&ct=res&cd=0&d=6382612685700818764&ei=bzNOX8XcGPCF6rQPyO6SqAE&scisig=AAGBfm2gowB_5J8mZ-5ucoALdgg32yaPsg&nossl=1&ws=1855x932&at=You only look once%3A Unified%2C real-time object detection)
2016 CVPR
引用次数:10791
作者:Joseph Redmon University of Washington, USA
联系方式:Email: [email protected]
代码复现:http://pjreddie.com/yolo/

you only look once,一张图片放到深度学习网络中一次就可以得到输出,而前面的RCNN系列的论文是先提取proposal,再对proposal做分类和回归,相当于是看了两次。
ppt2
YOLO的基本原理

把图像划分成S * S的网格,物体的真实框的中心落在哪个网格上,就由该网格对应锚框负责检测该物体。
输出特征图是S * S * C,长和宽分别表示划分的网格,而通道C来表示想要得到的信息,包括[x, y, w, h, 置信度pobject, one-hot分类信息]
类似于前面的FPN网络,YOLO也用到了预设锚框的算法,对每一个格子预设B个锚框,输出的特征图的通道C的大小应该是 C = 85 ∗ B C = 85 * B C=85∗B。
85是说,前面4个坐标表示,该预设锚框与真实框的偏移量,类似于RCNN系列中的回归分支,第5个坐标代表该锚框的置信度,即有多大概率包含一个物体,最后80个坐标是coco数据集80个类别的one-hot向量输出,如果用其他的数据集进行训练,数量也会不尽相同。
YOLOv2
ppt1
YOLOv2
YOLO9000: better, faster, stronger
2017 CVPR
引用次数:5553
作者:Joseph Redmon University of Washington, USA
联系方式:Email: [email protected]
代码复现:http://pjreddie.com/yolo/
yolov2是基于v1做的优化

Backbone升级:用DarkNet19作为骨架网络,输入图像分辨率从224 * 224升级到了448 * 448。
网络结构完全改为全卷积网络结构:网络结构层中只有Conv和Batch Norm。
在数据集上用Kmeans聚类得到anchor。
引入多尺度训练:每个batch输入的图像resize的大小是不同的。
优势:精度提升,速度提升
弊端:小目标的召回率不高,靠近的群体目标检测效果不好,精度还可以再提高。
YOLOv3
ppt1
YOLOv3
Yolov3: An incremental improvement
2018 arXiv technical report
引用次数:3702
作者:Joseph Redmon University of Washington, USA
联系方式:Email: [email protected]
代码复现:http://pjreddie.com/yolo/
优化方法:
骨架网络改为DarkNet53。
多尺度预测,跨尺度特征融合。
coco数据集聚类9种不同尺度的anchor,每个尺度有3个。
分类用sigmoid激活,支持目标多分类。
优势:精度提升,速度提升,通用性强。
弊端:小目标的召回率仍然不高,靠近的群体目标检测效果仍然不好,定位精度仍然还可以再提高。
但是总体来说YOLOv3的性价比已经很高了。
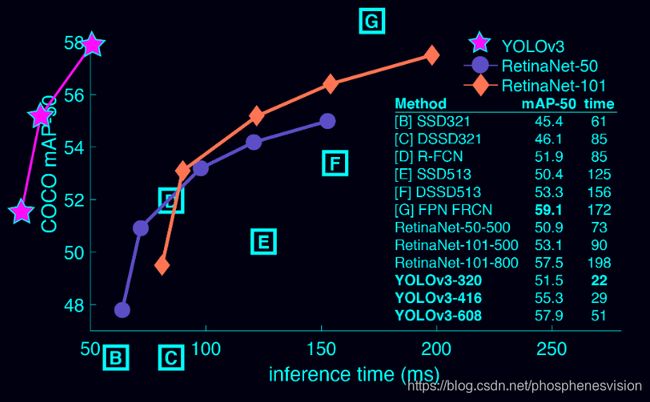
ppt2
yolov3结构图
图源:https://blog.csdn.net/leviopku/article/details/82660381

首先是图像输入到backbone中,backbone由5个ResNet Block组成,每一个block都会进行一次倍数为2的下采样。
且有三个尺度的输出,分别进行特征提取,得到不同尺度的结果输出。
ppt3
为什么要用3个输出分支?在coco数据集聚类9种尺度的anchor。

下采样倍率较多的那支输出,说明它经过的卷积层数比较多,感受野比较大,融合了更多的图像信息,因此需要比较大的那三个anchor与之匹配。
剩下的两个分支也是这样来分析。
ppt4
偏移量的预测

预测出来的偏移量是[tx, ty, tw, th],最后真实的偏移量是[bx, by, bw, bh],它们之间的变换关系如下
锚框尺寸[pw, ph]
中心点偏移 b x = c x + σ ( t x ) , b y = c y + σ ( t y ) b_x = c_x + \sigma(t_x), b_y = c_y + \sigma(t_y) bx=cx+σ(tx),by=cy+σ(ty)。
宽高拉伸 b h = p h exp ( t h ) , b w = p w exp ( t w ) b_h = p_h \exp(t_h), b_w = p_w \exp(t_w) bh=phexp(th),bw=pwexp(tw)。
为什么要这么做:一个网络的输出理论上来说取值范围是负无穷至正无穷,但是这么大的预测值对实际的应用来说是没有意义的,因此对于中心点的预测值做一个sigmoid函数作用到区间0至1上,这样,真实的预测值就不会偏出这个网格了,同样,高度和宽度都必须是正数,通过exp函数的作用,就保证了高和宽也一定是正的。
ppt5
YOLOv3的训练过程
正常的预测值应该是什么样的,假设一张图片有N个真实物体,那么真实值就是一个长度为N的列表,列表的每个元素形如[x, y, w, h, class]。
而网络的输出则是三个特征图,大小分别为[1, 255, 13, 13],[1, 255, 26, 26],[1, 255, 52, 52]。
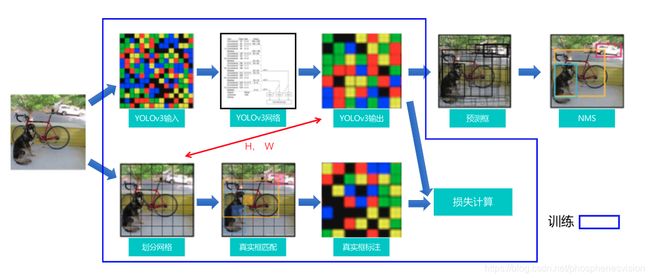
这是需要对预测值做出一些改变,拿13 * 13的那个分支来看,
-
初始化一个
[1, 255, 13, 13]的空数组, -
首先做对每个真实框做匹配,中心点落在哪个网格就填到哪个网格对应的位置上。
-
一共有9个锚框,与哪个锚框匹配?真实框与哪个锚框的IoU值最大就与哪个锚框匹配。
如果两个物体离得比较近,而且大小也差不多,不仅撞了网格,还撞了锚框,那就默认让后一个真实框覆盖掉前一个真实框,这就是为什么YOLOv3在检测距离相近的物体时效果比较差的原因。
-
然后怎么从真实的偏移量是
[bx, by, bw, bh]得到预测出来的偏移量是[tx, ty, tw, th],刚才那个运算的反过程。计算公式
锚框尺寸
[pw, ph],真实框[gtx, gty, gtw, gth]中心点偏移 σ ( t x ∗ ) = g t x − c x , σ ( t y ∗ ) = g t y − c y \sigma(t_x^*) = gt_x - c_x, \sigma(t_y^*) = gt_y - c_y σ(tx∗)=gtx−cx,σ(ty∗)=gty−cy。
宽高拉伸 t h ∗ = log ( g t h p h ) , t w ∗ = log ( g t w p w ) t_h^* = \log(\frac{gt_h}{p_h}), t_w^* = \log(\frac{gt_w}{p_w}) th∗=log(phgth),tw∗=log(pwgtw)。
-
填充pobject,对应锚框有目标标1,否则标0。
-
类别信息,填充one-hot向量。
损失函数
- 分类分支:YOLOv3分类使用sigmoid激活函数,分类损失为Sigmoid Cross Entropy。
- 定位分支:x,y用sigmoid激活,使用Sigmoid Cross Entropy;w,h用exp缩放,使用L1损失。
- Objectness分支:一个0至1之间的评分,使用sigmoid激活函数,使用Sigmoid Cross Entropy。
对于有真实框标记的锚框,需要计算定位损失,objectness损失和分类损失。
对于没有真实框标记的锚框,只需要计算objectness损失,将它向0进行回归。
对于没有真实框标记的锚框,但实际上该锚框与真实框超过了一个阈值threshold0.7,不计算任何损失。
ppt6
YOLOv3的预测过程,

计算中心点偏移,得到中心点坐标和预测框真实大小。
sigmoid计算objectness。
对每一个类别分别用sigmoid计算它的score。
为什么不用softmax?
softmax默认是这个锚框中只能有一个物体,如果遇到锚框中存在多个物体的情况下是不行的。
但是sigmoid对于每一个类的预测是独立的,这样就可以解决一个锚框存在多个物体的情况。
预测框评分score = objectness * 对应类别的评分
综上,解码得到[class, score, x, y, w, h]
后处理NMS
- 按class进行分组。
- 拿自行车这个类别来算,按score进行排序。
- 得到score最大的认为这是对的,把它放到对的那一个组。
- 剩下的依次与对的那一个组中所有的框计算IoU,如果值比较大,那么说明预测的是同一个物体,舍弃;如果值比较小,那么认为预测的是不同的物体,放到对的那个组里面去。
- 依次遍历完所有的输出框。
PPYOLO
未完待续。